yolo进化史之yolov2
yolov1和当时最好的目标检测系统相比,有很多缺点.比如和Fast R-CNN相比,定位错误更多.和基于区域选择的目标检测方法相比,recall也比较低.yolov2的目标即在保证分类准确度的情况下,尽可能地去提高recall和定位精度.
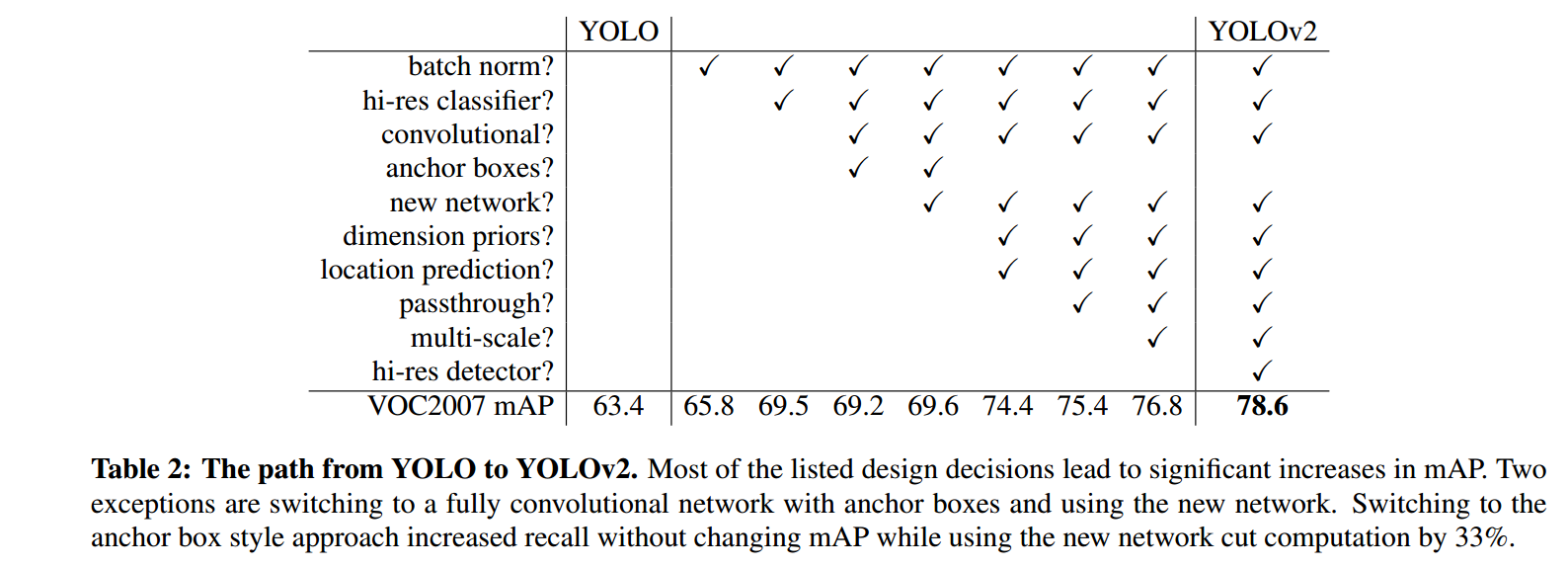
上图是yolo尝试了的方法.
可以看到使得检测精度得到大幅提升的主要就是hi-res classifier和dimension priors && location prediction
Batch Normalization
bn使得mAP提高了2%.并且可以去掉dropout而不带来过拟合.
High Resolution Classifier
yolo可以看成2部分组成,一个是特征提取部分,这部分就是分类网络的全连接层之前的部分. 一个是yolo做预测的部分.
YOLO训练分为两个阶段。首先,我们训练一个像VGG16这样的分类器网络。然后用卷积层替换全连接层,并对其进行端到端的再训练,用于目标检测。yolov1用224 * 224的图片训练分类器,然后用448 * 448的图片做目标检测。 yolov2在用224*224的图片读分类网络做训练以后,再用10个迭代,用448*448的图片去对网络做微调.这样的话,卷积核的参数就可以更好地适应高分辨率的输入,然后用448*448的图片去做检测网络的训练. 此举提高了mAP 4%.
