spark 源码分析之十--Spark RPC剖析之TransportResponseHandler、TransportRequestHandler和TransportChannelHandler剖析
spark 源码分析之十--Spark RPC剖析之TransportResponseHandler、TransportRequestHandler和TransportChannelHandler剖析
TransportResponseHandler分析
先来看类说明:
Handler that processes server responses, in response to requests issued from a [[TransportClient]]. It works by tracking the list of outstanding requests (and their callbacks). Concurrency: thread safe and can be called from multiple threads.
其关键的成员字段作如下说明:
1. channel:与之绑定的SocketChannel对象
2. outstandingFetches:是一个ConcurrentHashMap,主要保存StreamChunkId和ChunkReceivedCallback的映射关系。
3. outstandingRpcs:是一个ConcurrentHashMap,主要保存 request id 和RpcResponseCallback的映射关系。
4. streamCallbacks 是一个ConcurrentLinkedQueue队列,保存了Pair<String, StreamCallback>,其中String是stream id
5. timeOfLastRequestNs:记录了上次rpc 请求或 chunk fetching 的系统时间,以纳秒计算
其关键方法 handle 如下:

TransportRequestHandler分析
类说明如下:
A handler that processes requests from clients and writes chunk data back. Each handler is attached to a single Netty channel, and keeps track of which streams have been fetched via this channel, in order to clean them up if the channel is terminated (see #channelUnregistered). The messages should have been processed by the pipeline setup by TransportServer.
它是一个handler,处理来自于client 的 请求,返回chunk 给 client。每一个handler与一个netty channel 关联,并追踪那个chunk 已经被chennel获取到了。其中消息应该已经被TransportServer建立起来的管道处理过了。
其成员变量说明如下:
1. channel: 是Channel对象,与之关联的SocketChannel对象
2. reverseClient:是TransportClient对象,同一个channel 上的client,这样,就可以给消息的请求者通信了
3. rpcHandler:是一个RpcHandler对象,处理所有的 RPC 消息
4. streamManager: 是一个StreamManager对象,返回一个流的 任意一部分chunk
5. maxChunksBeingTransferred: 正在传输的流的chunk 下标
其关键方法 handle 如下:
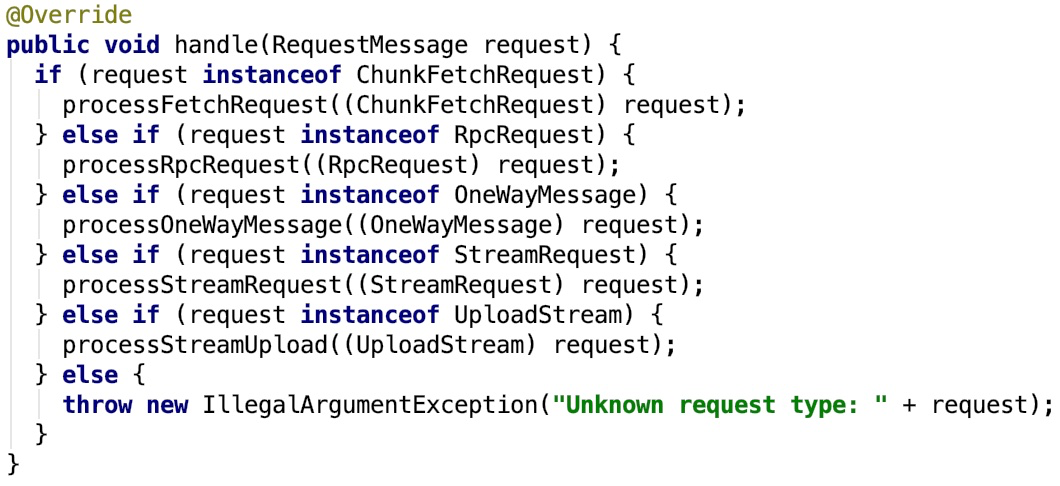
我们只看一个分支作为示例:
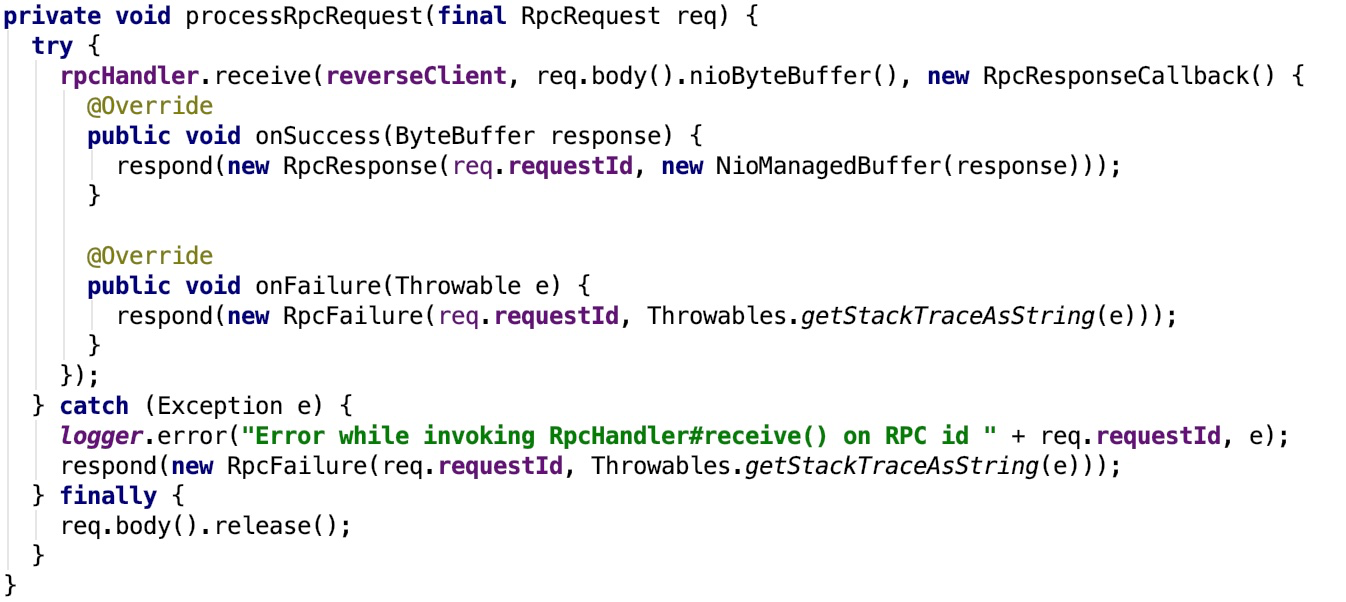
其调用了rpcHandler 的 receive 方法,该方法处理完毕后返回,如果成功,则返回RpcResponse对象,否则返回RpcResponse对象,由于这个返回可能是需要跨网络传输的,所以,有进一步封装了response 方法,如下:

即通过response 方法将server 端的请求结果返回给客户端。
TransportChannelHandler分析
类说明如下:
The single Transport-level Channel handler which is used for delegating requests to the TransportRequestHandler and responses to the TransportResponseHandler. All channels created in the transport layer are bidirectional. When the Client initiates a Netty Channel with a RequestMessage (which gets handled by the Server's RequestHandler), the Server will produce a ResponseMessage (handled by the Client's ResponseHandler). However, the Server also gets a handle on the same Channel, so it may then begin to send RequestMessages to the Client. This means that the Client also needs a RequestHandler and the Server needs a ResponseHandler, for the Client's responses to the Server's requests. This class also handles timeouts from a io.netty.handler.timeout.IdleStateHandler. We consider a connection timed out if there are outstanding fetch or RPC requests but no traffic on the channel for at least `requestTimeoutMs`. Note that this is duplex traffic; we will not timeout if the client is continuously sending but getting no responses, for simplicity.
传输层的handler,负责委托请求给TransportRequestHandler,委托响应给TransportResponseHandler。
在传输层中创建的所有通道都是双向的。当客户端使用RequestMessage启动Netty通道(由服务器的RequestHandler处理)时,服务器将生成ResponseMessage(由客户端的ResponseHandler处理)。但是,服务器也会在同一个Channel上获取句柄,因此它可能会开始向客户端发送RequestMessages。这意味着客户端还需要一个RequestHandler,而Server需要一个ResponseHandler,用于客户端对服务器请求的响应。此类还处理来自io.netty.handler.timeout.IdleStateHandler的超时。如果存在未完成的提取或RPC请求但是至少在“requestTimeoutMs”上没有通道上的流量,我们认为连接超时。请注意,这是双工流量;如果客户端不断发送但是没有响应,我们将不会超时。
关键方法channelRead如下:

该方法,负责将请求委托给TransportRequestHandler,将响应委托给TransportResponseHandler。
因为这个channel最终被添加到了channel上,所以消息从channel中传输(流出或流入)都会触发这个方法,进而调用响应的方法。
即Spark RPC通过netty的channel发送请求,获取响应。
spark 源码分析之十--Spark RPC剖析之TransportResponseHandler、TransportRequestHandler和TransportChannelHandler剖析的更多相关文章
- spark 源码分析之十二 -- Spark内置RPC机制剖析之八Spark RPC总结
在spark 源码分析之五 -- Spark内置RPC机制剖析之一创建NettyRpcEnv中,剖析了NettyRpcEnv的创建过程. Dispatcher.NettyStreamManager.T ...
- spark 源码分析之十一--Spark RPC剖析之TransportClient、TransportServer剖析
TransportClient类说明 先来看,官方文档给出的说明: Client for fetching consecutive chunks of a pre-negotiated stream. ...
