从代码角度理解NNLM(A Neural Probabilistic Language Model)
其框架结构如下所示:
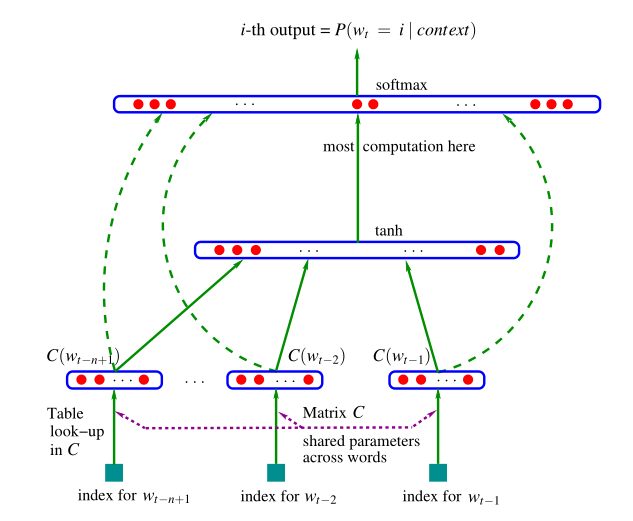
可分为四 个部分:
- 词嵌入部分
- 输入
- 隐含层
- 输出层
我们要明确任务是通过一个文本序列(分词后的序列)去预测下一个字出现的概率,tensorflow代码如下:
参考:https://github.com/pjlintw/NNLM/blob/master/src/nnlm.py
import argparse
import math
import time
import numpy as np
import tensorflow as tf
from datetime import date from preprocessing import TextLoader def main():
parser = argparse.ArgumentParser()
parser.add_argument('--data_dir', type=str, default='data/',
help='data directory containing input.txt')
parser.add_argument('--batch_size', type=int, default=120,
help='minibatch size')
parser.add_argument('--win_size', type=int, default=5,
help='context sequence length')
parser.add_argument('--hidden_num', type=int, default=100,
help='number of hidden layers')
parser.add_argument('--word_dim', type=int, default=300,
help='number of word embedding')
parser.add_argument('--num_epochs', type=int, default=3,
help='number of epochs')
parser.add_argument('--grad_clip', type=float, default=10.,
help='clip gradients at this value') args = parser.parse_args()
args_msg = '\n'.join([ arg + ': ' + str(getattr(args, arg)) for arg in vars(args)]) data_loader = TextLoader(args.data_dir, args.batch_size, args.win_size)
args.vocab_size = data_loader.vocab_size graph = tf.Graph()
with graph.as_default():
input_data = tf.placeholder(tf.int64, [args.batch_size, args.win_size])
targets = tf.placeholder(tf.int64, [args.batch_size, 1]) with tf.variable_scope('nnlm' + 'embedding'):
embeddings = tf.Variable(tf.random_uniform([args.vocab_size, args.word_dim], -1.0, 1.0))
embeddings = tf.nn.l2_normalize(embeddings, 1) with tf.variable_scope('nnlm' + 'weight'):
weight_h = tf.Variable(tf.truncated_normal([args.win_size * args.word_dim, args.hidden_num],
stddev=1.0 / math.sqrt(args.hidden_num)))
softmax_w = tf.Variable(tf.truncated_normal([args.win_size * args.word_dim, args.vocab_size],
stddev=1.0 / math.sqrt(args.win_size * args.word_dim)))
softmax_u = tf.Variable(tf.truncated_normal([args.hidden_num, args.vocab_size],
stddev=1.0 / math.sqrt(args.hidden_num))) b_1 = tf.Variable(tf.random_normal([args.hidden_num]))
b_2 = tf.Variable(tf.random_normal([args.vocab_size])) def infer_output(input_data):
"""
hidden = tanh(x * H + b_1)
output = softmax(x * W + hidden * U + b_2)
"""
input_data_emb = tf.nn.embedding_lookup(embeddings, input_data)
input_data_emb = tf.reshape(input_data_emb, [-1, args.win_size * args.word_dim])
hidden = tf.tanh(tf.matmul(input_data_emb, weight_h)) + b_1
hidden_output = tf.matmul(hidden, softmax_u) + tf.matmul(input_data_emb, softmax_w) + b_2
output = tf.nn.softmax(hidden_output)
return output outputs = infer_output(input_data)
one_hot_targets = tf.one_hot(tf.squeeze(targets), args.vocab_size, 1.0, 0.0)
loss = -tf.reduce_mean(tf.reduce_sum(tf.log(outputs) * one_hot_targets, 1))
