oracle模糊查询mysql的区别
https://blog.csdn.net/weixin_38673554/article/details/86503982#_1
oracle与使用mysql的区别
https://www.cnblogs.com/nr-zhang/p/10553646.html
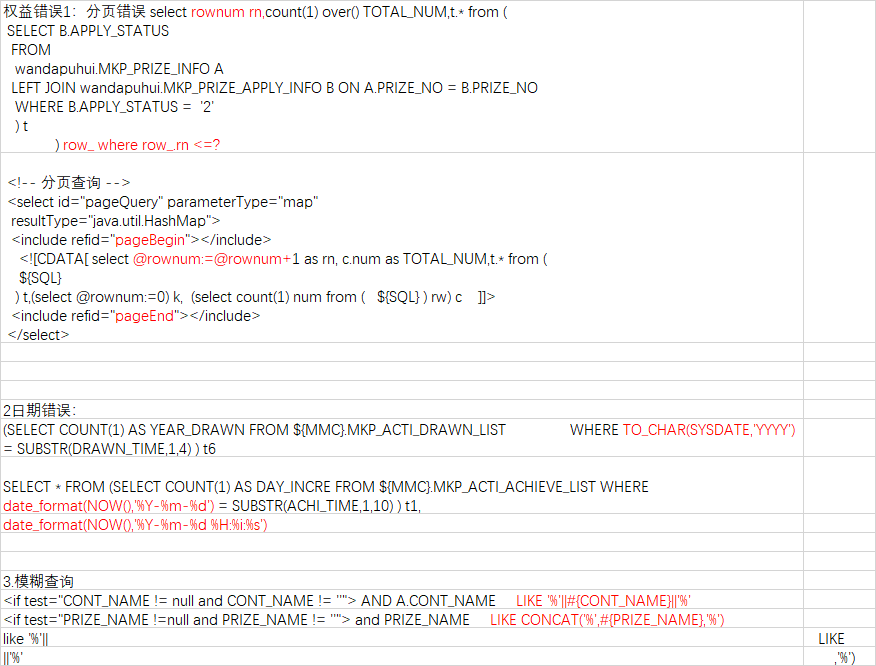
1.Like模糊查询有字符串拼接
所有用 str1||str2 拼接的字符串都要改成CONCAT(str1,str2)
'%'||#{zbmc}||'%'改成CONCAT('%',#{zbmc},'%')
a.fpdm||'-'||a.fphm 改成CONCAT(a.fpdm,'-',a.fphm)
Oracle中concat与||区别(以及与mysql中concat函数区别)
2. 分页查询
oracle中的ROWNUM
SELECT * FROM (SELECT ROWNUM rn,a.* from ( SELECT
A.* from FX_PZ A
) a where ROWNUM<=#{endRow} ) WHERE rn>#{startRow} order by ${sort} ${order}
1
2
3
改成
SELECT A.* from FX_PZ A
order by ${sort} ${order} limit #{startRow},#{rows}
1
2
注意limt关键字是最后才用到的。以下条件的出现顺序一般是:where->group by->having-order by->limit
Oracle与Mysql的分页比较
MySQL的Limit详解
3.Oracle中to_date/to_char函数改成MySql中的函数
to_date(#{kprqs},'yyyy-MM-dd')改成 str_to_date(#{kprqs},'%Y-%m-%d')
to_char(kprq,'yyyy-MM')改成date_format(kprq,'%Y-%m')
to_char(kprq,'q')改成 FLOOR((date_format(kprq, '%m')+2)/3))
mysql和oracle中的to_date()/to_char()互换
Oracle中的时间函数用法(to_date、to_char) (总结)
4.Oracle中nvl/decode函数改成MySql中的函数
nvl(sum(a.je),0)改成ifnull(sum(a.je),0)
nvl、ifnull 用法(将null转代为0)
decode(trim(s.fpzt),'0','正常','2','作废','3','红冲','')
改成
( case trim(s.fpzt)
when '0' then '正常'
when '2' then '作废'
when '3' then '红冲'
else '' end
)
1
2
3
4
5
6
decode(sum(sl), null, 0.00, sum(sl)) as sl,
改成
IFNULL(SUM(sl),0.00)或者( case when sum(je) is null then 0.00 else sum(je) end)
oracle/MySQL 中的decode的使用
5.Oracle中substr/to_number函数改成MySql中的函数
substr(kprq,0,8) 改成 substr(kprq,1,8)
mysql函数substr 注意脚标从1开始
Oracle中的substr()函数 详解及应用
to_number(b.field1)改成 cast(b.field1 as unsigned int)
select cast(11 as unsigned int) /整型/
select cast(11 as decimal(10,2)) /浮点型/
6.Oracle中MERGE INTO批量更新/插入改成MySql的批量更新插入
Mybatis批量新增或更新(mysql数据库)
<update id="updateFlbmBatch" parameterType="java.util.List">
MERGE INTO TAB_FLBM A
USING
<foreach collection="list" item="item" index="index"
separator="union">
(select
#{item.ssflbm,jdbcType=VARCHAR},
#{item.bb,jdbcType=VARCHAR},
