Python+Tornado+Tampermonkey 获取某讯等主流视频网站的会员视频解析播放
近期,《哪吒之魔童降世》在各大视频软件可以看了,然而却是一贯的套路,非会员谢绝观看!!!只能从国内那些五花八门的视频网站上找着看了,或者通过之前本人说的 Chrome 的油猴插件,传送门 https://www.cnblogs.com/weijiutao/p/10608107.html,进行观看。
经过分析,通过油猴插件观看某奇艺等主流视频网站的方法其实就是在视频网页链接的前面加上一个视频解析的链接地址,如下:

播放传送门
http://jx.618g.com/?url=http://www.iqiyi.com/lib/m_217405614.html?src=search
http://www.iqiyi.com/lib/m_217405614.html?src=search
通过上面的分析,本人萌生了一个将 Tampermonkey 和 主流视频网站 联系起来的一个小工具,通过自己输入想要观看的视频,然后通过油猴插件里面的视频解析网站解析出来,效果如下:
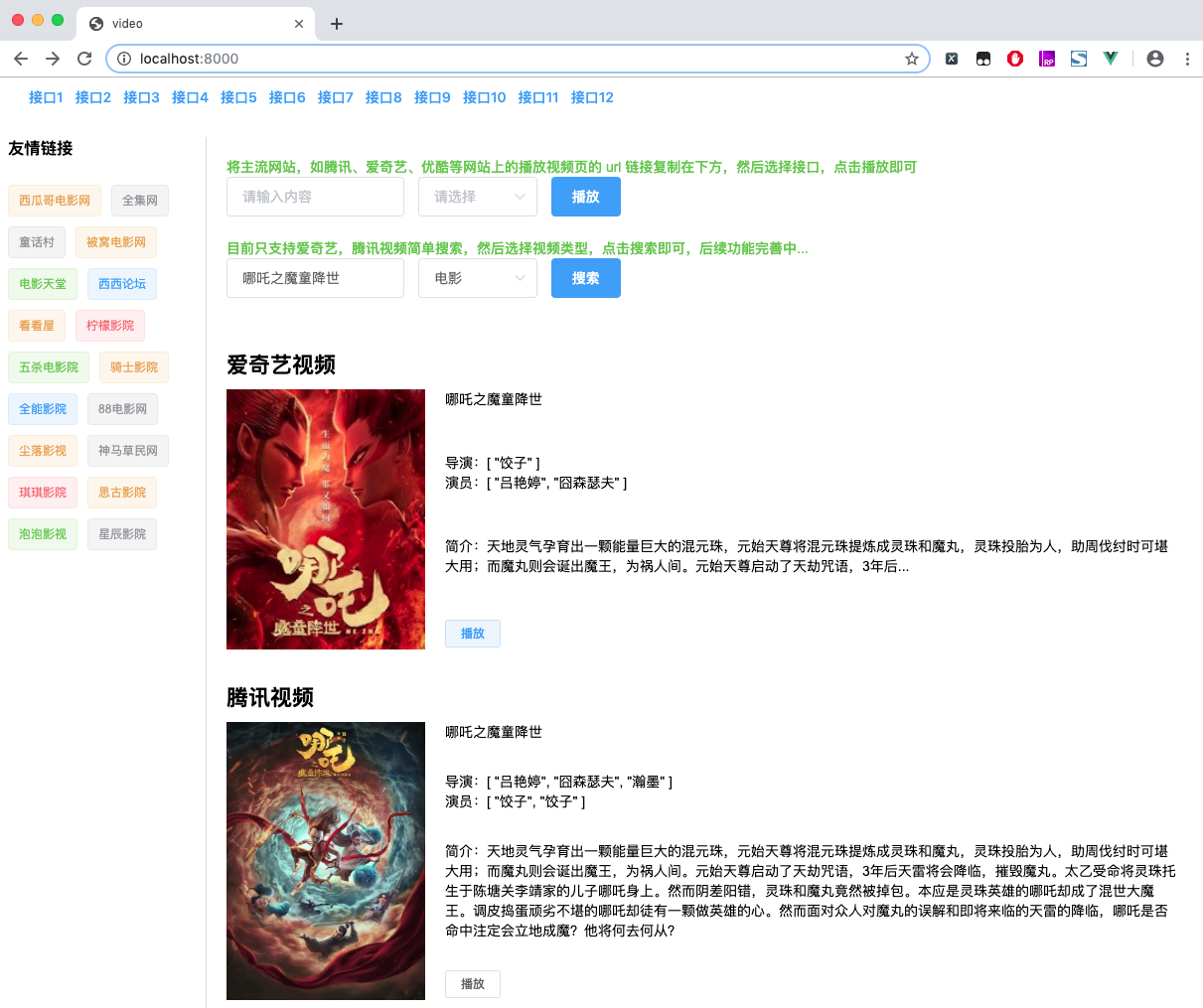
首先我们要做的就是从某奇艺等网站上获取到我们想要的视频信息,如海报,电影名,演员,导演,简介和播放链接等信息。
本人选用了 Python 语言开发,结合 Tornado 框架将想要的信息呈现到 web 页面上。目录结构如下:

项目的主入口为 app.py ,代码如下:
import tornado.web
import tornado.ioloop
import tornado.httpserver
import tornado.options
import os import spider.tv.tencent
import spider.tv.aiqiyi import spider.movie.tencent
import spider.movie.aiqiyi import spider.variety.tencent
import spider.variety.aiqiyi from tornado.options import options
from tornado.web import RequestHandler, StaticFileHandler tornado.options.define("port", type=int, default=8000, help="服务器端口") class IndexHandler(RequestHandler): # 主页处理类
def get(self):
self.render("index.html") def post(self):
self.render("index.html") class TvpalyHandler(RequestHandler):
def post(self):
name = self.get_argument("name")
type = self.get_argument("type")
if type == '':
resultTencent = spider.tv.tencent.tencents(self, name)
resultAiqiyi = spider.tv.aiqiyi.aiqiyi(self, name)
data = {
"tencent": resultTencent,
"aiqiyi": resultAiqiyi,
}
self.write(data)
elif type == '':
resultTencent = spider.movie.tencent.tencents(self, name)
resultAiqiyi = spider.movie.aiqiyi.aiqiyi(self, name)
data = {
"tencent": resultTencent,
"aiqiyi": resultAiqiyi,
}
self.write(data)
elif type == '':
resultTencent = spider.variety.tencent.tencents(self, name)
resultAiqiyi = spider.variety.aiqiyi.aiqiyi(self, name)
data = {
"tencent": resultTencent,
"aiqiyi": resultAiqiyi,
}
self.write(data) if __name__ == '__main__':
tornado.options.parse_command_line()
current_path = os.path.dirname(__file__)
app = tornado.web.Application(
[ (r'/', IndexHandler),
(r'/api/tvplay', TvpalyHandler),
