mybatis 源码分析(二)mapper 初始化
mybatis 的初始化还是相对比较复杂,但是作者在初始化过程中使用了多种设计模式,包括建造者、动态代理、策略、外观等,使得代码的逻辑仍然非常清晰,这一点非常值得我们学习;
一、mapper 初始化主要流程
mybatis 初始化的过程中,主要是 XML 配置的解析,不同的部分又分别委托给了不同的解析器;

解析流程为:
XMLConfigBuilder -> XMLMapperBuilder -> XMLStatementBuilder -> XMLScriptBuilder -> SqlSourceBuilder
- XMLConfigBuilder:负责全局的 mybatis-conf.xml 配置解析;
- XMLMapperBuilder:负责 sql 配置的 mapper 配置解析;
- XMLStatementBuilder:负责 mapper 配置文件中 select|insert|update|delete 节点解析;
- XMLScriptBuilder:负责各 sql 节点解析,主要是动态 sql 解析;
- SqlSourceBuilder:负责构建 SqlSource;
源码分析:
首先在 XMLConfigBuilder 确定了主要的解析流程:
private void parseConfiguration(XNode root) { // 解析的代码和xml的配置一一对应
try {
//issue #117 read properties first
propertiesElement(root.evalNode("properties"));
Properties settings = settingsAsProperties(root.evalNode("settings"));
loadCustomVfs(settings);
loadCustomLogImpl(settings);
typeAliasesElement(root.evalNode("typeAliases"));
pluginElement(root.evalNode("plugins"));
objectFactoryElement(root.evalNode("objectFactory"));
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
reflectorFactoryElement(root.evalNode("reflectorFactory"));
settingsElement(settings);
// read it after objectFactory and objectWrapperFactory issue #631
environmentsElement(root.evalNode("environments"));
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
typeHandlerElement(root.evalNode("typeHandlers"));
mapperElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}
private void mapperElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
if ("package".equals(child.getName())) { // package 方式,mapper 必须和 xml 配置文件在同一目录下
String mapperPackage = child.getStringAttribute("name");
configuration.addMappers(mapperPackage);
} else {
String resource = child.getStringAttribute("resource");
String url = child.getStringAttribute("url");
String mapperClass = child.getStringAttribute("class");
if (resource != null && url == null && mapperClass == null) {
ErrorContext.instance().resource(resource);
InputStream inputStream = Resources.getResourceAsStream(resource);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url != null && mapperClass == null) {
ErrorContext.instance().resource(url);
InputStream inputStream = Resources.getUrlAsStream(url);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url == null && mapperClass != null) {
Class<?> mapperInterface = Resources.classForName(mapperClass);
configuration.addMapper(mapperInterface);
} else {
throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one.");
}
}
}
}
}
然后在 XMLMapperBuilder 中解析 mapper
public void parse() {
if (!configuration.isResourceLoaded(resource)) {
configurationElement(parser.evalNode("/mapper"));
configuration.addLoadedResource(resource);
bindMapperForNamespace(); // 绑定 mapper 和 xml 配置
}
// 下面的三个方式是继续之前未完成的节点解析;比如在 cache-ref 解析的时候,依赖的 cache namespace 还未创建的时候,就需要暂停
parsePendingResultMaps();
parsePendingCacheRefs();
parsePendingStatements();
}
private void cacheRefElement(XNode context) {
if (context != null) {
configuration.addCacheRef(builderAssistant.getCurrentNamespace(), context.getStringAttribute("namespace"));
CacheRefResolver cacheRefResolver = new CacheRefResolver(builderAssistant, context.getStringAttribute("namespace"));
try {
cacheRefResolver.resolveCacheRef(); // 未找到依赖的 cache 时,暂停解析
} catch (IncompleteElementException e) {
configuration.addIncompleteCacheRef(cacheRefResolver);
}
}
}
二、动态 sql 解析
此外在 mapper 各节点的解析过程中 resultMap 和 sql 节点的解析最为复杂,resultMap 解析主要是 xml 和 反射的处理,有一点繁琐有兴趣可以自己看一下;这里主要讲一下 sql 节点的解析要点;
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
private void buildStatementFromContext(List<XNode> list, String requiredDatabaseId) {
for (XNode context : list) {
final XMLStatementBuilder statementParser = new XMLStatementBuilder(configuration, builderAssistant, context, requiredDatabaseId);
try {
statementParser.parseStatementNode(); // 主要的解析过程放到了XMLStatementBuilder中
} catch (IncompleteElementException e) {
configuration.addIncompleteStatement(statementParser);
}
}
}
// XMLStatementBuilder
public void parseStatementNode() {
...
