谱聚类的python实现
什么是谱聚类?
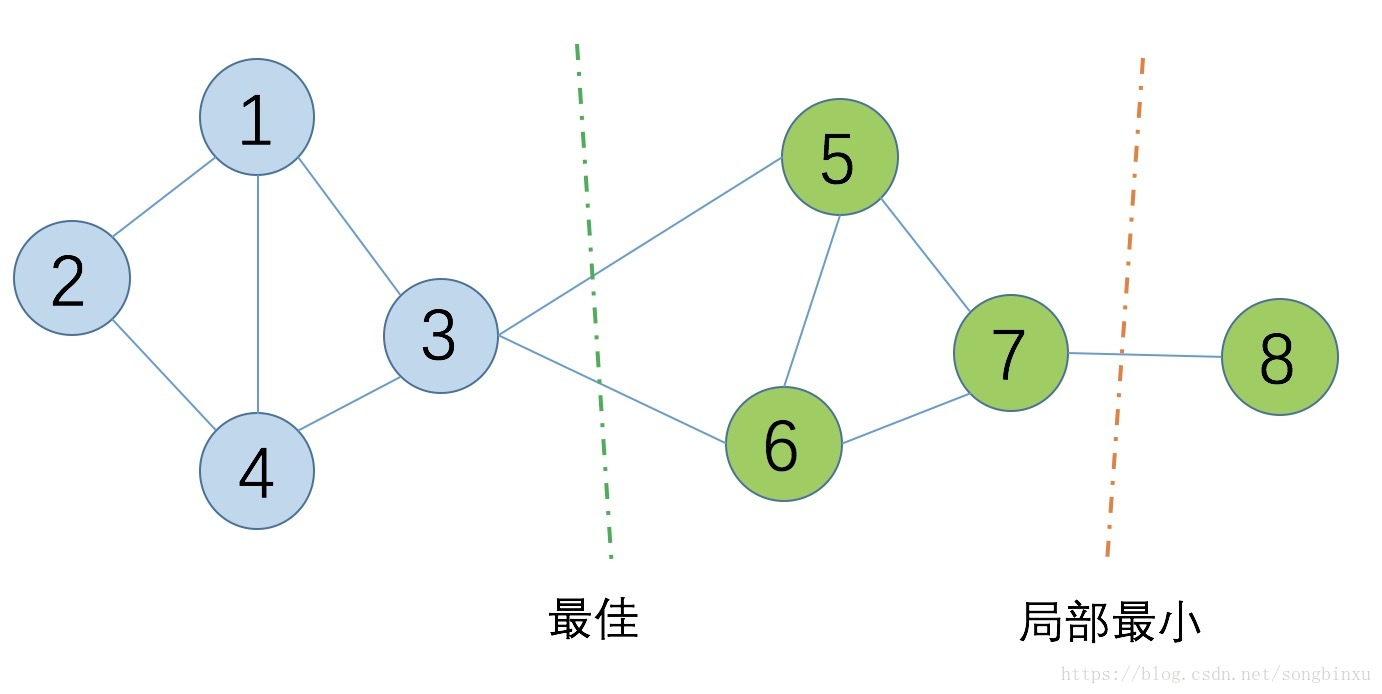
就是找到一个合适的切割点将图进行切割,核心思想就是:

使得切割的边的权重和最小,对于无向图而言就是切割的边数最少,如上所示。但是,切割的时候可能会存在局部最优,有以下两种方法:
(1)RatioCut:核心是要求划分出来的子图的节点数尽可能的大
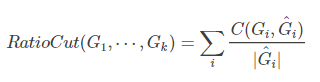
分母变为子图的节点的个数 。
(2)NCut:考虑每个子图的边的权重和
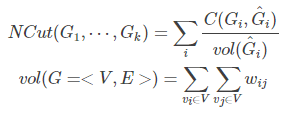
分母变为子图各边的权重和。
具体之后求解可以参考:https://blog.csdn.net/songbinxu/article/details/80838865
谱聚类的整体流程?
