使用python统计《三国演义》小说里人物出现次数前十名,并实现可视化。
一、安装所需要的第三方库
jieba (jieba是优秀的中文分词第三分库)
pyecharts (一个优秀的数据可视化库)
《三国演义》.txt下载地址(提取码:kist )
使用pycharm安装库
- 打开Pycharm选择【File】下的Settings

- 出现下面页面,
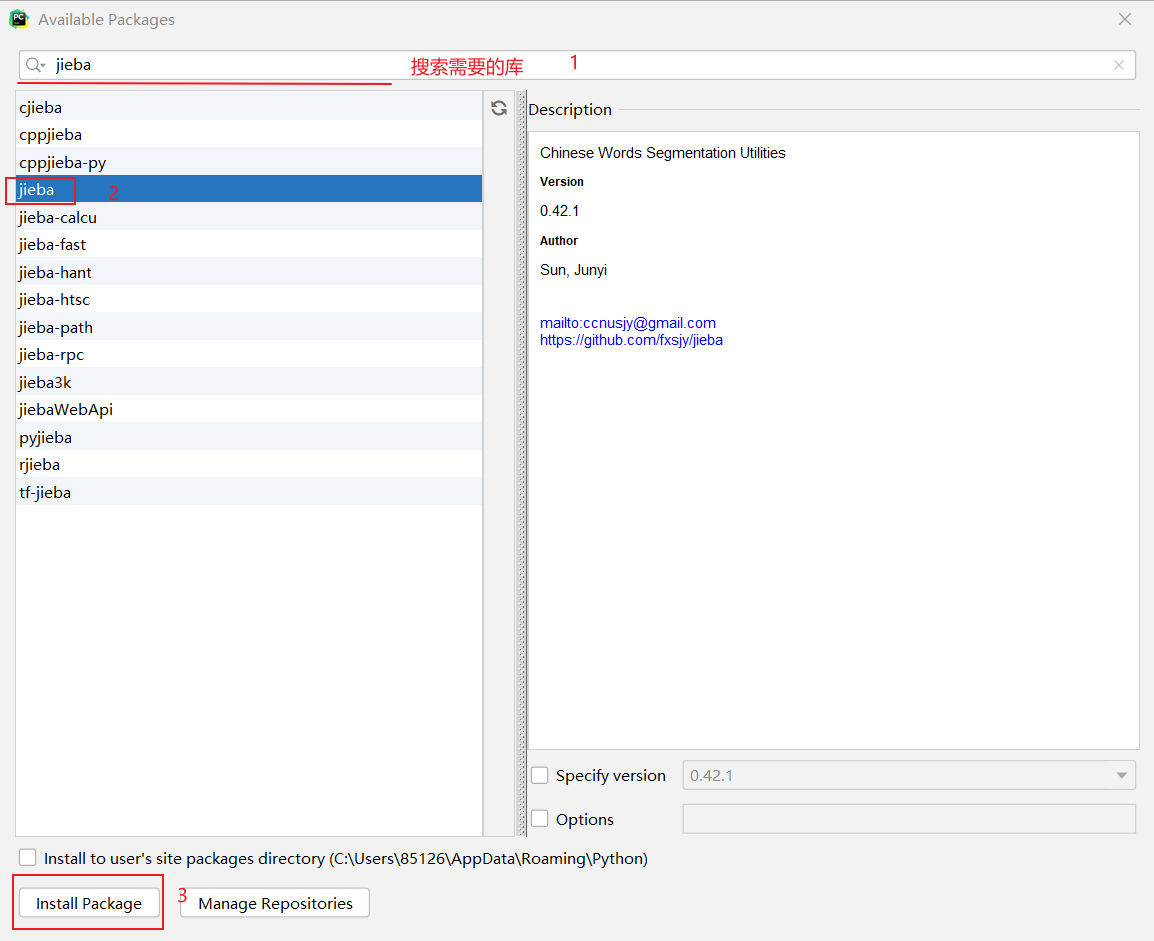
- 选择右边的【+】出现下面页面,在此页面顶端搜索想要的库,然后安装就可以了
二、编写代码
import jieba #导入库import osprint("人物出现次数前十名:")txt = open('三国演义.txt', 'r' ,encoding='gb18030').read()words = jieba.lcut(txt)counts = {}for word in words:if len(word) == 1:continueelif word == "诸葛亮" or word == "孔明曰":rword = "孔明"elif word == "关公" or word == "云长":rword = "关羽"elif word == "玄德" or word == "玄德曰":rword = "刘备"elif word == "孟德" or word == "丞相":rword = "曹操" # 把相同意思的名字归为一个人else:rword = wordcounts[rword] = counts.get(rword, 0) + 1items = list(counts.items())items.sort(key=lambda x: x[1], reverse=True)for i in range(10):word, count=items[i]print("{}:{}".format(word, count)) # 打印前十名名单
- 结果如下图:
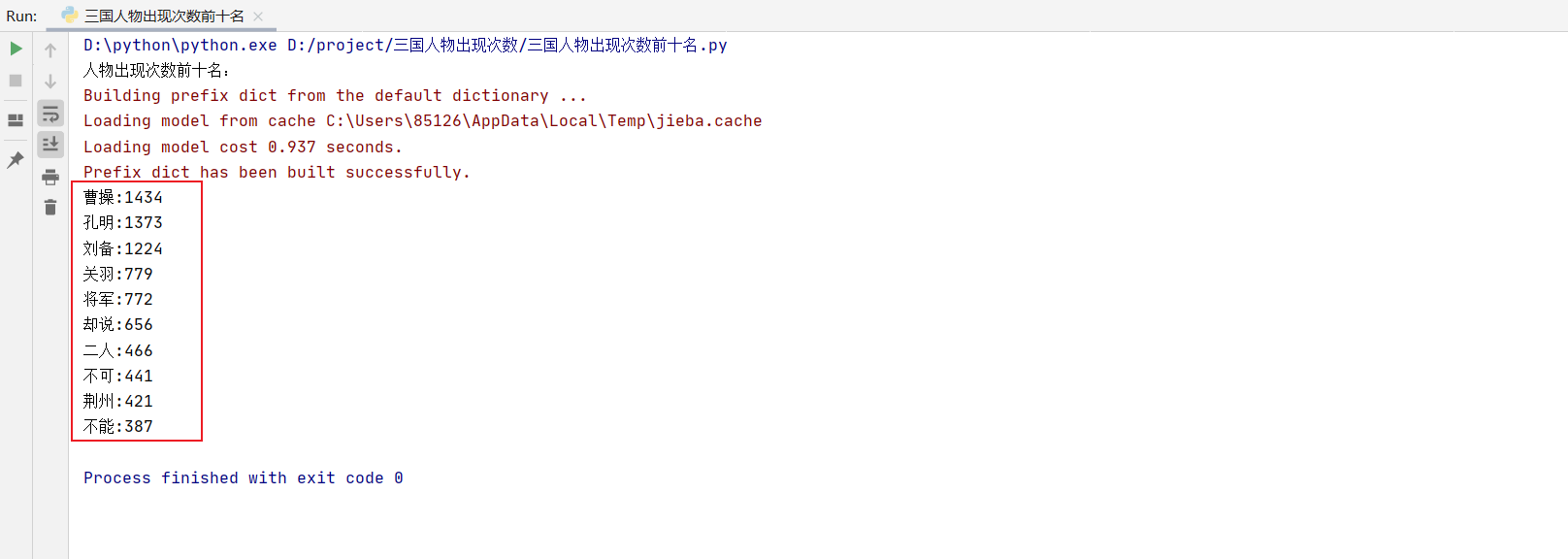
