HDFS之DataNode
DataNode工作机制
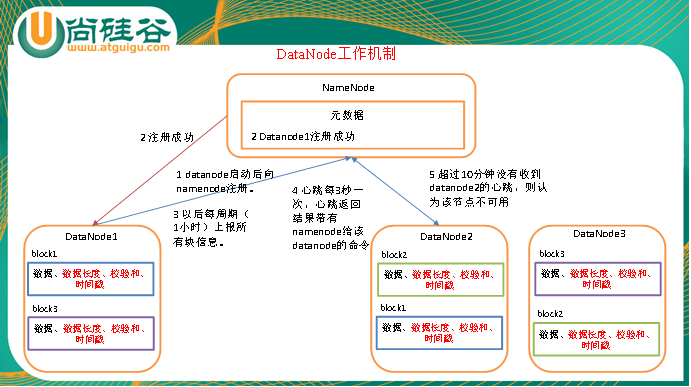
1)一个数据块在datanode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
2)DataNode启动后向namenode注册,通过后,周期性(1小时)的向namenode上报所有的块信息。
3)心跳是每3秒一次,心跳返回结果带有namenode给该datanode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个datanode的心跳,则认为该节点不可用。
4)集群运行中可以安全加入和退出一些机器
数据完整性
1)当DataNode读取block的时候,它会计算checksum
2)如果计算后的checksum,与block创建时值不一样,说明block已经损坏。
3)client读取其他DataNode上的block.
4)datanode在其文件创建后周期验证checksum
掉线时限参数设置
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval。
而默认的dfs.namenode.heartbeat.recheck-interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
|
<property> <name>dfs.namenode.heartbeat.recheck-interval</name> <value>300000</value> </property> <property> <name> dfs.heartbeat.interval </name> <value>3</value> </property> |
服役新数据节点
(1)在namenode的/opt/module/hadoop-2.7.2/etc/hadoop目录下创建dfs.hosts文件
[atguigu@hadoop105 hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[atguigu@hadoop105 hadoop]$ touch dfs.hosts
[atguigu@hadoop105 hadoop]$ vi dfs.hosts
添加如下主机名称(包含新服役的节点)
hadoop102
hadoop103
hadoop104
hadoop105
(2)在namenode的hdfs-site.xml配置文件中增加dfs.hosts属性
|
<property> <name>dfs.hosts</name> <value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts</value> </property> |
(3)刷新namenode
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
(4)更新resourcemanager节点
[atguigu@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
(5)在namenode的slaves文件中增加新主机名称
增加105 不需要分发
hadoop102
hadoop103
hadoop104
hadoop105
(6)单独命令启动新的数据节点和节点管理器
[atguigu@hadoop105 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
[atguigu@hadoop105 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
(7)在web浏览器上检查是否ok
3)如果数据不均衡,可以用命令实现集群的再平衡
[atguigu@hadoop102 sbin]$ ./start-balancer.sh
退役旧数据节点
1)在namenode的/opt/module/hadoop-2.7.2/etc/hadoop目录下创建dfs.hosts.exclude文件
[atguigu@hadoop102 hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[atguigu@hadoop102 hadoop]$ touch dfs.hosts.exclude
[atguigu@hadoop102 hadoop]$ vi dfs.hosts.exclude
添加如下主机名称(要退役的节点)
hadoop105
2)在namenode的hdfs-site.xml配置文件中增加dfs.hosts.exclude属性
|
<property> <name>dfs.hosts.exclude</name> <value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts.exclude</value> </property> |
3)刷新namenode、刷新resourcemanager
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
[atguigu@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
4)检查web浏览器,退役节点的状态为decommission in progress(退役中),说明数据节点正在复制块到其他节点。
5)等待退役节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。注意:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役。
[atguigu@hadoop105 hadoop-2.7.2]$ sbin/hadoop-daemon.sh stop datanode
[atguigu@hadoop105 hadoop-2.7.2]$ sbin/yarn-daemon.sh stop nodemanager
6)从include文件中删除退役节点,再运行刷新节点的命令
(1)从namenode的dfs.hosts文件中删除退役节点hadoop105
hadoop102
hadoop103
hadoop104
(2)刷新namenode,刷新resourcemanager
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
[atguigu@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
7)从namenode的slave文件中删除退役节点hadoop105
hadoop102
hadoop103
hadoop104
8)如果数据不均衡,可以用命令实现集群的再平衡
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-balancer.sh
HDFS之DataNode的更多相关文章
- HDFS Namenode&Datanode
HDFS Namenode&Datanode HDFS 机制粗略示意图 客户端写入文件流程: NN && DN Namenode(NN)工作机制 NN是整个文件系统的管理节点. ...