- 计算距离矩阵(例如欧氏距离)
- 利用KNN计算邻接矩阵 A
- 由 A 计算度矩阵 D 和拉普拉斯矩阵 L
- 标准化 L→$D^{−1/2}LD^{−1/2}$
- 对矩阵 $D^{−1/2}LD^{−1/2}$进行特征值分解,得到特征向量 $H_{nn}$
- 将 $H_{nn}$ 当成样本送入 Kmeans 聚类
- 获得聚类结果 C=(C1,C2,⋯,Ck)
python实现:
(1)首先是数据的生成:
from sklearn import datasets
import matplotlib.pyplot as plt
%matplotlib inline
plt.title('make_circles function example')
plt.scatter(x1[:, 0], x1[:, 1], marker='o')
plt.show()
x1的形状是(1000,2)

(2)接下来,我们要计算两两样本之间的距离:
import numpy as np
def euclidDistance(x1, x2, sqrt_flag=False):
res = np.sum((x1-x2)**2)
if sqrt_flag:
res = np.sqrt(res)
return res
将这些距离用矩阵的形式保存:
def calEuclidDistanceMatrix(X):
X = np.array(X)
S = np.zeros((len(X), len(X)))
for i in range(len(X)):
for j in range(i+1, len(X)):
S[i][j] = 1.0 * euclidDistance(X[i], X[j])
S[j][i] = S[i][j]
return S
S = calEuclidDistanceMatrix(x1)
array([[0.00000000e+00, 1.13270081e+00, 2.62565479e+00, ...,
2.99144277e+00, 1.88193070e+00, 1.12840739e+00],
[1.13270081e+00, 0.00000000e+00, 2.72601994e+00, ...,
2.95125426e+00, 5.11864947e-01, 6.05388856e-05],
[2.62565479e+00, 2.72601994e+00, 0.00000000e+00, ...,
1.30747922e-02, 1.18180915e+00, 2.74692378e+00],
...,
[2.99144277e+00, 2.95125426e+00, 1.30747922e-02, ...,
0.00000000e+00, 1.26037239e+00, 2.97382982e+00],
[1.88193070e+00, 5.11864947e-01, 1.18180915e+00, ...,
1.26037239e+00, 0.00000000e+00, 5.22992113e-01],
[1.12840739e+00, 6.05388856e-05, 2.74692378e+00, ...,
2.97382982e+00, 5.22992113e-01, 0.00000000e+00]])
(3)使用KNN计算跟每个样本最接近的k个样本点,然后计算出邻接矩阵:
def myKNN(S, k, sigma=1.0):
N = len(S)
#定义邻接矩阵
A = np.zeros((N,N))
for i in range(N):
#对每个样本进行编号
dist_with_index = zip(S[i], range(N))
#对距离进行排序
dist_with_index = sorted(dist_with_index, key=lambda x:x[0])
#取得距离该样本前k个最小距离的编号
neighbours_id = [dist_with_index[m][1] for m in range(k+1)] # xi's k nearest neighbours
#构建邻接矩阵
for j in neighbours_id: # xj is xi's neighbour
A[i][j] = np.exp(-S[i][j]/2/sigma/sigma)
A[j][i] = A[i][j] # mutually return A
A = myKNN(S,3)
array([[1. , 0. , 0. , ..., 0. , 0. ,
0. ],
[0. , 1. , 0. , ..., 0. , 0. ,
0.99996973],
[0. , 0. , 1. , ..., 0. , 0. ,
0. ],
...,
[0. , 0. , 0. , ..., 1. , 0. ,
0. ],
[0. , 0. , 0. , ..., 0. , 1. ,
0. ],
[0. , 0.99996973, 0. , ..., 0. , 0. ,
1. ]])
(4)计算标准化的拉普拉斯矩阵
def calLaplacianMatrix(adjacentMatrix):
# compute the Degree Matrix: D=sum(A)
degreeMatrix = np.sum(adjacentMatrix, axis=1)
# compute the Laplacian Matrix: L=D-A
laplacianMatrix = np.diag(degreeMatrix) - adjacentMatrix
# normailze
# D^(-1/2) L D^(-1/2)
sqrtDegreeMatrix = np.diag(1.0 / (degreeMatrix ** (0.5)))
return np.dot(np.dot(sqrtDegreeMatrix, laplacianMatrix), sqrtDegreeMatrix)
L_sys = calLaplacianMatrix(A)
array([[ 0.66601736, 0. , 0. , ..., 0. ,
0. , 0. ],
[ 0. , 0.74997723, 0. , ..., 0. ,
0. , -0.28868642],
[ 0. , 0. , 0.74983185, ..., 0. ,
0. , 0. ],
...,
[ 0. , 0. , 0. , ..., 0.66662382,
0. , 0. ],
[ 0. , 0. , 0. , ..., 0. ,
0.74953329, 0. ],
[ 0. , -0.28868642, 0. , ..., 0. ,
0. , 0.66665079]])
(5)特征值分解
lam, V = np.linalg.eig(L_sys) # H'shape is n*n
lam = zip(lam, range(len(lam)))
lam = sorted(lam, key=lambda x:x[0])
H = np.vstack([V[:,i] for (v, i) in lam[:1000]]).T
H = np.asarray(H).astype(float)
(6)使用Kmeans进行聚类
from sklearn.cluster import KMeans
def spKmeans(H):
sp_kmeans = KMeans(n_clusters=2).fit(H)
return sp_kmeans.labels_
labels = spKmeans(H)
plt.title('spectral cluster result')
plt.scatter(x1[:, 0], x1[:, 1], marker='o',c=labels)
plt.show()

(7) 对比使用kmeans聚类
pure_kmeans = KMeans(n_clusters=2).fit(x1)
plt.title('pure kmeans cluster result')
plt.scatter(x1[:, 0], x1[:, 1], marker='o',c=pure_kmeans.labels_)
plt.show()

参考:
https://www.cnblogs.com/xiximayou/p/13180579.html
https://www.cnblogs.com/chenmo1/p/11681669.html
https://blog.csdn.net/songbinxu/article/details/80838865
https://github.com/SongDark/SpectralClustering/
谱聚类的python实现的更多相关文章
- 谱聚类python实践
聚类后: # -*- coding: utf-8 -*-"""Created on 09 05 2017 @author: similarface"" ...
