Python数据分析揭秘知乎大V的小秘密
前言
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 清风小筑
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
知乎,可以说是国内目前最大的问答类社区。与微博、贴吧等产品不同,知乎上面的内容更多是用户针对特定的问题分享知识、经验和见解。
大V的关联
首先给大家看的是知乎上粉丝数前50用户的关系图:
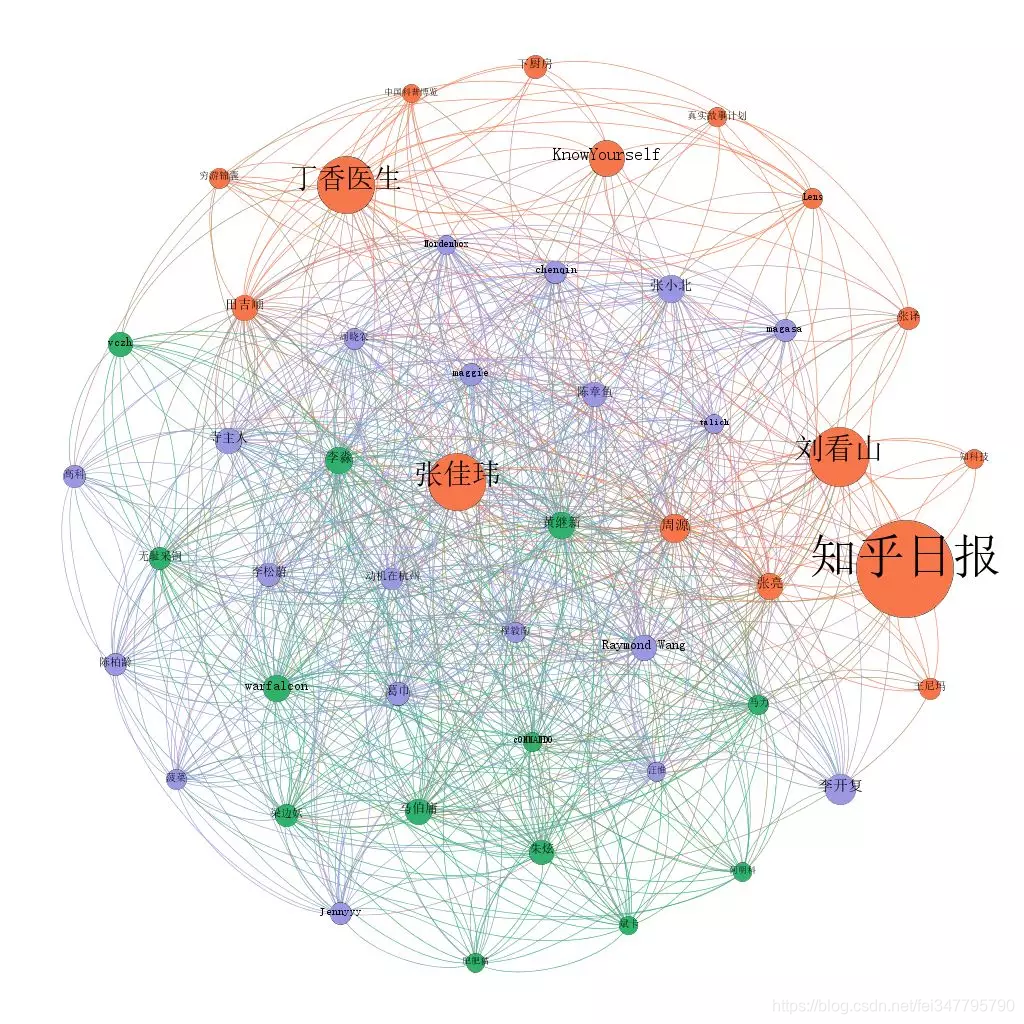
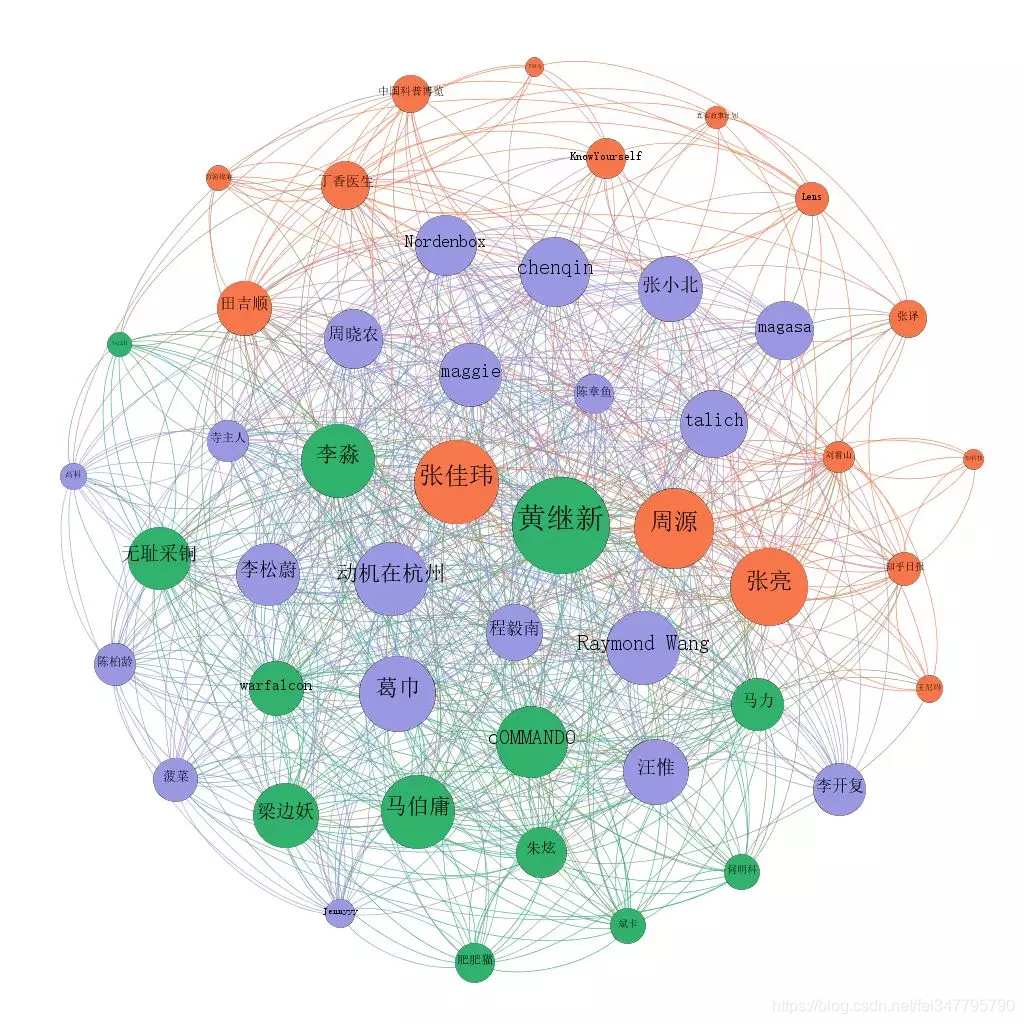
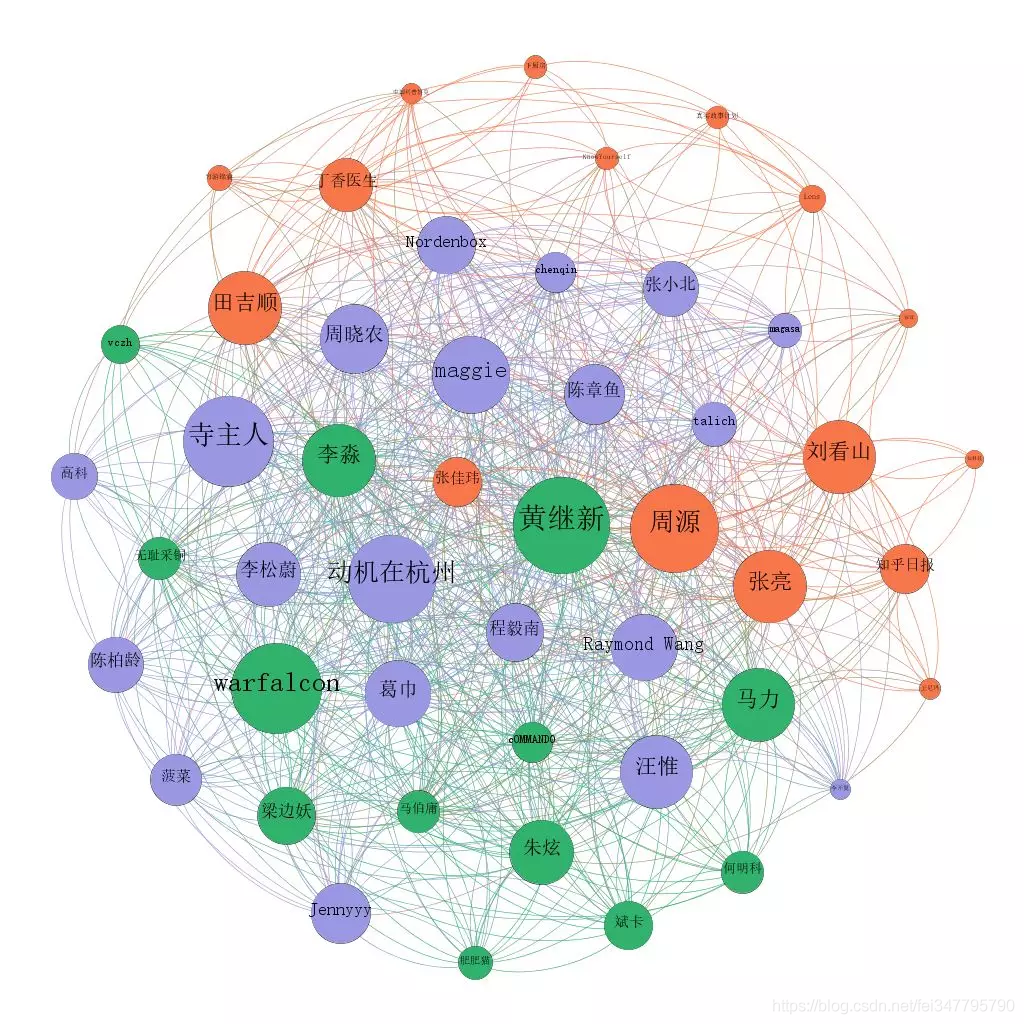
图中的线是用户之间的相互关注的关系。这三张图的差别只在圆圈的大小上,依次分别代表:粉丝数、连入度(被图中其他人关注的数量)、连出度(关注图中其他人的数量)
比较明显的是,像知乎日报、刘看山、丁香医生这类普通用户关注较多的“机构号”,在大V中的受关注度并不高。
