scrapy 基础组件专题(二):下载中间件
下载器中间件是介于Scrapy的request/response处理的钩子框架,是用于全局修改Scrapy request和response的一个轻量、底层的系统。
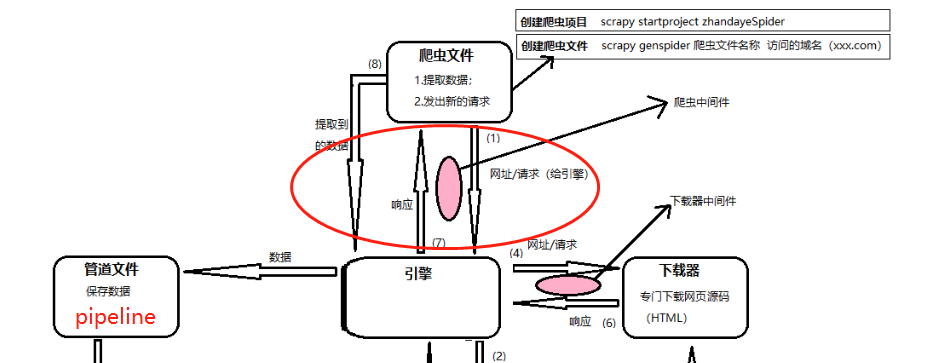
1.激活Downloader Middleware
要激活下载器中间件组件,将其加入到 DOWNLOADER_MIDDLEWARES 设置中。 该设置是一个字典(dict),键为中间件类的路径,值为其中间件的顺序(order)。像下面这样
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.CustomDownloaderMiddleware': 543,
}DOWNLOADER_MIDDLEWARES 设置会与Scrapy定义的 DOWNLOADER_MIDDLEWARES_BASE 设置合并(但不是覆盖), 而后根据顺序(order)进行排序,最后得到启用中间件的有序列表: 第一个中间件是最靠近引擎的,最后一个中间件是最靠近下载器的。
关于如何分配中间件的顺序settings里面的Scrapy默认BASE设置 ,而后根据你想要放置中间件的位置选择一个值。 由于每个中间件执行不同的动作,你的中间件可能会依赖于之前(或者之后)执行的中间件,因此顺序是很重要的。
如果你想禁止内置的(在 DOWNLOADER_MIDDLEWARES_BASE 中设置并默认启用的)中间件, 你必须在项目的 DOWNLOADER_MIDDLEWARES 设置中定义该中间件,并将其值赋为 None 。 例如,如果您想要关闭user-agent中间件:
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.CustomDownloaderMiddleware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
}2.自定义Downloader Middleware
如果你想自定义一个属于你的下载器中间件,只需要编写一个下载器中间件类,继承自scrapy.downloadermiddlewares.DownloaderMiddleware,而后在里面重写以下的几个方法。
process_request(request, spider)
当每个request通过下载中间件时,该方法被调用。
process_request() 必须返回其中之一: 返回 None 、返回一个 Response 对象、返回一个 Request 对象或raise IgnoreRequest 。
如果其返回 None ,Scrapy将继续处理该request,执行其他的中间件的相应方法,直到合适的下载器处理函数(download handler)被调用, 该request被执行(其response被下载)。
如果其返回 Response 对象,Scrapy将不会调用 任何 其他的 process_request() 或 process_exception() 方法,或相应地下载函数; 其将返回该response。 已安装的中间件的 process_response() 方法则会在每个response返回时被调用。
如果其返回 Request 对象,Scrapy则停止调用 process_request方法并重新调度返回的request。当新返回的request被执行后, 相应地中间件链将会根据下载的response被调用。
如果其raise一个 IgnoreRequest 异常,则安装的下载中间件的 process_exception() 方法会被调用。如果没有任何一个方法处理该异常, 则request的errback(Request.errback)方法会被调用。如果没有代码处理抛出的异常, 则该异常被忽略且不记录(不同于其他异常那样)。
参数:
request(Request 对象)–处理的request
spider(Spider 对象)–该request对应的spiderprocess_response(request, response, spider)
process_request() 必须返回以下之一: 返回一个 Response 对象、 返回一个 Request 对象或raise一个 IgnoreRequest 异常。
- 如果其返回一个 Response (可以与传入的response相同,也可以是全新的对象), 该response会被在链中的其他中间件的 process_response() 方法处理。
- 如果其返回一个 Request 对象,则中间件链停止, 返回的request会被重新调度下载。处理类似于 process_request() 返回request所做的那样。
- 如果其抛出一个 IgnoreRequest 异常,则调用request的errback(Request.errback)。 如果没有代码处理抛出的异常,则该异常被忽略且不记录(不同于其他异常那样)。
参数:
request (Request 对象) – response所对应的request
response (Response 对象) – 被处理的response
spider (Spider 对象) – response所对应的spiderprocess_exception(request, exception, spider)
当下载处理器(download handler)或 process_request() (下载中间件)抛出异常(包括IgnoreRequest异常)时,Scrapy调用 process_exception() 。
process_exception() 应该返回以下之一: 返回 None 、 一个 Response 对象、或者一个 Request 对象。
- 如果其返回 None ,Scrapy将会继续处理该异常,接着调用已安装的其他中间件的 process_exception() 方法,直到所有中间件都被调用完毕,则调用默认的异常处理。
- 如果其返回一个 Response 对象,则已安装的中间件链的 process_response() 方法被调用。Scrapy将不会调用任何其他中间件的 process_exception() 方法。
- 如果其返回一个 Request 对象, 则返回的request将会被重新调用下载。这将停止中间件的 process_exception() 方法执行,就如返回一个response的那样。
参数:
request (是 Request 对象) – 产生异常的request
exception (Exception 对象) – 抛出的异常
spider (Spider 对象) – request对应的spider- 自定义实例
import random
import base64
import six
def to_bytes(text, encoding=None, errors='strict'):
"""Return the binary representation of `text`. If `text`
is already a bytes object, return it as-is."""