- 可以看到这里面有很多不是人物的名字,所以咱们要把这些删掉。更改代码如下
import jieba #导入库import osprint("人物出现次数前十名:")txt = open('三国演义.txt', 'r' ,encoding='gb18030').read()remove = {"将军", "却说", "不能", "后主", "上马", "不知", "天子", "大叫", "众将", "不可","主公", "蜀兵", "只见", "如何", "商议", "都督", "一人", "汉中", "人马","陛下", "魏兵", "天下", "今日", "左右", "东吴", "于是", "荆州", "不能", "如此","大喜", "引兵", "次日", "军士", "军马","二人","不敢"} # 这些文字是要排出掉的,多次运行程序所得到的words = jieba.lcut(txt)counts = {}for word in words:if len(word) == 1:continueelif word == "诸葛亮" or word == "孔明曰":rword = "孔明"elif word == "关公" or word == "云长":rword = "关羽"elif word == "玄德" or word == "玄德曰":rword = "刘备"elif word == "孟德" or word == "丞相":rword = "曹操" # 把相同意思的名字归为一个人else:rword = wordcounts[rword] = counts.get(rword, 0) + 1for word in remove:del counts[word] #匹配文字相等就删除items = list(counts.items())items.sort(key=lambda x: x[1], reverse=True)for i in range(10):word, count=items[i]print("{}:{}".format(word, count)) # 打印前十名名单
- 运行结果如下图