#{item.qysj,jdbcType=VARCHAR},
#{item.gdqjzsj,jdbcType=VARCHAR}, #{item.spbm,jdbcType=VARCHAR},
#{item.spmc,jdbcType=VARCHAR},
#{item.sm,jdbcType=VARCHAR},
#{item.zzssl,jdbcType=VARCHAR},
#{item.gjz,jdbcType=VARCHAR},
#{item.hzx,jdbcType=CHAR},
#{item.kyzt,jdbcType=CHAR},
#{item.zzstsgl,jdbcType=VARCHAR},
#{item.zzszcyj,jdbcType=VARCHAR},
#{item.zzstsnrdm,jdbcType=VARCHAR}, #{item.xfsgl,jdbcType=VARCHAR},
#{item.xfszcyj,jdbcType=VARCHAR},
#{item.xfstsnrdm,jdbcType=VARCHAR},
#{item.tjjbm,jdbcType=VARCHAR},
#{item.pid,jdbcType=VARCHAR},
#{item.gxsj,jdbcType=VARCHAR}, #{item.bbh,jdbcType=VARCHAR},
#{item.spbmjc,jdbcType=VARCHAR},
#{item.hgjcksppm,jdbcType=CLOB} from
dual) b
</foreach>
on (a.ssflbm=b.ssflbm)
when matched then
update set a.BB = b.BB,
a.QYSJ = b.QYSJ,
a.GDQJZSJ = b.GDQJZSJ,
a.SPBM = b.SPBM,
a.SPMC = b.SPMC,
a.SM = b.SM,
a.ZZSSL = b.ZZSSL,
a.GJZ = b.GJZ,
a.HZX = b.HZX,
a.KYZT = b.KYZT,
a.ZZSTSGL = b.ZZSTSGL,
a.ZZSZCYJ = b.ZZSZCYJ,
a.ZZSTSNRDM = b.ZZSTSNRDM,
a.XFSGL = b.XFSGL,
a.XFSZCYJ = b.XFSZCYJ,
a.XFSTSNRDM = b.XFSTSNRDM,
a.TJJBM = b.TJJBM,
a.PID = b.PID,
a.GXSJ = b.GXSJ,
a.BBH = b.BBH,
a.SPBMJC = b.SPBMJC
when
not matched then
insert into TAB_FLBM (SSFLBM, BB, QYSJ,
GDQJZSJ, SPBM,
SPMC,
SM, ZZSSL, GJZ, HZX,
KYZT, ZZSTSGL, ZZSZCYJ,
ZZSTSNRDM, XFSGL,
XFSZCYJ,
XFSTSNRDM, TJJBM, PID,
GXSJ, BBH, SPBMJC)
values
(b.ssflbm, b.bb,
b.qysj,
b.gdqjzsj, b.spbm, b.spmc,
b.sm, b.zzssl,
b.gjz,
b.hzx,jdbcType=CHAR},
b.kyzt,jdbcType=CHAR}, b.zzstsgl,
b.zzszcyj,
b.zzstsnrdm, b.xfsgl, b.xfszcyj,
b.xfstsnrdm, b.tjjbm,
b.pid,
b.gxsj,
b.bbh, b.spbmjc)
</update>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
改成
<update id="updateFlbmBatch" parameterType="java.util.List">
insert into TAB_FLBM
(SSFLBM, BB, QYSJ,
GDQJZSJ, SPBM,
SPMC,
SM, ZZSSL, GJZ, HZX,
KYZT, ZZSTSGL, ZZSZCYJ,
ZZSTSNRDM, XFSGL,
XFSZCYJ,
XFSTSNRDM, TJJBM, PID,
GXSJ, BBH, SPBMJC)
values
<foreach collection="list" item="item" index="index"
separator=",">
(
