scrapy实战1分布式爬取有缘网(6.22接口已挂):
直接上代码:
items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy class YouyuanwangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 个人头像链接
header_url=scrapy.Field()
# 用户名
username=scrapy.Field()
# 内心独白
monologue=scrapy.Field()
# 相册图片链接
pic_urls=scrapy.Field()
#籍贯
place_from=scrapy.Field()
#学历
education=scrapy.Field()
# 年龄
age=scrapy.Field()
#身高
height=scrapy.Field()
#工资
salary=scrapy.Field()
#兴趣爱好
hobby=scrapy.Field()
# 网站来源 youyuan
source=scrapy.Field()
# 个人主页源url
source_url=scrapy.Field()
# 爬虫名
spider=scrapy.Field()
spiders >yuoyuan.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import Rule
from scrapy_redis.spiders import RedisCrawlSpider
from youyuanwang.items import YouyuanwangItem # class YouyuanSpider(CrawlSpider):
class youyuan(RedisCrawlSpider):
name = 'youyuan'
# allowed_domains = ['www.youyuan.com']
# 有缘网的列表页
# start_urls = ['http://www.youyuan.com/find/beijing/mm18-25/advance-0-0-0-0-0-0-0/p1/']
redis_key = 'youyuan:start_urls'
#动态域范围的获取
def __init__(self, *args, **kwargs):
# Dynamically define the allowed domains list.
domain = kwargs.pop('domain', '')
self.allowed_domains = filter(None, domain.split(','))
super(youyuan, self).__init__(*args, **kwargs)
#匹配全国
#list_page = LinkExtractor(allow=(r'http://www.youyuan.com/find/.+'))
# 只匹配北京、18~25岁、女性 的 搜索页面匹配规则,根据response提取链接
page_links=LinkExtractor(allow=r"http://www.youyuan.com/find/beijing/mm18-25/advance-0-0-0-0-0-0-0/p\d+/")
# 个人主页 匹配规则,根据response提取链接
profile_page=LinkExtractor(allow=r"http://www.youyuan.com/\d+-profile/") rules = (
# 匹配列表页成功,跟进链接,跳板
Rule(page_links),
# 匹配个人主页的链接,形成request保存到redis中等待调度,一旦有响应则调用parse_profile_page()回调函数处理,不做继续跟进
Rule(profile_page,callback="parse_profile_page",follow=False)
) # 处理个人主页信息,得到我们要的数据
def parse_profile_page(self, response):
item=YouyuanwangItem()
# 个人头像链接
item['header_url']=self.get_header_url(response)
# 用户名
item['username']=self.get_username(response)
#籍贯
item['place_from']=self.get_place_from(response)
#学历
item['education']=self.get_education(response) # 年龄
item['age']=self.get_age(response)
# 身高
item['height']=self.get_height(response)
# 工资
item['salary']=self.get_salary(response)
# 兴趣爱好
item['hobby']=self.get_hobby(response)
# 相册图片链接
item['pic_urls'] = self.get_pic_urls(response)
# 内心独白
item['monologue'] = self.get_monologue(response)
# 个人主页源url
item['source_url']=response.url
# 网站来源 youyuan
item['source']="youyuan"
# 爬虫名
item['spider']="youyuan"
yield item
#提取头像地址
def get_header_url(self,response):
header=response.xpath('//dl[@class="personal_cen"]/dt/img/@src').extract()
if len(header):
header_url=header[0]
else:
header_url= ""
return header_url.strip()
#提取用户名
def get_username(self,response):
username=response.xpath('//dl[@class="personal_cen"]/dd//div[@class="main"]/strong/text()').extract()
if len(username):
username=username[0]
else:
username=""
return username.strip()
#提取年龄
def get_age(self,response):
age=response.xpath('//dl[@class="personal_cen"]//p[@class="local"]/text()').extract()
if len(age):
age=age[0].split()[1]
else:
age=""
return age
#提取身高
def get_height(self,response):
height=response.xpath('//div[@class="pre_data"]/ul/li[2]/div/ol[2]/li[2]/span/text()').extract()
if len(height):