Convolutional With Anchor Boxes
yolov1用全连接层做box的坐标预测. 这个会造成在训练的初始,梯度不够稳定,因为一开始预测的尺寸对某一物体有效,可能对另一物体无效.但是现实世界里,目标的尺寸并不是随机的,所以我们事先聚类好一些anchor box(锚或者叫先验框),依次为基础,去做box坐标预测.
anchor的采用让mAP从69.5掉到了69.2,但是recall从81%上升到了88%.
Using anchor boxes we get a small decrease in accuracy.
YOLO only predicts 98 boxes per image but with anchor
boxes our model predicts more than a thousand. Without
anchor boxes our intermediate model gets 69:5 mAP with a
recall of 81%. With anchor boxes our model gets 69:2 mAP
with a recall of 88%. Even though the mAP decreases, the
increase in recall means that our model has more room to
improve.
论文里,这里让人有点迷惑,其实这里说的anchor box是作者手工选择的box,而不是k-means聚类出来的,采用了k-means聚类的box作为anchor box,把mAP提高了接近5%. 对应于文章开头的图里的dimension priors. 聚类先验框可以参考https://www.cnblogs.com/sdu20112013/p/10937717.html
去除全连接层
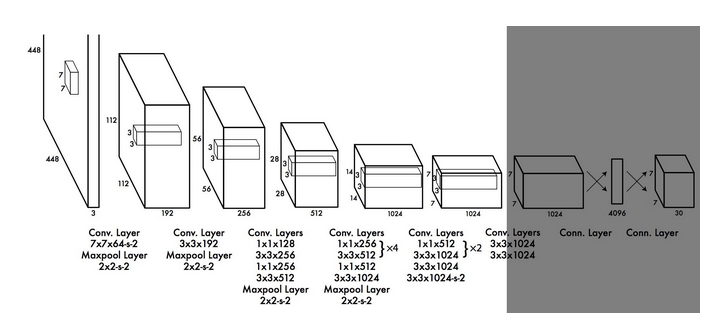
把对class的预测从cell级别调整到针对box.
yolov1每个cell预测出2个box,class个prob. yolov2有5个anchor box.依据每个anchor box预测出(1+4+20)个参数,所以每个cell预测出
5*(1+4+20)=125个参数.
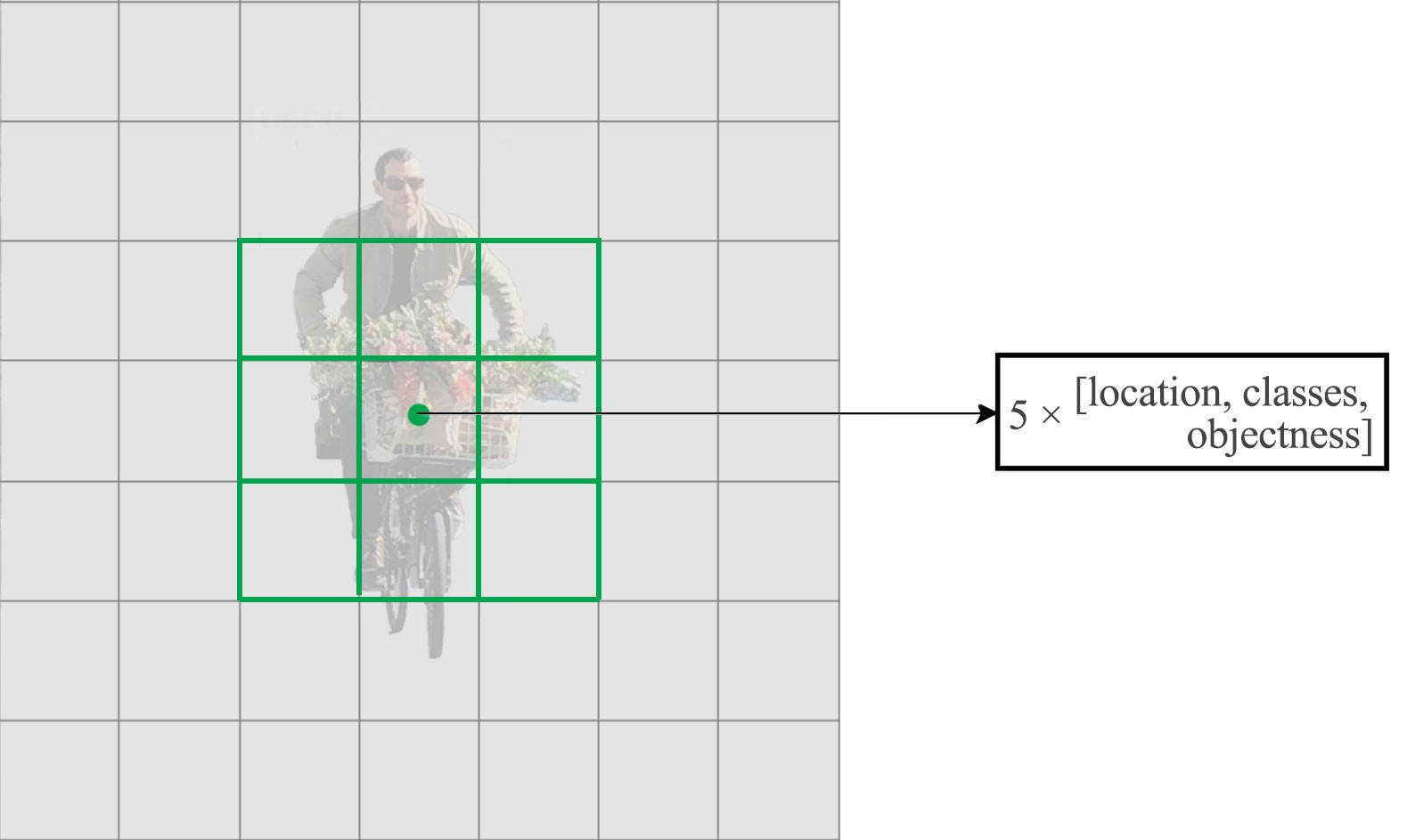
- 图像输入尺寸由448调整到416,同时去掉一个池化层
这样最终得到的feature map的13*13的.

作者认为通常目标位于图片中央,尤其是大目标,所以希望特征图是奇数的,这样就有某一个确定的cell去预测目标而不是用临近的4个cell.
We do this because we want an odd number of
locations in our feature map so there is a single center cell.
Objects, especially large objects, tend to occupy the center
of the image so it’s good to have a single location right at
the center to predict these objects instead of four locations
that are all nearby
- 去掉一个池化层使得最终输出是 13×13 (instead of 7×7).
Direct location prediction
我们怎么计算预测的box坐标值呢?

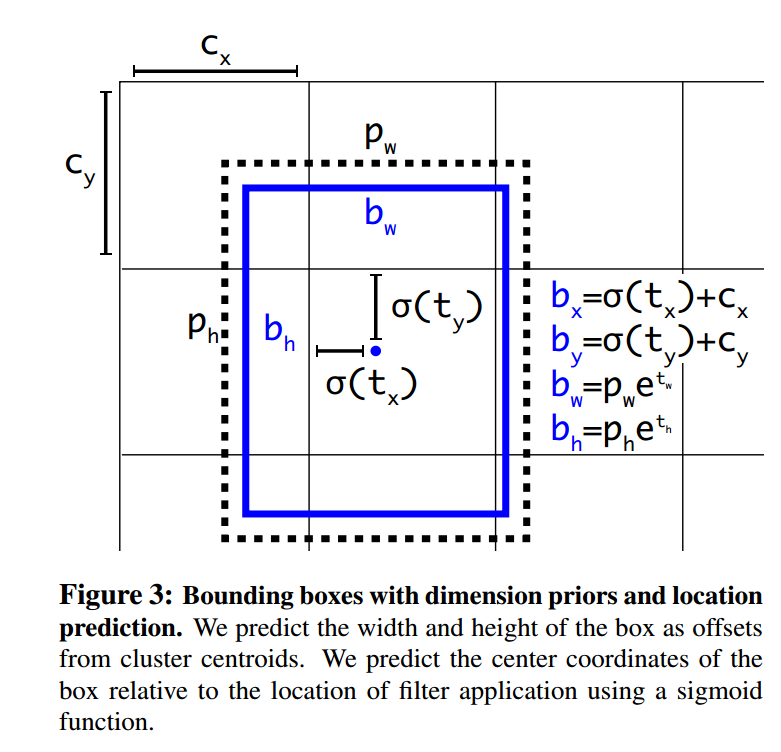
σ(tx)函数将预测值限定到了0-1之间.这样就保证了我们预测出来的box仍然是围绕着当前cell的.这一点也使得网络更稳定.
