Hadoop学习(5)-zookeeper的安装和命令行,java操作
zookeeper是干嘛的呢
Zookeeper的作用
1.可以为客户端管理少量的数据kv
key:是以路径的形式表示的,那就意味着,各key之间有父子关系,比如
/ 是顶层key
用户建的key只能在/ 下作为子节点,比如建一个key: /aa 这个key可以带value数据
也可以建一个key: /bb
也可以建key: /aa/xx
2.可以为客户端监听指定数据节点的状态,并在数据节点发生变化是,通知客户端
Zookeeper 安装步骤
把包上传linux后解压到apps/
[root@hdp-01 ~]# tar -zxvf zookeeper-3.4.6.tar.gz -C apps/
/root/apps/zookeeper-3.4.6/conf下该配置文件
[root@hdp-01 conf]# cp zoo_sample.cfg zoo.cfg
然后vim zoo.cfg
更改为
dataDir=/root/zkdata
最后添加
server.1=hdp-01:2888:3888
server.2=hdp-02:2888:3888
server.3=hdp-03:2888:3888
server.4=hdp-04:2888:3888
接着,在hdp-01上,新建数据目录/root/zkdata,并在目录重生成一个文件myid,内容为1
接着,在hdp-02上,新建数据目录/root/zkdata,并在目录重生成一个文件myid,内容为2
接着,在hdp-03上,新建数据目录/root/zkdata,并在目录重生成一个文件myid,内容为3
接着,在hdp-04上,新建数据目录/root/zkdata,并在目录重生成一个文件myid,内容为4
然后将zookeeper scp给其他机器
启动
[root@hdp-01 ~]# /root/apps/zookeeper-3.4.6/bin/zkServer.sh start
查看状态
[root@hdp-01 ~]# /root/apps/zookeeper-3.4.6/bin/zkServer.sh status
可以自己写一个脚本进行启动名字叫zkmanage.sh
用的时候后面跟上参数,传入$1.
sh ./zkmanage.sh start
或者关闭的时候
sh ./zkmanager.sh stop
脚本代码如下

#!/bin/bash
for host in hdp-01 hdp-02 hdp-03 hdp-04
do
echo "${host}:starting...."
ssh $host "/root/apps/zookeeper-3.4.6/bin/zkServer.sh $1"
done
sleep 2
for host in hdp-01 hdp-02 hdp-03 hdp-04
do
ssh $host "/root/apps/zookeeper-3.4.6/bin/zkServer.sh status"
done
注意一点,如果有的结点没有启动,一定要看一下是不是这几台机器的时间是不是不对应,如果差别太大是启动不起来的。f**k.
简单补充一点就是,启动之后,这几台机器,有的当leader,有的当follower,只有一个leader,他们谁当leader是根据他们 '投票的形式'的决定的。
只有一个leader
zookeeper的命令行客户端和java客户端
命令行
在bin/zkCli.sh
这样会连到本机localhost
指定连到哪一台zookeeper
bin/zkcli.sh –server hdp-02:2181
两个作用,管理数据和监听
首先是管理数据
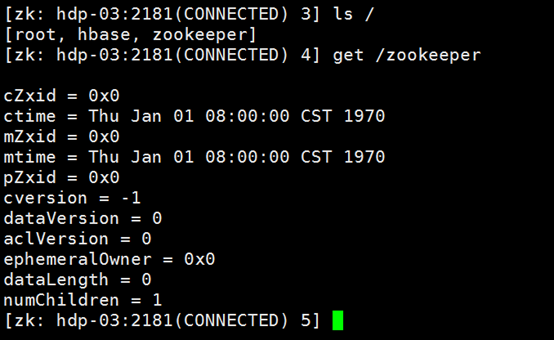
也可以自己建数据
[zk: hdp-03:2181(CONNECTED) 8] create /aa "hellozk"
created /aa
[zk: hdp-03:2181(CONNECTED) 9] ls /
[aa, root, hbase, zookeeper]
[zk: hdp-03:2181(CONNECTED) 10] get /aa
"hellozk"
cZxid = 0xc00000023
ctime = Mon Aug 05 14:41:52 CST 2019
mZxid = 0xc00000023
mtime = Mon Aug 05 14:41:52 CST 2019
pZxid = 0xc00000023
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 9
numChildren = 0
修改数据
[zk: hdp-03:2181(CONNECTED) 11] set /aa hellospark
cZxid = 0xc00000023
ctime = Mon Aug 05 14:41:52 CST 2019
mZxid = 0xc00000024
mtime = Mon Aug 05 14:42:40 CST 2019
pZxid = 0xc00000023
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 10
numChildren = 0
这个数据版本,你没修改几次就会变成几
也可以在/aa下建立子目录
如果有些命令忘了,可以输入help查看帮助
删除就是rmr
[zk: hdp-03:2181(CONNECTED) 13] rmr /aa
监听
[zk: hdp-03:2181(CONNECTED) 17] create /aa iamfine
Created /aa
[zk: hdp-03:2181(CONNECTED) 18] get /aa watch
然后这时候如果改变了/aa 就让他通知我
在另一台机器上启动一个zookeeper
[zk: hdp-03:2181(CONNECTED) 2] set /aa iamnotfine
此时就会有信息

但当你再改一次的话,这个连接就不会再提醒了,这个监听只起一次作用。
数据类型分为好几种
zookeeper中的znode有多种类型:
1、PERSISTENT 持久的:创建者就算跟集群断开联系,该类节点也会持久存在与zk集群中
2、EPHEMERAL 短暂的:创建者一旦跟集群断开联系,zk就会将这个节点删除
3、SEQUENTIAL 带序号的:这类节点,zk会自动拼接上一个序号,而且序号是递增的
我们一般创建的都是持久的
create –e /bb xxx
这时候就是短暂的
create /cc yyyy
create –s /cc/c qq
然后他们就会自动的在这些子节点下带上序号
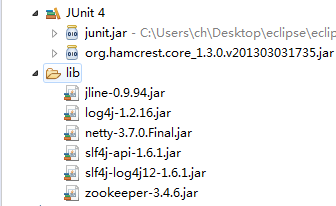
java客户端
需要的jar包
import java.io.UnsupportedEncodingException;
import java.util.List; import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.ZooDefs.Ids;
import org.apache.zookeeper.ZooKeeper;
import org.junit.Before;
import org.junit.Test; public class ZookeeperClientDemo {
ZooKeeper zk = null;
@Before
public void init() throws Exception{
// 构造一个连接zookeeper的客户端对象
zk = new ZooKeeper("hdp-01:2181,hdp-02:2181,hdp-03:2181", 2000, null);
}
//增
@Test
public void testCreate() throws Exception{ // 参数1:要创建的节点路径 参数2:数据 参数3:访问权限 参数4:节点类型
String create = zk.create("/zkTest", "hello zk".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println(create); zk.close(); } //改
@Test
public void testUpdate() throws Exception { // 参数1:节点路径 参数2:数据 参数3:所要修改的版本,-1代表任何版本
zk.setData("/zkTest", "我爱你".getBytes("UTF-8"), -1); zk.close(); } //查
@Test
public void testGet() throws Exception {
// 参数1:节点路径 参数2:是否要监听 参数3:所要获取的数据的版本,null表示最新版本
byte[] data = zk.getData("/zkTest", false, null);
System.out.println(new String(data,"UTF-8")); zk.close();
} //查子节点
@Test
public void testListChildren() throws Exception {
// 参数1:节点路径 参数2:是否要监听
// 注意:返回的结果中只有子节点名字,不带全路径
List<String> children = zk.getChildren("/zkTest", false); for (String child : children) {
System.out.println(child);
} zk.close();
} //删
@Test
public void testRm() throws InterruptedException, KeeperException{ zk.delete("/zkTest", -1); zk.close();
} }
java客户端监听节点是否发生了变化
import java.util.List; import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.EventType;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.ZooKeeper;
import org.junit.Before;
import org.junit.Test; public class ZookeeperWatchDemo { ZooKeeper zk = null; @Before
public void init() throws Exception {
// 构造一个连接zookeeper的客户端对象
zk = new ZooKeeper("hdp-01:2181,hdp-02:2181,hdp-03:2181", 2000, new Watcher() { @Override
public void process(WatchedEvent event) {
//如果在连接,并且为该节点的数据变化了
if (event.getState() == KeeperState.SyncConnected && event.getType() == EventType.NodeDataChanged) {
System.out.println(event.getPath()); // 收到的事件所发生的节点路径
System.out.println(event.getType()); // 收到的事件的类型
System.out.println("数据变化了啊....."); // 收到事件后,我们的处理逻辑 try {
zk.getData("/mygirls", true, null); } catch (KeeperException | InterruptedException e) {
e.printStackTrace();
}
//如果在连接,并且是字节点变化了
}else if(event.getState() == KeeperState.SyncConnected && event.getType() == EventType.NodeChildrenChanged){ System.out.println("子节点变化了......");