这张图是通过一个叫做 Gephi 的软件,基于 Python 采集下来的数据做出来的。其中圈的颜色是 Gephi 根据关联关系自动聚合的结果。
谁是大V
知乎的四大指标:关注、赞同、感谢、收藏。我们分别看下以不同指标排行的“头部用户”:

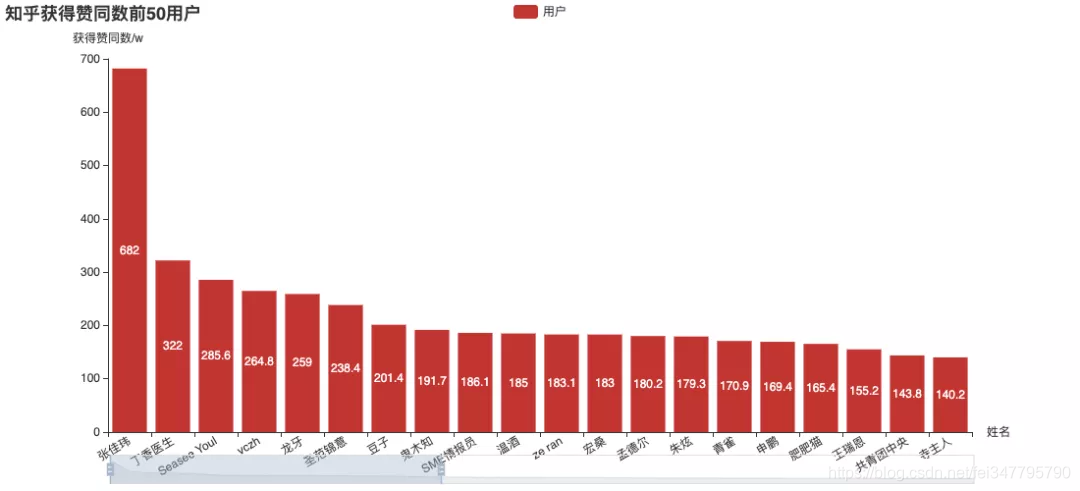

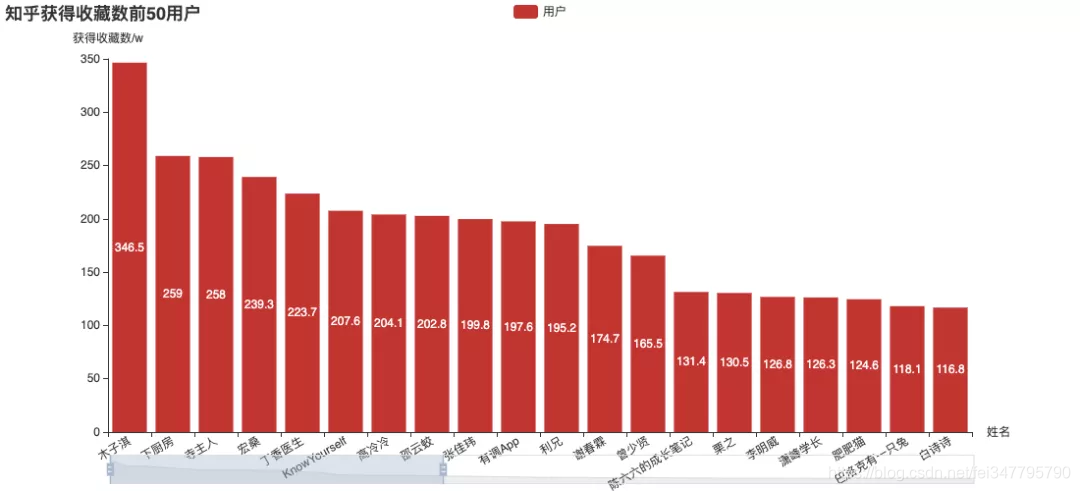
其中,张佳玮可以说是非常突出了。(这个名字好熟悉……还记得之前的虎扑分析吗?)
