使用ArrayPool池化大型数组(翻译)
原文链接:https://adamsitnik.com/Array-Pool/
第一次翻译,会有较多机翻,如果有错误,请及时指出批评,我会立即改正。
使用ArrayPool来避免大数组造成的Full GC的问题。
简介
.NET的垃圾收集器(GC)实现了许多性能优化,其中之一就是,设定年轻的对象很快消亡,然而老的对象却可以生存很久。这就是为什么托管堆被划分为三个代。我们称呼他们为第0代(最年轻的)、第1代(短暂生存)、第2代(生存最长的)。新的对象默认都被分配到第0代。当GC尝试分配一个新的对象到第0代时并且发现第0代已经满了,就会触发第0代进行回收,这个被称呼为局部回收(仅仅回收第0代)。GC遍历整个对象图形,从最根部(局部变量,静态字段等)开始,将所有的引用对象标记为生存对象。
以上是第一阶段,被称为“标记”阶段,此阶段为非阻塞的。但是GC回收进程是阻塞的,GC会挂起所有的线程来执行下一步。
生存了的对象被提权(提权过程大部分时间都是消耗在数据拷贝上)到第1代,然后第0代被清空。第0代往往被设计为很小,所以执行第0代的回收会比较快。理想情况下,一个WEB请求,从开始请求到结束请求,所有被分配的对象都应该被回收掉。然后GC就可以将下一个对象指针移到第0代的起始位置。同理,根据第0代的回收逻辑,当第1代也满了之后,GC就不能再将第0代的对象进行提权到第1代了。接着GC就开始回收第1代的内存。第1代也很小,执行回收也很快,紧接着,第1代的生存者被提权到第2代。第2代里面都是生存期很长的对象,第2代非常大并且执行第2代的垃圾回收会非常非常耗时。所以针对于第2代的垃圾回收我们应该尽量避免,想知道为什么?让我们看看下面的视频然后看看第2代的垃圾回收是如何影响用户体验的。
大对象堆栈(LOH)
每当GC将对象转移到新的一代时,都会进行内存拷贝。如你想象,如果是在拷贝一些大对象,例如大数组或者字符串时会尤其耗时。为了解决这种问题,GC有另一个优化手段,任何一个大于85000字节的对象都被认为是大对象,大对象存储在托管堆的单独部分中,称为大对象堆(LOH),该部分使用自由列表算法进行管理。这意味着GC有一个免费的内存段列表,当我们想要分配一些大的内容时,它会搜索列表以找到一个可行的内存段。因此,默认情况下,大对象永远不会在内存中移动。然而,如果遇到LOH碎片问题,则需要压缩LOH。从.NET 4.5.1开始,您可以按需执行此操作。
问题来了
分配大对象时,它被标记为GC的第2代对象。不像小对象是默认放在第0代的。这种机制的结果就是如果你在LOH中耗尽内存,GC会清理整个托管堆(第0代、第1代、第2代以及LOH块),而不仅仅是LOH。这种行为被称为Full GC,是最为耗时的垃圾回收。对于许多应用,Full GC可以忍受,但是对于高性能的WEB服务器,实在是无法忍受,其中需要很少的大内存缓冲来处理平均的Web请求(例如从套接字读取,解压缩,解码JSON等等)。
要是想知道Full GC是不是你的应用性能问题,可以用内置的perfmon.exe程序获得简单的视图报告。

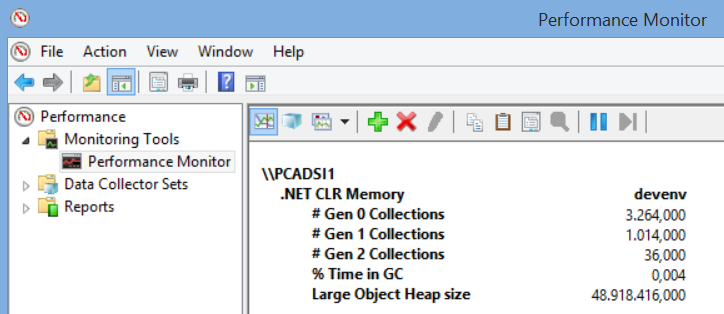
如你所见,对于我的Visual Studio程序来说,Full GC不是问题,我的Visual Studio应用程序已经运行了好几个小时了,第2代的回收相比于第0、1代来说要少很多。
解决方案
解决方案非常简单:缓冲池。 池(Pool)是一组可以使用的初始化对象。我们不是分配新对象,而是从池中租用它。一旦我们完成使用,我们就将它返回到池中。每个大型托管对象都是一个数组或数组包装器(字符串包含一个长度字段和一个字符数组)。所以我们需要池数组来避免这个问题。
ArrayPool是托管数组的高性能池。您可以在System.Buffers包中找到它,它的源代码你也可以在GitHub上找到。它的运用已经相当成熟并可以在生产中使用。它是面向.NET Stadard 1.1,这意味着您不仅可以在.NET Core应用程序中使用它,还可以在现有的.NET 4.5.1应用程序中使用它!