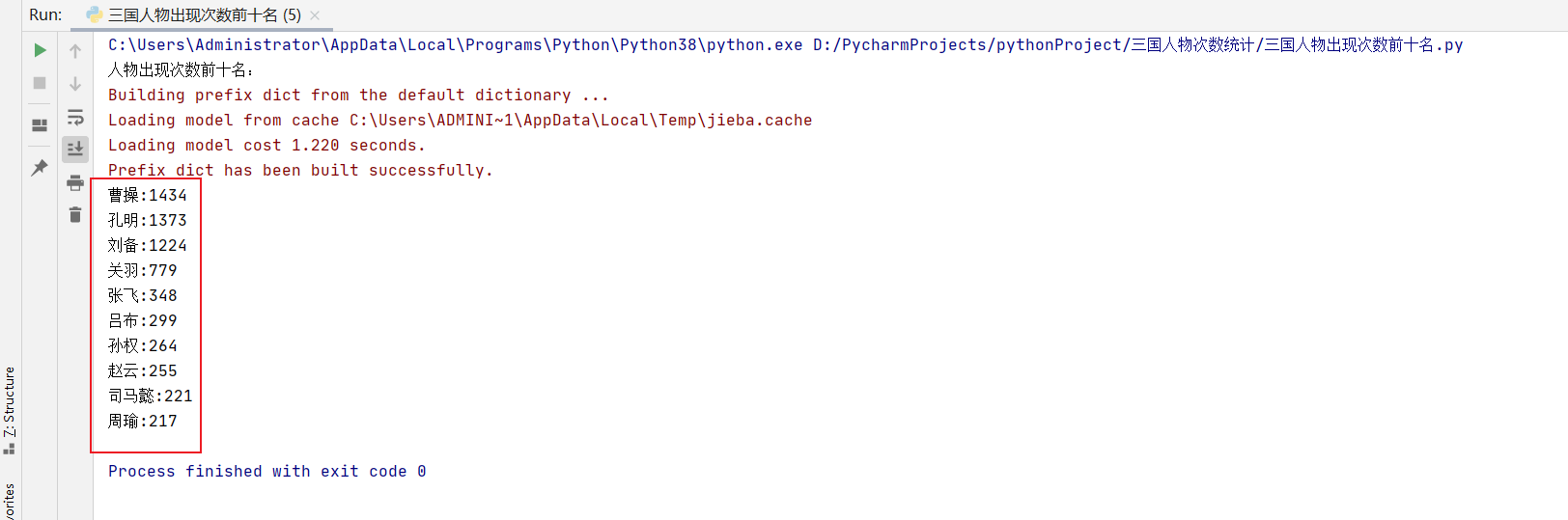
可以看到现在都是人物名称了
- 导出数据,代码如下
import jieba #导入库import osprint("人物出现次数前十名:")txt = open('三国演义.txt', 'r' ,encoding='gb18030').read()remove = {"将军", "却说", "不能", "后主", "上马", "不知", "天子", "大叫", "众将", "不可","主公", "蜀兵", "只见", "如何", "商议", "都督", "一人", "汉中", "人马","陛下", "魏兵", "天下", "今日", "左右", "东吴", "于是", "荆州", "不能", "如此","大喜", "引兵", "次日", "军士", "军马","二人","不敢"} # 这些文字是要排出掉的,多次运行程序所得到的words = jieba.lcut(txt)counts = {}for word in words:if len(word) == 1:continueelif word == "诸葛亮" or word == "孔明曰":rword = "孔明"elif word == "关公" or word == "云长":rword = "关羽"elif word == "玄德" or word == "玄德曰":rword = "刘备"elif word == "孟德" or word == "丞相":rword = "曹操" # 把相同意思的名字归为一个人else:rword = wordcounts[rword] = counts.get(rword, 0) + 1for word in remove:del counts[word] #匹配文字相等就删除items = list(counts.items())items.sort(key=lambda x: x[1], reverse=True)#导出数据fo = open("三国人物出场次数.txt", "a", encoding='utf-8')for