#{item.ssflbm,jdbcType=VARCHAR},
#{item.bb,jdbcType=VARCHAR},
#{item.qysj,jdbcType=VARCHAR},
#{item.gdqjzsj,jdbcType=VARCHAR}, #{item.spbm,jdbcType=VARCHAR},
#{item.spmc,jdbcType=VARCHAR},
#{item.sm,jdbcType=VARCHAR},
#{item.zzssl,jdbcType=VARCHAR},
#{item.gjz,jdbcType=VARCHAR},
#{item.hzx,jdbcType=CHAR},
#{item.kyzt,jdbcType=CHAR},
#{item.zzstsgl,jdbcType=VARCHAR},
#{item.zzszcyj,jdbcType=VARCHAR},
#{item.zzstsnrdm,jdbcType=VARCHAR}, #{item.xfsgl,jdbcType=VARCHAR},
#{item.xfszcyj,jdbcType=VARCHAR},
#{item.xfstsnrdm,jdbcType=VARCHAR},
#{item.tjjbm,jdbcType=VARCHAR},
#{item.pid,jdbcType=VARCHAR},
#{item.gxsj,jdbcType=VARCHAR}, #{item.bbh,jdbcType=VARCHAR},
#{item.spbmjc,jdbcType=VARCHAR},
#{item.hgjcksppm,jdbcType=CLOB}
)
</foreach>
ON DUPLICATE KEY UPDATE
BB = BB,
QYSJ = QYSJ,
GDQJZSJ = GDQJZSJ,
SPBM = SPBM,
SPMC = SPMC,
SM = SM,
ZZSSL = ZZSSL,
GJZ = GJZ,
HZX = HZX,
KYZT = KYZT,
ZZSTSGL = ZZSTSGL,
ZZSZCYJ = ZZSZCYJ,
ZZSTSNRDM = ZZSTSNRDM,
XFSGL = XFSGL,
XFSZCYJ = XFSZCYJ,
XFSTSNRDM = XFSTSNRDM,
TJJBM = TJJBM,
PID = PID,
GXSJ = GXSJ,
BBH = BBH,
SPBMJC = SPBMJC
</update>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
2019-01-10 补充
7.数据库类型 Oracle中number 改成 mysql中decimal
Oracle 版 类型是number 但是oracle中是直接 number 而没有写成 NUMBER(14,2) 还是会有小数位啊
Mysql版 类型是decimal 不添加小数位 小数部分就会四舍五入 所以这点需要注意
8.Oracle中is not null 和 mysql 中有区别
mysql 对 空字符串 和 null 有区分
is not null 在mysql中 如果该字段为 空字符串 那么就是 true 不会过滤掉
null 会被过滤掉
1
2
3
oracle对空字符串和null没有区分
is not null 在oracle中 如果该字段为 空字符串或 null 那么就是 false 会过滤掉
1
2
所以请注意 如果在MySQL中需要用到 is not null 不要设置字段默认值为 Empty String而是设置成null
MySQL中NULL与空字符串
————————————————
版权声明:本文为CSDN博主「csdn_yfqs」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/csdn_yfqs/article/details/83992739
oracle模糊查询mysql的区别的更多相关文章
- Oracle 模糊查询方法
在这个信息量剧增的时代,怎样帮助用户从海量数据中检索到想要的数据.模糊查询是不可缺少的. 那么在Oracle中模糊查询是怎样实现的呢? 一.我们能够在where子句中使用likeke ...
- Oracle模糊查询CONCAT参数个数无效
在使用MyBatis操作Oracle数据库的时候,写模糊查询突然发现原本在MySql中正确的代码,在Oracle中报错,参数个数无效 <if test="empId!=null and ...