代码示例
var samePool = ArrayPool<byte>.Shared;
byte[] buffer = samePool.Rent(minLength);
try
{
Use(buffer);
}
finally
{
samePool.Return(buffer);
// don't use the reference to the buffer after returning it!
}
void Use(byte[] buffer) // it's an array
如何使用
首先你需要一个初始化的池,至少有三种方式可以获得:
- 最建议的方式:使用 ArrayPool.Shared 属性,它将返回一个线程安全的可共享的池对象实例,不过要记住他有一个默认的最大数组长度( 2^20 (1024*1024 = 1 048 576))。
- 使用 ArrayPool.Create静态方法,也可以创建一个线程安全的池,并且可以自定义maxArrayLength和maxArraysPerBucket两个参数,如果最大数组长度对你来说不够的话,你可以尝试使用。不过请记住,一旦你创建了它,你有责任让它保持活力。
- 从抽象ArrayPool 派生自定义类并且自己实现处理机制。
接下来,在获取了初始化池之后你就需要调用Rent方法,它需要你传入一个你想要的缓存的最小长度,请记住,Rent返回的内容可能比您要求的要大。
byte[] webRequest = request.Bytes;
byte[] buffer = ArrayPool<byte>.Shared.Rent(webRequest.Length);
Array.Copy(
sourceArray: webRequest,
destinationArray: buffer,
length: webRequest.Length); // webRequest.Length != buffer.Length!!
完成使用后,只需使用Return方法将其返回到相同的池中即可。Return方法有一个重载,它允许你清理缓冲区,以便后续的消费者调用Rent方法不会看到以前的消费者的内容。默认情况下,内容保持不变。
源码中有一段关于ArrayPool的一个非常重要的备注
Once a buffer has been returned to the pool, the caller gives up all ownership of the buffer and must not use it. The reference returned from a given call to Rent must only be returned via Return once.
这意味着,开发人员需要正确使用此功能。如果在将缓冲区返回到池后继续使用对缓冲区的引用,则存在不可预料的风险。据我所知,截止至今天来说还没有一个静态代码分析工具可以校验正确的用法。 ArrayPool是corefx库的一部分,它不是C#语言的一部分。
压测
让我们使用BenchmarkDotNet来比较使用new操作符分配数组和使用ArrayPool池化它们的性能消耗,为了确保基准测试包含GC的时间,我配置了BenchmarkDotNet不要进行GC回收。池化的性能测试包含了Rent和Return的消耗,我正在运行.NET Core 2.0的基准测试,这很重要,因为它具有更快的ArrayPool 版本。对于.NET Core 2.0,ArrayPool 是clr的一部分,而之前的框架使用corefx版本。两个版本都非常快,它们的比较和它们的设计分析可能需要一篇单独的博客文章来介绍了。
class Program
{
static void Main(string[] args) => BenchmarkRunner.Run<Pooling>();
}
[MemoryDiagnoser]
[Config(typeof(DontForceGcCollectionsConfig))] // we don't want to interfere with GC, we want to include it's impact
public class Pooling
{
[Params((int)1E+2, // 100 bytes
(int)1E+3, // 1 000 bytes = 1 KB
(int)1E+4, // 10 000 bytes = 10 KB
(int)1E+5, // 100 000 bytes = 100 KB
(int)1E+6, // 1 000 000 bytes = 1 MB
(int)1E+7)] // 10 000 000 bytes = 10 MB
public int SizeInBytes { get; set; }
private ArrayPool<byte> sizeAwarePool;
[GlobalSetup]
public void GlobalSetup()
=> sizeAwarePool = ArrayPool<byte>.Create(SizeInBytes + 1, 10); // let's create the pool that knows the real max size
[Benchmark]
public void Allocate()
=> DeadCodeEliminationHelper.KeepAliveWithoutBoxing(new byte[SizeInBytes]);
[Benchmark]