# Clip grad.
optimizer = tf.train.AdagradOptimizer(0.1)
gvs = optimizer.compute_gradients(loss)
capped_gvs = [(tf.clip_by_value(grad, -args.grad_clip, args.grad_clip), var) for grad, var in gvs]
optimizer = optimizer.apply_gradients(capped_gvs) embeddings_norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))
normalized_embeddings = embeddings / embeddings_norm
processing_message_lst = list()
with tf.Session(graph=graph) as sess: tf.global_variables_initializer().run()
for e in range(args.num_epochs):
data_loader.reset_batch_pointer()
for b in range(data_loader.num_batches):
start = time.time()
x, y = data_loader.next_batch()
feed = {input_data: x, targets: y}
train_loss, _ = sess.run([loss, optimizer], feed)
end = time.time() processing_message = "{}/{} (epoch {}), train_loss = {:.3f}, time/batch = {:.3f}".format(
b, data_loader.num_batches,
e, train_loss, end - start) print(processing_message)
processing_message_lst.append(processing_message)
# print("{}/{} (epoch {}), train_loss = {:.3f}, time/batch = {:.3f}".format(
# b, data_loader.num_batches,
# e, train_loss, end - start)) np.save('nnlm_word_embeddings.zh', normalized_embeddings.eval()) # record training processing
print(start - end)
local_time = str(time.strftime("%Y-%m-%d_%H:%M:%S", time.localtime()))
with open("{}.txt".format('casdsa'), 'w', encoding='utf-8') as f:
f.write(local_time)
f.write(args_msg)
f.write('\n'.join(processing_message_lst)) if __name__ == '__main__':
main()
我们主要关注的是模型的部分:
词嵌入部分:
embeddings = tf.Variable(tf.random_uniform([args.vocab_size, args.word_dim], -1.0, 1.0))
生成一个[V, N]的矩阵,其中V表示词汇表,由所有词构成,word_dim表示每个词表示的维度;
输入部分:
input_data_emb = tf.nn.embedding_lookup(embeddings, input_data)
input_data_emb = tf.reshape(input_data_emb, [-1, args.win_size * args.word_dim])
我们分词后的每一个词是用其在词汇表中对应的索引来表示的,比如:“我 爱 美丽 的 中国”,表示为[8,12,27,112] ,我们对应的标签就是[44],即我们根据前面4个词来预测最后一个词,此时我们得到的是[batchsize,N,word_dim],然后将其调整形状为:[batchsize,N*word_dim];
隐含层部分:
hidden = tf.tanh(tf.matmul(input_data_emb, weight_h)) + b_1
将之前的每个词嵌入拼接起来后做一个映射,再经过一个tanh激活函数;
输出部分:
hidden_output = tf.matmul(hidden, softmax_u) + tf.matmul(input_data_emb, softmax_w) + b_2
output = tf.nn.softmax(hidden_output)
这里由两个部分组成,一个是隐含层的输出,一个是输入层直接经过映射(跳过隐含层)到输出层的输出,需要注意的是输出层的神经元的个数就是词汇表的大小;
最后在计算损失的时候是:
outputs = infer_output(input_data)
one_hot_targets = tf.one_hot(tf.squeeze(targets), args.vocab_size, 1.0, 0.0)
loss = -tf.reduce_mean(tf.reduce_sum(tf.log(outputs) * one_hot_targets, 1))
训练完成之后我们最终需要的是词嵌入,也就是:
embeddings_norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))
normalized_embeddings = embeddings / embeddings_norm
下面是pytorch版本的,思路是一样的:
参考:https://github.com/LeeGitaek/NNLM_Paper_Implementation/blob/master/nnlm_model.py
# -*- coding: utf-8 -*-
"""NNLM_paper.ipynb
Automatically generated by Colaboratory.