if isinstance(text, bytes):
return text
if not isinstance(text, six.string_types):
raise TypeError('to_bytes must receive a unicode, str or bytes '
'object, got %s' % type(text).__name__)
if encoding is None:
encoding = 'utf-8'
return text.encode(encoding, errors) class MyProxyDownloaderMiddleware(object):
def process_request(self, request, spider):
proxy_list = [
{'ip_port': '111.11.228.75:80', 'user_pass': 'xxx:123'},
{'ip_port': '120.198.243.22:80', 'user_pass': ''},
{'ip_port': '111.8.60.9:8123', 'user_pass': ''},
{'ip_port': '101.71.27.120:80', 'user_pass': ''},
{'ip_port': '122.96.59.104:80', 'user_pass': ''},
{'ip_port': '122.224.249.122:8088', 'user_pass': ''},
]
proxy = random.choice(proxy_list)
if proxy['user_pass'] is not None:
request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port'])
encoded_user_pass = base64.encodestring(to_bytes(proxy['user_pass']))
request.headers['Proxy-Authorization'] = to_bytes('Basic ' + encoded_user_pass)
else:
request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port']) 配置:
DOWNLOADER_MIDDLEWARES = {
# 'xiaohan.middlewares.MyProxyDownloaderMiddleware': 543,
}
3.内置Downloader Middleware介绍
CookiesMiddleware
该中间件使得爬取需要cookie(例如使用session)的网站成为了可能。 其追踪了web server发送的cookie,并在之后的request中发送回去, 就如浏览器所做的那样。
以下设置可以用来配置cookie中间件:
COOKIES_ENABLED默认为True
COOKIES_DEBUG默认为FalseScrapy通过使用 cookiejar Request meta key来支持单spider追踪多cookie session。 默认情况下其使用一个cookie jar(session),不过我们可以传递一个标示符来使用多个。
比如:for i, url in enumerate(urls):
yield scrapy.Request("http://www.example.com", meta={'cookiejar': i},
callback=self.parse_page)需要注意的是 cookiejar meta key不是”黏性的(sticky)”。 我们需要在之后的request请求中接着传递。
比如:def parse_page(self, response):
# do some processing
return scrapy.Request("http://www.example.com/otherpage",
meta={'cookiejar': response.meta['cookiejar']},
callback=self.parse_other_page)DefaultHeadersMiddleware
该中间件设置 DEFAULT_REQUEST_HEADERS 指定的默认request header。
DownloadTimeoutMiddleware
该中间件设置 DOWNLOAD_TIMEOUT 指定的request下载超时时间.
HttpAuthMiddleware
该中间件完成某些使用 Basic access authentication (或者叫HTTP认证)的spider生成的请求的认证过程。
HttpCacheMiddleware
该中间件为所有HTTP request及response提供了底层(low-level)缓存支持。 其由cache存储后端及cache策略组成。
HttpCompressionMiddleware
该中间件提供了对压缩(gzip, deflate)数据的支持
ChunkedTransferMiddleware
该中间件添加了对 chunked transfer encoding 的支持。
HttpProxyMiddleware
该中间件提供了对request设置HTTP代理的支持。您可以通过在 Request 对象中设置 proxy 元数据来开启代理。
RedirectMiddleware
该中间件根据response的状态处理重定向的request。通过该中间件的(被重定向的)request的url可以通过 Request.meta 的 redirect_urls 键找到。
MetaRefreshMiddleware
该中间件根据meta-refresh html标签处理request重定向。
RetryMiddleware
该中间件将重试可能由于临时的问题,例如连接超时或者HTTP 500错误导致失败的页面。
爬取进程会收集失败的页面并在最后,spider爬取完所有正常(不失败)的页面后重新调度。 一旦没有更多需要重试的失败页面,该中间件将会发送一个信号(retry_complete), 其他插件可以监听该信号。RobotsTxtMiddleware
该中间件过滤所有robots.txt eclusion standard中禁止的request。
确认该中间件及 ROBOTSTXT_OBEY 设置被启用以确保Scrapy尊重robots.txt。UserAgentMiddleware
用于覆盖spider的默认user agent的中间件。
要使得spider能覆盖默认的user agent,其 user_agent 属性必须被设置。AjaxCrawlMiddleware
根据meta-fragment html标签查找 ‘AJAX可爬取’ 页面的中间件。
scrapy 基础组件专题(二):下载中间件的更多相关文章
- scrapy 基础组件专题(一):scrapy框架中各组件的工作流程
Scrapy 使用了 Twisted 异步非阻塞网络库来处理网络通讯,整体架构大致如下(绿线是数据流向): Scrapy主要包括了以下组件: 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事 ...