height=height[0]
else:
height="" return height.strip()
#提取工资
def get_salary(self,response):
salary=response.xpath('//div[@class="pre_data"]/ul/li[2]/div/ol[1]/li[4]/span/text()').extract()
if len(salary):
salary=salary[0]
else:
salary=""
return salary.strip()
#提取兴趣爱好
def get_hobby(self,response):
hobby=response.xpath('//dl[@class="personal_cen"]//ol[@class="hoby"]//li/text()').extract()
if len(hobby):
hobby=",".join(hobby).replace(" ","")
else:
hobby=""
return hobby.strip()
#提取相册图片
def get_pic_urls(self,response):
pic_urls=response.xpath('//div[@class="ph_show"]/ul/li/a/img/@src').extract()
if len(pic_urls):
pic_urls=",".join(pic_urls)
#将相册url列表转换成字符串
else:
pic_urls=""
return pic_urls
#提取内心独白
def get_monologue(self,response):
monologue=response.xpath('//div[@class="pre_data"]/ul/li/p/text()').extract()
if len(monologue):
monologue=monologue[0]
else:
monologue=""
return monologue.strip()
#提取籍贯
def get_place_from(self,response):
place_from=response.xpath('//div[@class="pre_data"]/ul/li[2]/div/ol[1]/li[1]/span/text()').extract()
if len(place_from):
place_from=place_from[0]
else:
place_from=""
return place_from.strip()
#提取学历
def get_education(self,response):
education=response.xpath('//div[@class="pre_data"]/ul/li[2]/div/ol[1]/li[3]/span/text()').extract()
if len(education):
education=education[0]
else:
education=""
return education.strip()
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import Rule,CrawlSpider
#from scrapy_redis.spiders import RedisCrawlSpider
from youyuanwang.items import YouyuanwangItem class YouyuanSpider(CrawlSpider):
#class YouyuanSpider(RedisCrawlSpider):
name = 'youyuan'
allowed_domains = ['www.youyuan.com']
# 有缘网的列表页
start_urls = ['http://www.youyuan.com/find/beijing/mm18-25/advance-0-0-0-0-0-0-0/p1/']
#redis_key = 'YouyuanSpider:start_urls'
#动态域范围的获取
# def __init__(self, *args, **kwargs):
# # Dynamically define the allowed domains list.
# domain = kwargs.pop('domain', '')
# self.allowed_domains = filter(None, domain.split(','))
# super(YouyuanSpider, self).__init__(*args, **kwargs)
#匹配全国
#list_page = LinkExtractor(allow=(r'http://www.youyuan.com/find/.+'))
# 只匹配北京、18~25岁、女性 的 搜索页面匹配规则,根据response提取链接
page_links=LinkExtractor(allow=r"http://www.youyuan.com/find/beijing/mm18-25/advance-0-0-0-0-0-0-0/p\d+/")
# 个人主页 匹配规则,根据response提取链接
profile_page=LinkExtractor(allow=r"http://www.youyuan.com/\d+-profile/") rules = (
# 匹配列表页成功,跟进链接,跳板
Rule(page_links),
# 匹配个人主页的链接,形成request保存到redis中等待调度,一旦有响应则调用parse_profile_page()回调函数处理,不做继续跟进
Rule(profile_page,callback="parse_profile_page",follow=False)
) # 处理个人主页信息,得到我们要的数据
def parse_profile_page(self, response):
item=YouyuanwangItem()
# 个人头像链接
item['header_url']=self.get_header_url(response)
# 用户名
item['username']=self.get_username(response)
#籍贯
item['place_from']=self.get_place_from(response)
#学历
item['education']=self.get_education(response) # 年龄
item['age']=self.get_age(response)
# 身高
item['height']=self.get_height(response)
# 工资
item['salary']=self.get_salary(response)
# 兴趣爱好
item['hobby']=self.get_hobby(response)
# 相册图片链接
item['pic_urls'] = self.get_pic_urls(response)
# 内心独白
item['monologue'] = self.get_monologue(response)
# 个人主页源url
item['source_url']=response.url
# 网站来源 youyuan
item['source']="youyuan"