i in range(10):word, count=items[i]word = str(word)count = str(count)fo.write(word)fo.write(':') #使用冒号分开fo.write(count)fo.write('\n') #换行fo.close() #关闭文件
- 现在咱们运行看是否导出,运行结果如下图。
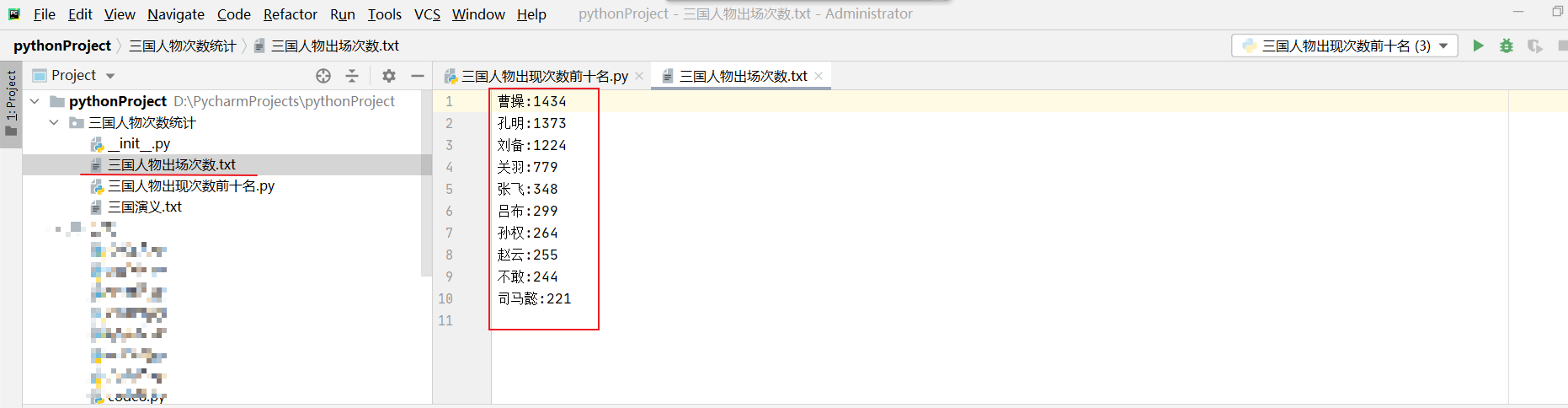
可以看到已经生成一个名为三国人物出场次数.txt的文件,而文件里的内容就是咱们刚才的数据。
三、数据可视化
- 想要可视化首先咱们要有数据,咱们把刚才导出的数据转换为字典形式。代码如下
#将txt文本里的数据转换为字典形式fr = open('三国人物出场次数.txt', 'r', encoding='utf-8')dic = {}keys = [] # 用来存储读取的顺序for line in fr:v = line.strip().split(':')dic[v[0]] = v[1]keys.append(v[0])fr.close()print(dic)
-运行结果如下

- 使用pyecharts绘图
- 先倒入模块
from pyecharts import options as optsfrom pyecharts.charts import Bar
- 代码如下
# 绘图list1=list(dic.keys())list2=list(dic.values()) #提取字典里的数据作为绘图数据c = (Bar().add_xaxis(list1).add_yaxis("人物出场次数",list2).set_global_opts(xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),).render("人物出场次数可视化图.html"))
- 运行程序看到目录下会生成一个名为人物出场次数可视化图.html的文件,如下图
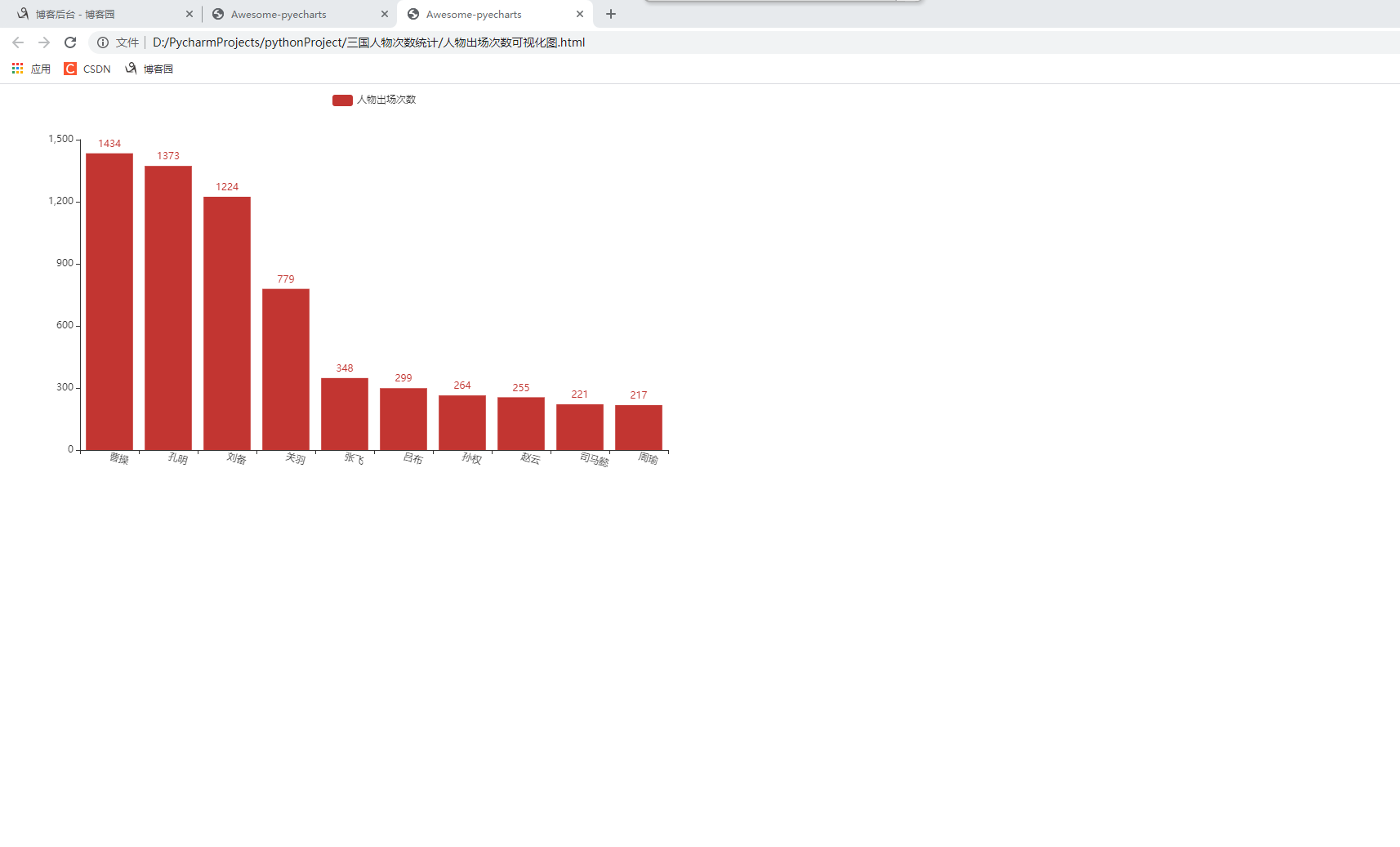