- scrapy 基础组件专题(八):scrapy-redis 框架分析
scrapy-redis简介 scrapy-redis是scrapy框架基于redis数据库的组件,用于scrapy项目的分布式开发和部署. 有如下特征: 分布式爬取 您可以启动多个spider工 ...
- scrapy 基础组件专题(七):scrapy 调度器、调度器中间件、自定义调度器
一.调度器 配置 SCHEDULER = 'scrapy.core.scheduler.Scheduler' #表示scrapy包下core文件夹scheduler文件Scheduler类# 可以通过 ...
- scrapy 基础组件专题(三):爬虫中间件
一.爬虫中间件简介 图 1-1 图 1-2 开始这一张之前需要先梳理一下这张图, 需要明白下载器中间件和爬虫中间件所在的位置 下载器中间件是在引擎(ENGINE)将请求推送给下载器(DOWNLOADE ...
- scrapy 基础组件专题(十二):scrapy 模拟登录
1. scrapy有三种方法模拟登陆 1.1直接携带cookies 1.2找url地址,发送post请求存储cookie 1.3找到对应的form表单,自动解析input标签,自动解析post请求的u ...
- scrapy 基础组件专题(十四):scrapy CookiesMiddleware源码
一 Scrapy框架--cookie的获取/传递/本地保存 1. 完成模拟登陆2. 登陆成功后提取出cookie,然后保存到本地cookie.txt文件中3. 再次使用时从本地的cookie.txt中 ...
- scrapy 基础组件专题(五):自定义扩展
通过scrapy提供的扩展功能, 我们可以编写一些自定义的功能, 插入到scrapy的机制中 一.编写一个简单的扩展 我们现在编写一个扩展, 统计一共获取到的item的条数我们可以新建一个extens ...
- scrapy 基础组件专题(四):信号运用
一.scrapy信号使用的简单实例 import scrapy from scrapy import signals from ccidcom.items import CcidcomItem cla ...
- scrapy 基础组件专题(六):自定义命令
写好自己的爬虫项目之后,可以自己定制爬虫运行的命令. 一.单爬虫 在项目的根目录下新建一个py文件,如命名为start.py,写入如下代码: from scrapy.cmdline import ex ...
随机推荐
- 数据库连接池 Druid和C3p0
datasource.properties数据源 #数据源 datasource.peoperties jdbc.driver=com.mysql.jdbc.Driver jdbc.url=jdbc: ...
- 别再写一摞if-else了!再写开除!两种设计模式带你消灭它!
代码洁癖狂们!看到一个类中有几十个if-else是不是很抓狂? 设计模式学了用不上吗?面试的时候问你,你只能回答最简单的单例模式,问你有没有用过反射之类的高级特性,回答也是否吗? 这次就让设计模式(模 ...
- Shell语法规范
ver:1.0 博客:https://www.cnblogs.com/Rohn 本文介绍了Shell编程的一些语法规范,主要参考依据为谷歌的Shell语法风格. 目录 背景 使用哪一种Shell 什么 ...
- yaml读取封装
#!/usr/bin/env python # -*- coding: utf-8 -*- """ 对yaml格式的配置文件的操作 """ ...
- cb03a_c++_数据结构_顺序容器_STL_stack
/*cb03a_c++_数据结构_顺序容器_STL_stack堆栈:LIFO--Last In First Out后进先出,用于系统程序设计自适应容器(容器适配器),不是独立的容器,是一个适配器栈适配 ...
- QT creator视频教程分享
Qt Creator快速入门(第3版) [霍亚飞著] 完整pdf扫描版[92MB] 附随书源码,资源收集于网络,供参考 https://pan.baidu.com/s/1pLQdIUR kjaf ht ...
- python 获取两位的月份(09)和天数(09)
- Azure Monitor(一)Application Insights
一,引言 Azure Monitor 是 Azure 中的一项完整堆栈监视服务,是一种收集和分析遥测数据的服务.它提供了一组完整的功能来监视 Azure 资源以及其他云中和本地的资源.Azure Mo ...
- Vuex怎么用(1)
1. vuex是什么 github站点: https://github.com/vuejs/vuex在线文档: https://vuex.vuejs.org/zh-cn/简单来说: 对应用中组件的状态 ...
- Spring学习笔记下载
动力节点的spring视频教程相当的经典:下载地址 https://pan.baidu.com/s/1eTSOaae