通过JS逆向ProtoBuf 反反爬思路分享
前言
本文意在记录,在爬虫过程中,我首次遇到Protobuf时的一系列问题和解决问题的思路。
文章编写遵循当时工作的思路,优点:非常详细,缺点:文字冗长,描述不准确
protobuf用在前后端传输,在一定程度节约了带宽,也为爬虫工程师增加了工作量。
遇见Protobuf
一拿到网站,F12查看是否有相关数据的请求接口
ok! 接口找到了,看下请求参数吧!

emmm~~ 为啥请求参数是乱码?

平时见着的都是这个样子滴?可以直接看到参数!
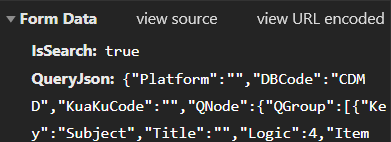
哎,咱们这初出茅庐的菜鸟,乖乖搜搜,看看有没有前辈们写过相关的文章
搜索了 接口请求参数乱码 、爬虫请求参数乱码 等关键词,没有相关的答案(后面了解后,才知道这种关键词匹配不到Protobuf很正常)
好吧,没有现成的答案,于是乖乖的分析请求头
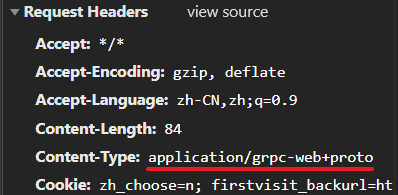
咦~ 这个类型重来没见过啊!老实说我只见过以下几种:
- application/json: JSON数据格式
- application/octet-stream : 二进制流数据
- application/x-www-form-urlencoded : 中默认的encType,form表单数据被编码为key/value格式发送到服务器(表单默认的提交数据的格式)
- multipart/form-data : 需要在表单中进行文件上传时,就需要使用该格式
复制它,搜一搜!嘿,找到了一篇文章,哈哈哈,有救了有救了(心中狂喜)

原文链接:https://zhuanlan.zhihu.com/p/146083543?utm_source=wechat_session
看了文章之后,还是很懵逼,图片超级模糊看不清,不过该作者提供了思路与概念
什么是gRPC? 什么是protobuf(Protocol Buffers)?
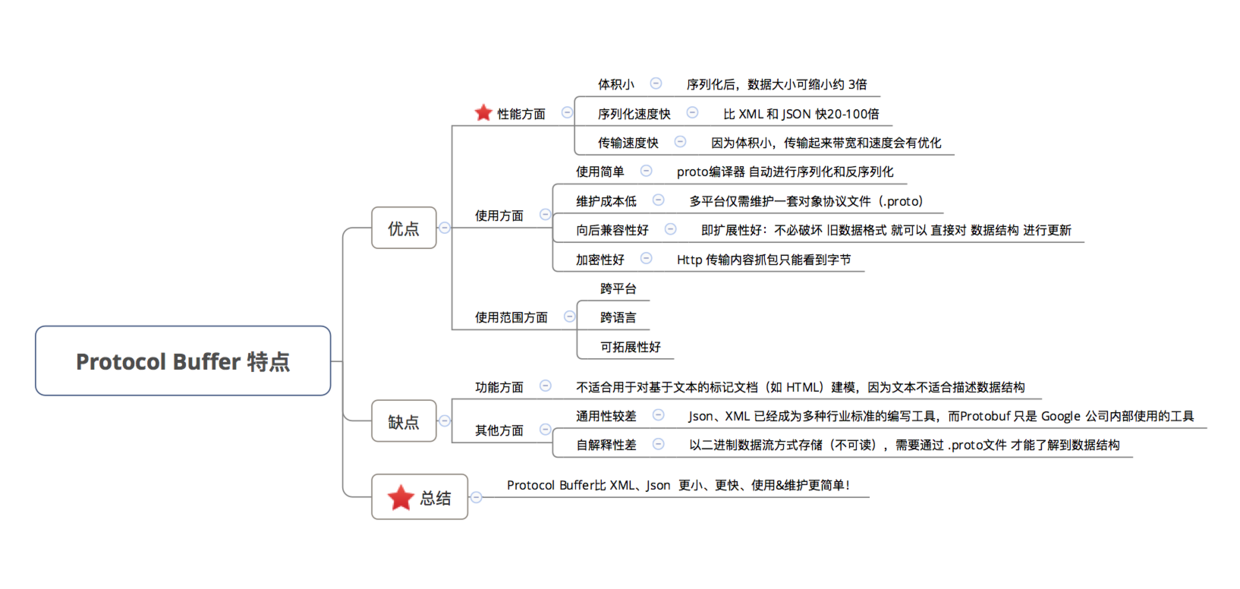
Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或 RPC 数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。
一张图草草过掉。。。
如何使用protocol buffers?
我已经大概了解了这个 protobuf,那么正常的应该如何去使用呢?
于是乎,又搜索 python protobuf使用教程,好家伙,绝大部分文章使用教程都是抄谷歌官网的文档,用例都不带改变一下的。
不过也不是没有收获,搜索过程中,更加具体的了解了protobuf及使用流程,大致如下:
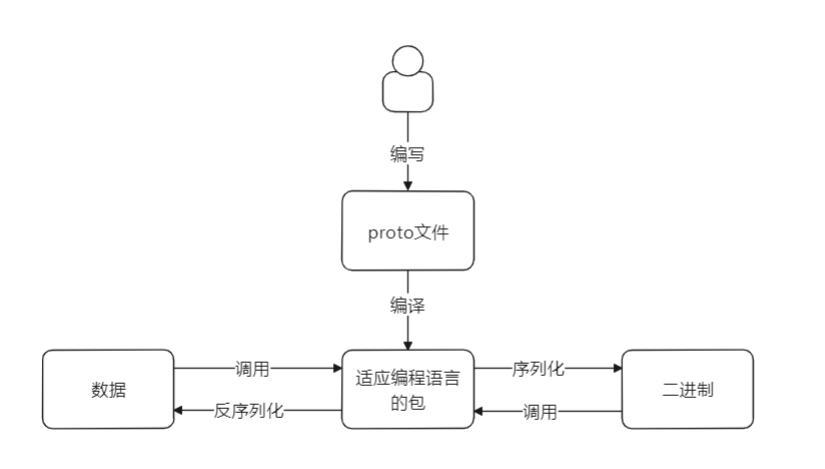
开发者需要先编写proto文件,在proto文件中编写预期的数据类型、数据字段、默认值等
然后,通过编译器生成,编程语言对应的开发包!开发时调开发包中的对应方法进行序列化和反序列化。
思路,有了

那么,我要请求这个接口,参数必须得是序列化的字节序列
而要实现序列化,就必须要有开发包,可是开发包是js的
而开发包也是编译而来的,于是只要“拿”到proto文件就可以编译任意编程语言的开发包了!
好吧,思路有了,通过js反编译出proto文件,再编译为python包即可!

好家伙,就这样对待萌新嘛,有点害怕啊!
反编译在路上
使用protobuf
这里写文章,我就把这一步放前面来,我实际是先调试JS(盲目调),根本不知道找什么,费事又费力!
现在,个人推荐的步骤是写一个简单的proto文件,编译成JS包,瞧瞧里面的代码是什么样子的,心里好一个底!