Since we constrain the location prediction the
parametrization is easier to learn, making the network
more stable. Using dimension clusters along with directly
predicting the bounding box center location improves
YOLO by almost 5% over the version with anchor boxes
Fine-Grained Features
随着卷积不断进行,我们最终得到一个13*13的特征图.对大目标来说,基于这个特征图做预测是ok的,但是对小目标来说就没那么好了.Faster R-CNN或者SSD在不同的layer生成的特征图上去做位置的预测,相当于不同分辨率的特征图负责不同尺寸的目标. yolo采取了一个不同的思路,把两个layer的feature map连成一个.称之为passthrough,在此基础去做预测.如下图:
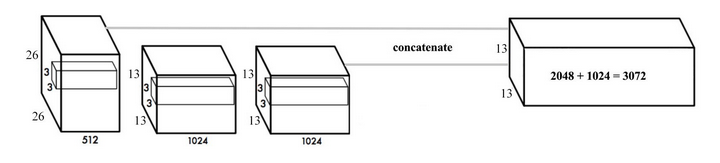
Multi-Scale Training
由于去掉了全连接层,模型的输入可以使任意size.为了让yolov2有更好的鲁棒性,在训练的时候,我们每10个batch就随机改变input的size.由于模型是进行32倍下采样的,所以我们把input size改变成320,352...608这些尺寸.
以上是yolov2提升准确率所做的改造.现在我们来看下为了更快的推理速度,yolov2都做了什么.
Googlenet
大部分检测网络是以VGG-16做为特征提取器的.以一个224*224的图片为例,一次前向传播,VGG-16有30.69 billion次浮点数运算.yolo用了一个基于googlenet的定制化的网络,一次前向传播只有8.52 billion次运算.相应的,代价是准确率的稍微下降.
Darknet-19
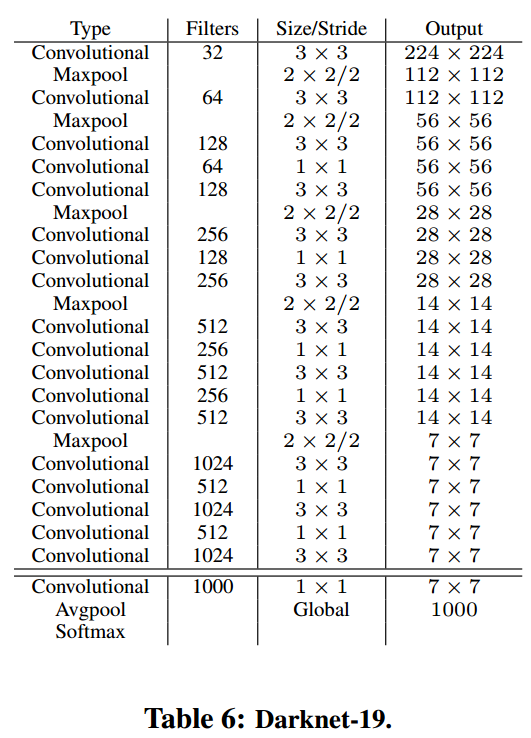
作者继续去简化特征提取层的网络结构.如上图. 注意上图份两部分. 最后三层(conv,avgpool,softmax)是做分类的.前面的n层是做特征提取的.
对这个分类网络,先在ImageNet做分类的训练,把特征提取的网络的参数训练出来,先用224*224的做训练,再用448*448的做微调.之后保持特征提取部分的网络不变,把最后几层替换掉,去做检测网络的训练.如下图

参考:https://arxiv.org/abs/1612.08242
yolo进化史之yolov2的更多相关文章
- yolo进化史之yolov3
yolov3的论文写的比较简略,不看yolov1,yolov2很难直接看懂. 建议先看v1,v2论文. yolov3主要做了几点改进 改进了特征提取部分的网络结构 多尺度预测 分类由softmax改为 ...
- 目标检测YOLO进化史之yolov1
yolov3在目标检测领域可以算得上是state-of-art级别的了,在实时性和准确性上都有很好的保证.yolo也不是一开始就达到了这么好的效果,本身也是经历了不断地演进的. yolov1 测试图片 ...