public void RentAndReturn_Shared()
{
var pool = ArrayPool<byte>.Shared;
byte[] array = pool.Rent(SizeInBytes);
pool.Return(array);
}
[Benchmark]
public void RentAndReturn_Aware()
{
var pool = sizeAwarePool;
byte[] array = pool.Rent(SizeInBytes);
pool.Return(array);
}
}
public class DontForceGcCollectionsConfig : ManualConfig
{
public DontForceGcCollectionsConfig()
{
Add(Job.Default
.With(new GcMode()
{
Force = false // tell BenchmarkDotNet not to force GC collections after every iteration
}));
}
}
结果
如果你对于BenchmarkDotNet在内存诊断程序开启的情况下所输出的内容不清楚的话,你可以读我的这一篇文章来了解如何阅读这些结果。
BenchmarkDotNet=v0.10.7, OS=Windows 10 Redstone 1 (10.0.14393)
Processor=Intel Core i7-6600U CPU 2.60GHz (Skylake), ProcessorCount=4
Frequency=2742189 Hz, Resolution=364.6722 ns, Timer=TSC
dotnet cli version=2.0.0-preview1-005977
[Host] : .NET Core 4.6.25302.01, 64bit RyuJIT
Job-EBWZVT : .NET Core 4.6.25302.01, 64bit RyuJIT
| Method | SizeInBytes | Mean | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|
| Allocate | 100 | 8.078 ns | 0.0610 | - | - | 128 B |
| RentAndReturn_Shared | 100 | 44.219 ns | - | - | - | 0 B |
对于非常小的内存块,默认分配器可以更快
| Method | SizeInBytes | Mean | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|
| Allocate | 1000 | 41.330 ns | 0.4880 | 0.0000 | - | 1024 B |
| RentAndReturn_Shared | 1000 | 43.739 ns | - | - | - | 0 B |
对于1000个字节他们的速度也差不多
| Method | SizeInBytes | Mean | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|
| Allocate | 10000 | 374.564 ns | 4.7847 | 0.0000 | - | 10024 B |
| RentAndReturn_Shared | 10000 | 44.223 ns | - | - | - | 0 B |
随着分配的字节增加,被分配的内存增多导致程序越来越慢。
| Method | SizeInBytes | Mean | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|
| Allocate | 100000 | 3,637.110 ns | 31.2497 | 31.2497 | 31.2497 | 10024 B |
| RentAndReturn_Shared | 100000 | 46.649 ns | - | - | - | 0 B |
第2代回收,当大于85000字节时,我们看到了第一次的Full GC回收。
| Method | SizeInBytes | Mean | StdDev | Gen 0/1/2 | Allocated |
|---|---|---|---|---|---|
| RentAndReturn_Shared | 100 | 44.219 ns | 0.0314 ns | - | 0 B |
| RentAndReturn_Shared | 1000 | 43.739 ns | 0.0337 ns | - | 0 B |
| RentAndReturn_Shared | 10000 | 44.223 ns | 0.0333 ns | - | 0 B |
| RentAndReturn_Shared | 100000 | 46.649 ns | 0.0346 ns | - | 0 B |
| RentAndReturn_Shared | 1000000 | 42.423 ns | 0.0623 ns | - | 0 B |
此刻,你应该注意到了,ArrayPool池化所消耗的成本是不变的以及与被分配的大小无关的,这很棒,因为你可以预测你代码的行为。
被分配的缓存
如果当我们在给定的池中租赁的缓存超过了最大长度限制(2^20,ArrayPool.Shared)会发生什么呢?