首先我们需要下载用于编译的编译器
https://github.com/protocolbuffers/protobuf/releases/
下载后放在磁盘某个地方,复制路径,设置环境变量,方便随时编译
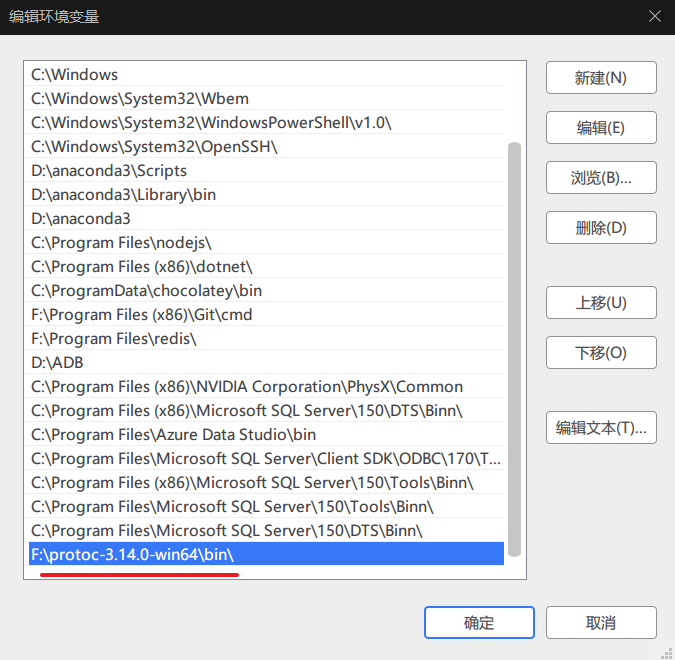
现在写一个简单的proto文件
test.proto
syntax = "proto3"; // 定义proto的版本
message School {
string name = 1; // 学校名
int32 years = 2; // 学校年龄
message Community {
string name = 1; // 社团名称
enum Grade {
DEFAULT = 0;
THREEGRADE = 3; // 三个年级
SIXGRADE = 6; // 六个年级
}
repeated Community community = 3;
Grade grade = 4;
}
编译为JS包
❯ protoc --js_out=. .\test.proto
主要还是得自己动手,编译后,细心观察,这里截取一段比较重要的代码
/**
* Serializes the given message to binary data (in protobuf wire
* format), writing to the given BinaryWriter.
* @param {!proto.School} message
* @param {!jspb.BinaryWriter} writer
* @suppress {unusedLocalVariables} f is only used for nested messages
*/
proto.School.serializeBinaryToWriter = function(message, writer) {
var f = undefined;
f = message.getName();
if (f.length > 0) {
writer.writeString(
1,
f
);
}
f = message.getYears();
if (f !== 0) {
writer.writeInt32(
2,
f
);
}
f = message.getCommunityList();
if (f.length > 0) {
writer.writeRepeatedMessage(
3,
f,
proto.School.Community.serializeBinaryToWriter
);
}
f = message.getGrade();
if (f !== 0.0) {
writer.writeEnum(
4,
f
);
}
};
这一段序列化的代码中出现了如下的方法名:
getName, writeString
getYears, writeInt32
getCommunityList, writeRepeatedMessage
getGrade, writeEnum
然后这一整个判断,这意味 School中定义了四个数据变量, 序号为1, 2,3,4,而数据类型和变量名可以根据其调用的方法推出:
序号为1的数据类型为String,变量名为name
序号为2的数据类型为Int32,变量名为years
序号为3的数据类型为Message,变量名为community,Repeated下面讲
序号为4的数据类型为Enum, 变量名为grade
字符串和整数型一看就明了,不做过多解释,下面了解Message和Enum
Message是什么数据类型?
简单的理解,可以把message看作是一个类,在其中定义的变量就是类属性
在序号为3的判断中有这样一行代码
proto.School.Community.serializeBinaryToWriter
再来看看School的
proto.School.serializeBinaryToWriter
到这里可知,Community定义在School里面且类型是Message
在定义序号为3的数据时,数据类型就是Community,并且是可重复的!
所以才会出现这样一个方法writeRepeatedMessage,并且严格来说,序号为3的数据是自定义的Message数据类型,且是可重复的
什么是可重复?
用name和commmunity对比一下,学校名只能有一个吧(别名除外),所以当name设置了值之后,再进行设置值就会覆盖原来的值!
而Message类型的community被repeated修饰,即community是一个包含多个Commounity实例的数组
没明白什么意思?没关系,用Python代码来解释一下,就会秒懂!
class Community():
name = ""
class School():
# community_list = [Community(), Community(), Community(), ...]
community = [Community(), Community(), Community(), ...] # 可重复
Enum是什么数据类型?
枚举类型,
例如,有的学校是初高中一起的,就是6个年级,而有些只有高中或初中就是3个年级。在这两种限定情况下,只可能出现3或者6,这样就可以设置枚举类型,要么3要么6,自己选一个!
这就好比前端中的单选框,必须且只能选择一个
注意:枚举类型。必须要有为0的默认选项
总而言之呢,看见writeEnum就知道这个数据为Enum类型
repeated也可以修饰Enum,其对应的JS写操作的方法为writePackedEnum
被repeated修饰的enum类型,则好似前端中的多选框,至少选择一个,可选择多个
小结一下:
被repeated修饰的message类型的数据,看作是一个包含任意个某message类型数据的数组
被repeated修饰的enum类型的数据,看作是一个包含任意个整数类型数据的整型数组
调试JS反写proto
知道了proto文件编译后js序列化的核心代码之后,那么接下来断点调试,就不至于无头苍蝇乱撞!
将接口的请求地址复制,粘贴至审查工具 -> Sources -> XHR/fetch Breakpoints
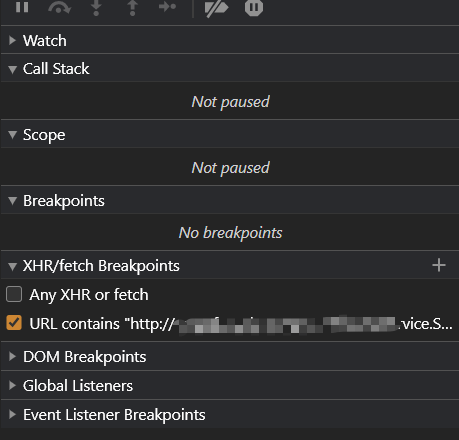
这个有啥用?当调试工具,检查到有这个链接的请求即将被发送时,会自动进入断点调试状态。
接着,请求一下接口!
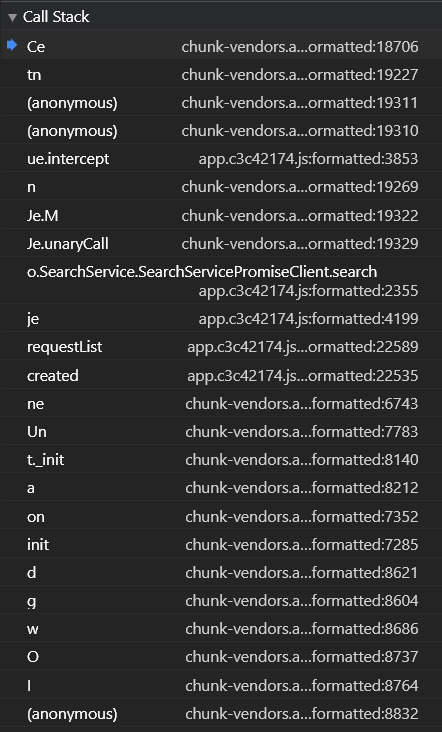
Call Stack就是调用栈,这里就看到了 SearchService字样的方法,点进去瞧瞧看!