} }
});
} @Test
public void testGetWatch() throws Exception {
//此时监听的逻辑就是new ZooKeeper时的watcher,这里也可以自己写一个watcher,
//但如果自己写的话,就会只运行一次了,不能重复监听
byte[] data = zk.getData("/mygirls", true, null); // 监听节点数据变化 List<String> children = zk.getChildren("/mygirls", true); //监听节点的子节点变化事件 System.out.println(new String(data, "UTF-8"));
//这时候启动的监听线程为一个守护线程,当主线程结束后,就会退出,所以这里让主线程睡眠时间,当主线程结束,他也就没了
//这个守护线程使我们在创建的zookeeper的时候就创建的,
Thread.sleep(Long.MAX_VALUE); } }
监听服务器上下线
首先是一个服务器的业务逻辑
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.Date; public class TimeQueryService extends Thread{ int port = 0;
public TimeQueryService(int port){ this.port = port;
}
@Override
public void run() { try {
//javaSocket编程,创建一个指定的端口号接受数据
ServerSocket ss = new ServerSocket(port);
System.out.println("业务线程已绑定端口"+port+"准备接受消费端请求了.....");
while(true){
Socket sc = ss.accept();
InputStream inputStream = sc.getInputStream();
OutputStream outputStream = sc.getOutputStream();
outputStream.write(new Date().toString().getBytes());
} } catch (IOException e) {
e.printStackTrace();
} } }
然后服务器上线时,先向zookeeper注册,等待消费者来访问
package cn.edu360.zk.distributesystem; import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.ZooDefs.Ids;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat; public class TimeQueryServer {
ZooKeeper zk = null; // 构造zk客户端连接
public void connectZK() throws Exception{
zk = new ZooKeeper("hdp-01:2181,hdp-02:2181,hdp-03:2181,hdp-04:2181", 2000, null);
}
// 注册服务器信息
public void registerServerInfo(String hostname,String port) throws Exception{ /**
* 先判断注册节点的父节点是否存在,如果不存在,则创建
*/
Stat stat = zk.exists("/servers", false);
if(stat==null){
zk.create("/servers", null, Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
} // 注册服务器数据到zk的约定注册节点下
String create = zk.create("/servers/server", (hostname+":"+port).getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL); System.out.println(hostname+" 服务器向zk注册信息成功,注册的节点为:" + create); } public static void main(String[] args) throws Exception { TimeQueryServer timeQueryServer = new TimeQueryServer(); // 构造zk客户端连接
timeQueryServer.connectZK(); // 注册服务器信息
timeQueryServer.registerServerInfo(args[0], args[1]); // 启动业务线程开始处理业务
new TimeQueryService(Integer.parseInt(args[1])).start(); } }
然后是消费者端的业务逻辑
先看一下zookeeper有哪些alive的服务器,然后随便挑一台访问
package cn.edu360.zk.distributesystem; import java.io.InputStream;
import java.io.OutputStream;
import java.net.Socket;
import java.util.ArrayList;
import java.util.List;
import java.util.Random; import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.Watcher.Event.EventType;
import org.apache.zookeeper.Watcher.Event.KeeperState; public class Consumer { // 定义一个list用于存放最新的在线服务器列表