# 爬虫名
item['spider']="youyuan"
yield item
#提取头像地址
def get_header_url(self,response):
header=response.xpath('//dl[@class="personal_cen"]/dt/img/@src').extract()
if len(header):
header_url=header[0]
else:
header_url= ""
return header_url.strip()
#提取用户名
def get_username(self,response):
username=response.xpath('//dl[@class="personal_cen"]/dd//div[@class="main"]/strong/text()').extract()
if len(username):
username=username[0]
else:
username=""
return username.strip()
#提取年龄
def get_age(self,response):
age=response.xpath('//dl[@class="personal_cen"]//p[@class="local"]/text()').extract()
if len(age):
age=age[0].split()[1]
else:
age=""
return age
#提取身高
def get_height(self,response):
height=response.xpath('//div[@class="pre_data"]/ul/li[2]/div/ol[2]/li[2]/span/text()').extract()
if len(height):
height=height[0]
else:
height="" return height.strip()
#提取工资
def get_salary(self,response):
salary=response.xpath('//div[@class="pre_data"]/ul/li[2]/div/ol[1]/li[4]/span/text()').extract()
if len(salary):
salary=salary[0]
else:
salary=""
return salary.strip()
#提取兴趣爱好
def get_hobby(self,response):
hobby=response.xpath('//dl[@class="personal_cen"]//ol[@class="hoby"]//li/text()').extract()
if len(hobby):
hobby=",".join(hobby).replace(" ","")
else:
hobby=""
return hobby.strip()
#提取相册图片
def get_pic_urls(self,response):
pic_urls=response.xpath('//div[@class="ph_show"]/ul/li/a/img/@src').extract()
if len(pic_urls):
pic_urls=",".join(pic_urls)
#将相册url列表转换成字符串
else:
pic_urls=""
return pic_urls
#提取内心独白
def get_monologue(self,response):
monologue=response.xpath('//div[@class="pre_data"]/ul/li/p/text()').extract()
if len(monologue):
monologue=monologue[0]
else:
monologue=""
return monologue.strip()
#提取籍贯
def get_place_from(self,response):
place_from=response.xpath('//div[@class="pre_data"]/ul/li[2]/div/ol[1]/li[1]/span/text()').extract()
if len(place_from):
place_from=place_from[0]
else:
place_from=""
return place_from.strip()
#提取学历
def get_education(self,response):
education=response.xpath('//div[@class="pre_data"]/ul/li[2]/div/ol[1]/li[3]/span/text()').extract()
if len(education):
education=education[0]
else:
education=""
return education.strip()
pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
# import json
#
# class YouyuanwangPipeline(object):
# def __init__(self):
# self.filename=open("youyuanwang.json","wb")
# def process_item(self, item, spider):
# jsontext=json.dumps(dict(item),ensure_ascii=False) + ",\n"
# self.filename.write(jsontext.encode("utf-8"))
# return item
# def close_spider(self,spider):
# self.filename.close() import pymysql
from .models.es_types import YouyuanType
class XiciPipeline(object):
def process_item(self, item, spider):
# DBKWARGS=spider.settings.get('DBKWARGS')
con=pymysql.connect(host='127.0.0.1',user='root',passwd='',db='yunyuan',charset='utf8')
cur=con.cursor()
sql=("insert into youyuanwang(header_url,username,monologue,pic_urls,place_from,education,age,height,salary,hobby,source)"
"VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)")
lis=(item['header_url'],item['username'],item['monologue'],item['pic_urls'],item['place_from'],item['education'],item['age'],item['height'],item['salary'],item['hobby'],item['source']) cur.execute(sql,lis)