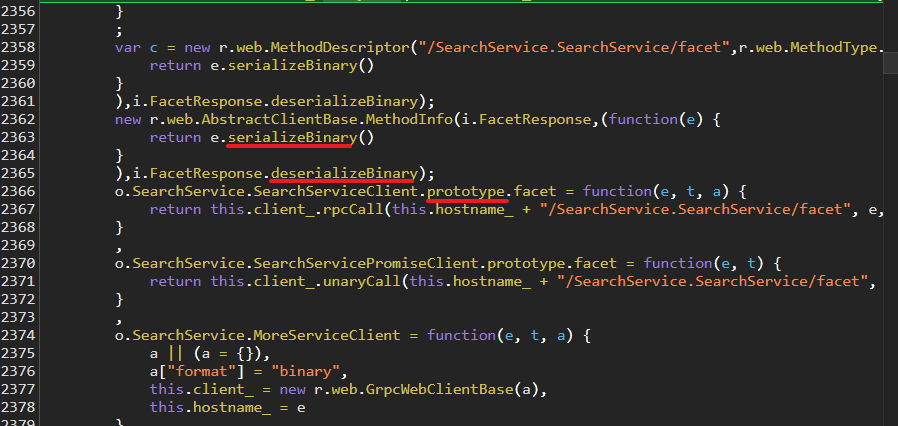
看下这些方法的命名,序列化(serialize)、反序列化(deserialize),基本断定就在这个js文件里,但是这个js有几万行代码,不可能仔细去看也没必要。
在这里手动打个断点,然后重新请求一次

然后,耐心的慢慢的调试下去,看,这个方法名,这种命名方式,眼熟不?

在这里,直接就可以看出其基本结构
message SearchService {
message SearchRequest {
}
}
然后,我们继续调试。

这里可以看出SearchRequest定义了两个变量,分别是序号为1的message类型的CommonRequest和序号为2的enum类型的InterfaceType。
根据SearchService.CommonRequest可知,CommonRequest定义在SearchService中
所以,proto文件现在是这样的:
message SearchService {
message CommonRequest {
}
enum InterfaceType {
// 定义了什么不知道,但是enum必须有一个值就是0
DEFAUTL = 0;
}
message SearchRequest {
CommonRequest commonrequest = 1; // 任意变量名
InterfaceType interfaceType = 2; // 任意变量名
}
}
关于变量名是什么,这个其实不重要,后面会讲到
继续往下调试,进入到了CommonRequest
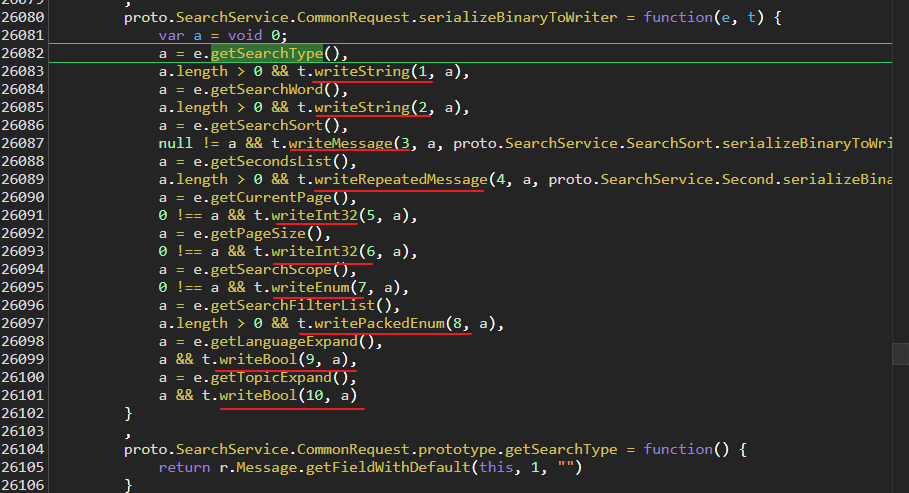
这if判断,这方法名,熟悉嘛?
根据方法名,直接就可以反写出CommonRequest
message SearchSort {
}
message Second {
}
enum SearchScope {
A = 0;
}
enum SearchFilter {
B = 0;
}
message CommonRequest {
string searchType = 1;
string searchWord = 2;
SearchSort searchSort = 3;
repeated Second seconds = 4;
int32 currentPage = 5;
int32 pageSize = 6;
SearchScope searchScope = 7
repeated SearchFilter searchFilter = 8;
bool languageExpand = 9;
bool topicExpand = 10;
}
SearchSort和Second都是在SearchService定义的,Ctrl + F搜索
SearchService.SearchSort.serializeBinaryToWriter
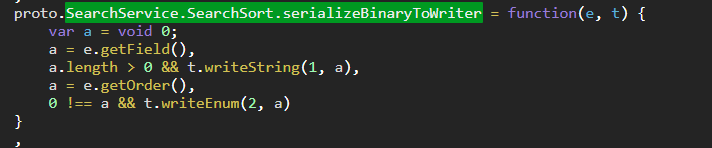
SearchService.Second.serializeBinaryToWriter

显而易见,这两个message如下:
enum Order {
C = 0;
}
message SearchSort {
string field = 1;
Order order = 2;
}
message Second {
string field = 1;
string value = 2;
}
对于所有的enum枚举类,至少填充一个默认值0,且变量名唯一
有的情况,枚举类含有哪些字段,可以在代码中直接看到,就照抄写进去。
看不到的,给个唯一变量名,默认值为0即可
好了,对于这一个请求接口的proto文件就算反写完成了!
syntax = "proto3";
message SearchService {
enum Order {
C = 0;
}
enum SearchScope {
A = 0;
}
enum SearchFilter {
B = 0;
}
message SearchSort {
string field = 1;
Order order = 2;
}
message Second {
string field = 1;
string value = 2;
}
message CommonRequest {
string searchType = 1;
string searchWord = 2;
SearchSort searchSort = 3;
repeated Second seconds = 4;
int32 currentPage = 5;
int32 pageSize = 6;
SearchScope searchScope = 7;
repeated SearchFilter searchFilter = 8;
bool languageExpand = 9;
bool topicExpand = 10;
}
enum InterfaceType {
// 定义了什么不知道,但是enum必须有一个值就是0
DEFAUTL = 0;
}
message SearchRequest {
CommonRequest commonrequest = 1; // 任意变量名
InterfaceType interfaceType = 2; // 任意变量名
}
}
现在还差一个源数据,即我们需要知道待编译的源数据是什么样子的?
抓包!
确定请求参数
抓包工具:fiddler4
之前审查工具抓包已经看到了,请求参数是乱码,还抓包?
这次抓包会使用到fiddler默认的hexview插件,虽然现在是乱码,不过还是有办法的!
这些黑色样式的十六进制编码就是需要的数据!