private volatile ArrayList<String> onlineServers = new ArrayList<>(); // 构造zk连接对象
ZooKeeper zk = null; // 构造zk客户端连接
public void connectZK() throws Exception { zk = new ZooKeeper("hdp-01:2181,hdp-02:2181,hdp-03:2181,hdp-04:2181", 2000, new Watcher() { @Override
public void process(WatchedEvent event) {
if (event.getState() == KeeperState.SyncConnected && event.getType() == EventType.NodeChildrenChanged) { try {
// 事件回调逻辑中,再次查询zk上的在线服务器节点即可,查询逻辑中又再次注册了子节点变化事件监听
getOnlineServers();
} catch (Exception e) {
e.printStackTrace();
} } }
}); } // 查询在线服务器列表
public void getOnlineServers() throws Exception { List<String> children = zk.getChildren("/servers", true);
ArrayList<String> servers = new ArrayList<>(); for (String child : children) {
byte[] data = zk.getData("/servers/" + child, false, null); String serverInfo = new String(data); servers.add(serverInfo);
} onlineServers = servers;
System.out.println("查询了一次zk,当前在线的服务器有:" + servers); } public void sendRequest() throws Exception {
Random random = new Random();
while (true) {
try {
// 挑选一台当前在线的服务器
int nextInt = random.nextInt(onlineServers.size());
String server = onlineServers.get(nextInt);
String hostname = server.split(":")[0];
int port = Integer.parseInt(server.split(":")[1]); System.out.println("本次请求挑选的服务器为:" + server); Socket socket = new Socket(hostname, port);
OutputStream out = socket.getOutputStream();
InputStream in = socket.getInputStream(); out.write("haha".getBytes());
out.flush(); byte[] buf = new byte[256];
int read = in.read(buf);
System.out.println("服务器响应的时间为:" + new String(buf, 0, read)); out.close();
in.close();
socket.close(); Thread.sleep(2000);
} catch (Exception e) {
e.printStackTrace();
} } } public static void main(String[] args) throws Exception { Consumer consumer = new Consumer();
// 构造zk连接对象
consumer.connectZK(); // 查询在线服务器列表
consumer.getOnlineServers(); // 处理业务(向一台服务器发送时间查询请求)
consumer.sendRequest(); } }
Hadoop学习(5)-zookeeper的安装和命令行,java操作的更多相关文章
- Hadoop学习(6)-HBASE的安装和命令行操作和java操作
使用HABSE之前,要先安装一个zookeeper 我以前写的有https://www.cnblogs.com/wpbing/p/11309761.html 先简单介绍一下HBASE HBASE是一个 ...
- hadoop学习(三)HDFS常用命令以及java操作HDFS
一.HDFS的常用命令 1.查看根目录下的信息:./hadoop dfs -ls 2.查看根目录下的in目录中的内容:./hadoop dfs -ls in或者./hadoop dfs -ls ./i ...
- Hadoop学习(7)-hive的安装和命令行使用和java操作
Hive的用处,就是把hdfs里的文件建立映射转化成数据库的表 但hive里的sql语句都是转化成了mapruduce来对hdfs里的数据进行处理 ,并不是真正的在数据库里进行了操作. 而那些表的定义 ...
- webpack学习(一)安装和命令行、一次js/css的打包体验及不同版本错误
一.前言 找了一个视频教程开始学习webpack,跟着视频学习,在自己的实际操作中发现,出现了很多问题.基本上都是因为版本的原因而导致,自己看的视频是基于webpack 1.x版,而自己现在早已是we ...
- HDFS shell命令行常见操作
hadoop学习及实践笔记—— HDFS shell命令行常见操作 附:HDFS shell guide文档地址 http://hadoop.apache.org/docs/r2.5.2/hadoop ...