con.commit()
cur.close()
con.close()
return item class ElasticsearchPipeline(object):
def process_item(self,item,spider):
youyuan = YouyuanType()
youyuan.header_url=item["header_url"]
youyuan.username=item["username"]
youyuan.age=item["age"]
youyuan.salary=item["salary"]
youyuan.monologue=item["monologue"]
youyuan.pic_urls=item["pic_urls"]
youyuan.place_from=item["place_from"] youyuan.save() return item
settings.py
# -*- coding: utf-8 -*- # Scrapy settings for youyuanwang project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html BOT_NAME = 'youyuanwang' SPIDER_MODULES = ['youyuanwang.spiders']
NEWSPIDER_MODULE = 'youyuanwang.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'youyuanwang (+http://www.yourdomain.com)' # Obey robots.txt rules
#ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default)
#COOKIES_ENABLED = False # Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False # Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#} # Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'youyuanwang.middlewares.YouyuanwangSpiderMiddleware': 543,
#} # Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'youyuanwang.middlewares.MyCustomDownloaderMiddleware': 543,
#} # Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True # Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
#'youyuanwang.pipelines.XiciPipeline': 300,
'youyuanwang.pipelines.ElasticsearchPipeline': 300,
# 'scrapy_redis.pipelines.RedisPipeline':400,
} # Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
从redis保存到mongodb 在目录下新建文件process_item_mongo.py(名字随便取)
#coding=utf-8 import pymongo
import redis
import json def process_item():
Redis_conn=redis.StrictRedis(host='127.0.0.1',port=6379,db=0)
Mongo_conn=pymongo.MongoClient(host='127.0.0.1',port=27017)
db=Mongo_conn["youyuan"]
table=db["beijing_18_25"]
while True:
source, data = Redis_conn.blpop(["youyuan:items"])
data = json.loads(data.decode("utf-8"))
table.insert(data)
if __name__=="__main__":
process_item()
从redis保存到mysql 在目录下新建文件process_item_mysql.py(名字随便取)
#coding=utf-8 import pymysql
import redis
import json def process_item():
Redis_conn=redis.StrictRedis(host='127.0.0.1',port=6379,db=0)
MySql_conn=pymysql.connect(host='127.0.0.1',user='root',passwd='',port=3306,db='yunyuan')
while True:
source,data=Redis_conn.blpop("youyuan:items")
data=json.loads(data.decode("utf-8"))
cur=MySql_conn.cursor()
sql=("insert into youyuanwang(header_url,username,monologue,pic_urls,place_from,education,age,height,salary,hobby,source)"
"VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)")
lis = (data['header_url'], data['username'], data['monologue'], data['pic_urls'], data['place_from'],
data['education'], data['age'], data['height'], data['salary'], data['hobby'], data['source'])
cur.execute(sql,lis)
MySql_conn.commit()
cur.close()
MySql_conn.close()
if __name__=="__main__":
process_item()
数据:
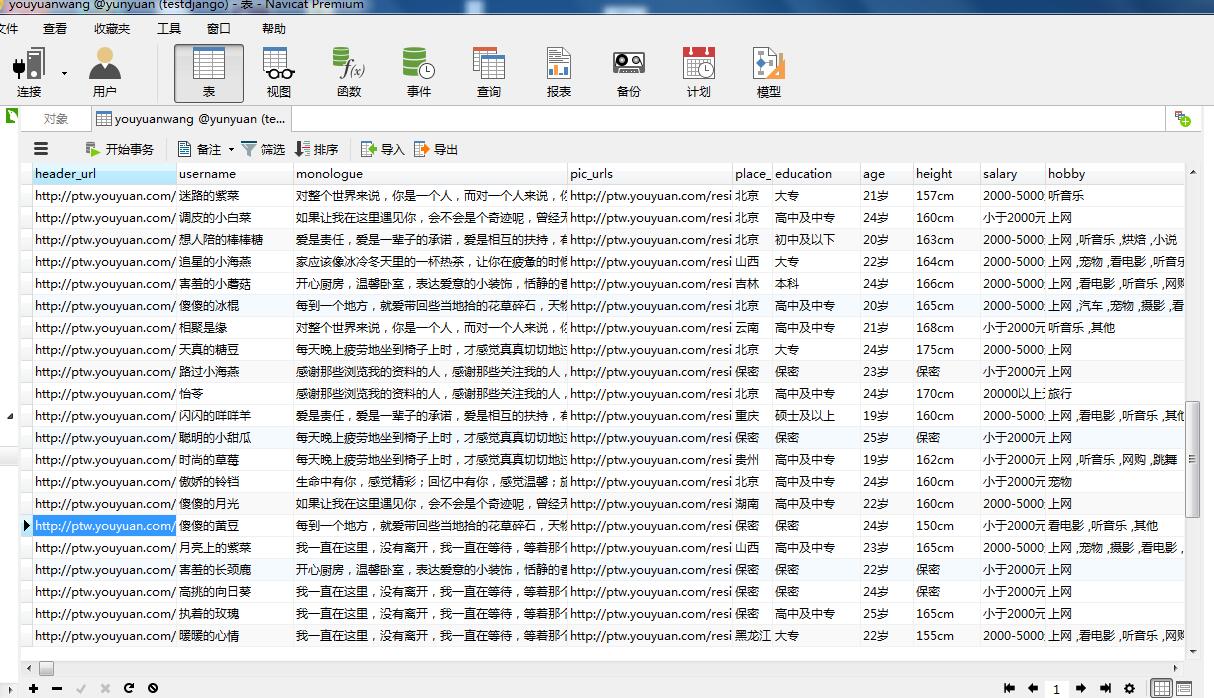
申明:以上只限于参考学习交流!!! 更多:https://github.com/huwei86/Spideryouyuanwang
scrapy实战1分布式爬取有缘网(6.22接口已挂):的更多相关文章
- scrapy实战2分布式爬取lagou招聘(加入了免费的User-Agent随机动态获取库 fake-useragent 使用方法查看:https://github.com/hellysmile/fake-useragent)
items.py # -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentati ...