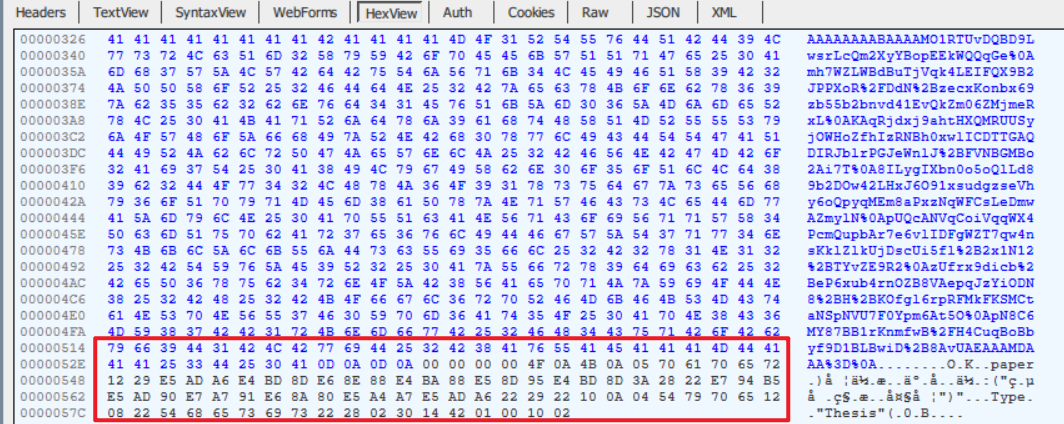
选中,右键保存为字节文件
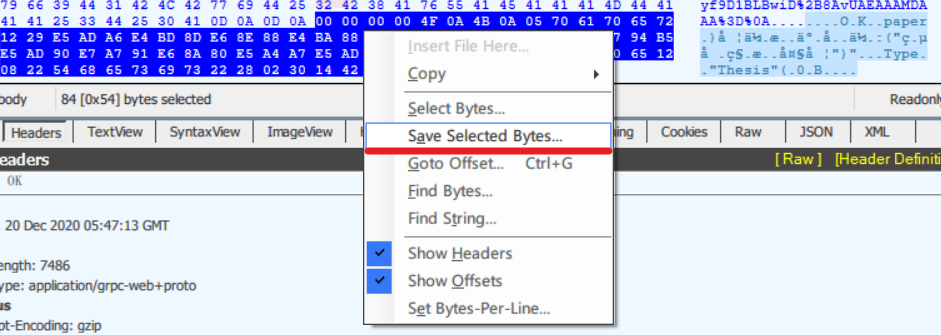
这个字节数据是可以通过protoc编译器解码出来的哦!
来,试试看!
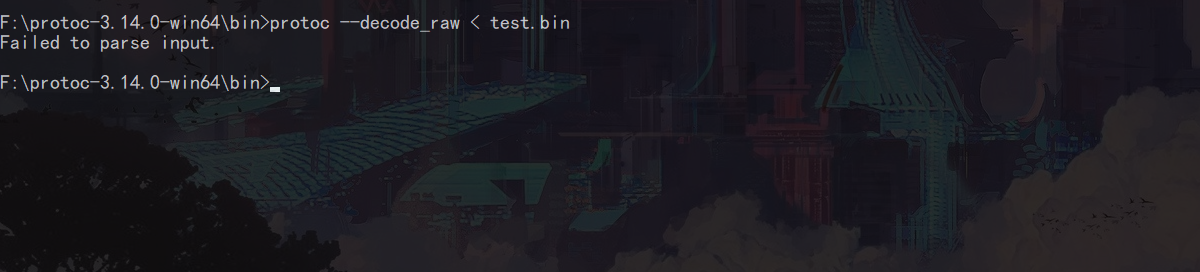
解码失败了,在本例中,这里传输的数据不仅仅只有请求参数,他的头部还有一段校验和
就如下图中的 00 00 00 00 4F,这段校验和是不属于数据序列化后的字节,是后来加上去的!
这种情况,依然是可以通过js调试分析得出结论!

那么去掉校验和的字节序列就是编码后的数据,而解码之后源数据就是这个样子的!
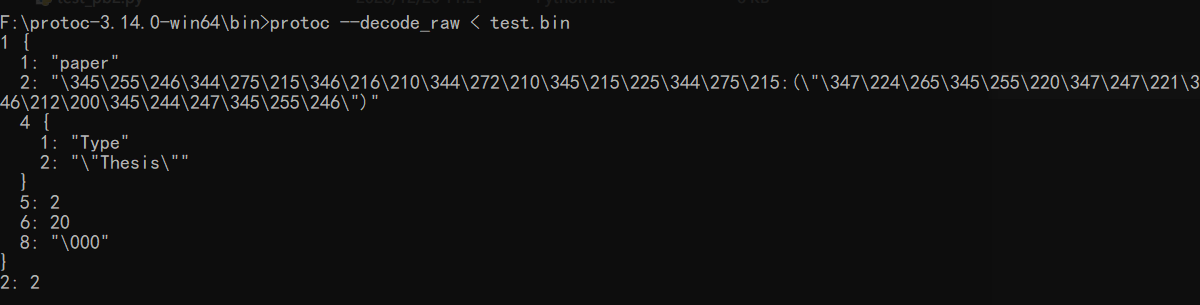
与之前编写的proto文件,对比看看
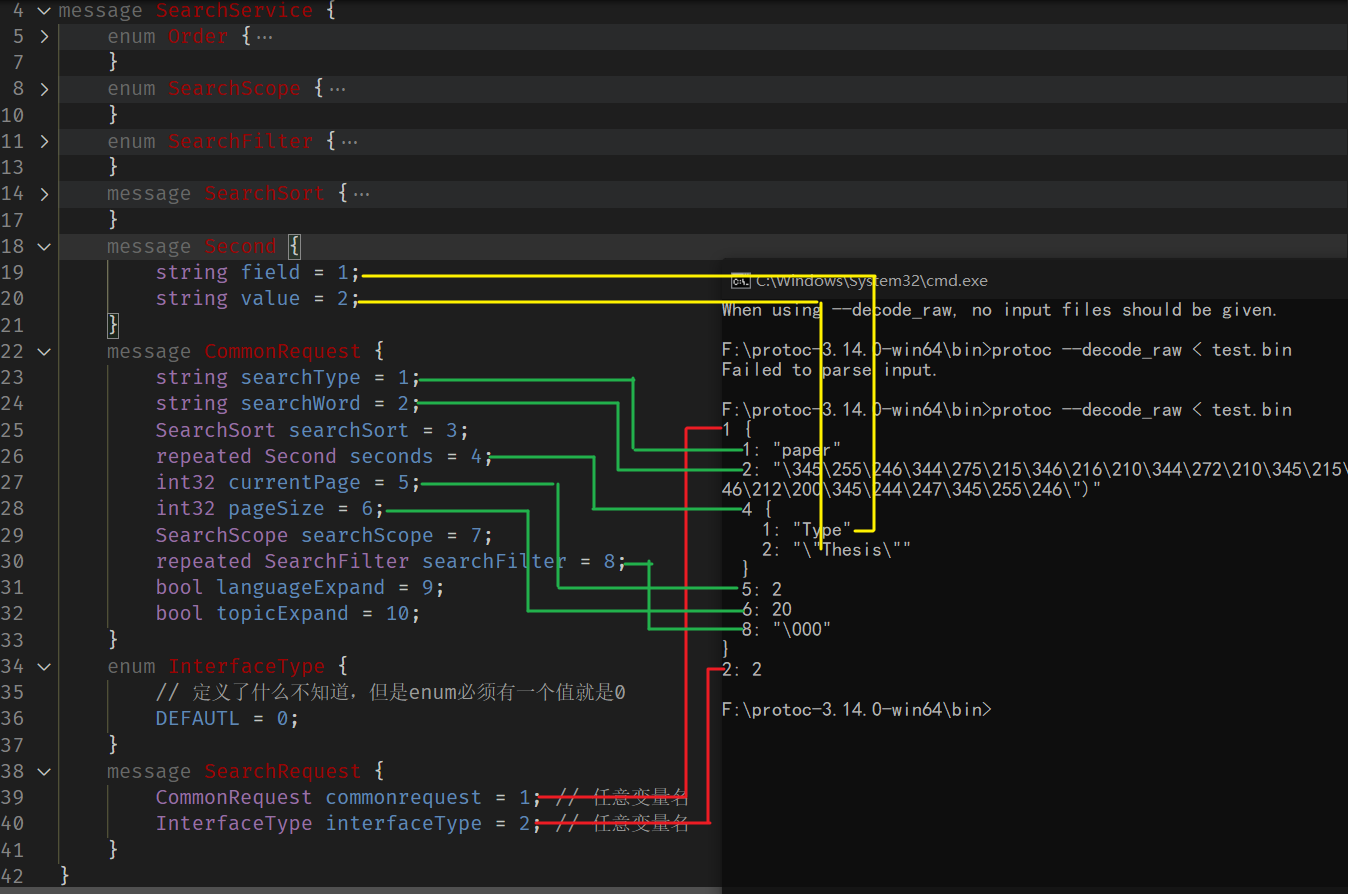
实际传输时,简单的看,键就是proto中定义的序号,这就是之前提到的 变量名是什么根本不重要,变量名只是方便开发者开发时便于理解与调用。(传输一个数字远比传输一个字符串更有效率)
而对于,我们爬虫开发者而言,构造出这个请求参数,获取这个接口的响应内容是最终目标!