(r'/(.*)', StaticFileHandler, {
"path": os.path.join(current_path, "statics/html"),
"default_filename": "index.html"
}),
],
static_path=os.path.join(current_path, "static"),
template_path=os.path.join(current_path, "template"),
debug=True,
autoescape=None
) http_server = tornado.httpserver.HTTPServer(app)
http_server.listen(options.port)
tornado.ioloop.IOLoop.current().start()
由于本人没有经过系统的 Python 学习,完全都是自学而来,所以代码中如有什么不妥之处请大神批评指正。
在上面的代码中,我们做的内容其实是接收前端发来的 POST 请求,并通过 type 类型去目录 spider 中调用不同类型的内容(电影,电视剧,综艺),上面我们在 web 页面搜索 哪吒 其实就是 type == 2 时所要做的处理,即调用目录 spider->movie 下的 aiqiyi.py 和 tencent.py,由于某酷的web页面全是动态js加载的,内容不好做处理,这里就忽略了。
我们以 aiqiyi.py 为例,tencent.py 代码其实大同小异,思路一样。代码如下:
from urllib import request, parse
from lxml import etree
import ssl # 取消 https 代理验证
ssl._create_default_https_context = ssl._create_unverified_context def aiqiyi(self, name):
# 报头
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36'
headers = {'User-Agent': user_agent}
url = "https://so.iqiyi.com/so/q_" + parse.quote(name)
req = request.Request(url, headers=headers)
try:
response = request.urlopen(req)
# 获取每页的HTML源码字符串
html = response.read().decode('utf-8')
# 解析html 为 HTML 文档
selector = etree.HTML(html) # 来源
source = "爱奇艺视频" # 剧照
pic = 'https:' + \
selector.xpath('//ul[@class="mod_result_list"]/li[1]/a//img/@src')[0] # 导演
director = selector.xpath(
"//ul[@class='mod_result_list']/li[1]//div[@class='info_item'][1]/div[@class='result_info_cont result_info_cont-half'][1]/a[@class='result_info_link']/text()")
# 主演
actor = selector.xpath(
"//ul[@class='mod_result_list']/li[1]//div[@class='info_item'][1]/div[@class='result_info_cont result_info_cont-half'][2]/a[@class='result_info_link']/text()") # 简介
desc = selector.xpath(
"//ul[@class='mod_result_list']/li[@class='list_item'][1]//div[@class='info_item'][2]//span[@class='result_info_txt']/text()")[
0] # 链接
link = selector.xpath('//ul[@class="mod_result_list"]/li[1]/a/@href')[0]
defalut_result = {
"source": source,
"name": name,
"pic": pic,
"director": director,
"actor": actor,
"desc": desc,
"list": [{'title': '播放', 'link': link}]
}
return defalut_result
except Exception:
print(url, Exception)