- 使用浏览器打开,就可以看到数据以图形的方式呈现出来。
三、全部代码呈现
#《三国演义》的人物出场次数Python代码:import jieba #导入库import osfrom pyecharts import options as optsfrom pyecharts.charts import Barprint("人物出现次数前十名:")txt = open('三国演义.txt', 'r' ,encoding='gb18030').read()remove = {"将军", "却说", "不能", "后主", "上马", "不知", "天子", "大叫", "众将", "不可","主公", "蜀兵", "只见", "如何", "商议", "都督", "一人", "汉中", "人马","陛下", "魏兵", "天下", "今日", "左右", "东吴", "于是", "荆州", "不能", "如此","大喜", "引兵", "次日", "军士", "军马","二人","不敢"} # 这些文字是要排出掉的,多次运行程序所得到的words = jieba.lcut(txt)counts = {}for word in words:if len(word) == 1:continueelif word == "诸葛亮" or word == "孔明曰":rword = "孔明"elif word == "关公" or word == "云长":rword = "关羽"elif word == "玄德" or word == "玄德曰":rword = "刘备"elif word == "孟德" or word == "丞相":rword = "曹操" # 把相同意思的名字归为一个人else:rword = wordcounts[rword] = counts.get(rword, 0) + 1for word in remove:del counts[word] #匹配文字相等就删除items = list(counts.items())items.sort(key=lambda x: x[1], reverse=True)#导出数据fo = open("三国人物出场次数.txt", "a", encoding='utf-8')for i in range(10):word, count=items[i]word = str(word)count = str(count)fo.write(word)fo.write(':') #使用冒号分开fo.write(count)fo.write('\n') #换行fo.close() #关闭文件#将txt文本里的数据转换为字典形式fr = open('三国人物出场次数.txt', 'r',encoding='utf-8' )dic = {}keys = [] # 用来存储读取的顺序for line in fr:v = line.strip().split(':')dic[v[0]] = v[1]keys.append(v[0])fr.close()print(dic)# 绘图list1=list(dic.keys())list2=list(dic.values()) #提取字典里的数据作为绘图数据c = (Bar().add_xaxis(list1).add_yaxis("人物出场次数",list2).set_global_opts(xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),).render("人物出场次数可视化图.html"))
使用python统计《三国演义》小说里人物出现次数前十名,并实现可视化。的更多相关文章
- Python统计日志中每个IP出现次数
介绍了Python统计日志中每个IP出现次数的方法,实例分析了Python基于正则表达式解析日志文件的相关技巧,需要的朋友可以参考下 本脚本可用于多种日志类型 #-*- coding:utf-8 -* ...
- python 统计字符串中指定字符出现次数的方法
python 统计字符串中指定字符出现次数的方法: strs = "They look good and stick good!" count_set = ['look','goo ...
