(8)分布式下的爬虫Scrapy应该如何做-图片下载(源码放送)
转载主注明出处:http://www.cnblogs.com/codefish/p/4968260.html
在爬虫中,我们遇到比较多需求就是文件下载以及图片下载,在其它的语言或者框架中,我们可能在经过数据筛选,然后异步的使用文件下载类来达到目的,Scrapy框架中本身已经实现了文件及图片下载的文件,相当的方便,只要几行代码,就可以轻松的搞定下载。下面我将演示如何使用scrapy下载豆瓣的相册首页内容。
优点介绍:
1)自动去重
2)异步操作,不会阻塞
3)可以生成指定尺寸的缩略图
4)计算过期时间
5)格式转化
编码过程:
一,定义Item
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy
from scrapy import Item,Field class DoubanImgsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_urls = Field()
images = Field()
image_paths = Field()
pass
二,定义spider
#coding=utf-8
from scrapy.spiders import Spider
import re
from douban_imgs.items import DoubanImgsItem
from scrapy.http.request import Request
# please pay attention to the encoding of info,otherwise raise error
import sys
reload(sys)
sys.setdefaultencoding('utf8') class download_douban(Spider):
name = 'download_douban'
def __init__(self, url='', *args, **kwargs):
self.allowed_domains = ['douban.com']
self.start_urls = [
'http://www.douban.com/photos/album/%s/' %(url) ]
#call the father base function
self.url = url
super(download_douban, self).__init__(*args, **kwargs) def parse(self, response):
"""
:type response: response infomation
"""
list_imgs = response.xpath('//div[@class="photolst clearfix"]//img/@src').extract()
if list_imgs:
item = DoubanImgsItem()
item['image_urls'] = list_imgs
yield item
三,定义piepline
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
from scrapy import Request
from scrapy import log class DoubanImgsPipeline(object):
def process_item(self, item, spider):
return item class DoubanImgDownloadPieline(ImagesPipeline):
def get_media_requests(self,item,info):
for image_url in item['image_urls']: yield Request(image_url) def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
item['image_paths'] = image_paths
return item
四,定义setting.py,启用item处理器
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'douban_imgs.pipelines.DoubanImgDownloadPieline': 300,
} IMAGES_STORE='C:\\doubanimgs' IMAGES_EXPIRES = 90
运行效果:
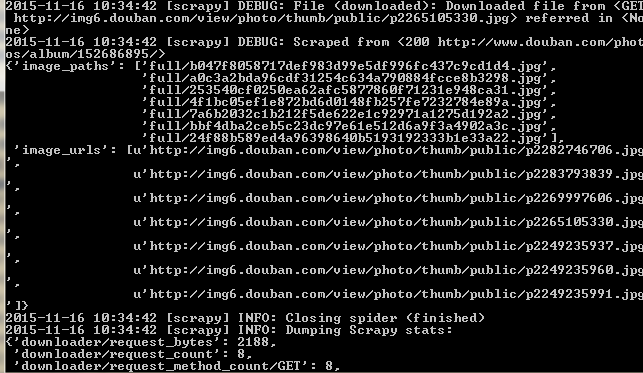
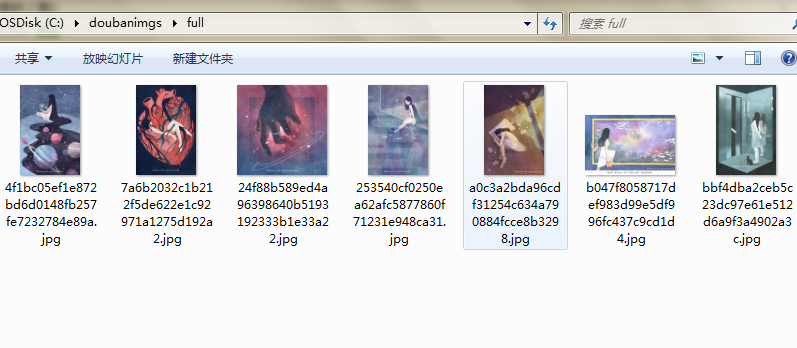
github地址:https://github.com/BruceDone/scrapy_demo
转载主注明出处:http://www.cnblogs.com/codefish/p/4968260.html
如果scrapy或者爬虫系列对你有帮助,请推荐一下,我后续会更新更多的爬虫系列
(8)分布式下的爬虫Scrapy应该如何做-图片下载(源码放送)的更多相关文章
- (5)分布式下的爬虫Scrapy应该如何做-windows下的redis的安装与配置
软件版本: redis-2.4.6-setup-64-bit.exe — Redis 2.4.6 Windows Setup (64-bit) 系统: win7 64bit 本篇的内容是为了给分布式下 ...