完全还原proto文件是不需要的!
实现请求
最后还有几步
编译proto为python包,构建参数,序列化参数,发送请求
Python使用编译包
在网上搜了搜,好像都没有写具体怎么使用这个编译包,基本类型使用简单,对于repeated修饰的message和enum类型,则在下文说明具体该调用什么方法,该怎么赋值!
protoc --python_out=. ./test.proto
目录下生成了test_pb2.py 拖入项目中,需要使用时就调用即可
那么,在Python中,具体如何使用编译好的包呢?
import test_pb2 as pb # 导包
请求参数序列化的是SearchRequest,所以可以理解为先实例化一个SearchRequest
search_request = pb.SearchService.SearchRequest()
search_request需要设置两个值,一个是commonrequest和interfaceType
commonrequest是CommonRequest类型,它有好几个字段,例如可以这样写:
search_request.commonrequest.searchType = "paper"
search_request.commonrequest.searchWord = '学位授予单位:("电子科技大学")'
search_request.commonrequest.currentPage = 2
search_request.commonrequest.pageSize = 20
这些是字符串,数字型的都是直接赋值的,很好理解!
而对于,repeated修饰的messsage类型和enum类型,则需要稍微多几个步骤
例如:
# 可重复message类型
# 可重复message类型,需要调用一个add方法,然后将对应字段赋值
seconds = search_request.commonrequest.Second.add()
seconds.field = "Type"
seconds.value = '"Thesis"'
# 可重复enum枚举类型
search_request.commonrequest.searchFilter.append(0)
这里可以看作是一个动态长度的整型数组,append将新值追加至末尾
参数序列化的完整代码
import message_pb2 as pb
search_request = pb.SearchService.SearchRequest()
search_request.commonrequest.searchType = "paper"
search_request.commonrequest.searchWord = '学位授予单位:("电子科技大学")'
seconds = search_request.commonrequest.seconds.add()
seconds.field = "Type"
seconds.value = '"Thesis"'
search_request.commonrequest.currentPage = 1
search_request.commonrequest.pageSize = 20
search_request.commonrequest.searchFilter.append(0)
search_request.interfaceType = 2
with open('me.bin', mode="wb") as f:
f.write(search_request.SerializeToString())
print(search_request.SerializeToString().decode())
至此,请求参数的序列化已经是完成了!
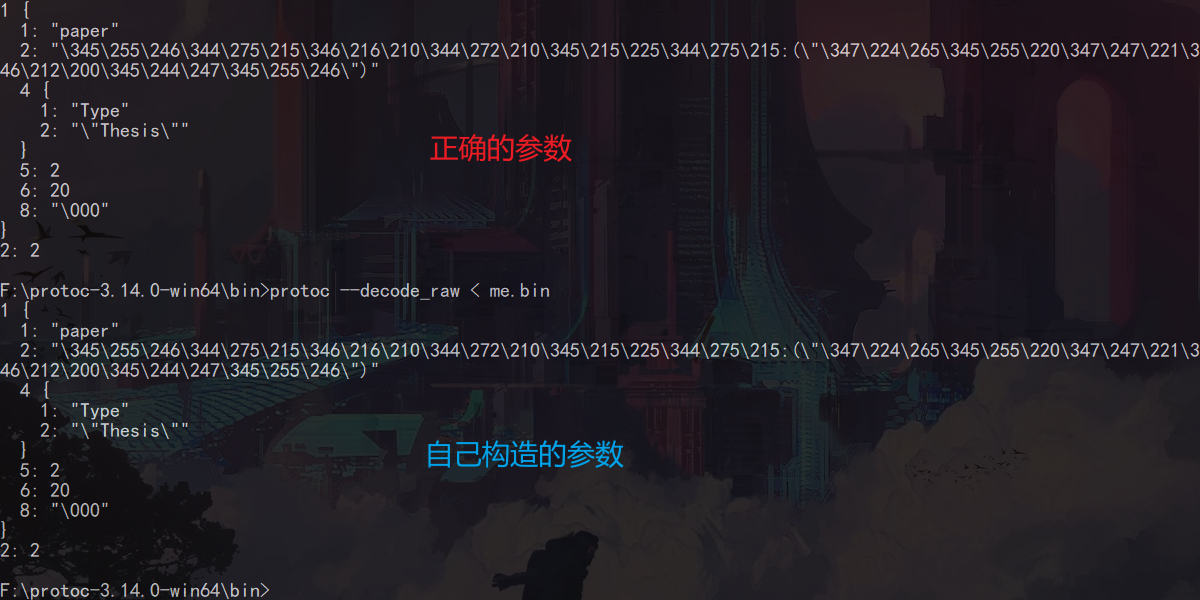
请求接口
这里只需注意一点就是请求头里的内容编码 'Content-Type': 'application/grpc-web+proto'
代码
headers = {
'Referer': 'xxxx',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'Content-Type': 'application/grpc-web+proto',
}
bytes_body = search_request.SerializeToString()
# 构造字节序列的头部
bytes_head = bytes([0, 0, 0, 0, len(bytes_body)])
resp = requests.post(url="xxxx",
data=bytes_head+bytes_body,
headers=headers)
print(resp.content)
在本例中,请求的字节序列有个包含校验码的头部,所以在请求前需要加上去。
各个网站或APP都不相同,具体情况具体分析!
成功拿到数据,这里因为编码的原因依然是乱码,所以这里就得反序列化!

解码响应数据
基本思路是一致的:逆向JS -> 编写proto文件 -> 编译为Python包 -> 调用包实现反序列化数据
原本我想,搞定了请求,响应岂不是一样的!
然后果然吃瘪了!