String parameterType = context.getStringAttribute("parameterType");
Class<?> parameterTypeClass = resolveClass(parameterType);
String lang = context.getStringAttribute("lang");
LanguageDriver langDriver = getLanguageDriver(lang);
// Parse selectKey after includes and remove them.
processSelectKeyNodes(id, parameterTypeClass, langDriver);
// Parse the SQL (pre: <selectKey> and <include> were parsed and removed)
KeyGenerator keyGenerator;
String keyStatementId = id + SelectKeyGenerator.SELECT_KEY_SUFFIX;
keyStatementId = builderAssistant.applyCurrentNamespace(keyStatementId, true);
if (configuration.hasKeyGenerator(keyStatementId)) {
keyGenerator = configuration.getKeyGenerator(keyStatementId);
} else {
keyGenerator = context.getBooleanAttribute("useGeneratedKeys",
configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType))
? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
}
SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
...
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets);
}
代码中的 LanguageDriver 就封装了动态 sql 的解析规则,通过这个接口也可以使用其他的模版引擎或者解析规则(可以通过配置或者注解指定);
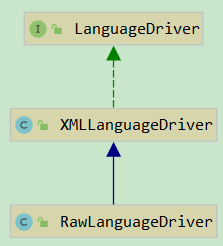
其中 XMLLanguageDriver 主要处理动态 sql,RawLanguageDriver 主要处理静态 sql;
从代码中可以看到最后 LanguageDriver 将 xml 配置解析成了 SqlSource,其结构如下:

其中:
- RawSqlSource:处理静态sql,去掉xml标签;
- DynamicSqlSource:处理动态sql,去掉xml标签;
- ProviderSqlSource:处理注解形式的sql;
- StaticSqlSource:最终将上面 SqlSource 处理结果中的占位符,替换为 "?",构成真正可执行的sql;
其解析的整体流程如下:
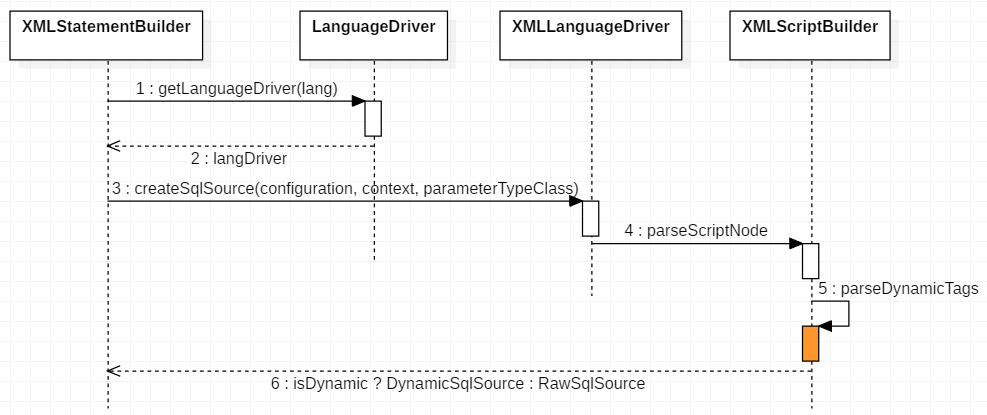
从图中可以看到 sql 节点的主要解析逻辑就在于 parseDynamicTags,MixedSqlNode rootSqlNode = parseDynamicTags(context);
在看源码之前先看一下 SqlNode 的结构;

这里的每个 node 和 sql 节点下的子节点一一对应;
protected MixedSqlNode parseDynamicTags(XNode node) {
List<SqlNode> contents = new ArrayList<>();
NodeList children = node.getNode().getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
XNode child = node.newXNode(children.item(i));
if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {
String data = child.getStringBody("");
TextSqlNode textSqlNode = new TextSqlNode(data);
if (textSqlNode.isDynamic()) {
contents.add(textSqlNode);
isDynamic = true;
} else {
contents.add(new StaticTextSqlNode(data));
}
} else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) { // issue #628
String nodeName = child.getNode().getNodeName();
