Xray批量化自动扫描
关于Xray高级版破解:
不过好像新版本的Xray修复了破解的BUG,亲测Xray1.3.3高级版仍然可以破解
因为Xray没有批量化的选项,在网上查了一下,fofa2Xray是封装好了的EXE文件,其他的好像需要配置代理之类的,反正挺麻烦,我只是想从txt里面按行读取URL进行扫描,所以昨晚上花半个小时自己写了一个小脚本实现Xray自动化批量扫描。
首先是一个大LOGO
def logo():
logo='''
_ __ _ __ _ __
| '_ \| '_ \| '_ \
| |_) | |_) | |_) |
| .__/| .__/| .__/
| | | | | |
|_| |_| |_|
__ __
\ \ / /
\ V / _ __ __ _ _ _
/ \| '__/ _` | | | |
/ /^\ \ | | (_| | |_| |
\/ \/_| \__,_|\__, |
__/ |
|___/
v1.0
author:springbird
'''
return logo
将Xray高级版破解之后路径配置在环境变量里,这样我们这个代码就不需要固定位置放置
核心是
def xrayScan(targeturl,outputfilename="test"):
scanCommand="xray.exe webscan --basic-crawler {} --html-output {}.html".format(targeturl,outputfilename)
print(scanCommand)
os.system(scanCommand)
return
os.system执行命令进行扫描,这样就实现了单个URL的脚本扫描,接着是读取TXT实现批量
def pppGet():
f = open("target.txt")
lines = f.readlines()
pattern = re.compile(r'^http://')
for line in lines:
try:
if not pattern.match(line.strip()):
targeturl="http://"+line.strip()
else:
targeturl=line.strip()
print(targeturl.strip())
outputfilename=hashlib.md5(targeturl.encode("utf-8"))
xrayScan(targeturl.strip(), outputfilename.hexdigest())
# print(type(line))
except Exception as e:
print(e)
pass
f.close()
print("Xray Scan End~")
return
这里的代码就是从文件里面读取URL,依次放在Xray里面进行扫描,放置待扫描URL的txt的名字为target.txt
最终完整代码为:
import os
import hashlib
import re
def logo():
logo='''
_ __ _ __ _ __
| '_ \| '_ \| '_ \
| |_) | |_) | |_) |
| .__/| .__/| .__/
| | | | | |
|_| |_| |_|
__ __
\ \ / /
\ V / _ __ __ _ _ _
/ \| '__/ _` | | | |
/ /^\ \ | | (_| | |_| |
\/ \/_| \__,_|\__, |
__/ |
|___/
v1.0
author:springbird
'''
return logo
def xrayScan(targeturl,outputfilename="test"):
scanCommand="xray.exe webscan --basic-crawler {} --html-output {}.html".format(targeturl,outputfilename)
print(scanCommand)
os.system(scanCommand)
return
# def test():
# pattern = re.compile(r'^http://')
# m = pattern.match('http://www.baidu.com')
# n = pattern.match('hta')
# print(m)
# print(n)
# return
def pppGet():
f = open("target.txt")
lines = f.readlines()
pattern = re.compile(r'^http://')
for line in lines:
try:
if not pattern.match(line.strip()):
targeturl="http://"+line.strip()
else:
targeturl=line.strip()
print(targeturl.strip())
outputfilename=hashlib.md5(targeturl.encode("utf-8"))
xrayScan(targeturl.strip(), outputfilename.hexdigest())
# print(type(line))
except Exception as e:
print(e)
pass
f.close()
print("Xray Scan End~")
return
def main():
print(logo())
pppGet()
return
if __name__ == '__main__':
main()
运行截图为:
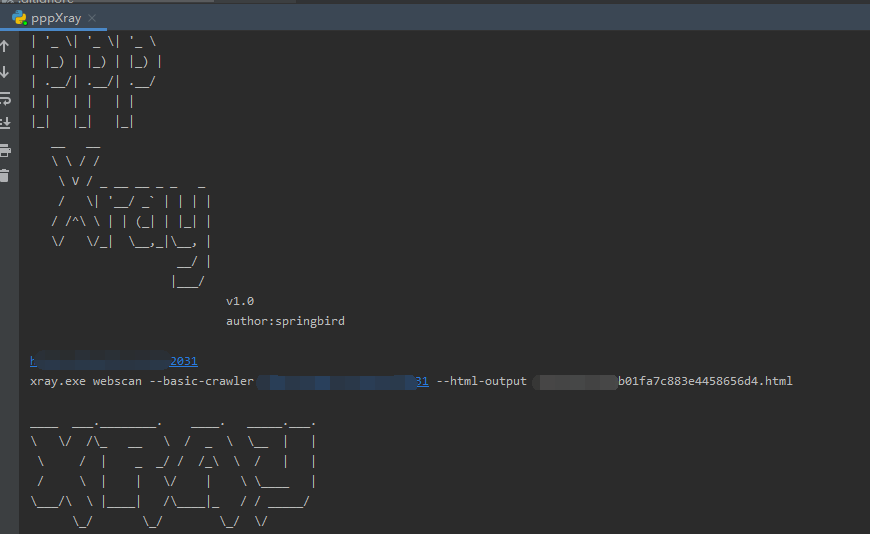
其实这个批量的功能还是挺重要的,或许是Xray开发团队不想扫描器被滥用的原因才没有实现该功能,把代码放在了github上:
https://github.com/Cl0udG0d/pppXray
Xray批量化自动扫描的更多相关文章
- 你的应用安全吗? ——用Xray和Synk保驾护航
一.背景 在当下软件应用的开发过程当中,自研的内部代码所占的比例逐步地减少,开源的框架和共用库已经得到了广泛的引用.如下图所示,在一个Kubernetes部署的应用当中,我们自己开发代码所占的比例可能 ...