问题:
- 找不到接收响应的代码片段
- 在JS编译包内分析的数据结构不完整
听我娓娓道来
我在请求发送之后,一直单步调试,耗费了很长时间,就是找不到响应的内容
当我看到getResponseMessage()方法时,我觉得我看到了希望,然后调试进入
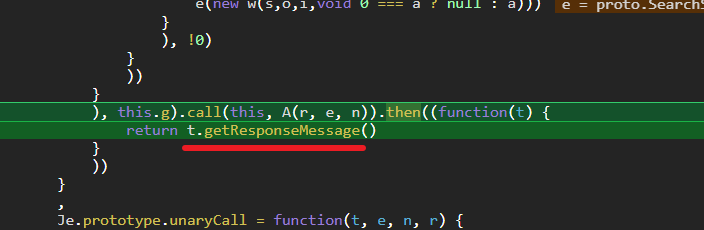
在调用栈内看到了熟悉的字眼 SearchService
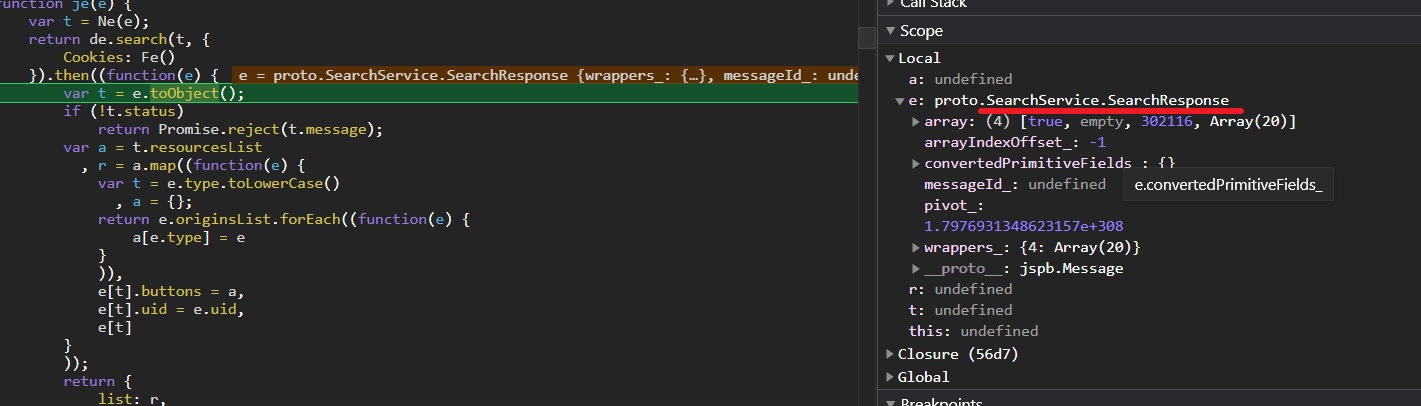
SearchService内包含SearchResponse,然后一路调试下去(和之前的步骤一样),逆向出响应的proto文件!
按正常的流程,就是用编译包反序列化数据即可,但是这里又遇到了问题!
分析hexview
使用之前的操作:通过查看hexview,选取数据段部分,用proto编译工具反解码
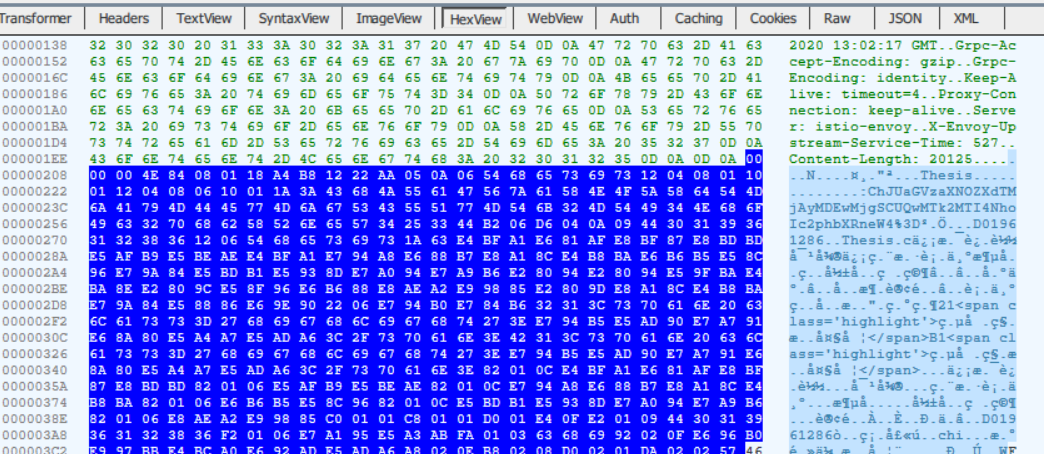
我猜测和之前请求时的操作一样,前5位是记录数据段长度的字节序列头,所以我就认为从第6位开始到最后的这一部分就是数据段,也就是我们需要解码的部分!
但是,当我把这部分保存为二进制文件,用proto编译工具反解码时,一直提示解析失败!
这个就让我很怀疑是不是猜测错了,然后我又想如果又字节序列头,那会不会又字节序列尾呢?
接着,我查看了响应头信息,总长度为 20125
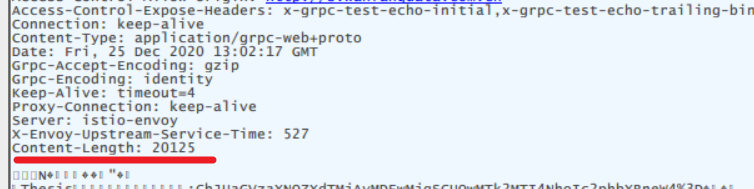
又接着将前5位十六进制转为十进制,得到数据段长度为 20100
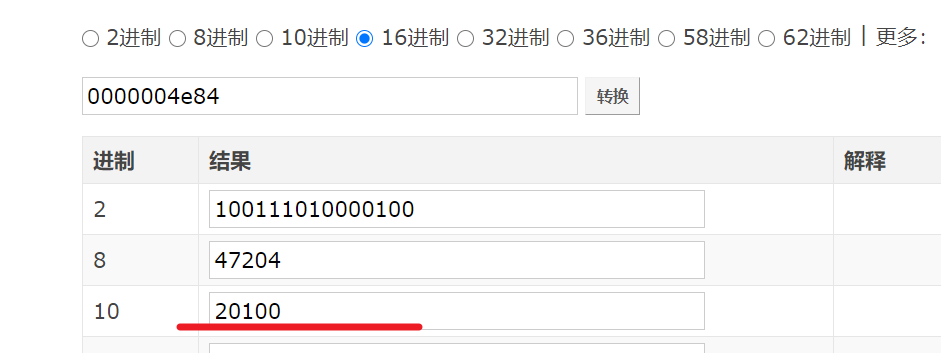
20125 - 20100 = 25
去掉头部的5位,那么也就是说尾部是20位,至此经过我的”掐头去尾“,就这样得到了数据段!