- Oracle 模糊查询 优化
模糊查询是数据库查询中经常用到的,一般常用的格式如下: (1)字段 like '%关键字%' 字段包含"关键字"的记录 即使在目标字段建立索引也不会走索引,速度最慢 (2 ...
- oracle模糊查询效率提高
1.使用两边加‘%’号的查询,oracle是不通过索引的,所以查询效率很低. 例如:select count(*) from lui_user_base t where t.user_name lik ...
- oracle模糊查询效率可这样提高
1.使用两边加'%'号的查询,oracle是不通过索引的,所以查询效率很低. 例如:select count(*) from lui_user_base t where t.user_name lik ...
- oracle 模糊查询中的转义字符用法
drop view aaa; create view aaa as select '_BCDE' A FROM DUAL UNION ALL SELECT 'ABCDE' FROM DUAL UNIO ...
- Oracle模糊查询
通配符 % 匹配零个或更多的任意字符 _ 匹配一个任意字符 [ ] 匹配指定范围中的一个字符([a-z],[0-9]) [^ ] 不属于指定范围,不包含其中的字符 escape转义 --查询 ...
- oracle模糊查询提高效率的方法
转载:https://blog.csdn.net/weixiaohuai/article/details/83513957 https://blog.csdn.net/chihen/article/d ...
- mysql正则表达式,实现多个字段匹配多个like模糊查询
现在有这么一个需求 一个questions表,字段有题目(TestSubject),选项(AnswerA,AnswerB,AnswerC,AnswerD,AnswerE) 要求字段不包含png,jpg ...
随机推荐
- java instanceof 判断是否是String
if(formbean.getBean().get("RZZGMCM") instanceof String){ formbean.getBean().put("RZZG ...
- 【代码周边】MongoDB与Mysql对比以及插入稳定性分析(指定主键的影响)
在数据库存放的数据中,有一种特殊的键值叫做主键,它用于惟一地标识表中的某一条记录.也就是说,一个表不能有多个主键,并且主键不能为空值. 无论是MongoDB还是MySQL,都存在着主键的定义. 对于M ...
- idea中surround with
idea中的surround with是把选中的代码块装进一些带有{}的语句中,比如if,try,for等等 快捷键是ctrl+alt+t,先选中代码,再按快捷键,如图
- 基于Opencv的简单图像处理
实验环境 本实验均在笔记本电脑完成,电脑的配置如表1所示: 系统 Windows 10 家庭版 处理器 英特尔 Core i5-6200 @ 2.30GHz 双核 主板 宏碁 Zoro_SL 内存 1 ...
- 第13章节 BJROBOT 雷达跟随【ROS全开源阿克曼转向智能网联无人驾驶车】
雷达跟随说明:注意深度摄像头的 USB 延长线,可能会对雷达扫描造成影响, 所以在雷达跟随前,把深度摄像头的 USB 延长线取下.另外雷达跟随范围大概是前方 50cm 和 120°内扫描到的物体都可以 ...
- Oracle 模糊查询 优化
模糊查询是数据库查询中经常用到的,一般常用的格式如下: (1)字段 like '%关键字%' 字段包含"关键字"的记录 即使在目标字段建立索引也不会走索引,速度最慢 (2 ...
- 瞄到BindingGroup用法
文章转载于https://www.cnblogs.com/dangnianxiaoqingxin/p/12653988.html 2.BindingGroup的使用 public class MyCl ...
- 剑指offer 面试题2:实现Singleton模式
转自:https://blog.csdn.net/liang19890820/article/details/61615495 Singleton 的头文件(懒汉式/饿汉式公用): // single ...
- linux之curl工具
curl是一个利用URL语法在命令行下工作的文件传输工具,作用是发出网络请求,然后获取数据:它支持文件的上传和下载:支持多种通信协议. 一.查看网页源码 直接在 curl 命令后加上网址,默认会发送 ...
- 【Linux】tcpdump
tcpdump介绍 tcpdump 是一个运行在命令行下的抓包工具.它允许用户拦截和显示发送或收到过网络连接到该计算机的TCP/IP和其他数据包.tcpdump 适用于 大多数的类Unix系统操作系统 ...