- ARL资产导出对接Xray扫描
使用ARL资产灯塔系统对目标进行资产整理的时候,能够对获取的结果进行导出: 导出之后为excel文件 想要将site中的URL导出为txt文件,再使用Xray高级版进行批量化扫描: https://w ...
- xray—学习笔记
长亭xray扫描器 简介 xray (https://github.com/chaitin/xray) 是从长亭洞鉴核心引擎中提取出的社区版漏洞扫描神器,支持主动.被动多种扫描方式,自备盲打平台.可以 ...
- Xray学习
Xray 目前支持的漏洞检测类型包括: XSS漏洞检测 (key: xss) SQL 注入检测 (key: sqldet) 命令/代码注入检测 (key: cmd-injection) 目录枚举 (k ...
- spring自动扫描、DispatcherServlet初始化流程、spring控制器Controller 过程剖析
spring自动扫描1.自动扫描解析器ComponentScanBeanDefinitionParser,从doScan开始扫描解析指定包路径下的类注解信息并注册到工厂容器中. 2.进入后findCa ...
- Spring常用注解,自动扫描装配Bean
1 引入context命名空间(在Spring的配置文件中),配置文件如下: xmlns:context="http://www.springframework.org/schema/con ...
- SpringMVC自动扫描@Controller注解的bean
若要对@Controller注解标注的bean进行自动扫描,必须将<context:component-scan base-package="包路径.controller"/ ...
- Spring的自动扫描与管理
通过在classpath自动扫描方式把组件纳入spring容器中管理 前面的例子我们都是使用XML的bean定义来配置组件.在一个稍大的项目中,通常会有上百个组件,如果这些这组件采用xml的bean定 ...
- 自动扫描FTP文件工具类 ScanFtp.java
package com.util; import java.io.BufferedInputStream; import java.io.BufferedOutputStream; import ja ...
随机推荐
- 3.4 spring5源码系列--循环依赖的设计思想
前面已经写了关于三篇循环依赖的文章, 这是一个总结篇 第一篇: 3.1 spring5源码系列--循环依赖 之 手写代码模拟spring循环依赖 第二篇: 3.2spring源码系列----循环依赖源 ...
- 人体动作捕捉格式之BVH
BVH简介 BVH是BioVision公司推出的一种人体动作捕捉文件格式.这种文件以节点为核心元素,记录连续数帧内人体骨架的运动. BVH=? 研究一个东西的时候我比较喜欢先研究它的名字.BVH可以认 ...
- CV 履历 格式
CV 指的是 "Curriculum Vitae" Curriculum vitae 在拉丁语中的意思是"生命的故事" CV 经常被称为 "Resum ...
- KMP算法和bfprt算法总结
目录 1 KMP算法 1.1 KMP算法分析 1.2 KMP算法应用 题目1:旋转词 题目2:子树问题 2 bfprt算法 2.1 bfprt算法分析 2.2 bfprt算法应用 1 KMP算法 大厂 ...
- http代理阅读4 响应缓存处理
if (c->read->ready) { ngx_http_upstream_process_header(r, u); //读事件触发 准备处理http头部信息 return; } 向 ...
- C/C++中内存对齐问题的一些理解(转)
内存对齐指令 一般来说,内存对齐过程对coding者来说是透明的,是由编译器控制完成的 如对内存对齐有明确要求,可用#pragma pack(n)指定,以n和结构体中最长数据成员长度中较小者为有效值 ...
- 在Linux下的安装mysql-5.7.28 心得总结
mysql-5.7.28 在Linux下的安装教程图解 这篇文章主要介绍了mysql-5.7.28 的Linux安装,本文通过图文并茂的形式给大家介绍的非常详细,具有一定的参考借鉴价值,希望给有需要的 ...
- git , repo out off memory
解决方法,建立swap # dd if=/dev/zero of=/root/myswapfile bs=1M count=1024 1024+0 records in 1024+0 records ...
- Spring源码之FactoryBean的实现
https://zhuanlan.zhihu.com/p/97005407 https://blog.csdn.net/qq_35634181/article/details/104507465 总结 ...
- HDU100题简要题解(2020~2029)
HDU2020 绝对值排序 题目链接 Problem Description 输入n(n<=100)个整数,按照绝对值从大到小排序后输出.题目保证对于每一个测试实例,所有的数的绝对值都不相等. ...