data = {"code": -1, "message": "error", "data": None}
return data
我们要解析的页面其实是 'https://so.iqiyi.com/so/q_' + 要搜索的内容,如下图所示:
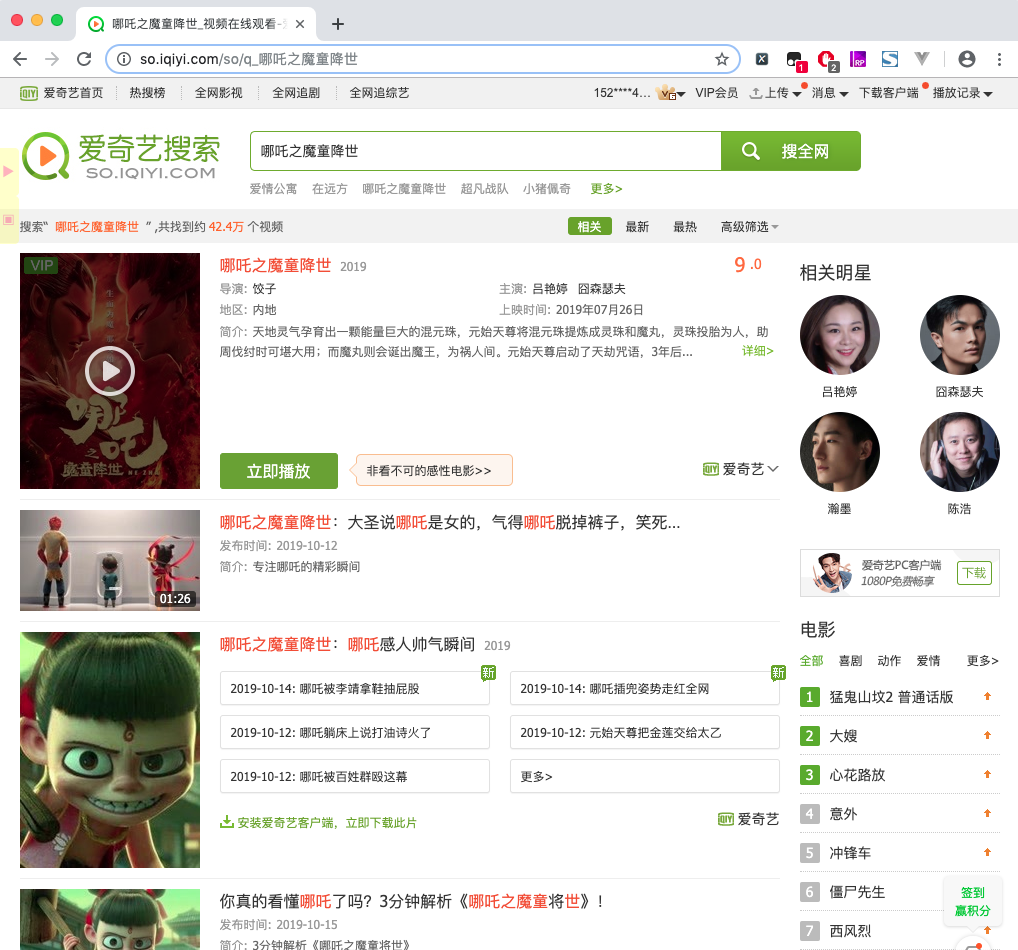
然后我们就可以通过 python 爬虫来抓取页面中的内容信息了,从上面的页面截图可以发现我们输入的搜索字其实搜索到了一些其他的信息,这些信息在提取过程中会出现很多复杂情况,所以再这里本人就只提取了第一个内容,即可以播放的 哪吒之魔童降世 的完整视频。
本人选用的是通过 xpath 的形式来抓取,具体 dom 抓取操作可以看本人之前的文章,传送门
https://www.cnblogs.com/weijiutao/p/10879871.html
https://www.cnblogs.com/weijiutao/p/10880805.html
https://www.cnblogs.com/weijiutao/p/10614694.html
通过 aiqiyi.py 我们就爬取到了我们想要的视频内容,然后将获取到的信息返回给前端页面即可,
前端页面 teplate->index.html 代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>video</title>
<link rel="stylesheet" href="/static/css/element.css">
<link rel="stylesheet" href="/static/css/style.css">
<script src="/static/js/common/vue.js"></script>
<script src="/static/js/common/axios.js"></script>
<script src="/static/js/common/element.js"></script>
<script src="/static/js/common/qs.js"></script>
<script src="/static/js/common/request.js"></script>
<script src="/static/js/common/jquery.js"></script>
</head>
<body>
<div id="app" v-cloak> <el-container>
<el-header>
<template v-for="item in apiLink">
<el-button type="text" @click="openLinkClick(item.link)">接口[[item.id]]</el-button>
</template>
</el-header>
<el-container class="main_container">
<el-aside width="200px">
<div class="friends_link">
<h3>友情链接</h3>
<template v-for="(item,index) in friendsLink">
<template v-if="index%3 ==0">
<a :href="item.link" target="_blank">
<el-tag type="warning">[[item.name]]</el-tag>
</a>
</template>
<template v-else-if="index%4 ==0">
<a :href="item.link" target="_blank">
<el-tag type="success">[[item.name]]</el-tag>
</a>
</template>
<template v-else-if="index%5 ==0">
<a :href="item.link" target="_blank">
<el-tag type="primary">[[item.name]]</el-tag>
</a>
</template>
<template v-else-if="index%7 ==0">
<a :href="item.link" target="_blank">
<el-tag type="danger">[[item.name]]</el-tag>
</a>
</template>
<template v-else>
<a :href="item.link" target="_blank">
<el-tag type="info">[[item.name]]</el-tag>
</a>
</template>
</template>
</div> </el-aside>
<el-container>
<el-main>
<el-link type="success">将主流网站,如腾讯、爱奇艺、优酷等网站上的播放视频页的 url 链接复制在下方,然后选择接口,点击播放即可</el-link>
