爬取https://www.parenting.com/baby-names/boys/earl网站top10男女生名字及相关信息
爬取源代码如下:
import requests
import bs4
from bs4 import BeautifulSoup
import re
import pandas as pd
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') lilist=[] r=requests.get('https://www.parenting.com/baby-names/boys/earl')
soup=BeautifulSoup(r.text,"lxml")
soup= soup.find_all('a',href=True)
for i in soup:
if 'https://www.parenting.com/pregnancy/baby-names/baby-boy-names/' in str(i)or'https://www.parenting.com/pregnancy/baby-names/girl-baby-names/' in str(i):
lilist.append(i.get("href"))
lilist1=[]
results1=[]
results=[]
results2=[] for i in list(set(lilist)):
r=requests.get(i)
soup=BeautifulSoup(r.text,"lxml") Source=soup.find_all('p')
Source=soup.find_all(attrs={'class': 'description'}) results0 = re.findall('<h4>(.*?)</h4>', r.text)
for c in results0:
if c!='':
lilist1.append(c)
#print(lilist1)
#lilist1=[]
pattern = re.compile('<p><strong>Origin:</strong>\s(.*?)</p>', re.S)
results += re.findall(pattern, str(Source)) pattern1 = re.compile('<p><strong>Meaning:</strong>\s(.*?)</p>', re.S)
results1 += re.findall(pattern1, str(Source))
pattern2 = re.compile("<p><strong>Why it’s big:</strong>\s(.*?)</p>", re.S)
results2 += re.findall(pattern2, str(Source)) print(lilist1)
print(results1)
print(results)
print(results2)
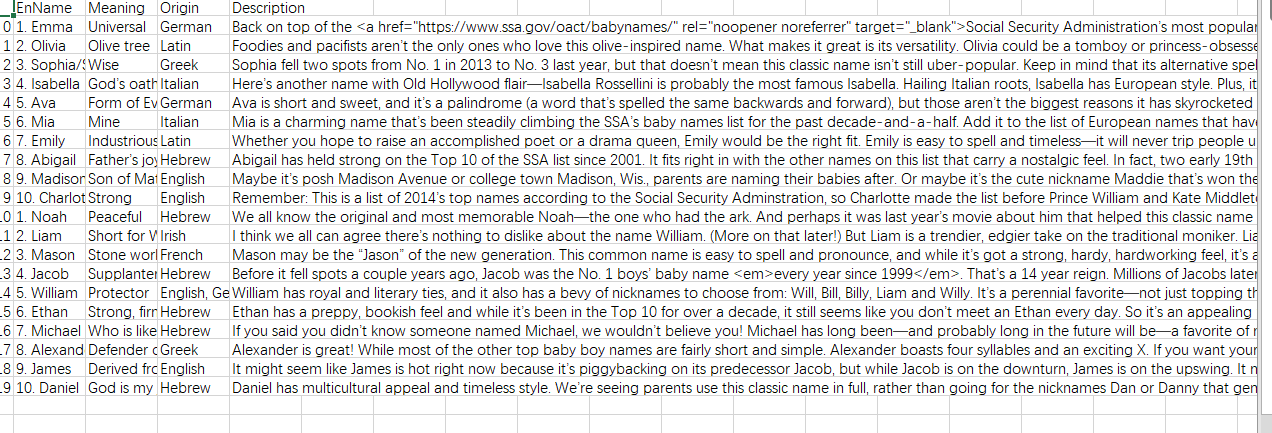
data = {
'EnName':lilist1,
'Meaning':results1,
'Origin':results,
'Description':results2
}
frame = pd.DataFrame(data)
frame.to_csv('wt10.csv',encoding="gb18030")
#print(results2)
爬取https://www.parenting.com/baby-names/boys/earl网站top10男女生名字及相关信息的更多相关文章
- 一个爬取https和http通用的工具类(JDK自带的URL的用法)
今天在java爬取天猫的时候因为ssl报错,所以从网上找了一个可以爬取https和http通用的工具类.但是有的时候此工具类爬到的数据不全,此处不得不说python爬虫很厉害. package cn. ...
- 解决:Python爬取https站点时SNIMissingWarning和InsecurePlatformWarning
今天想利用Requests库爬取糗事百科站点,写了一个请求,却报错了: 后来参考kinsomy的博客,在cmd中pip install pyopenssl ndg-httpsclient pyasn1 ...
