RDD、DataFrame和DataSet的区别
原文链接:http://www.jianshu.com/p/c0181667daa0
RDD、DataFrame和DataSet是容易产生混淆的概念,必须对其相互之间对比,才可以知道其中异同。
RDD和DataFrame
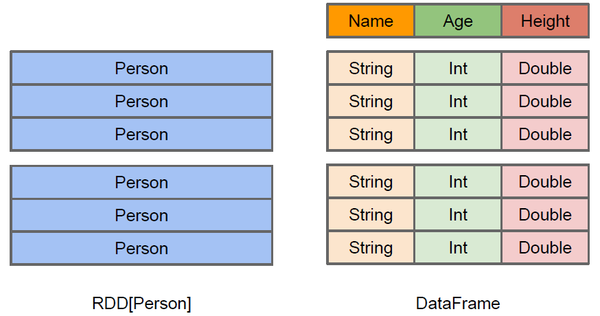
RDD-DataFrame
上图直观地体现了DataFrame和RDD的区别。左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。DataFrame多了数据的结构信息,即schema。RDD是分布式的Java对象的集合。DataFrame是分布式的Row对象的集合。DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化,比如filter下推、裁剪等。
提升执行效率
RDD API是函数式的,强调不变性,在大部分场景下倾向于创建新对象而不是修改老对象。这一特点虽然带来了干净整洁的API,却也使得Spark应用程序在运行期倾向于创建大量临时对象,对GC造成压力。在现有RDD API的基础之上,我们固然可以利用mapPartitions方法来重载RDD单个分片内的数据创建方式,用复用可变对象的方式来减小对象分配和GC的开销,但这牺牲了代码的可读性,而且要求开发者对Spark运行时机制有一定的了解,门槛较高。另一方面,Spark SQL在框架内部已经在各种可能的情况下尽量重用对象,这样做虽然在内部会打破了不变性,但在将数据返回给用户时,还会重新转为不可变数据。利用 DataFrame API进行开发,可以免费地享受到这些优化效果。
减少数据读取
分析大数据,最快的方法就是 ——忽略它。这里的“忽略”并不是熟视无睹,而是根据查询条件进行恰当的剪枝。
上文讨论分区表时提到的分区剪 枝便是其中一种——当查询的过滤条件中涉及到分区列时,我们可以根据查询条件剪掉肯定不包含目标数据的分区目录,从而减少IO。
对于一些“智能”数据格 式,Spark SQL还可以根据数据文件中附带的统计信息来进行剪枝。简单来说,在这类数据格式中,数据是分段保存的,每段数据都带有最大值、最小值、null值数量等 一些基本的统计信息。当统计信息表名某一数据段肯定不包括符合查询条件的目标数据时,该数据段就可以直接跳过(例如某整数列a某段的最大值为100,而查询条件要求a > 200)。
此外,Spark SQL也可以充分利用RCFile、ORC、Parquet等列式存储格式的优势,仅扫描查询真正涉及的列,忽略其余列的数据。
执行优化
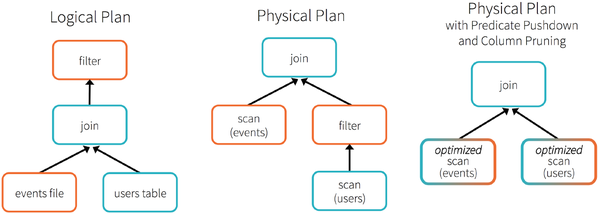
人口数据分析示例
为了说明查询优化,我们来看上图展示的人口数据分析的示例。图中构造了两个DataFrame,将它们join之后又做了一次filter操作。如果原封不动地执行这个执行计划,最终的执行效率是不高的。因为join是一个代价较大的操作,也可能会产生一个较大的数据集。如果我们能将filter下推到 join下方,先对DataFrame进行过滤,再join过滤后的较小的结果集,便可以有效缩短执行时间。而Spark SQL的查询优化器正是这样做的。简而言之,逻辑查询计划优化就是一个利用基于关系代数的等价变换,将高成本的操作替换为低成本操作的过程。
得到的优化执行计划在转换成物 理执行计划的过程中,还可以根据具体的数据源的特性将过滤条件下推至数据源内。最右侧的物理执行计划中Filter之所以消失不见,就是因为溶入了用于执行最终的读取操作的表扫描节点内。
对于普通开发者而言,查询优化 器的意义在于,即便是经验并不丰富的程序员写出的次优的查询,也可以被尽量转换为高效的形式予以执行。
RDD和DataSet
DataSet以Catalyst逻辑执行计划表示,并且数据以编码的二进制形式被存储,不需要反序列化就可以执行sorting、shuffle等操作。
DataSet创立需要一个显式的Encoder,把对象序列化为二进制,可以把对象的scheme映射为Spark
SQl类型,然而RDD依赖于运行时反射机制。