- (4)分布式下的爬虫Scrapy应该如何做-规则自动爬取及命令行下传参
本次探讨的主题是规则爬取的实现及命令行下的自定义参数的传递,规则下的爬虫在我看来才是真正意义上的爬虫. 我们选从逻辑上来看,这种爬虫是如何工作的: 我们给定一个起点的url link ,进入页面之后提 ...
- (3)分布式下的爬虫Scrapy应该如何做-递归爬取方式,数据输出方式以及数据库链接
放假这段时间好好的思考了一下关于Scrapy的一些常用操作,主要解决了三个问题: 1.如何连续爬取 2.数据输出方式 3.数据库链接 一,如何连续爬取: 思考:要达到连续爬取,逻辑上无非从以下的方向着 ...
- (2)分布式下的爬虫Scrapy应该如何做-关于对Scrapy的反思和核心对象的介绍
本篇主要介绍对于一个爬虫框架的思考和,核心部件的介绍,以及常规的思考方法: 一,猜想 我们说的爬虫,一般至少要包含几个基本要素: 1.请求发送对象(sender,对于request的封装,防止被封) ...
- (1)分布式下的爬虫Scrapy应该如何做-安装
关于Scrapy的安装,网上一搜一大把,一个一个的安装说实话是有点麻烦,那有没有一键安装的?答案显然是有的,下面就是给神器的介绍: 主页:http://conda.pydata.org/docs/ 下 ...
- (9)分布式下的爬虫Scrapy应该如何做-关于ajax抓取的处理(一)
转载请注明出处:http://www.cnblogs.com/codefish/p/4993809.html 最近在群里频繁的被问到ajax和js的处理问题,我们都知道,现在很多的页面都是用动态加载的 ...
- 爬虫框架Scrapy之案例三图片下载器
items.py class CoserItem(scrapy.Item): url = scrapy.Field() name = scrapy.Field() info = scrapy.Fiel ...
- python爬虫实战(3)--图片下载器
本篇目标 1.输入关键字能够根据关键字爬取百度图片 2.能够将图片保存到本地文件夹 1.URL的格式 进入百度图片搜索apple,这时显示的是瀑布流版本,我们选择传统翻页版本进行爬取.可以看到网址为: ...
- 第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器 编写spiders爬虫文件循环 ...
随机推荐
- 【转】webstorm 注册码 / phpstorm 注册码
WebStorm注册码 User Name: EMBRACE License Key: ===== LICENSE BEGIN ===== 24718-12042010 00001h6wzKLpfo3 ...
- mycat初探
1:安装客户端 yum install mysql 2:安装服务端 yum install mysql-server 3:mycat要求不区分大小写 my.cnf(/etc/my.cnf)的[mysq ...
- WPF UI虚拟化
ComboBox
- Codeforces Round #177 (Div. 1) 题解【ABCD】
Codeforces Round #177 (Div. 1) A. Polo the Penguin and Strings 题意 让你构造一个长度为n的串,且里面恰好包含k个不同字符,让你构造的字符 ...
- VC++ 学习笔记(一):如何开始
毫无疑问,学习C++是一件痛苦的事情. 我大概十年前接触C++.那是在学校里,准备考研究生,某学校要求考C++.我就开始一点一点学习,学习的过程还是比较舒服的.不得不说,就古典C++的理论,钱老讲的还 ...
- Windows下修改Oracle默认的端口1521
数据库最好不对公网开放,如果要开放,最好把默认端口改掉,防止一些针对 1521端口的入侵 1.找到 product\11.2.0\dbhome_1\NETWORK\ADMIN 下面的 listene ...
- [原创]自定义控件之AndroidSegmentControlView,仿IOS平台UISegmentControlView,继承自View
版权声明:本文为博主原创文章,转载请注明出处. 控件简介 UISegmentControl在IOS平台的App中非常常见,其控件如下图所示: 这种控件的主要作用是动态的更改界面的显示内容,一般应用于内 ...
- Kafka - SQL 代码实现
1.概述 上次给大家分享了关于 Kafka SQL 的实现思路,这次给大家分享如何实现 Kafka SQL.要实现 Kafka SQL,在上一篇<Kafka - SQL 引擎分享>中分享了 ...
- js多线程?
http://www.cnblogs.com/o--ok/archive/2012/11/04/JS.html http://blog.csdn.net/nx8823520/article/detai ...
- 在 sublime text 3 中添加 Emmet (ZenCoding)
安装 Emmet 插件: 启动 Sublime Text 3,选择 Preferences>Package Control,点选 Package Control:Install Package: ...