- spark 源码分析之十八 -- Spark存储体系剖析
本篇文章主要剖析BlockManager相关的类以及总结Spark底层存储体系. 总述 先看 BlockManager相关类之间的关系如下: 我们从NettyRpcEnv 开始,做一下简单说明. Ne ...
- spark 源码分析之十九 -- Stage的提交
引言 上篇 spark 源码分析之十九 -- DAG的生成和Stage的划分 中,主要介绍了下图中的前两个阶段DAG的构建和Stage的划分. 本篇文章主要剖析,Stage是如何提交的. rdd的依赖 ...
- spark 源码分析之十五 -- Spark内存管理剖析
本篇文章主要剖析Spark的内存管理体系. 在上篇文章 spark 源码分析之十四 -- broadcast 是如何实现的?中对存储相关的内容没有做过多的剖析,下面计划先剖析Spark的内存机制,进而 ...
- spark 源码分析之十六 -- Spark内存存储剖析
上篇spark 源码分析之十五 -- Spark内存管理剖析 讲解了Spark的内存管理机制,主要是MemoryManager的内容.跟Spark的内存管理机制最密切相关的就是内存存储,本篇文章主要介 ...
- spark 源码分析之十九 -- DAG的生成和Stage的划分
上篇文章 spark 源码分析之十八 -- Spark存储体系剖析 重点剖析了 Spark的存储体系.从本篇文章开始,剖析Spark作业的调度和计算体系. 在说DAG之前,先简单说一下RDD. 对RD ...
- spark 源码分析之十七 -- Spark磁盘存储剖析
上篇文章 spark 源码分析之十六 -- Spark内存存储剖析 主要剖析了Spark 的内存存储.本篇文章主要剖析磁盘存储. 总述 磁盘存储相对比较简单,相关的类关系图如下: 我们先从依赖类 Di ...
- spark 源码分析之十四 -- broadcast 是如何实现的?
本篇文章主要剖析broadcast 的实现机制. BroadcastManager初始化 BroadcastManager初始化方法源码如下: TorrentBroadcastFactory的继承关系 ...
随机推荐
- log4net插入access自定义字段
1.创建表格 2.创建log4net.xml,并设置属性始终复制,关键属性 <bufferSize value="1" /> <conversionPattern ...
- JS数据结构第四篇 --- 栈
一.什么是数据结构栈 在数据结构中有一个栈结构,在内存空间中也有一个栈空间,这两个”栈“是两个不同的概念.这篇我们说的是数据结构中的栈.栈是一种特殊的线性表,特殊性在哪?就是只能在栈顶进行操作,往栈顶 ...
- C++标准库(体系结构与内核分析)(侯捷第二讲)
一.OOP和GP的区别(video7) OOP:面向对象编程(Object-Oriented programming) GP:泛化编程(Generic programming) 对于OOP来说,我们要 ...
- PATA 1006. Sign In and Sign Out (25)
#include <bits/stdc++.h> using namespace std; const int N = 100005; struct visitor{ char ID[20 ...
- linux查看文件内容命令tail、cat、tac、head、echo
1.tail tail -f test.log 你会看到屏幕不断有内容被打印出来. 这时候中断第一个进程Ctrl-C, linux 如何显示一个文件的某几行(中间几行) 从第3000行开始,显示100 ...
- 数据结构与算法---树结构(Tree structure)
为什么需要树这种数据结构 数组存储方式的分析 优点:通过下标方式访问元素,速度快.对于有序数组,还可使用二分查找提高检索速度. 缺点:如果要检索具体某个值,或者插入值(按一定顺序)会整体移动,效率较低 ...
- Codeforces 348B:Apple Tree(DFS+LCM+思维)
http://codeforces.com/contest/348/problem/B 题意:给一棵树,每个叶子结点有w[i]个苹果,每个子树的苹果数量为该子树所有叶子结点苹果数量之和,要使得每个结点 ...
- 鼠标滑至某位置,在鼠标旁边出现详情弹窗div
首先效果如下: 代码如下: //这个是一个循环,循环所有name为xx的td标签(也就是给tdname为XXX的添加事件)$("td[name='strGoodsSKU']").e ...
- 6.秋招复习简单整理之请你谈谈JDBC的反射,以及它的作用?
通过反射com.mysql.jdbc.Driver类,实例化该类时会调用该类的静态代码块,该代码块会去java的DriverManager类中注册自己,DriverManager管理所有已注册的驱动类 ...
- c++学习书籍推荐《Exceptional C++ Style》下载
百度云及其他网盘下载地址:点我 编辑推荐 软件“风格”所要讨论的主题是如何在开销与功能之间.优雅与可维护性之间.灵活.性与过分灵活之间寻找完美的平街点.在本书中,著名的C++大师Herb Sutter ...