数据对照
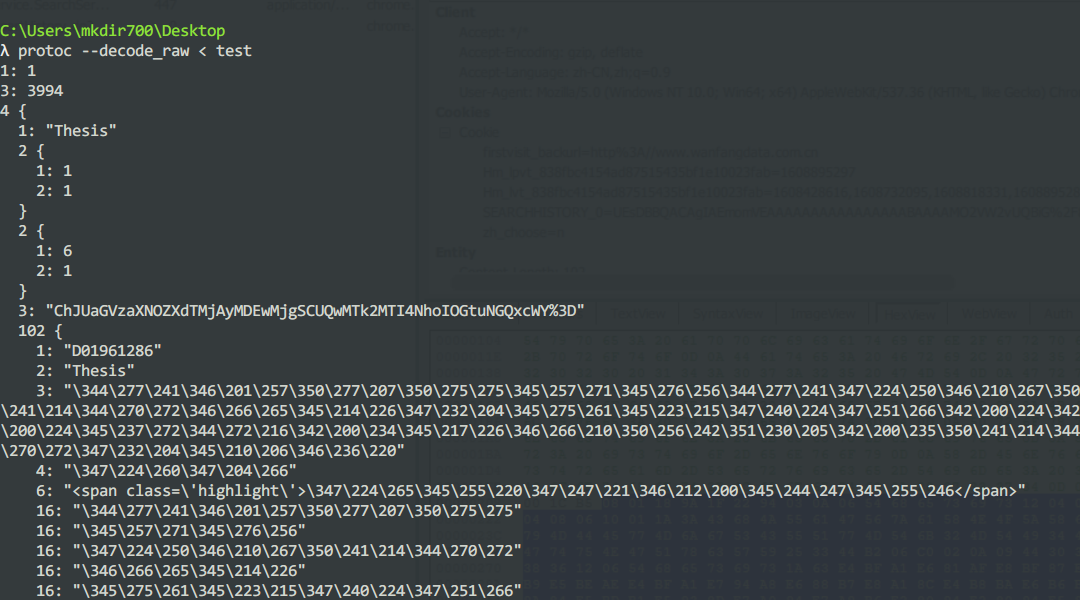
现在就是按解析出来的数据序号对应的数据类型与我编写的proto文件进行一一对照,看下数据类型是否符合。
然后,我遇到了两个问题:
1、同一数据字段,数据类型不一致

上图红框圈出来的部分,正常的话应该序号为8的字段是一个message类型
在这个消息类型内部呢,包含一个可重复(repeated)的字符串类型(string)的字段
然而,中间居然在字符串之间插了一个message?
因为才接触grpc,我还以为这样是允许存在的,毕竟编译器正确解析出来。搜了一圈,也没找到同一字段允许多种数据类型
我根据这个字段对应的 0x726f6a61,在hexview中查找
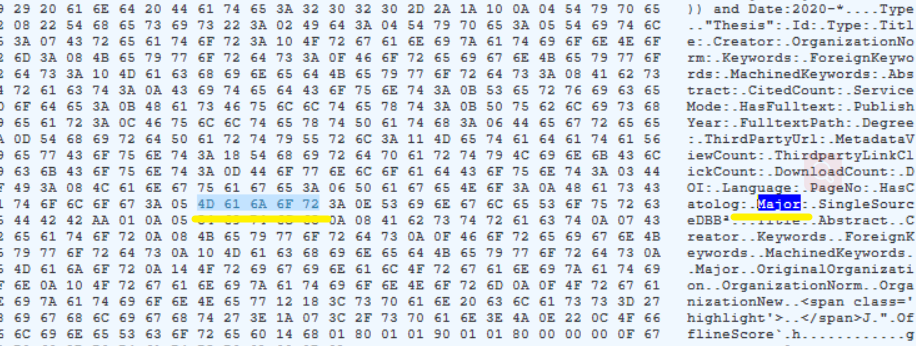
很明显,这应该是一个单词,而编译器解析时出错了!
2、proto文件编写得不完整
我逆向出了SearchService.SearchResponse,响应回来时反序列化为一个长度为4的数组,其中第2位没有值。
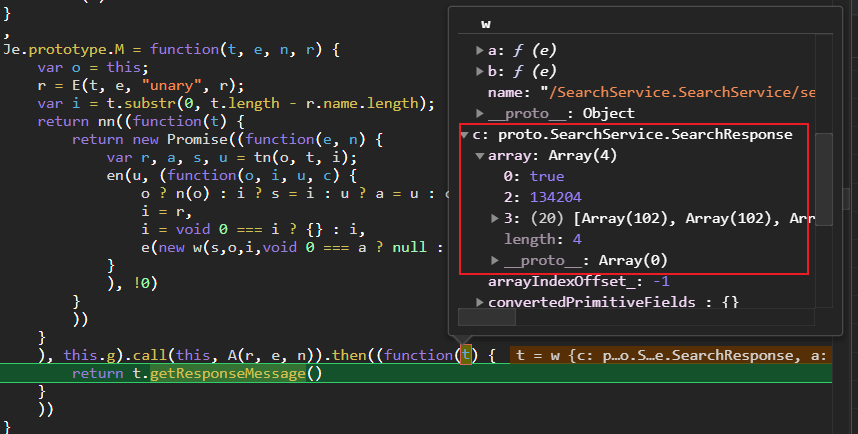
与解码出来的数据序号是一致的。
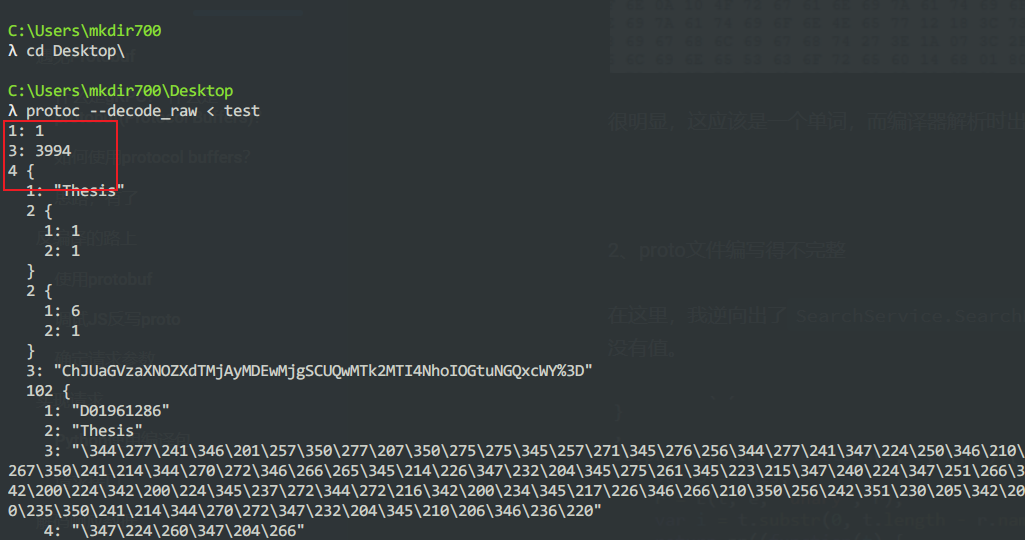
然而现在的问题是,多一个序号为1002的数据字段
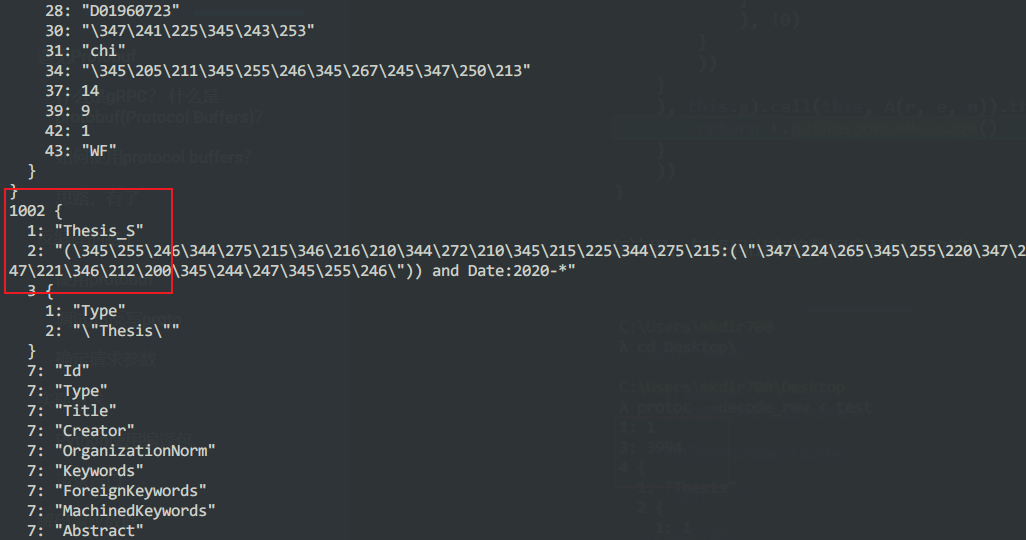
响应传回的数据结构就是这样的:
1:
3:
4:
1002:
而我自己构造的proto文件中的数据结构则是这样的:
1:
2: // 根据实际需求,可省略不写
3:
4:
也就是说,没有序号为1002的这个数据字段!