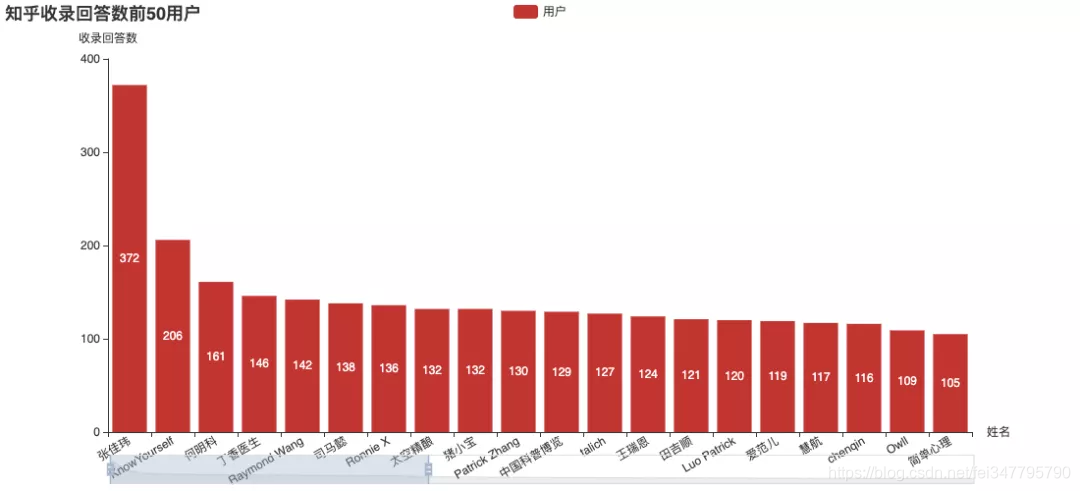

官方收录回答数,张佳玮还是遥遥领先,收录文章数也榜上有名。
如果不论质量,仅看数量的话:


把这几组数据合成了两张三维散点图:
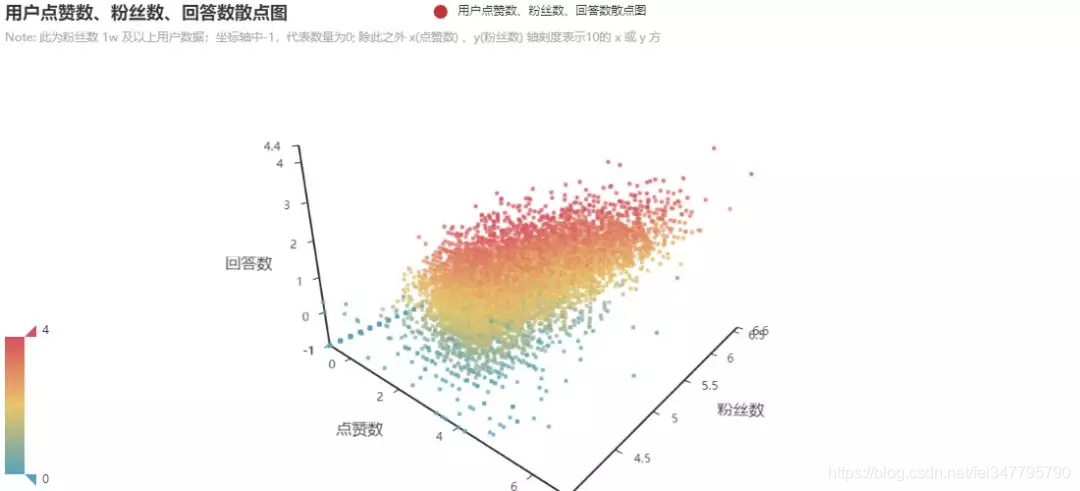

图中选取的数据为关注数大于1万的用户。在项目里有可以交互的网页版本,可以更直观的查看这个分布图。
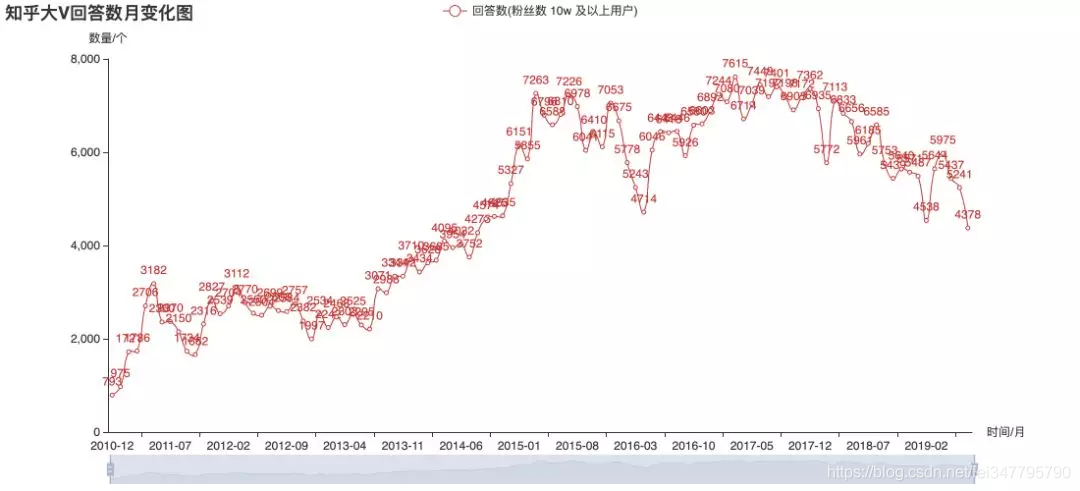
大V的热情在消退?