| Method | SizeInBytes | Mean | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|
| Allocate | 10000000 | 557,963.968 ns | 211.5625 | 211.5625 | 211.5625 | 10000024 B |
| RentAndReturn_Shared | 10000000 | 651,147.998 ns | 207.1484 | 207.1484 | 207.1484 | 10000024 B |
| RentAndReturn_Aware | 10000000 | 47.033 ns | - | - | - | 0 B |
当超过了最大长度限制,每一次运行时都会重新分配一段新的缓存区。并且当你把它还到池里的时候,都会被忽略而不是再放入池中。
别担心,ArrayPool有针对于事件监测(ETW)的事件提供者,所以你可以使用PerfView或者其他工具来检测你的应用程序并且监控BufferAllocated事件。
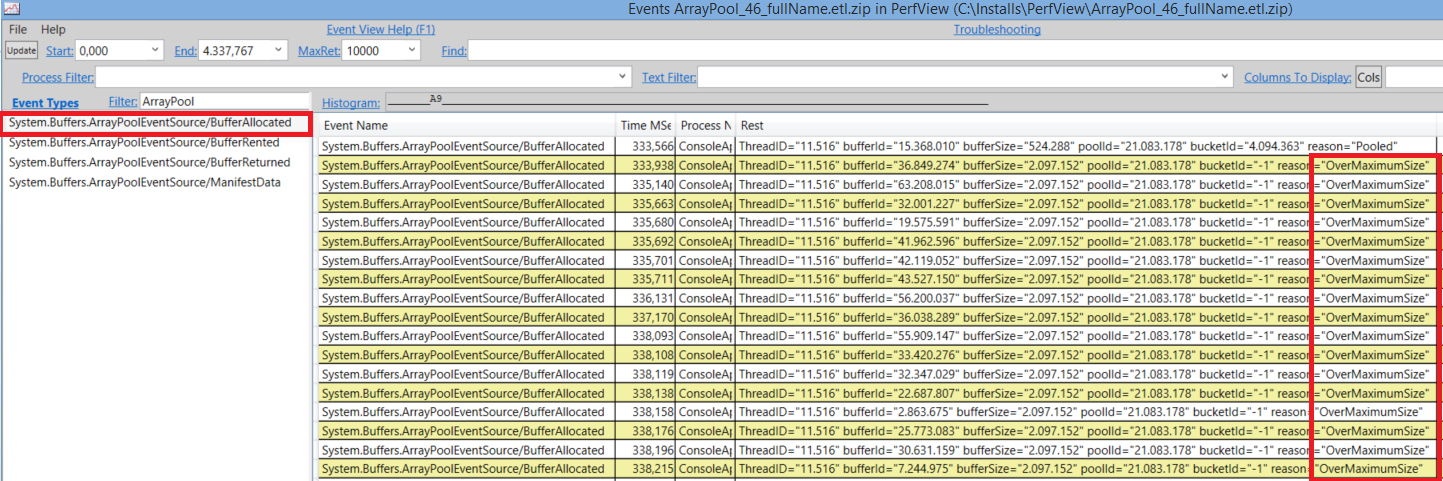
为了避免这种问题,你可以使用ArrayPool.Create方法,这个方法提供了maxArrayLength参数用来创建一个池。但是也不要创建太多的自定义池,使用池化的目标是为了保持LOH区域尽可能的小。如果你创建了太多的池,就会增爆LOH块,充满了大数组是无法被GC正常回收的(因为在你使用了自定义池之后使得这些大数组变为根引用)。这就是为什么很多流行的框架,例如ASP.NET CORE或者ImageSharp都只使用了ArrayPool.Shared,如果你只是使用ArrayPool.Shared而不是使用new实例化类的话,那么在悲观情况下(请求的数组大小大于默认最大值),会看出来效率略微较之前下降(你会做额外的检查并且重新分配)。但是在乐观情况下,会很明显比之前快很多,因为你只要从池里租赁就可以了。所以我相信默认使用ArrayPool.Shared就好了。如果BufferAllocated事件被频繁调用,就可以考虑使用ArrayPool.Create方法。
MemoryStream的池化
有时,为了避免LOH的分配一个数组可能不是很够,有个第三方API的,