- python统计英文首字母出现的次数
使用python解析有道词典导出的xml格式单词,统计各个首字母出现的次数,并按次数由多到少进行排序 相关实现 导出的xml格式如下 <wordbook> <item> < ...
- python统计字符串里每个字符的次数
方法一: 推导式 dd="ewq4aewtaSDDSFDTFDSWQrtewtyufashas" print {i:dd.count(i) for i in dd} 方法二: co ...
- 【python】一篇文章里的词频统计
一.环境 1.python3.6 2.windows系统 3.安装第三方模块 pip install wordcloud #词云展示库 pip install jieba #结巴分词 pip inst ...
- 简易安装python统计包
PythonCharm简易安装python统计包及 本文介绍使用pythonCharm IDE 来安装Python统计包或一些packages的简单过程,基本无任何技术难度,顺便提一提笔者在安装过程中 ...
- Python统计列表中的重复项出现的次数的方法
本文实例展示了Python统计列表中的重复项出现的次数的方法,是一个很实用的功能,适合Python初学者学习借鉴.具体方法如下:对一个列表,比如[1,2,2,2,2,3,3,3,4,4,4,4],现在 ...
- Python抓取小说
Python抓取小说 前言 这个脚本命令MAC在抓取小说写,使用Python它有几个码. 代码 # coding=utf-8 import re import urllib2 import chard ...
- 使用jieba分析小说人物出现次数
分析: 1. 读取小说,以读的形式打开 with open('文件名.txt','r',encoding='utf8') as f: str = f.read() 2. 切割小说 ret = jieb ...
随机推荐
- 《Graph-Based Reasoning over Heterogeneous External Knowledge for Commonsense Question Answering》论文整理
融合异构知识进行常识问答 论文标题 -- <Graph-Based Reasoning over Heterogeneous External Knowledge for Commonsense ...
- Qlik Sense学习笔记之Mashup开发(二)
date: 2019-01-26 11:28:07 updated: 2019-01-26 11:28:07 Qlik Sense学习笔记之Mashup开发(二) 1.Mobile SPA UI Fr ...
- C2. Balanced Removals (Harder) (幾何、思維)
Codeforce 1237C2 Balanced Removals (Harder) (幾何.思維) 今天我們來看看CF1237C2 題目連結 題目 給你偶數個三維座標點,每次選其中兩點,如果兩點為 ...
- APIO2008免费道路
题目大意 给定一张n个点m条边的图,图上有两种边,求保证有k条第一种边的情况下的最小生成树 传送门 题解 考虑最小生成树kruskal算法 先找到不含限制的最小生成树,然后就可以知道哪些第一种边是必选 ...
- CF618F Double Knapsack
题意简化 给定两个大小为 n 的集合A,B,要求在每个集合中选出一个子集,使得两个选出来的子集元素和相等 元素范围在 1~n ,n<=1e5 题目连接 题解 考虑前缀和 令A集合的前缀和为SA, ...
- Django、haystack、whoosh实现全局搜索
Django.haystack.whoosh实现全局搜索 关注公众号"轻松学编程"了解更多. [参考:https://blog.csdn.net/zhaogeno1/article ...
- Python爬虫之多线程
详情点我跳转 关注公众号"轻松学编程"了解更多. 多线程 在介绍Python中的线程之前,先明确一个问题,Python中的多线程是假的多线程! 为什么这么说,我们先明确一个概念,全 ...
- linux 安装部署
[smb] service smb restart vim /etc/selinux/config systemctl stop firewalld.service(centos7 64) seten ...
- Appium学习之驱动真机运行
一.Appium工具的简单原理 Appium工具可以分为:客户端(appium-client).服务端(appium-server)和移动设备端(模拟器或者真机).客户端支持多语言,如:python- ...
- 10、Django与Ajax
AJAX准备知识:JSON 什么是 JSON ? JSON 指的是 JavaScript 对象表示法(JavaScript Object Notation) JSON 是轻量级的文本数据交换格式 JS ...