<el-form :inline="true" :model="formCopyLink">
<el-form-item>
<el-input v-model="formCopyLink.copyLink" placeholder="请输入内容"></el-input>
</el-form-item>
<el-form-item>
<el-select style="width: 120px;" v-model="formCopyLink.apiLink" placeholder="请选择">
<el-option
v-for="item in apiLink"
:key="item.id"
:label="'接口'+item.id"
:value="item.link"
>
</el-option>
</el-select>
</el-form-item>
<el-form-item>
<el-button type="primary" @click="openCopyLinkPlayClick">播放</el-button>
</el-form-item>
</el-form>
<el-link type="success">目前只支持爱奇艺,腾讯视频简单搜索,然后选择视频类型,点击搜索即可,后续功能完善中...</el-link>
<el-form :inline="true" :model="formTv">
<el-form-item>
<el-input v-model="formTv.name" placeholder="请输入内容"></el-input>
</el-form-item>
<el-form-item>
<el-select style="width: 120px;" v-model="formTv.type" placeholder="请选择">
<el-option label="电视剧" value="1"></el-option>
<el-option label="电影" value="2"></el-option>
<el-option label="综艺" value="3"></el-option>
</el-select>
</el-form-item>
<el-form-item>
<el-button type="primary" @click="requestGetTvPlay">搜索</el-button>
</el-form-item>
</el-form> <tv-movie
:tvMovie="aiqiyiData"
@select-link="selectLinkClick"
></tv-movie> <tv-movie
:tvMovie="tencentData"
@select-link="selectLinkClick"
></tv-movie> </el-main>
<el-footer></el-footer>
</el-container>
</el-container>
</el-container> </div>
</body>
<script> Vue.component('tv-movie', {
delimiters: ["[[", "]]"],
props: ['tvmovie'],
data: function () {
return {}
},
methods: {
selectLinkChange(link) {
this.$emit('select-link', link)
}
},
template: `
<div class="tv_movie">
<template v-if="tvmovie">
<h3 class="tv_movie_source">[[tvmovie.source]]</h3>
<div class="tv_movie_content">
<div class="tv_movie_content_left">
<el-image :src="tvmovie.pic"></el-image>
</div>
<div class="tv_movie_content_right">
<div>
<p>[[tvmovie.name]]</p>
</div>
<div>
<p>导演:[[tvmovie.director]]</p>
<p>演员:[[tvmovie.actor]]</p>
</div>
<div>
<p>简介:[[tvmovie.desc]]</p>
</div>
<div>
<template v-for="item in tvmovie.list">
<el-button size="mini" @click="selectLinkChange(item.link)">[[item.title]]
</el-button>
</template>
</div>
</div>
</div>
</template>
</div> `