- AI佳作解读系列(二)——目标检测AI算法集杂谈:R-CNN,faster R-CNN,yolo,SSD,yoloV2,yoloV3
1 引言 深度学习目前已经应用到了各个领域,应用场景大体分为三类:物体识别,目标检测,自然语言处理.本文着重与分析目标检测领域的深度学习方法,对其中的经典模型框架进行深入分析. 目标检测可以理解为是物 ...
- 检测算法简介及其原理——fast R-CNN,faster R-CNN,YOLO,SSD,YOLOv2,YOLOv3
1 引言 深度学习目前已经应用到了各个领域,应用场景大体分为三类:物体识别,目标检测,自然语言处理.本文着重与分析目标检测领域的深度学习方法,对其中的经典模型框架进行深入分析. 目标检测可以理解为是物 ...
- 小白也能弄懂的目标检测之YOLO系列 - 第一期
大家好,上期分享了电脑端几个免费无广告且实用的录屏软件,这期想给大家来讲解YOLO这个算法,从零基础学起,并最终学会YOLOV3的Pytorch实现,并学会自己制作数据集进行模型训练,然后用自己训练好 ...
- YOLO2解读,训练自己的数据及相关转载以供学习
https://pjreddie.com/darknet/yolo/ 具体安装及使用可以参考官方文档https://github.com/pjreddie/darknet https://blog.c ...
- 转载:点云上实时三维目标检测的欧拉区域方案 ----Complex-YOLO
感觉是机器翻译,好多地方不通顺,凑合看看 原文名称:Complex-YOLO: An Euler-Region-Proposal for Real-time 3D Object Detection ...
- You Only Look One-level Feature
你只需要看一个层次的特征 摘要:本文回顾了单阶段检测器的特征金字塔网络(FPN),指出FPN的成功在于其对目标检测优化问题的分治解决,而不是多尺度特征融合.从优化的角度来看,我们引入了一种替代的方法来 ...
- [目标检测]YOLO原理
1 YOLO 创新点: 端到端训练及推断 + 改革区域建议框式目标检测框架 + 实时目标检测 1.1 创新点 (1) 改革了区域建议框式检测框架: RCNN系列均需要生成建议框,在建议框上进行分类与回 ...
随机推荐
- Windows to Linux API 映射
- 有趣的RPC理解
RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议.RPC协议假定某些传输协议的存在,如TCP或UDP,为通 ...
- Kafka集群配置---Windows版
Kafka是一种高吞吐量的分布式发布订阅的消息队列系统,Kafka对消息进行保存时是通过tipic进行分组的.今天我们仅实现Kafka集群的配置.理论的抽空在聊 前言 最近研究kafka,发现网上很多 ...
- JWT+Interceptor实现无状态登录和鉴权
无状态登录原理 先提一下啥是有状态登录 单台tomcat的情况下:编码的流程如下 前端提交表单里用户的输入的账号密码 后台接受,查数据库, 在数据库中找到用户的信息后,把用户的信息存放到session ...
- 算法与数据结构基础 - 分治法(Divide and Conquer)
分治法基础 分治法(Divide and Conquer)顾名思义,思想核心是将问题拆分为子问题,对子问题求解.最终合并结果,分治法用伪代码表示如下: function f(input x size ...
- Vue 路由模块化配置
博客地址:https://ainyi.com/77 企业运营后台页面很多,路由如若不区分模块化配置,所有路由挤在同一个文件将不好维护,所以路由的配置也要模块化 分享两个解决方案 -- Vue 路由配置 ...
- win10文件备份、文件同步方案
用个人版onedrive同步重要数据,数据安全有保障,但免费版只有15G空间,需要合理分配.(201907与别人合租家庭版,空间1T充足) google-drive可以同步指定的文件夹,但空间也只有1 ...
- vim 基础配置
最近在使用 python 搞服务, 简单配置了一个 vim, 配置了自动补全以及背景色 .(ps:搜狗输入法快捷键占用真是太坑爹,改用谷歌输入法,世界安静了) 具体配置如下: 一. 安装插件 1.克隆 ...
- Python 命令行之旅 —— 深入 argparse (一)
作者:HelloGitHub-Prodesire HelloGitHub 的<讲解开源项目>系列,项目地址:https://github.com/HelloGitHub-Team/Arti ...
- 逻辑回归(Logistic Regression)详解,公式推导及代码实现
逻辑回归(Logistic Regression) 什么是逻辑回归: 逻辑回归(Logistic Regression)是一种基于概率的模式识别算法,虽然名字中带"回归",但实际上 ...