单机版ZooKeeper的安装教程
之前一直没有时间去整理,现在抽出几分钟时间整理以下,有问题的在评论区留言即可。
前期准备JDK环境(ZK需要jdk进行编译,本文以jdk1.8.0_211为例)、Linux系统(本文以Centos7为例)、zookeeper安装包(通过zookeeper官网下载,本文以3.5.5版本为例)。
Zookeeper的安装(使用安装包,否则无法启动)
1、下载zookeeper安装包
进入zookeeper官网选择下载链接如下: https://www-eu.apache.org/dist/zookeeper/
选择最新稳定版本3.5.5,选择下载apache-zookeeper-3.5.5-bin.tar.gz,文件说明:
1)apache-zookeeper-3.5.5.tar.gz 源码包
2)apache-zookeeper-3.5.5-bin.tar.gz 安装包
或者直接通过
wget http://mirror.bit.edu.cn/apache/zookeeper/current/apache-zookeeper-3.5.5-bin.tar.gz 下载安装包。
解压完成后 进入我们的Linux下/etc/profile文件增加环境变量: export ZOOKEEPER_HOME=zookeeper安装路径,并加入PATH下

如图所示,完成后保存退出,至此zk的安装告一段落(注意此时zookeeper还不能启动 需要更改zk.cfg(zoo_sample.cfg))。
zookeeper目录结构
- bin 常用命令
- conf 存放配置文件,其中我们需要修改zk.cfg(zoo_sample.cfg)
- docs 存放帮助文档信息
- lib 需要依赖的jat包
zookeeper的配置文件信息(zoo_sample.cfg)
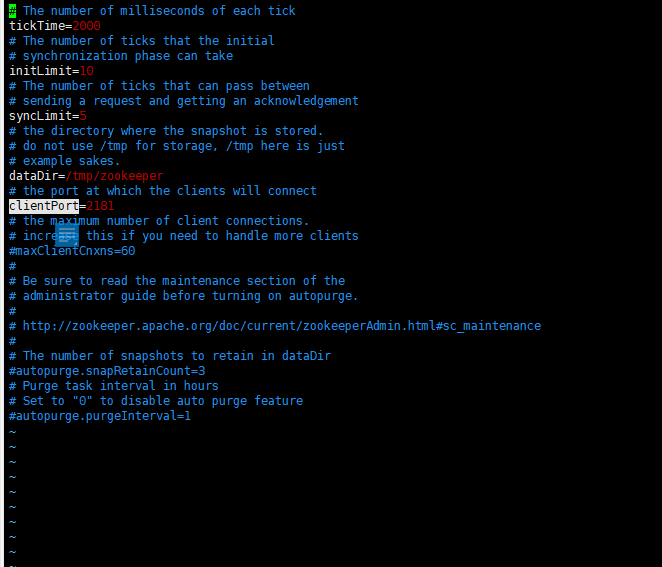
tickTime 用于计算的基本时间单元,所有时间设置都是tickTime的倍数,单位为毫秒。当为session超时设置5的时候 则真实session超时时间为5*tickTime
initLimit 用于集群,允许 “从节点” 连接 并同步 到 “master节点” 的初始化连接时间,以tickTime的倍数表示
syncLimit 用于集群,在运行过程中,“master节点” 负责与ZK集群中所有机器进行通信,例如通过一些心跳检测机制,来检测机器的存活状态。如果“master节点” 发出心跳包在syncLimit之后,还没有从“从节点”收到响应,那么就认为这个 “从节点”已经不在线了将其抛弃。因此不要把这个参数设置得过大,否则可能会掩盖一些问题。(No Java system property)
dataDir 存放数据文件的目录,必须配置(当“日志目录”dataLogDir没有配置时则默认此地址为log文件存放地址)
clientPort 连接服务器的端口,默认2181
配置文件修改完毕后重命名为“zoo.cfg” ,否则运行时会提示 zoo.cfg: No such file or directory
单机ZOOKEEPER的运行
- 完成上述配置之后来到我们的bin目录下可以运行我们的zk
命令:./zkServer.sh start 启动ZK
命令:./zkServer.sh status查看当前zk的运行状态信息
出现 :
Client port found: 2181. Client address: localhost.
以上就是单机的zookeeper安装教程,本文有不足的地方希望大家可以在评论区多多讨论,感谢。
单机版ZooKeeper的安装教程的更多相关文章
- JDK+Tomcat+Zookeeper+DubboAdmin安装教程
JDK+Tomcat+Zookeeper+DubboAdmin安装教程 1. 安装内容: JDK 1.8.131 Tomcat 7.0.77 Zookeeper 3.4.9 Dubbo admin 2 ...