- 谱聚类--SpectralClustering
谱聚类通常会先对两两样本间求相似度. 然后依据相似度矩阵求出拉普拉斯矩阵,然后将每一个样本映射到拉普拉斯矩阵特诊向量中,最后使用k-means聚类. scikit-learn开源包中已经有现成的接口能 ...
- 用scikit-learn学习谱聚类
在谱聚类(spectral clustering)原理总结中,我们对谱聚类的原理做了总结.这里我们就对scikit-learn中谱聚类的使用做一个总结. 1. scikit-learn谱聚类概述 在s ...
- 谱聚类(spectral clustering)原理总结
谱聚类(spectral clustering)是广泛使用的聚类算法,比起传统的K-Means算法,谱聚类对数据分布的适应性更强,聚类效果也很优秀,同时聚类的计算量也小很多,更加难能可贵的是实现起来也 ...
- [zz]谱聚类
了凡春秋USTC 谱聚类 http://chunqiu.blog.ustc.edu.cn/?p=505 最近忙着写文章,好久不写博客了.最近看到一个聚类方法--谱聚类,号称现代聚类方法,看到它简洁的公 ...
- 大数据下多流形聚类分析之谱聚类SC
大数据,人人都说大数据:类似于人人都知道黄晓明跟AB结婚一样,那么什么是大数据?对不起,作为一个本科还没毕业的小白实在是无法回答这个问题.我只知道目前研究的是高维,分布在n远远大于2的欧式空间的数据如 ...
- Laplacian matrix 从拉普拉斯矩阵到谱聚类
谱聚类步骤 第一步:数据准备,生成图的邻接矩阵: 第二步:归一化普拉斯矩阵: 第三步:生成最小的k个特征值和对应的特征向量: 第四步:将特征向量kmeans聚类(少量的特征向量):
- 谱聚类Ng算法的Matlab简单实现
请编写一个谱聚类算法,实现"Normalized Spectral Clustering-Algorithm 3 (Ng 算法)" 结果如下 谱聚类算法核心步骤都是相同的: •利用 ...
- 【聚类算法】谱聚类(Spectral Clustering)
目录: 1.问题描述 2.问题转化 3.划分准则 4.总结 1.问题描述 谱聚类(Spectral Clustering, SC)是一种基于图论的聚类方法——将带权无向图划分为两个或两个以上的最优子图 ...
随机推荐
- iframe和DataForm
一.iframe使用 iframe在一个页面中,相当于整个window窗口的子窗口,可通过页面的元素结构查看. <div> <p>学习iframe</p> < ...
- paramiko上传文件到Linux
一.传输单个文件到Linux服务器 import paramiko transport = paramiko.Transport(('host',22)) transport.connect(user ...
- 渲染导航菜单的同时给每个菜单绑定不同的router跳转
这个问题一开始的时候,我总想着router跳转只有两种方式 一种@click,一种router-link 然后我想着@click,绑定一个事件,事件下面无法确定我当前是哪个菜单,解决不了. 然后< ...
- c++ 第一天 变量、判断、循环
C++介绍 语言的产生 C++ 由 Bjarne Stroustrup 于 1979 年在贝尔实验室开始设计开发的,由于C++ 进一步扩充和完善了 C 语言,是一种面向对象的程序设计语言 ,所以最初命 ...
- PHP vprintf() 函数
实例 输出格式化的字符串: <?php高佣联盟 www.cgewang.com$number = 9;$str = "Beijing";vprintf("There ...
- 7.29 NOI模拟赛 题答 npc问题 三染色 随机 贪心
LINK:03colors 这道题虽然绝大多数的人都获得了满分 可是我却没有. 老师讲题的时候讲到了做题答的几个技巧 这里总结一下. 数据强度大概为n=5000,m=60000的随机数据. 老师说:一 ...
- P5979 [PA2014]Druzyny dp 分治 线段树 分类讨论 启发式合并
LINK:Druzyny 这题研究了一下午 终于搞懂了. \(n^2\)的dp很容易得到. 考虑优化.又有大于的限制又有小于的限制这个非常难处理. 不过可以得到在限制人数上界的情况下能转移到的最远端点 ...
- springMVC 与 html RESTful 解决方案
若前端为html 而非jsp 且 拦截如下 <servlet-mapping> <servlet-name>springMVC</servlet-name> &l ...
- Spring 方法替换 了解一下
其实说简单的就是一个A Bean 在执行本方法的时候并不执行,而是调用另一个B Bean方法 要求B implements MethodReplacer @Override public ...
- 同事问我MySQL怎么递归查询,我懵逼了
前言 最近在做的业务场景涉及到了数据库的递归查询.我们公司用的 Oracle ,众所周知,Oracle 自带有递归查询的功能,所以实现起来特别简单. 但是,我记得 MySQL 是没有递归查询功能的,那 ...