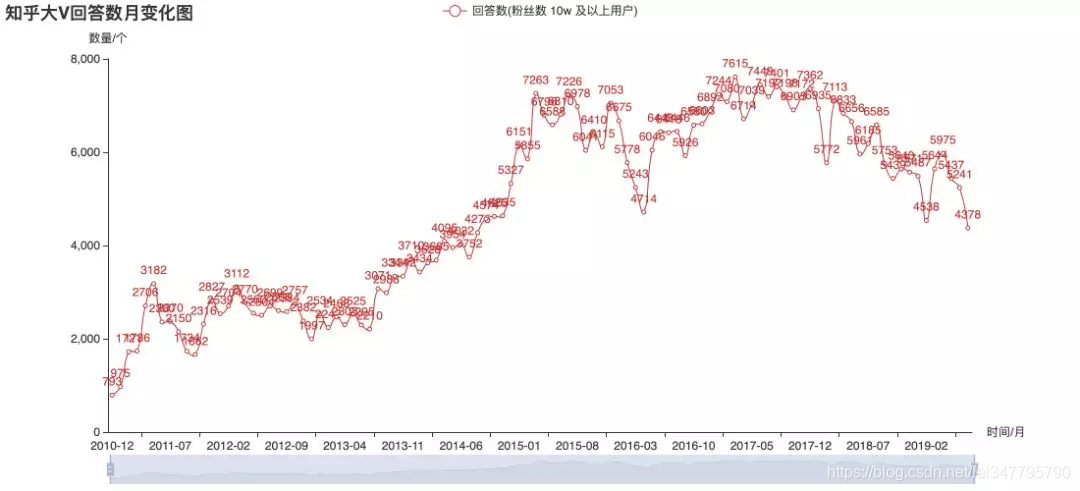
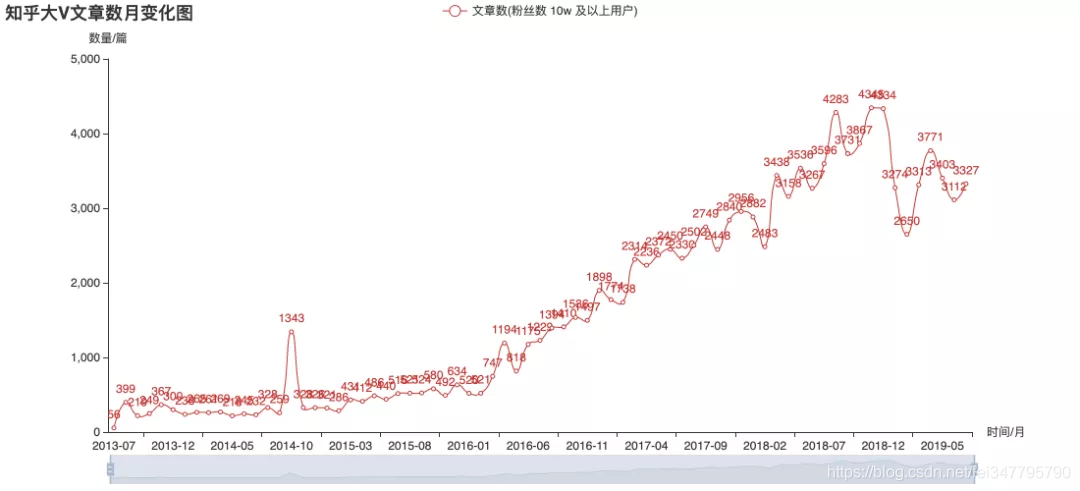
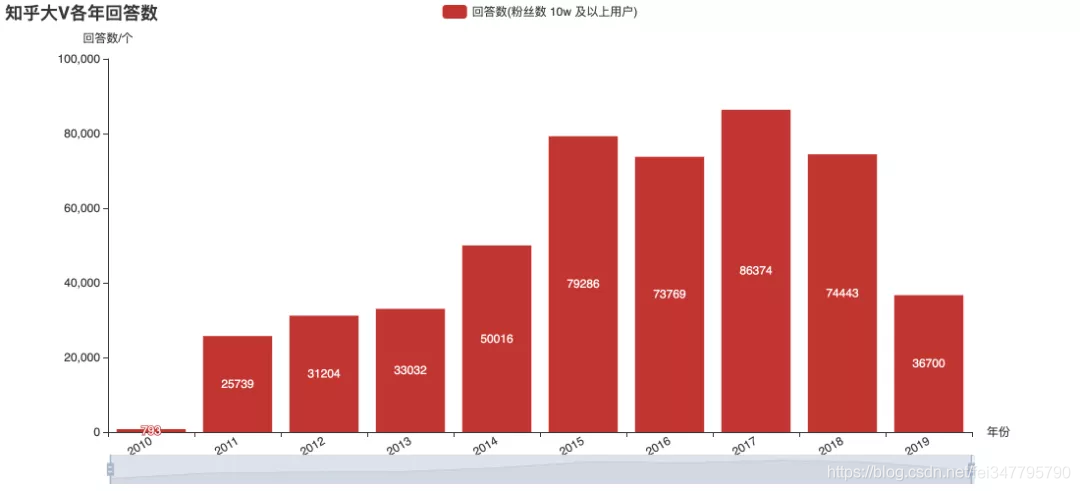
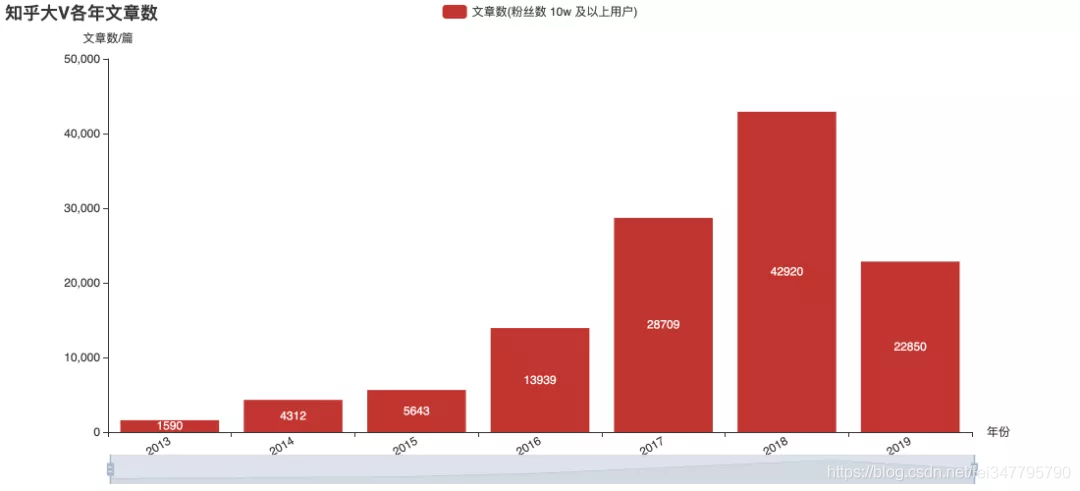
上面几张图是对目前关注数超10万的用户的历史发布数据进行的统计。从图上来看,2015年大V们更热衷于回答,后来则大都改去写专栏文章了。从趋势来看,似乎大V们发文的频率已不再增长。不过这并不能直接推断知乎的整体热度,也可能内容的产出更分散于不同用户了呢?这就只有知乎官方才有权威数据了。
用户爱看什么?
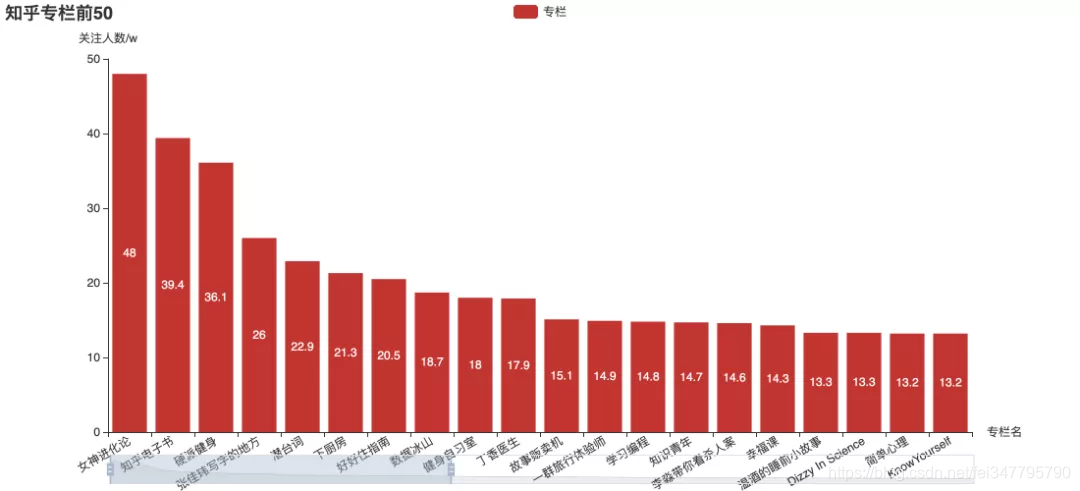
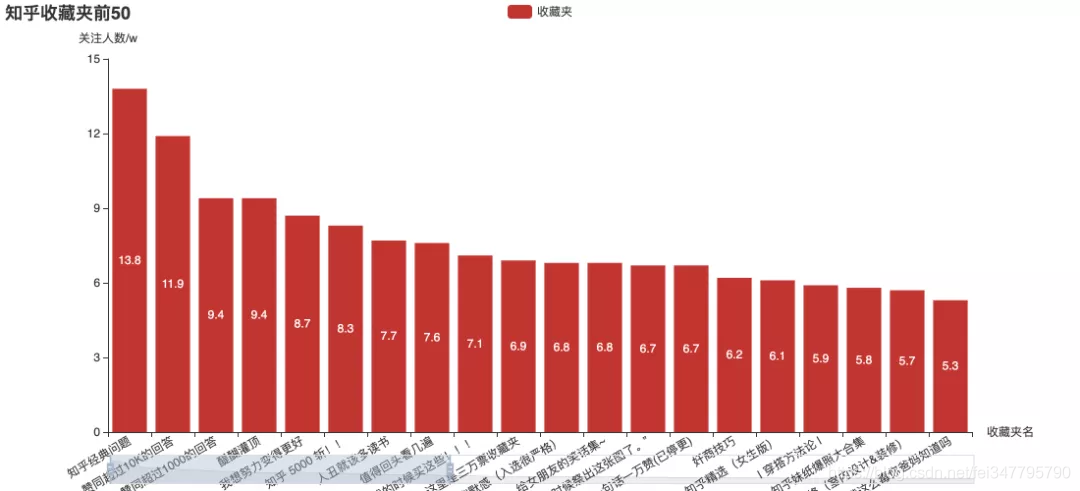
这些关注度最高专栏和收藏夹,里面有你关注的吗?
最后,这是一个以关注数超1万的用户的个人简介做出来的词云:

代码
# coding:utf8
# 抓取粉丝数过 1w 用户
import requests
import pymongo
import time
import pickle
def get_ready(ch='user_pd',dbname='test'):
'''数据库调用'''
global mycol, myclient,myhp
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient[dbname]
mycol = mydb[ch]
get_ready()
ss = mycol.find({})
se = {1,} # 去重集合
se2 = ['GOUKI9999','zhang-jia-wei'] # 爬取的列表
# with open(r'C:\Users\yc\Desktop\used.txt', 'rb') as f: # 读取
# used = pickle.load(f)
used={1,}