Original file is located at
https://colab.research.google.com/drive/1q6tWzcpFLzU_qvzvkdYiDaxSp--y6nFR
""" import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from torch.autograd import Variable device = 'cuda' if torch.cuda.is_available() else 'cpu' torch.manual_seed(777)
if device == 'cuda':
torch.cuda.manual_seed_all(777) sentences = ['i like dog','i love coffee','i hate milk'] word_list = ' '.join(sentences).split()
word_list = list(set(word_list))
print(word_list) word_dict = {w: i for i,w in enumerate(word_list)}
print('word dict')
print(word_dict)
number_dict = {i: w for i, w in enumerate(word_list)}
print(number_dict)
n_class = len(word_dict) # number of vocabulary print(n_class) #NNLM Parameter
n_step = 2 # n-1 in paper
n_hidden = 2 # h in paper
m = 2 # m in paper
epochs = 5000
learning_rate = 0.001 def make_batch(sentences):
input_batch = []
target_batch = [] for sen in sentences:
word = sen.split()
input = [word_dict[n] for n in word[:-1]]
target = word_dict[word[-1]] input_batch.append(input)
target_batch.append(target) return input_batch,target_batch #model class NNLM(nn.Module):
def __init__(self):
super(NNLM,self).__init__() self.C = nn.Embedding(n_class,m)
self.H = nn.Parameter(torch.randn(n_step * m,n_hidden).type(torch.Tensor))
self.W = nn.Parameter(torch.randn(n_step * m,n_class).type(torch.Tensor))
self.d = nn.Parameter(torch.randn(n_hidden).type(torch.Tensor))
self.U = nn.Parameter(torch.randn(n_hidden,n_class).type(torch.Tensor))
self.b = nn.Parameter(torch.randn(n_class).type(torch.Tensor)) def forward(self,x):
x = self.C(x)
x = x.view(-1,n_step*m) # batch_size,n_step * n_class
tanh = torch.tanh(self.d + torch.mm(x,self.H))
output = self.b + torch.mm(x,self.W)+torch.mm(tanh,self.U)
return output
model = NNLM() criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(),lr=learning_rate) input_batch , target_batch = make_batch(sentences)
print(input_batch)
print('target_batch')
print(target_batch)
input_batch = Variable(torch.LongTensor(input_batch))
target_batch = Variable(torch.LongTensor(target_batch)) for epoch in range(epochs):
optimizer.zero_grad()
output = model(input_batch) loss = criterion(output,target_batch)
if (epoch+1)%100 == 0:
print('epoch : {:.4f} , cost = {:.6f}'.format(epoch+1,loss)) loss.backward()
optimizer.step() predict = model(input_batch).data.max(1,keepdim=True)[1] print([sen.split()[:2] for sen in sentences],'->',[number_dict[n.item()] for n in predict.squeeze()])
从代码角度理解NNLM(A Neural Probabilistic Language Model)的更多相关文章
- A Neural Probabilistic Language Model
A Neural Probabilistic Language Model,这篇论文是Begio等人在2003年发表的,可以说是词表示的鼻祖.在这里给出简要的译文 A Neural Probabili ...
- pytorch ---神经网络语言模型 NNLM 《A Neural Probabilistic Language Model》
论文地址:http://www.iro.umontreal.ca/~vincentp/Publications/lm_jmlr.pdf 论文给出了NNLM的框架图: 针对论文,实现代码如下: # -* ...
- A Neural Probabilistic Language Model (2003)论文要点
论文链接:http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf 解决n-gram语言模型(比如tri-gram以上)的组合爆炸问题,引入 ...