- 【分布式】ZooKeeper学习之一:安装及命令行使用
ZooKeeper学习之一:安装及命令行使用 一直都想着好好学一学分布式系统,但是这拖延症晚期也是没得治了,所以干脆强迫自己来写一个系列博客,从zk的安装使用.客户端调用.涉及到的分布式原理.选举过程 ...
- Hadoop学习(9)-spark的安装与简单使用
spark和mapreduce差不多,都是一种计算引擎,spark相对于MapReduce来说,他的区别是,MapReduce会把计算结果放 在磁盘,spark把计算结果既放在磁盘中有放在内存中,ma ...
- mac安装GNU命令行工具
mac安装GNU命令行工具 2.添加的repo tap home/dupes brew install coreutils binutils diffutils ed -- ...
- 【Mac】Mac OS X 安装GNU命令行工具
macos的很多用户都是做it相关的人,类unix系统带来了很多方面,尤其是经常和linux打交道的人. 但是作为经常使用linux 命令行的人发现macos中的命令行工具很多都是bsd工具,跟lin ...
随机推荐
- 【翻译】Keras.NET简介 - 高级神经网络API in C#
Keras.NET是一个高级神经网络API,它使用C#编写,并带有Python绑定,可以在Tensorflow.CNTK或Theano上运行.其关注点是实现快速实验.因为做好研究的关键是:能在尽可能短 ...
- jmeter分析性能报告时的误区
概述 我们用jmeter做性能测试,必然需要学会分析测试报告.但是初学者常常因为对概念的不清晰,最后被测试报告带到沟里去. 常见的误区 分析响应时间全用平均值 响应时间不和吞吐量挂钩 响应时间和吞吐量 ...
- C# 连接数据库等
SqlConnection连接池:可以通过连接字符串配置连接池.对象池技术:HttpApplication :Asp.Net生产者 消费者. 线程.应用程序跟数据连接非常耗时,而且连接使用非常频繁,使 ...
- element-ui中轮播图自适应图片高度
哈哈,久违了各位.我又回来了,最近在做毕设,所以难免会遇到很多问题,需要解决很多问题,在万能的博友帮助下,终于解决了Element-ui中轮播图的图片高度问题,话不多说上代码. 那个axios的使用不 ...
- 微信小程序社区爬取
# CrawlSpider 需要使用:规则提取器 和 解析器 # 1. allow设置规则的方法:要能够限制在目标url上面, 不要跟其他的url产生相同的正则即可 # 2. 什么情况下使用follo ...
- Socket网络编程系列教程序
C语言的用途相当多,可以用在数据结构.数据库.网络.嵌入式等方面,历经40多年不衰,真是厉害!最近一直想从某一应用方面写一个系列教程,好好地把某一方面讲深讲透. 正好博主对网络方面的编 ...
- 学习11:内容# 1.函数名第一类对象及使用 ***** # 2.f格式化 *** # 3.迭代器 **** # 4.递归 ****
目录 1.第一类对象 -- 特殊点 2.f.格式化 Python3.6版本以上才能够使用 3.迭代器 迭代 : 器 : 工具 4.递归 1.第一类对象 -- 特殊点 1.可以当做值被赋值给变量 def ...
- 扫描线——POJ1151
平面上有若干个矩形,求矩形相互覆盖的面积.为方便起见,矩形的边均平行于坐标轴. 我们根据容斥原理,矩形相互覆盖的面积即为所有矩形的面积和减去所有矩形所覆盖的面积即可. 而现在问题是如何求得所有矩形所覆 ...
- Prim算法与Kruskal(没有代码)
两个最小生成树算法, 都有一个共同的思想: 这棵树是一点一点长大的; 并且每次生长, 都是贪心的. 不同之处是: Kruscal算法是以边为中心的, 每次找最小的并且有用的边添加到树上; Prim算法 ...
- [原创]Flask+uwsgi+virtualenv+nginx部署配置
1.创建工程python2.7版本虚目录: #virtualenv -p /usr/bin/python2.7 CDN_resource #cd CDN_resource #source ./bin/ ...