sed = {}
for s in ss:
if s['follower_count']>=10000: # 粉丝数大于10000
sed[s['user_id']] = sed.get(s['user_id'],0) + 1
if sed[s['user_id']] == 1:
se.add(s['user_id'])
se2.append(s['user_id'])
leng = len(se2)
print(leng)
proxies = {
"http": "http://spiderbeg:pythonbe@106.52.85.210:8000",
"https": "http://spiderbeg:pythonbe@106.52.85.210:8000",
}
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'cookie':'your_cookie(用户主页面)'
}
for i,url_id in enumerate(se2): # 爬取
if i>=0:
print(i,' ', end='') # url个数
if url_id not in used: # 是否使用过
used.add(url_id)
nums = 500
off = 0 while True:
url2 = 'https://www.zhihu.com/api/v4/members/' + url_id + '/followees?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=' + str(off) + '&limit=' + str(nums)
r2 = requests.get(url2, headers=headers,proxies=proxies)
time.sleep(0.5)
c = 0
if 'error' in r2.json():
if r2.json()['error']['code'] in {310000, 310001}:
break
else:
raise NameError('页面错误')
used.add(url_id) # 判断是否使用
for d in r2.json()['data']:
z = {}
c+=1
z['user_id'] = d['url_token']
z['name'] = d['name']
z['headline'] = d['headline']
z['follower_count'] = d['follower_count']
z['answer_count'] = d['answer_count']
z['articles_count'] = d['articles_count'] # if d['articles_count'] else 0
z['from'] = url_id # 谁的关注列表
if d['follower_count']>=10000 and d['url_token'] not in se and d['url_token'] not in used: # 粉丝大于 1w,则爬取
se.add(d['url_token'])
se2.append(d['url_token'])
mycol.insert_one(z) # 插入数据
if r2.json()["paging"]['is_end'] == False:
nums+=500
off+=500
elif r2.json()["paging"]['is_end'] == True:
break
else:
print(r2.json)
break
Python数据分析揭秘知乎大V的小秘密的更多相关文章
- Python数据分析练手:分析知乎大V
原文链接:https://zhuanlan.zhihu.com/p/92768131?utm_source=tuicool&utm_medium=referral 知乎,可以说是国内目前最大的 ...