通过上面两点,DataSet的性能比RDD的要好很多,可以参见[3]
DataFrame和DataSet
Dataset可以认为是DataFrame的一个特例,主要区别是Dataset每一个record存储的是一个强类型值而不是一个Row。因此具有如下三个特点:
DataSet可以在编译时检查类型
并且是面向对象的编程接口。用wordcount举例:
//DataFrame // Load a text file and interpret each line as a java.lang.String
val ds = sqlContext.read.text("/home/spark/1.6/lines").as[String]
val result = ds
.flatMap(_.split(" ")) // Split on whitespace
.filter(_ != "") // Filter empty words
.toDF() // Convert to DataFrame to perform aggregation / sorting
.groupBy($"value") // Count number of occurences of each word
.agg(count("*") as "numOccurances")
.orderBy($"numOccurances" desc) // Show most common words first//DataSet,完全使用scala编程,不要切换到DataFrame val wordCount =
ds.flatMap(_.split(" "))
.filter(_ != "")
.groupBy(_.toLowerCase()) // Instead of grouping on a column expression (i.e. $"value") we pass a lambda function
.count()
后面版本DataFrame会继承DataSet,DataFrame是面向Spark SQL的接口。
DataFrame和DataSet可以相互转化,df.as[ElementType]这样可以把DataFrame转化为DataSet,ds.toDF()这样可以把DataSet转化为DataFrame。
参考
[1] Spark SQL结构化分析
[3] Introducing Spark Datasets
RDD、DataFrame和DataSet的区别的更多相关文章
- Spark RDD、DataFrame和DataSet的区别
版权声明:本文为博主原创文章,未经博主允许不得转载. 目录(?)[+] 转载请标明出处:小帆的帆的专栏 RDD 优点: 编译时类型安全 编译时就能检查出类型错误 面向对象的编程风格 直接通过类 ...
- 谈谈RDD、DataFrame、Dataset的区别和各自的优势
在spark中,RDD.DataFrame.Dataset是最常用的数据类型,本博文给出笔者在使用的过程中体会到的区别和各自的优势 共性: 1.RDD.DataFrame.Dataset全都是spar ...
- RDD, DataFrame or Dataset
总结: 1.RDD是一个Java对象的集合.RDD的优点是更面向对象,代码更容易理解.但在需要在集群中传输数据时需要为每个对象保留数据及结构信息,这会导致数据的冗余,同时这会导致大量的GC. 2.Da ...
- spark结构化数据处理:Spark SQL、DataFrame和Dataset
本文讲解Spark的结构化数据处理,主要包括:Spark SQL.DataFrame.Dataset以及Spark SQL服务等相关内容.本文主要讲解Spark 1.6.x的结构化数据处理相关东东,但 ...
- SparkSQL 中 RDD 、DataFrame 、DataSet 三者的区别与联系
一.SparkSQL发展: Shark是一个为spark设计的大规模数据仓库系统,它与Hive兼容 Shark建立在Hive的代码基础上,并通过将Hive的部分物理执行计划交换出来(by s ...