}) let app = new Vue({
delimiters: ["[[", "]]"],
el: "#app",
data: {
formCopyLink: {
copyLink: "",
apiLink: "",
},
formTv: {
name: "",
type: "1",
},
apiLink: [],
friendsLink: [],
aiqiyiData: null,
tencentData: null,
selectLink: null,
},
mounted() {
this.requestGetMockApiLink();
this.requestGetMockFriendsLink();
},
methods: {
requestGetTvPlay() {
if (!this.formTv.name) return this.$message.warning("请输入要播放的内容");
let data = {...this.formTv};
requestFunc(null, '/api/tvplay', data, (data) => {
if (!data.aiqiyi) this.$message.warning("爱奇艺没搜到数据");
if (!data.tencent) this.$message.warning("腾讯没搜到数据");
this.aiqiyiData = data.aiqiyi;
this.tencentData = data.tencent;
})
},
requestGetMockApiLink() {
requestFunc('get', '/static/mock/apiLink.json', null, (data) => {
this.apiLink = data;
})
},
requestGetMockFriendsLink() {
requestFunc('get', '/static/mock/friendsLink.json', null, (data) => {
this.friendsLink = data;
})
},
selectLinkClick(link) {
this.selectLink = link;
},
openLinkClick(link) {
if (!this.selectLink) return this.$message.warning("请选择要播放的剧集");
window.open(link + this.selectLink, '_blank');
},
openCopyLinkPlayClick() {
if (!this.formCopyLink.copyLink) return this.$message.warning("请输入要播放 url 链接");
if (!this.formCopyLink.apiLink) return this.$message.warning("请选择要播放的接口");
window.open(this.formCopyLink.apiLink + this.selectLink, '_blank');
} },
}); </script>
</html>
在上面的代码中,我们使用了 vue+elementUi 来写前端的代码,并且引入了一些本人所知道的一些五花八门的视频网站的友情链接,其中这些友情链接和 Tampermonkey 中的视频解析链接存在了本地的文件 static->mock 的 json 文件中。
就此,一个简单的破解VIP视频的小工具就完成了。有需要代码可以去码云上查看:https://gitee.com/vijtor/video。
声明:上面的代码只是一个简单的实现思路,代码中如有不妥之处请大神批评指正!同时本人严正声明尊重知识产权和版权,对于上面的敏感信息不做任何商业用途,如有侵权问题请及时联系本人,蟹蟹!!!
Python+Tornado+Tampermonkey 获取某讯等主流视频网站的会员视频解析播放的更多相关文章
- python + selenium + PhantomJS 获取腾讯应用宝APP评论
PhantomJS PhantomJS 是一个基于WebKit的服务器端JavaScript API,它无需浏览器的支持即可实现对Web的支持,且原生支持各种Web标准,如DOM 处理.JavaScr ...
- 视频下载四大神器—如何下载优酷/爱奇艺/腾讯/B站超清无水印视频
视频下载四大神器—如何下载优酷/爱奇艺/腾讯/B站超清无水印视频 2018-07-11 | 标签»下载, 下载工具, 视频 又是视频下载,老生常谈的话题.阿刚同学已在乐软博客多次与大家分享推荐 ...
- python tornado websocket 多聊天室(返回消息给部分连接者)
python tornado 构建多个聊天室, 多个聊天室之间相互独立, 实现服务器端将消息返回给相应的部分客户端! chatHome.py // 服务器端, 渲染主页 --> 聊天室建立web ...