- 【zookeeper】安装教程文档需下载
请查看文件https://download.csdn.net/download/qq_42158942/11846847 zookeeper的作用 • ZooKeeper 是一个开源的分布式协调服务, ...
- Hive/Hbase/Sqoop的安装教程
Hive/Hbase/Sqoop的安装教程 HIVE INSTALL 1.下载安装包:https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-2.3 ...
- Linux下Kafka下载与安装教程
原文链接:http://www.studyshare.cn/software/details/1176/0 一.预备环境 Kafka是java生态圈中的一员,运行在java虚拟机上,按Kafka官方说 ...
- mysql 和 hive 和分布式zookeeper和HBASE分布式安装教程
一,mysql 安装mysql5.7完整教程1. yum -y install mysql-server直接执行语句后等待就好已安装: mysql-community-server.x86_64 0: ...
- Linux下zookeeper下载与安装教程
原文连接:(http://www.studyshare.cn/blog-front//blog/details/1169/0)一.下载 官网下载:点这里 百度网盘下载:点这里 官网下载图示: jav ...
- Hadoop、Zookeeper、Hbase分布式安装教程
参考: Hadoop安装教程_伪分布式配置_CentOS6.4/Hadoop2.6.0 Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS ZooKeeper-3.3 ...
- zookeeper的安装和启动教程
zookeeper的安装和启动 zookeeper安装包所在目录: 上传文件到虚拟机.现在本地新建一个目录setup,将zookeeper压缩包复制进去. ALT+P打开一个标签,操作如下put命令. ...
- windows下 zookeeper dubbo 安装+配置+demo 详细图文教程
Java集群优化——dubbo+zookeeper构建 互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服务架构以及流动计算架构势在必行,Dubbo是一个分布式服务框架,在这 ...
随机推荐
- websocket实现群聊和单聊(转)
昨日内容回顾 1.Flask路由 1.endpoint="user" # 反向url地址 2.url_address = url_for("user") 3.m ...
- 西门子 S7-300 PLC 从入门到精通的100个经典问题
1:使用CPU 315F和ET 200S时应如何避免出现“通讯故障”消息? 使用CPU S7 315F, ET 200S以及故障安全DI/DO模块,那么您将调用OB35 的故障安全程序.而且,您已 ...
- 6.秋招复习简单整理之请你谈谈JDBC的反射,以及它的作用?
通过反射com.mysql.jdbc.Driver类,实例化该类时会调用该类的静态代码块,该代码块会去java的DriverManager类中注册自己,DriverManager管理所有已注册的驱动类 ...
- java字符串的替换replace、replaceAll、replaceFirst的区别
看代码: String s = "my.test.txt"; System.out.println(s.replace(".", "#")) ...
- 关于Linux服务器配置java环境遇到的问题
关于Linux服务器配置java环境遇到的问题 将下载好的JDK安装包解压到/etc/local/路径下,安装完后用vim/etc/profile文件,在文件末尾添加 export JAVA_HOME ...
- Java+eclipse技巧小总结
首先是打开Content Assistant,自动代码补全 Window -> Preferences -> Java -> Editor -> Content Assist, ...
- 【Phabricator】教科书一般的Phabricator安装教程(配合官方文档并带有踩坑解决方案)
随着一声惊雷和滂沱的大雨,我的Phabricator页面终于在我的学生机上跑了起来. 想起在这五个小时内踩过的坑甚如大学隔壁炮王干过的妹子,心里的成就感不禁油然而生. 接下来,我将和大家分享一下本人在 ...
- Vmware centos7无法联网的问题解决
VMware三种网络连接方式的区别 : 1) bridge : 默认使用VMnet0,不提供DHCP服务 在桥接模式下,虚拟机和宿主计算机处于同等地位,虚拟机就像是一台真实主机一样存在于局域网中.因此 ...
- Git命令行之快速入门
从头开始创建一个版本库,添加一些内容,然后管理一些修订版本. 有两种建立 Git版本库 的基础技术.第一:从头开始创建,用现有的内容填充它.第二:可以克隆一个已有的版本库.这里选择从一个空的版本库开始 ...
- sql server还原数据库(请选择用于还原的备份集)
还原数据库的时候明明选择了备份集,还是提示未选择还原的备份集 后来查了下,是因为我本地有两个数据库(2008R2和2014),对应的两个数据库实例.而还原bak是sqlserver2014的备份,我默 ...