- org.apache.hadoop.hdfs.server.datanode.DataNode: Exception in receiveBlock for block
Hbase依赖的datanode日志中如果出现如下报错信息:DataXceiverjava.io.EOFException: INFO org.apache.hadoop.hdfs.server.da ...
- Datanode启动问题 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool <registering>
-- ::, INFO org.apache.hadoop.hdfs.server.datanode.DataNode: supergroup = supergroup -- ::, INFO org ...
- ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: Incompatible namespaceIDs
用三台centos操作系统的机器搭建了一个hadoop的分布式集群.启动服务后失败,查看datanode的日志,提示错误:ERROR org.apache.hadoop.hdfs.server.dat ...
- FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool <registering> (Datanode Uuid unassigned) service to controller/192.168.1.183:9000. Exiting. java.io.IOExcep
2018-01-09 09:47:38,297 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed ...
- hdfs.server.datanode.DataNode: Block pool ID needed, but service not yet registered with NN
启动hadoop 发现 50070 的 livenode 数量是 0 查看日志, hdfs.server.datanode.DataNode: Block pool ID needed, but se ...
- Hadoop启动HDFS时DataNode未启动
在用$HADOOP_HOME/sbin/start-dfs.sh启动HDFS时发现只有NameNode和SecondaryNameNode启动,没有DataNode. 查看logs下的DataNode ...
- 启动HDFS时datanode无法启动的坑
启动HDFS 启动hdfs,进入sbin目录,也可以执行./start-all.sh - $cd /app/hadoop/hadoop-2.2.0/sbin - $./start-dfs.sh 在此之 ...
- hdfs的datanode工作原理
datanode的作用: (1)提供真实文件数据的存储服务. (2)文件块(block):最基本的存储单位.对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序 ...
- hdfs namenode/datanode工作机制
一. namenode工作机制 1. 客户端上传文件时,namenode先检查有没有同名的文件,如果有,则直接返回错误信息.如果没有,则根据要上传文件的大小以及block的大小,算出需要分成几个blo ...
随机推荐
- Nginx 了解一下?
这篇文章主要简单的介绍下 Nginx 的相关知识,主要包括以下几部分内容: Nginx 适用于哪些场景? 为什么会出现 Nginx? Nginx 优点 Nginx 的编译与配置 Nginx 适用于哪些 ...
- 数据结构(四十七)归并排序(O(nlogn))
一.归并排序的定义 归并排序(Merging Sort)就是利用归并的思想实现的排序方法.它的原理是假设初始序列含有n个记录,则可以看成是n个有序的子序列,每个子序列的长度为1,然后两两归并,得到[n ...
- (记录)Ubuntu系统中运行需要导入jar包的Java程序
在学习Redis的过程中,在学到Redis客户端Jedis的时候,考虑到能不能在ubuntu下用Vim编写Java程序并且能够运行呢? 于是,首先在网上调研了一番用Vim写Java程序的可实现性. 相 ...
- c#中关于string的特性介绍以及注意事项
前言 string类型在我们实际项目开发中是一个最使用的类型,string是一个引用类型这一点大家都知道,但是在实际使用过程中,大家会发现string和我们常见的引用类型使用还真不一样,看下面的一个简 ...
- IDEA 使用lombok
一.配置maven <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback ...
- 清华大学教学内核ucore学习系列(1) bootloader
ucore是清华大学操作系统课程的实验内核,也是一个开源项目,是不可多得的非常好的操作系统学习资源 https://github.com/chyyuu/ucore_lab.git, 各位同学可以使用g ...
- 【java基础】程序员你真的理解反射机制吗?
目录 前言 1.反射的概述 2.正式使用反射之前很有必要了解的Class类 3.反射的使用 前言 很多讲解反射的博客文章并没有详细讲解Class类,~当然包括之前的我也一样~,这样的文章只会让反射徒有 ...
- NOIP模(ka)拟(chang)测试30 考试报告
应得分:300 实得分:210 毒瘤卡常出题人,卡掉90分! T1 Return 开个副本数组sort一下,unique去重就可以啦.时间复杂度$ O(nlog2(n)) $ T2 One 其实就是约 ...
- 原生JS实现双向链表
1.前言 双向链表和单向链表的区别在于,在链表中,一个节点只有链向下一个节点的链接,而在双向链表中,链接是双向的:一个链向下一个元素,另一个链向前一个元素,如下图所示: 从图中可以看到,双向链表中,在 ...
- 浅谈 KMP 算法
最近在复习数据结构,学到了 KMP 算法这一章,似乎又迷糊了,记得第一次学习这个算法时,老师在课堂上讲得唾沫横飞,十分有激情,而我们在下面听得一脸懵比,啥?这是个啥算法?啥玩意?再去看看书,完全听不懂 ...