- 爬取https页面遇到“SSLError: hostname 'xxx' doesn't match either of”的解决方法
使用python requests 框架包访问https://itunes.apple.com 页面是遇到 SSLError: hostname 'itunes.apple.com' doesn't ...
- java爬虫爬取https协议的网站时,SSL报错, java.lang.IllegalArgumentException TSLv1.2 报错
目前在广州一家小公司实习,这里的学习环境还是挺好的,今天公司从业十几年的大佬让我检查一下几年前的爬虫程序是否还能使用…… 我从myeclipse上check out了大佬的程序,放到workspace ...
- pyspider爬取tourism management 所有文章的标题 作者 摘要 关键词等等所有你想要的信息
#!/usr/bin/env python # -*- encoding: utf-8 -*- # vim: set et sw=4 ts=4 sts=4 ff=unix fenc=utf8: # C ...
- python爬取酒店信息练习
爬取酒店信息,首先知道要用到那些库.本次使用request库区获取网页,使用bs4来解析网页,使用selenium来进行模拟浏览. 本次要爬取的美团网的蚌埠酒店信息及其评价.爬取的网址为“http:/ ...
- Python 利用 BeautifulSoup 爬取网站获取新闻流
0. 引言 介绍下 Python 用 Beautiful Soup 周期性爬取 xxx 网站获取新闻流: 图 1 项目介绍 1. 开发环境 Python: 3.6.3 BeautifulSoup: ...
- python网络爬虫之解析网页的BeautifulSoup(爬取电影图片)[三]
目录 前言 一.BeautifulSoup的基本语法 二.爬取网页图片 扩展学习 后记 前言 本章同样是解析一个网页的结构信息 在上章内容中(python网络爬虫之解析网页的正则表达式(爬取4k动漫图 ...
- 教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http://www.xiaohuar.com/,让你体验爬取校花的成就感. Scr ...
随机推荐
- VSCode, Django, and Anaconda开发环境集成配置[Windows]
之前一直是在Ubuntu下进行Python和Django开发,最近换了电脑,把在Virtual Box 下跑的Ubuntu开发机挪过来总是频繁崩溃,索性就尝试把开发环境挪到Windows主力机了. 不 ...
- Java方法之定义形式及可变参数
目录 Java方法之定义形式及可变参数 方法调用 使用static修饰的方法 没有static修饰的方法 方法的定义格式 无参无返 无参有返 有参无返 有参有返 形参个数可变的方法 采用数组形参来定义 ...
- java程序员面试答题技巧
答题时,先答是什么,再答有什么作用和要注意什么(这部分最重要,展现自己的心得) 答案的段落分别,层次分明,条理清晰都非常重要,从这些表面的东西也可以看出一个人的 习惯.办事风格.条理等. 要讲你做出答 ...
- oc工程中oc、swift混编代码打包成静态framework踩坑笔记
参考资料: https://www.jianshu.com/p/734341f7c242 https://www.jianshu.com/p/55038871e7de 两天时间探索,期间不知道遇到 ...
- 带着canvas去流浪系列之七 绘制水球图
[摘要] 用原生canvasAPI实现百度echarts 示例代码托管在:http://www.github.com/dashnowords/blogs 一. 任务说明 使用原生canvasAPI绘制 ...
- 关于Python中的错误与异常,你是否了解的够仔细?
每次版本结束都描述这着同样的错误,相似的问题,但始终没见解决.所以今天,我就来总结下Python的错误与异常! 异常与错误 错误 语法错误 可以通过IDE或者解释器给出提示的错误 opentxt('a ...
- 基于webpack实现多html页面开发框架一 准备工作
本系列主要介绍如何基于webpack实现多html页面开发框架,这里不讲webpack的基本概念,废话不多说,直奔主题! 前置条件: 1.安装node环境,自己去官网下载安装 2.新建文件夹webpa ...
- Asp.net Core 3.0 Identity 使用smtp账户确认和密码恢复
当新建一个core项目后,使用identity基架后,确认邮件出现了错误,并不能正常使用. 建立文档在这里 https://docs.microsoft.com/zh-cn/aspnet/core/s ...
- Redis 中的数据库
前面我们花了很多的时间介绍了 redis 中基本的数据结构,及其内部的实现情况,这些都是非常基础的东西,可能不经意间你就会用到他们,希望你花点时间了解一下. 接下来,我们将走近 redis 数据库,学 ...
- apache thrift 和 apache jersey 记录
几篇好的入门文档链接: 1. Hello World by Thrift Using Java 2. Thrift 实例 Helloworld 3. Thrift版的Hello World 4. Th ...