我在这里调试了很久,就是没有找到 字节流转成JS数组的方法!
然后,只能根据编译工具解码的1002序号的数据样式,继续反写proto文件。
虽然不知道字段名,但是不影响,在上面也了解过,其核心是知道数据类型是什么即可!
编译工具解码后的逆向规则小结
数字,根据情况而定,一般是int32
" " 字符串类型
{ } message类型
出现多个重复序号,此字段可重复,即被repeated修饰
总结
- 了解了grpc,protocol buffers这种从未接触过的传输方式
- 对浏览器的审查工具的使用也更加熟练了
- 掌握了一点JS逆向的思路
参考文章
https://www.yuanrenxue.com/app-crawl/parse-protobuf.html
https://zhuanlan.zhihu.com/p/146083543?utm_source=wechat_session
通过JS逆向ProtoBuf 反反爬思路分享的更多相关文章
- 我去!爬虫遇到JS逆向AES加密反爬,哭了
今天准备爬取网页时,遇到『JS逆向AES加密』反爬.比如这样的: 在发送请求获取数据时,需要用到参数params和encSecKey,但是这两个参数经过JS逆向AES加密而来. 既然遇到了这个情况,那 ...
- Python反爬:利用js逆向和woff文件爬取猫眼电影评分信息
首先:看看运行结果效果如何! 1. 实现思路 小编基本实现思路如下: 利用js逆向模拟请求得到电影评分的页面(就是猫眼电影的评分信息并不是我们上述看到的那个页面上,应该它的实现是在一个页面上插入另外一 ...
- 网络爬虫之记一次js逆向解密经历
1 引言 数月前写过某网站(请原谅我的掩耳盗铃)的爬虫,这两天需要重新采集一次,用的是scrapy-redis框架,本以为二次爬取可以轻松完成的,可没想到爬虫启动没几秒,出现了大堆的重试提示,心里顿时 ...
- python爬虫之JS逆向
Python爬虫之JS逆向案例 由于在爬取数据时,遇到请求头限制属性为动态生成,现将解决方式整理如下: JS逆向有两种思路: 一种是整理出js文件在Python中直接使用execjs调用js文件(可见 ...
- 爬虫05 /js加密/js逆向、常用抓包工具、移动端数据爬取
爬虫05 /js加密/js逆向.常用抓包工具.移动端数据爬取 目录 爬虫05 /js加密/js逆向.常用抓包工具.移动端数据爬取 1. js加密.js逆向:案例1 2. js加密.js逆向:案例2 3 ...
- Android应用反破解的思路
一个Android应用要被破解,要经历:反编译->分析代码->重新编译打包的过程,反破解的思路也是从在这三个步骤上做文章: 1, 寻找反编译工具的缺陷,通过阅读其源码或者对其进行压力测试找 ...
- selenium + chrome 被检测,反反爬小记
selenium + chrome 很多难以采集的网站都使用selenium爬取,但是后来发现selenium有特征值,会被检测出来,今天来小结一下反反爬方案 测试网站 全绿好像代表没被检测出 中间人 ...
- python做反被爬保护的方法
python做反被爬保护的方法 网络爬虫,是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成.但是当网络爬虫被滥用后,互联网上就出现太多同质的东西,原创得不到保护.于是,很 ...
- 22.2.14session和反反爬处理
22.2.14 session和反反爬处理 1.session: requests库包含session,都是用来对一个url发送请求,区别在于session是一连串的请求,在session请求过程中c ...
随机推荐
- selenium.common.exceptions.WebDriverException: Message: 'chromedriver'解决
相信很多第一次学习selenium的同学们也对这个异常不陌生了,但具体该如何解决这个bug呢? 主要的原因还是因为selenium模拟的客户端对浏览器的操作,但相应浏览器的驱动版本不匹配导致的. 为了 ...
- MySQL锁(一)全局锁:如何做全库的逻辑备份?
数据库锁设计的初衷是处理并发问题,这也是数据库与文件系统的最大区别. 根据加锁的范围,MySQL里大致可以分为三种锁:全局锁.表锁和行锁.接下来我们会分三讲来介绍这三种锁,今天要讲的是全局锁. 全局锁 ...
- Python分析世界幸福指数
前言 民意测验机构盖洛普从2012年起,每年都会在联合国计划下发布<世界幸福指数报告>,报告会综合两年内150多个国家的国民对其所处社会.城市和自然环境等因素进行评价后,再根据他们所感知的 ...
- vue第二单元(webpack的配置-学习webpack的常用配置)
第二单元(webpack的配置-学习webpack的常用配置) #课程目标 掌握webpack的常用配置 掌握如何根据实际的需求修改webpack的对应配置 了解webpack-dev-server的 ...
- 留心一下VS的这个调试代码的bug
最近和同事在Debug代码时,遇到一个诡异的问题,开始以为是代码问题,分析了之后发现是VS(v16.8.3)的bug,特此分享一下,如果大家近期遇到类似的问题,不要茫然. 这个bug重现的方式是,在d ...
- SSH,公钥,私钥的理解
参考大佬的文章:https://blog.csdn.net/li528405176/article/details/82810342 https://www.cnblogs.com/Bravew ...
- yum提示错误: error: rpmdb: BDB0113 Thread/process 9866/140290246137664 failed:
错误如下: 解决办法:重新构建rpm数据库
- 服务器安装ESXI6.7
1 从官网下载ESXI镜像文件到本地 https://my.vmware.com/web/vmware/details?downloadGroup=ESXI670&productId=7 ...
- .net网站快速停机设置app_offline
在根目录防止一个app_offline.htm文件即可,文件内容自己设置,空白也是可以的,这样的话网站即可实现快速停机,方便维护和升级 有问题可以联系我,我的邮箱是:yxxrui@163.com,我的 ...
- Apache Cassandra——可扩展微服务应用程序的持久数据存储
通过使用微服务,团队可以更快地响应变化,而无需改动整个应用程序.利用微服务,开发团队可以构建出具有鲁棒性和可扩展性的系统,从而适应当今应用程序的需求. 然而,使用微服务也带来了一系列挑战.在本文中 ...