感谢Victor Baybekov我发现了Microsoft.IO.RecyclableMemoryStream库,这个库提供了MemoryStream对象的池化,这个是Bing的工程师为了解决LOH问题所涉及的。想要知道更多细节可以查看Ben Watson写的这篇博客。
总结
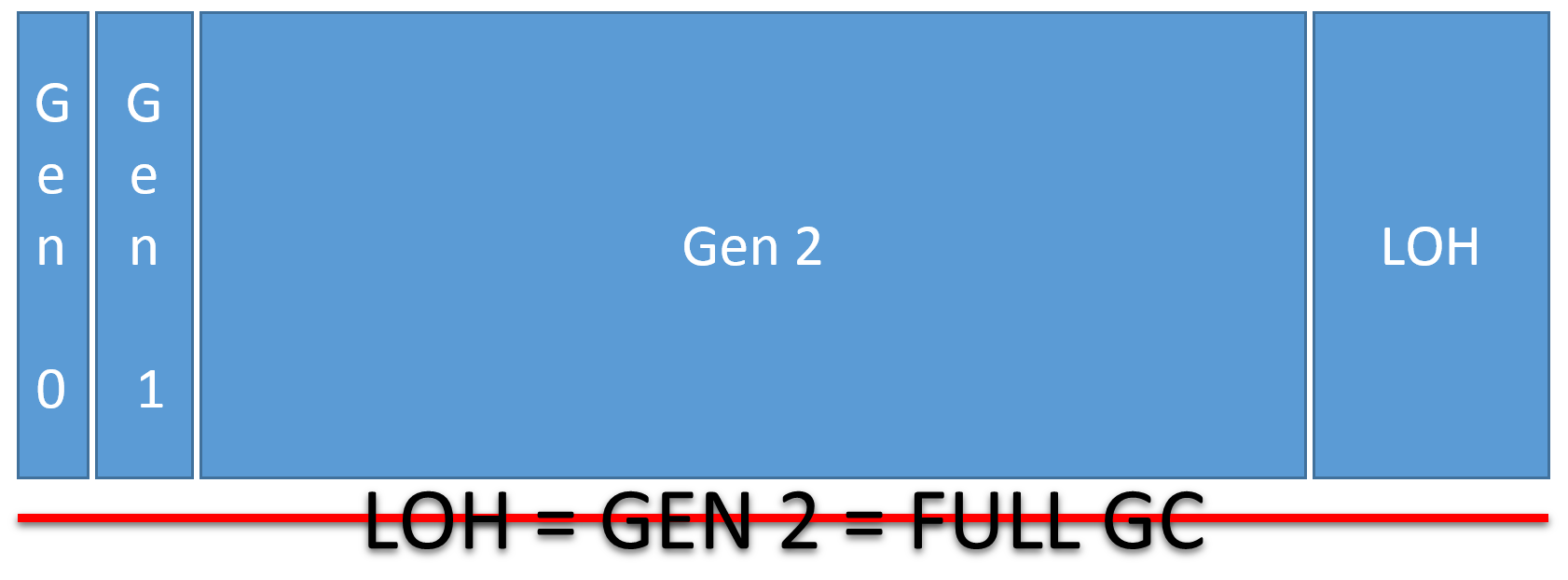
- LOH = 第2代 = Full GC = 糟糕的性能
- ArrayPool 被设计为更好的性能
- 如果你能控制生命周期可以使用池化
- 默认使用ArrayPool.Shared
- 池化的时候分配的内存不要超过最大数组长度限制
- 池越少,LOH就会越小,效率越好
转载请注明出处:https://www.cnblogs.com/briswhite/p/11349429.html
使用ArrayPool池化大型数组(翻译)的更多相关文章
- ArrayPool 源码解读之 byte[] 也能池化?
一:背景 1. 讲故事 最近在分析一个 dump 的过程中发现其在 gen2 和 LOH 上有不少size较大的free,仔细看了下,这些free生前大多都是模板引擎生成的html片段的byte[]数 ...
- C# ArrayPool 源码解读之 byte[] 池化
一:背景 1. 讲故事最近在分析一个 dump 的过程中发现其在 gen2 和 LOH 上有不少size较大的free,仔细看了下,这些free生前大多都是模板引擎生成的html片段的byte[]数组 ...
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
http://www.dengfanxin.cn/?p=403 原文地址 我对物体检测的一篇重要著作SPPNet的论文的主要部分进行了翻译工作.SPPNet的初衷非常明晰,就是希望网络对输入的尺寸更加 ...
- UFLDL教程笔记及练习答案五(自编码线性解码器与处理大型图像**卷积与池化)
自己主动编码线性解码器 自己主动编码线性解码器主要是考虑到稀疏自己主动编码器最后一层输出假设用sigmoid函数.因为稀疏自己主动编码器学习是的输出等于输入.simoid函数的值域在[0,1]之间,这 ...