- 建模角度理解word embedding及tensorflow实现
http://www.jianshu.com/p/d44ce1e3ec2f 1. 前言 本篇主要介绍关键词的向量表示,也就是大家熟悉的word embedding.自Google 2013 年开源wo ...
- [Android] Android开发优化之——从代码角度进行优化
通常我们写程序,都是在项目计划的压力下完成的,此时完成的代码可以完成具体业务逻辑,但是性能不一定是最优化的.一般来说,优秀的程序员在写完代码之后都会不断的对代码进行重构.重构的好处有很多,其中一点,就 ...
- 从源码角度理解Java设计模式——装饰者模式
一.饰器者模式介绍 装饰者模式定义:在不改变原有对象的基础上附加功能,相比生成子类更灵活. 适用场景:动态的给一个对象添加或者撤销功能. 优点:可以不改变原有对象的情况下动态扩展功能,可以使扩展的多个 ...
- IL角度理解C#中字段,属性与方法的区别
IL角度理解C#中字段,属性与方法的区别 1.字段,属性与方法的区别 字段的本质是变量,直接在类或者结构体中声明.类或者结构体中会有实例字段,静态字段等(静态字段可实现内存共享功能,比如数学上的pi就 ...
- IL角度理解for 与foreach的区别——迭代器模式
IL角度理解for 与foreach的区别--迭代器模式 目录 IL角度理解for 与foreach的区别--迭代器模式 1 最常用的设计模式 1.1 背景 1.2 摘要 2 遍历元素 3 删除元素 ...
- es6 代码片段理解
代码片段理解: [INCREMENT]: (state, action) => { const { payload: { id } } = action //because payload co ...
随机推荐
- 不停机不更新代码线上调试BUG的工具
如果你有以下痛点,请你查看本文章: 1.我改的代码为什么没有执行到?难道是我没 commit?分支搞错了? 2.遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗? 3.线上遇到某个用户的 ...
- python更改默认版本
1. rm /user/bin/python2. ln -s /usr/bin/python3.5 /usr/bin/python3. PATH=/usr/bin:$PATH
- 【实战分享】从选型到项目落地,漫谈 gRPC
什么是 gRPC? gRPC 的几种常见模式 在学习 gRPC 的时候,相信大家对于它的四种模式都有了解,我们来简单回顾一下: 简单模式(Simple RPC):这种模式最为传统,即客户端发起一次请求 ...
- 关于java和JS中的lastIndexOf方法的误解。
今天看JS的数组的lastIndexOf()方法,看书上的例子,怎么看都觉得不对劲.后来详细读了几遍解释,用java也测试了下,才发现,之前的理解完全是错误的. 上例子: String nums=&q ...
- IP 层收发报文简要剖析6--ip_forward 报文转发
//在函数ip_route_input_slow->ip_mkroute_input注册, /* * IP数据包的转发是由ip_forward()处理,该函数在ip_rcv_finish() * ...
- OLTP与OLAP分析与比较
(本文转载自Super_Mu的博客https://www.cnblogs.com/hhandbibi/p/7118740.html) 1.OLTP与OLAP的介绍 数据处理大致可以分成两大类:联机事务 ...
- spring 2.5 基础知识和与其他框架的集成
spring环境搭建: 一:导入spring2.5所需的包,在classpath目录下建一个名为"beans.xml"模板文件: <?xml version="1. ...
- Dubbo 初识SPI-Version2.7.5
1简介 SPI 全称为 Service Provider Interface,是一种服务发现机制.SPI 的本质是将接口实现类的全限定名配置在文件中,并由服务加载器读取配置文件,加载实现类.这样可以在 ...
- [转载]Redis 持久化之RDB和AOF
原文链接:https://www.cnblogs.com/itdragon/p/7906481.html 温馨提示 在正式数据(当然是非生产环境啦)练习以下操作时,一定一定一定记得备份dump.rdb ...
- 标准库之time,random,sys,os
# import time # print(time.time()) # 时间戳 # print(time.mktime(time.localtime())) # 结构化时间转换为时间戳 # prin ...