- sparkSQL中RDD——DataFrame——DataSet的区别
spark中RDD.DataFrame.DataSet都是spark的数据集合抽象,RDD针对的是一个个对象,但是DF与DS中针对的是一个个Row RDD 优点: 编译时类型安全 编译时就能检查出类型 ...
- spark的数据结构 RDD——DataFrame——DataSet区别
转载自:http://blog.csdn.net/wo334499/article/details/51689549 RDD 优点: 编译时类型安全 编译时就能检查出类型错误 面向对象的编程风格 直接 ...
- RDD、DataFrame和DataSet
简述 RDD.DataFrame和DataSet是容易产生混淆的概念,必须对其相互之间对比,才可以知道其中异同:DataFrame多了数据的结构信息,即schema.RDD是分布式的 Java对象的集 ...
- spark RDD、DataFrame、DataSet之间的相互转化
这三个数据集看似经常用,但是真正归纳总结的时候,很容易说不出来 三个之间的关系与区别参考我的另一篇blog http://www.cnblogs.com/xjh713/p/7309507.html ...
随机推荐
- Excel数据导入数据库的SQL快速生成
=CONCATENATE("insert into table_name(id, code, name, remark) values (uuid(),'",B2,"', ...
- 安卓中的Model-View-Presenter模式介绍
转载自:http://www.jcodecraeer.com/a/anzhuokaifa/androidkaifa/2015/0425/2782.html 英文原文:Introduction to M ...
- 使用Dotfuscator 进行.Net代码混淆 代码加密的方法
混淆代码能在一定程度上放置代码被盗用,保护我们的知识产权 1.打开vs2012,选择工具-〉Dotfuscator Software Services 2.选择你需要混淆的DLL 文件,可以多选择 3 ...
- HDFS 架构解析
本文以 Hadoop 提供的分布式文件系统(HDFS)为例来进一步展开解析分布式存储服务架构设计的要点. 架构目标 任何一种软件框架或服务都是为了解决特定问题而产生的.还记得我们在 <分布式存储 ...
- Javascript判断两个日期是否相等
大家一定遇到过这样的情况,有两个日期对象,然后需要判断他们是否相等. 例如: var date1 = new Date("2013-11-29"); var date2 = new ...
- 四核驱动的三维导航—淘宝新UI(设计篇)
前面有一篇博客说到了淘宝UWP的"四核驱动的三维导航—淘宝新UI(需求分析篇)",花了两周的时间实现了这个框架,然后又陆陆续续用了三周的时间完善它. 多窗口导航,与传统的导航方式的 ...
- Git Shell 基本命令(官网脱水版)
用户信息 当安装完 Git 应该做的第一件事就是设置你的用户名称与邮件地址. 这样做很重要,因为每一个 Git 的提交都会使用这些信息,并且它会写入到你的每一次提交中,不可更改: $ git conf ...
- .NET 基础 一步步 一幕幕 [前言]
.NET 基础 一步步 一幕幕 [前言部分] 本人小白一枚,虽然说从去年就开通博客了,到现在也没有写多少东东,虽然工作了,也没有更好得总结.故此重新祭出博客园法宝,修炼技术,争取早日走上大神之位. 故 ...
- hibernate学习笔记之三 持久化的三种状态
Hibernate持久化对象有3中状态,瞬时对象(transientObjects),持久化对象(persistentObjects),离线对象(detachedObjects) 下图显示持久化三种状 ...
- 【.NET深呼吸】存储基于本地线程的值
在特定情况,我们希望这样一个场景: N个线程同时调用同一个类实例的同一个操作方法,并且同一个变量可以面向每一个线程存储独立的值.比如,某变量X,它对于线程A的值与对于线程B的值是相互独立的.线程A设置 ...