- scrapy项目3:爬取当当网中机器学习的数据及价格(spider类)
1.网页解析 当当网中,人工智能数据的首页url如下为http://category.dangdang.com/cp01.54.12.00.00.00.html 点击下方的链接,一次观察各个页面的ur ...
- Python爬虫基础--分布式爬取贝壳网房屋信息(Client)
1. client_code01 2. client_code02 3. 这个时候运行多个client就可以分布式进行数据爬取.
- scrapy项目4:爬取当当网中机器学习的数据及价格(CrawlSpider类)
scrapy项目3中已经对网页规律作出解析,这里用crawlspider类对其内容进行爬取: 项目结构与项目3中相同如下图,唯一不同的为book.py文件 crawlspider类的爬虫文件book的 ...
- scrapy实战--登陆人人网爬取个人信息
今天把scrapy的文档研究了一下,感觉有点手痒,就写点东西留点念想吧,也做为备忘录.随意写写,看到的朋友觉得不好,不要喷我哈. 创建scrapy工程 cd C:\Spider_dev\app\scr ...
- Python爬虫基础--分布式爬取贝壳网房屋信息(Server)
1. server_code01 2. server_code02 3. server_code03
- 爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序 下面我们尝试爬取全书网中网游动漫类小说的书籍信息. 一.准备阶段 明确一下爬虫页面分析的思路: 对于书籍列表页:我们需要知道打开单本书籍 ...
- Scrapy爬虫(5)爬取当当网图书畅销榜
本次将会使用Scrapy来爬取当当网的图书畅销榜,其网页截图如下: 我们的爬虫将会把每本书的排名,书名,作者,出版社,价格以及评论数爬取出来,并保存为csv格式的文件.项目的具体创建就不再多讲 ...
- Scrapy 分布式爬取
由于受到计算机能力和网络带宽的限制,单台计算机运行的爬虫咋爬取数据量较大时,需要耗费很长时间.分布式爬取的思想是“人多力量大”,在网络中的多台计算机同时运行程序,公童完成一个大型爬取任务, Scrap ...
随机推荐
- 华为开发者论坛FusionStage版块
FusionStage版块 http://developer.huawei.com/ict/forum/forum.php?mod=forumdisplay&fid=400191&pa ...
- OnPropertyChanged的使用
#region INotifyPropertyChanged public event PropertyChangedEventHandler PropertyChanged; ...
- Android permission 动态申请、授权
原文:Android permission 动态申请.授权 Android permission 新特性深度学习 本篇文章介绍android permission系统,并介绍android 6.0 p ...
- Expression Blend学习四控件
原文:Expression Blend学习四控件 Expression Blend制作自定义按钮 1.从Blend工具箱中添加一个Button,按住shift,将尺寸调整为125*125; 2.右键点 ...
- 【Git】打标签
打标签 同大多数 VCS 一样,Git 也可以对某一时间点上的版本打上标签.人们在发布某个软件版本(比如 v1.0 等等)的时候,经常这么做.本节我们一起来学习如何列出所有可用的标签,如何新建标签,以 ...
- 快速写入Xml文件
我们在做一些操作的时候会需要生成日志,Xml文件就是我们常用的一种日志文件. 普通操作Xml文件的代码遇到大数据量的话就很慢了. 用这个生成Xml文件的话,即使数据量很大,也很快 private vo ...
- Android零基础入门第78节:四大组件的纽带——Intent
前面学习Activity时己经多次使用了 Intent,当一个Activity需要启动另一个Activity时, 程序并没有直接告诉系统要启动哪个Activity,而是通过Intent来表达自己的意图 ...
- 手机软件没过多久就删了 APP到底得了什么病?
直击现场 PC互联网时代正渐行渐远,移动互联网的创业浪潮汹涌而至.2014年,中国成为拥有智能手机用户最多的国家,而疯狂生长的APP正占据新的风口.据了解,目前我国主要应用商店的APP已累计超过400 ...
- Delphi xe5 StyleBook的用法(待续)
首先要在FORM里拖进来一个StyleBook1,然后在Form里设置属性,记住一定要在单击form,在OBject Inspector里设置StyleBook [StyleBook1]. 下一个属 ...
- 用C实现OOP面向对象编程(1)
如摘要所说,C语言不支持OOP(面向对象的编程).并这不意味着我们就不能对C进行面向对象的开发,只是过程要复杂许多.原来以C++的许多工作,在C语言中需我们手动去完成. 博主将与大家一起研究一下如下用 ...