- 16、爬取知乎大v张佳玮的文章“标题”、“摘要”、“链接”,并存储到本地文件
爬取知乎大v张佳玮的文章“标题”.“摘要”.“链接”,并存储到本地文件 # 爬取知乎大v张佳玮的文章“标题”.“摘要”.“链接”,并存储到本地文件 # URL https://www.zhihu.co ...
- 为什么学习python?(知乎大神的回答)
学习PHP 是因为得到一份工作 学习Java 是因为他们选修了计算机科学这门课程 学习python 是因为爱这门语言,因为寻求美
- 学一手,知乎大V(轮子哥)当年靠它进微软亚洲研究院
前言 vczh本名陈梓瀚,不过大家更愿意叫他「轮子哥」,毕业于华南理工大学软件学院.vczh大学时代就在微软实习,毕业后即加入微软.开始时是在微软上海,后来进入北京的微软亚洲研究院.现已移居美国西雅图 ...
- 为你揭秘知乎是如何搞AI的——窥大厂 | 数智方法论第1期
文章发布于公号[数智物语] (ID:decision_engine),关注公号不错过每一篇干货. 数智物语(公众号ID:decision_engine)出品 策划.编写:卷毛雅各布 「我们相信,在垃圾 ...
- 《Python金融大数据分析》高清PDF版|百度网盘免费下载|Python数据分析
<Python金融大数据分析>高清PDF版|百度网盘免费下载|Python数据分析 提取码:mfku 内容简介 唯一一本详细讲解使用Python分析处理金融大数据的专业图书:金融应用开发领 ...
- 万字长文,Python数据分析实战,使用Pandas进行数据分析
文章目录 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例的人,却不知道如何去学习更加高深的知识.那么针对这三类人,我给大家 ...
- (python数据分析)第03章 Python的数据结构、函数和文件
本章讨论Python的内置功能,这些功能本书会用到很多.虽然扩展库,比如pandas和Numpy,使处理大数据集很方便,但它们是和Python的内置数据处理工具一同使用的. 我们会从Python最基础 ...
- 小白学 Python 数据分析(10):Pandas (九)数据运算
人生苦短,我用 Python 前文传送门: 小白学 Python 数据分析(1):数据分析基础 小白学 Python 数据分析(2):Pandas (一)概述 小白学 Python 数据分析(3):P ...
随机推荐
- 1+x 证书 Web 前端开发中级理论考试(试卷 8 )含答案
1+x 证书 Web 前端开发中级理论考试(试卷 8 ) 官方QQ群 转载请注明来源:妙笔生花个人博客http://blog.zh66.club/index.php/archives/438/ 一.单 ...
- java对象引用测试
代码 java中初始化一个实例,这个实例对应的只是对象的一个地址,并不是对象本身.将这个实例赋值给别的实例时,新实例也是指向对象的地址,两个实例实际指向的是同一个实例.对新实例赋值,老实例也会同时改变 ...
- ETCD:TLS
原文地址:TLS etcd支持用于客户端到服务器以及对等方(服务器到服务器/集群)通信的自动TLS以及通过客户端证书的身份验证. 要启动并运行,首先要获得一个成员的CA证书和签名密钥对. 建议为集群中 ...
- 多线程七 AQS
一 . 简介AQS AQS简介 在同步组件的实现中,AQS是核心部分,同步组件的实现者,通过使用AQS提供的模板方法 实现同步组件语义 AQS实现了对同步状态的管理以及阻塞线程进行排队,等待通知等等一 ...
- Git原理入门解析
前言: 之前听过公司大佬分享过 Git 原理之后就想来自己总结一下,最近一忙起来就拖得久了,本来想塞更多的干货,但是不喜欢拖太久,所以先出一版足够入门的: 一.Git 简介 Git 是当前流行的分布式 ...
- 本地SQL Server数据库提示网络问题无法连接
运行程序时发现本地SQLserver数据库无法连接,提示信息为:在与SQL Server 建立连接时出现与网络相关的或特定与实例的错误.未能找到或无法访问服务器.请验证实例名称是否正确并且SQL Se ...
- MAC 软件提示已损坏,需要移到废纸篓的解决方法
解决方法一: 允许任何来源的应用.在系统偏好设置里,打开“安全性和隐私”,将“允许从以下位置下载的应用程序”设置为“任何来源“.当然,这个设置已经无法在Mac OS Sierra上完成了. 在Mac ...
- Thymeleaf常用语法:表达式语法之运算符
Thymeleaf表达式语法之常量分为字符串常量.数字常量.布尔值常量.空值常量:运算符分为算术运算符.关系运算符.条件运算符.无操作符. 开发环境:IntelliJ IDEA 2019.2.2Spr ...
- 关于sql sp_send_dbmail 发送邮件的怪异问题
存储过程,其实就是将sp_send_dbmail采用参数的方式发送邮件,存储过程如下: ALTER PROCEDURE [dbo].[SP_Email_Send] @EmailTo varchar(m ...
- gcc-stack-protector机制【转】
转自:https://blog.csdn.net/lhl_blog/article/details/70193865 版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上 ...