NodeHandler handler = nodeHandlerMap.get(nodeName);
if (handler == null) {
throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
}
handler.handleNode(child, contents);
isDynamic = true;
}
}
return new MixedSqlNode(contents);
}
这里主要逻辑是首先通过子标签的名字,获取对应的处理器,然后将所有的子标签生成的 SqlNode 合成 MixedSqlNode;

private void initNodeHandlerMap() {
nodeHandlerMap.put("trim", new TrimHandler());
nodeHandlerMap.put("where", new WhereHandler());
nodeHandlerMap.put("set", new SetHandler());
nodeHandlerMap.put("foreach", new ForEachHandler());
nodeHandlerMap.put("if", new IfHandler());
nodeHandlerMap.put("choose", new ChooseHandler());
nodeHandlerMap.put("when", new IfHandler());
nodeHandlerMap.put("otherwise", new OtherwiseHandler());
nodeHandlerMap.put("bind", new BindHandler());
}
到这里就已经比较清楚了,这个 sql 节点的解析过程使用的是策略模式,整个 sql 节点被封装成 SqlSource,其子节点封装为 SqlNode,每个 Node 的解析行为又封装到 NodeHandler 中;整个流程虽然比较长,但是每个模块都非常的清晰,这里非常值得我们学习;
三、mapper 动态代理
首先简单看一个动态代理的 demo
interface Car { void run(String name); }
@Test
public void testDynamic() {
Car car = (Car) Proxy.newProxyInstance(
Car.class.getClassLoader(), // 代理目标的类加载器
new Class[]{Car.class}, // 代理的接口数组,因为可以实现多个接口
new InvocationHandler() { // 动态代理的逻辑代码
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("----动态代理开始----");
// 目标逻辑代码
System.out.println("----动态代理结束----");
return null;
}
});
car.run("sdf");
}
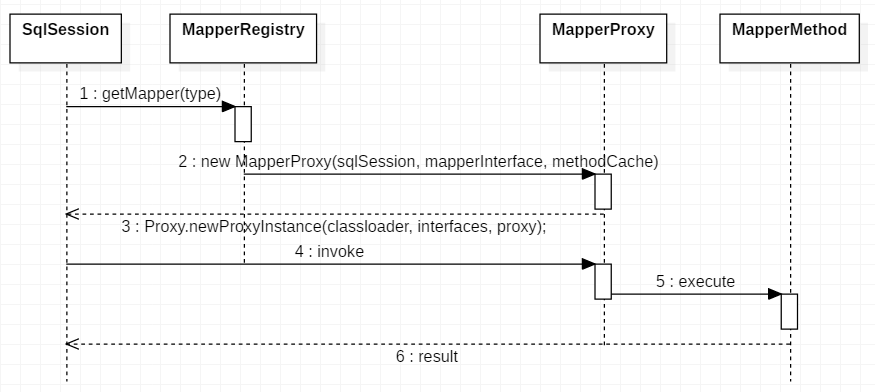
从上面的代码可以看到,我们只定义一个接口并没有实现类,但是通过动态代理就可以动态生成实现类;在使用 mapper 的时候也是一样的,每次调用mapper方法的时候,都会动态生成一个实现类;
初始化:
// MapperRegistry
public <T> void addMapper(Class<T> type) {
if (type.isInterface()) {
if (hasMapper(type)) {
throw new BindingException("Type " + type + " is already known to the MapperRegistry.");
}
boolean loadCompleted = false;
try {
knownMappers.put(type, new MapperProxyFactory<>(type)); // 为每一个接口添加一个动态代理工厂
MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type); // 解析注解配置
parser.parse();
loadCompleted = true;
} finally {
if (!loadCompleted) {
knownMappers.remove(type);
}
}
}
}
使用:
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
其主要流程大致如下:
mybatis 源码分析(二)mapper 初始化的更多相关文章
- Mybatis源码分析之Mapper的创建和获取
Mybatis我们一般都是和Spring一起使用的,它们是怎么融合到一起的,又各自发挥了什么作用? 就拿这个Mapper来说,我们定义了一个接口,声明了一个方法,然后对应的xml写了这个sql语句, ...
- mybatis源码分析二
这次分析mybatis的xml文件 1. <?xml version="1.0" encoding="UTF-8" ?> <configura ...