- [翻译] 编写高性能 .NET 代码--第二章 GC -- 将长生命周期对象和大对象池化
将长生命周期对象和大对象池化 请记住最开始说的原则:对象要么立即回收要么一直存在.它们要么在0代被回收,要么在2代里一直存在.有些对象本质是静态的,生命周期从它们被创建开始,到程序停止才会结束.其它对 ...
- Deep Learning 学习随记(七)Convolution and Pooling --卷积和池化
图像大小与参数个数: 前面几章都是针对小图像块处理的,这一章则是针对大图像进行处理的.两者在这的区别还是很明显的,小图像(如8*8,MINIST的28*28)可以采用全连接的方式(即输入层和隐含层直接 ...
- 第十四节,TensorFlow中的反卷积,反池化操作以及gradients的使用
反卷积是指,通过测量输出和已知输入重构未知输入的过程.在神经网络中,反卷积过程并不具备学习的能力,仅仅是用于可视化一个已经训练好的卷积神经网络,没有学习训练的过程.反卷积有着许多特别的应用,一般可以用 ...
- 自然语言处理的CNN模型中几种常见的池化方法
自然语言处理的CNN模型中几种常见的池化方法 本文是在[1]的基础上进行的二次归纳. 0x00 池化(pooling)的作用 首先,回顾一下NLP中基本的CNN模型的卷积和池化的大致原理[2].f ...
- Python3 卷积神经网络卷积层,池化层,全连接层前馈实现
# -*- coding: utf-8 -*- """ Created on Sun Mar 4 09:21:41 2018 @author: markli " ...
随机推荐
- mysql查询语句出现sending data耗时解决
在执行一个简单的sql查询,表中数据量为14万 sql语句为:SELECT id,titile,published_at from spider_36kr_record where is_analyz ...
- (转)代码结构中Dao,Service,Controller,Util,Model是什么意思?
作者:技能树IT修真院链接:https://www.zhihu.com/question/58410621/answer/623496434来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商 ...
- Hash的应用2
代码: #include <stdio.h> #define OFFSET 500000//偏移量 ];//记录每个数是否出现,出现为1,不出现为0 int main(){ int n,m ...
- 星际旅行(欧拉路,欧拉回路)(20190718 NOIP模拟测试5)
瞎搞了一个ans+=du*(du-1)/2 wa20分,好桑心(话外音:居然还有二十分,出题人太周到了) 还是判欧拉路 题解没太仔细想,感觉还是kx的思路明白 具体就是:因为每条边要走两遍,可以把一条 ...
- 记录一次pycharm中,引入其他类可用,下面总是有波浪线,而且Ctrl+b 无法查看类函数的源码
最近在玩python,发现引入其他的函数们总是有波浪线,但是能够使用,crtl+b却无法看到,非常尴尬,然后查看了原因,记录如下: This inspection detects names that ...
- 洛谷P2172 [国家集训队]部落战争 题解
题目链接:https://www.luogu.org/problemnew/show/P2172 分析: 不要被[国家集训队]的标签吓到,其实这题不是很难. 本题可以对比P4304 [TJOI2013 ...
- webService 的使用
webService Web service是一个平台独立的,低耦合的,自包含的.基于可编程的web的应用程序,可使用开放的XML(标准通用标记语言下的一个子集)标准来描述.发布.发现.协调和配置这些 ...
- JAVA 使用 POI进行读取Excel表格示例
导包 编码 public class PoiTest { /** * 最终效果 * 表头一内容0 表头二内容1 表头三内容2 表头一内容1 表头二内容2 表头三内容3 表头一内容2 表头二内容3 表头 ...
- Linu基础之权限管理
二十二.权限管理 22.1)什么是权限 针对某些文件或者进程,对用户进行限制,权限可以理解为用于约束用户能对系统所做的操作. 22.2)权限和用户的关系 [root@centos7 ~]# ll ...
- python基础——变量
变量是只不过保留的内存位置用来存储值.这意味着,当创建一个变量,那么它在内存中保留一些空间. 根据一个变量的数据类型,解释器分配内存,并决定如何可以被存储在所保留的内存中.因此,通过分配不同的数据类型 ...