- 获取腾讯soso地图坐标代码
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- python执行shell获取硬件参数写入mysql
最近要获取服务器各种参数,包括cpu.内存.磁盘.型号等信息.试用了Hyperic HQ.Nagios和Snmp,它们功能都挺强大的,但是于需求不是太符,亦或者太heavy. 于是乎想到用python ...
- 运用Python语言编写获取Linux基本系统信息(三):Python与数据库编程,把获取的信息存入数据库
运用Python语言编写获取Linux基本系统信息(三):Python与数据库编程 有关前两篇的链接: 运用Python语言编写获取Linux基本系统信息(一):获得Linux版本.内核.当前时间 运 ...
- 运用Python语言编写获取Linux基本系统信息(二):文件系统使用情况获取
本文跟着上一篇文章继续写,上一篇文章的链接 运用Python语言编写获取Linux基本系统信息(一):获得Linux版本.内核.当前时间 一.随便说说 获取文件系统使用情况的思路和上一篇获取主要系统是 ...
- Python 通过脚本获取Android的apk的部分属性,再通过加密算法生成秘钥。
Python 通过脚本获取Android的apk的部分属性,再通过加密算法生成秘钥. #!/usr/bin/env python # -*- coding: utf- -*- import os im ...
- python使用traceback获取详细的异常信息
原创来自:https://blog.csdn.net/mengtao0609/article/details/55049059 python使用traceback获取详细的异常信息 2017年02月1 ...
随机推荐
- ASP.NET CORE Docker发布记录
1.安装Docker yum install curl -y curl -fsSL https://get.docker.com/ | sh 2.编写Dockerfile文件 FROM microso ...
- 除了FastJson,你还有选择: Gson简易指南
前言 这个周末被几个技术博主的同一篇公众号文章 fastjson又被发现漏洞,这次危害可导致服务瘫痪! 刷屏,离之前漏洞事件没多久,fastjson 又出现严重 Bug.目前项目中不少使用了 fast ...
- 快速构建第一个Flink工程
本文简述通过maven和gradle快速构建的Flink工程.建议安装好Flink以后构建自己的Flink项目,安装与示例运行请查看:Flink快速入门--安装与示例运行. 在安装好Flink以后,只 ...
- buuctf 随便注 writeup
1.0 打开页面 显然这个题的考点是注入,那我们来测一下 2.0 sql注入测试 1 2 输入 1' 后发现没有回显,改为 1' --+ 后,有回显,应该在这存在注入点 试一下 1' and 1=1 ...
- angular关于Bootstrap样式不起作用问题
跟着慕课网的课程学习Angular,简直要被bootstrap的问题整死了,样式一直出不来,导航完全没有背景颜色.. 我在网上找了很多都试了,以下方法特别受用 1.把 "../node_mo ...
- 小白的消费为何被迫升级?-java数据类型的转换
背景 小白最近有点烦恼,原因也很简单,不知道为何?小白的消费不知不觉被迫升级了,请看费用清单: for (byte b = Byte.MIN_VALUE; b < Byte.MAX_VALUE; ...
- 3.httphandler和httpmodule各种的作用以及工作原理?
首先应该知道的是ASP.NET 请求处理过程是基于管道模型的,这个管道模型是由多个HttpModule和HttpHandler组成,ASP.NET 把http请求依次传递给管道中各个HttpModul ...
- Java的初始化块及执行过程详解
问题:Java对象初始化方式主要有哪几种?分别是什么?针对上面的问题,想必大家脑海中首先浮现出的答案是构造器,没错,构造器是Java中常用的对象初始化方式. 还有一种与构造器作用非常相似的是初始化块, ...
- 百度地图WEB端判断用户是否在网格范围内
在pc端设置商家的配送范围,用户在下单时,根据用户设置的配送地点判断是否在可配送范围内,并给用户相应的提示. 下面说下我的实现思路: 1.用百度地图在PC端设置配送范围,可拖拽选择 2.根据用户设置的 ...
- Android开发--Intent的使用(1)启动活动
Android系统是目前世界上市场占有率最高的移动操作系统,近年来,Android开发也越来越炙手可热. 在Android开发中,我们使用Intent进行活动Activity之间穿梭. 当我们点击启动 ...