- MyBatis源码分析(二)
MyBatis的xml配置(核心配置) configuration(配置) properties(属性) settings(设置) typeAliases(类型别名) typeHandlers(类型处 ...
- Mybatis源码分析之Mapper执行SQL过程(三)
上两篇已经讲解了SqlSessionFactory的创建和SqlSession创建过程.今天我们来分析myabtis的sql是如何一步一步走到Excutor. 还是之前的demo public ...
- Mybatis源码分析之Mapper文件解析
感觉CSDN对markdown的支持不够友好,总是伴随各种问题,很恼火! xxMapper.xml的解析主要由XMLMapperBuilder类完成,parse方法来完成解析: public void ...
- mybatis 源码分析二
1.SqlSession下的四大对象 Executor.StatementHandler.ParameterHandler.ResultSetHandler StatementHandler的作用是使 ...
- 精尽MyBatis源码分析 - MyBatis初始化(二)之加载Mapper接口与XML映射文件
该系列文档是本人在学习 Mybatis 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释(Mybatis源码分析 GitHub 地址.Mybatis-Spring 源码分析 GitHub ...
- 精尽 MyBatis 源码分析 - MyBatis 初始化(一)之加载 mybatis-config.xml
该系列文档是本人在学习 Mybatis 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释(Mybatis源码分析 GitHub 地址.Mybatis-Spring 源码分析 GitHub ...
- 精尽 MyBatis 源码分析 - MyBatis 初始化(三)之 SQL 初始化(上)
该系列文档是本人在学习 Mybatis 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释(Mybatis源码分析 GitHub 地址.Mybatis-Spring 源码分析 GitHub ...
- 精尽MyBatis源码分析 - MyBatis初始化(四)之 SQL 初始化(下)
该系列文档是本人在学习 Mybatis 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释(Mybatis源码分析 GitHub 地址.Mybatis-Spring 源码分析 GitHub ...
随机推荐
- linux_硬链接和软链接区别
硬链接有点类似于复制的概念. ln 源文件 目的文件 ln不加-s,则默认是硬链接.例如,ln script script-hard,ls命令显示,script*显示硬链接有两个.我任意删 ...
- WinForm控件之【ListView】
基本介绍 项列表控件,拥有五种不同视图的样式供展示项集合. 常设置属性 Columns:‘详细信息’视图中用来显示的列: Groups:ListView列表中的组,将列表各项分组区域展示: Horiz ...
- MyBatis 一对多映射
From<MyBatis从入门到精通> <!-- 6.1.2.1 collection集合的嵌套结果映射 和association类似,集合的嵌套结果映射就是指通过一次SQL查询将所 ...
- 【动态规划例题-数塔问题】-C++
描述 观察下面的数字金字塔.写一个程序查找从最高点到底部任意处结束的路径,使路径经过数字的和最大.每一步可以 从当前点走到左下方的点也可以到达右下方的点. 在上面的样例中,从13到8到26到15到24 ...
- python爬虫常用正则表达式组合匹配
["\']匹配什么?(.*?)匹配什么? ["\'] ----------- 匹配单双引号 (.*?)xxx ----------- 匹配任意长度字符+xxx ...
- 一文带你了解git
git简介 什么是git? git是当今世界上最先进的分布式的版本控制系统. 版本控制系统分集中式的和分布式的,集中式的主要代表有CVS.SVN,而Git是分布式版本控制系统的佼佼者. 那什么是集中式 ...
- python红蓝英雄大乱斗(面向对象实现)
红蓝英雄大乱斗 游戏规则 ''' 有红蓝两方英雄(可自定义个数) 随机一方英雄使用随机攻击方式攻击另一方英雄,任意一方英雄全部阵亡则游戏结束 每个英雄有 名字.生命值.普通攻击.Q技能攻击.W技能攻击 ...
- 【MySQL】(二)InnoDB存储引擎
InnoDB是事务安全的MySQL存储引擎,设计上采用了类似于Oracel数据库的架构.通常来说,InnoDB存储引擎是OLTP应用中核心表的首选存储引擎.同时,也正是因为InnoDB的存在,才使My ...
- Java EE API
百度云:链接:http://pan.baidu.com/s/1nvTlMLb 密码:vulq 官方下载网址:http://www.oracle.com/technetwork/java/jav ...
- 小白学python-day05(2)-列表及其操作
今天是day05(2),以下是学习总结 但行努力,莫问前程. --------------------------------------------------------------------- ...