技术分享丨数据仓库的建模与ETL实践技巧
摘要:如何搭建数据仓库,在这个过程中都应该遵循哪些方法和原则,项目实践中有哪些技巧。
一、数据仓库的“心脏”
首先来谈谈数据模型。模型是现实世界特征的模拟和抽象,比如地图、建筑设计沙盘,飞机模型等等。

而数据模型DataModel是现实世界数据特征的抽象。
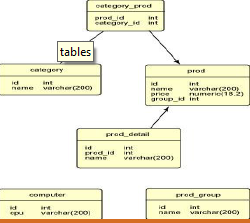
在数据仓库项目建设中,数据模型的建立具有重要的意义,客户的业务场景,流程规则,行业知识都体现在通过数据模型表现出来,在业务人员和技术人员之间搭建起来了一个沟通的桥梁,所以在国外一些数据仓库的文献中,把数据模型称之为数据仓库的心脏“TheHeartoftheDataWarehouse”。

数据模型设计的好坏直接影响数据的
- 稳定性
- 易用性
- 访问效率
- 存储容量
- 维护成本
二、数据仓库中数据模型,数据分层和ETL程序
2.1概述
数据仓库是一种通过(准)实时/批量的方式把各种外部数据源集成起来后,采用多种方式提供给最终用户进行数据消费的信息系统。
面对繁多的上游业务系统而言,数据仓库的一个重要任务就是进行数据清洗和集成,形成一个标准化的规范化的数据结构,为后续的一致性的数据分析提供可信的数据基础。
另一方面数据仓库里面的数据要发挥价值就需要通过多种形式表现,有用于了解企业生产状况的固定报表,有用于向管理层汇报的KPI驾驶舱,有用于大屏展示的实时数据推送,有用于部门应用的数据集市,也有用于分析师的数据实验室...对于不同的数据消费途径,数据需要从高度一致性的基础模型转向便于数据展现和数据分析的维度模型。不同阶段的数据因此需要使用不同架构特点的数据模型与之相匹配,这也就是数据在数据仓库里面进行数据分层的原因。
数据在各层数据中间的流转,就是从一种数据模型转向另外一种数据模型,这种转换的过程需要借助的就是ETL算法。打个比方,数据就是数据仓库中的原材料,而数据模型是不同产品形态的模子,不同的数据层就是仓库的各个“车间”,数据在各个“车间”的形成流水线式的传动就是依靠调度工具这个流程自动化软件,执行SQL的客户端工具是流水线上的机械臂,而ETL程序就是驱动机械臂进行产品加工的算法核心。
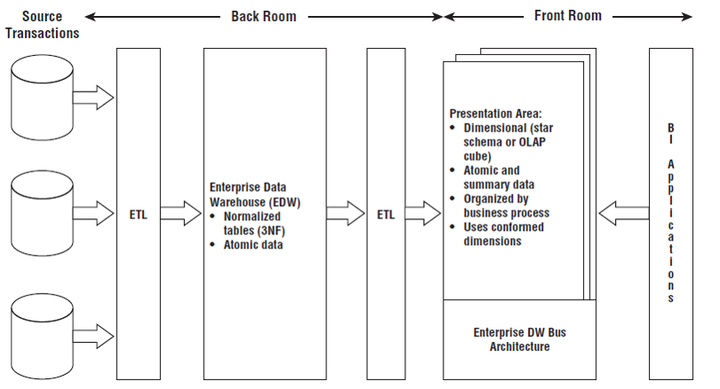
上图是数据仓库工具箱-维度建模权威指南一书中的数据仓库混合辐射架构
2.2金融行业中的分层模型
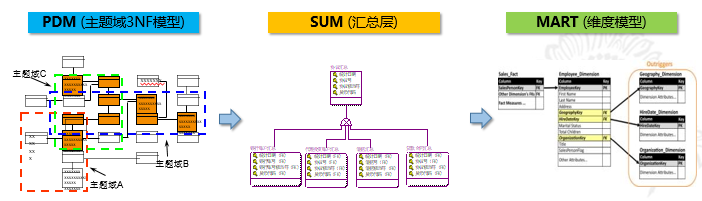
金融行业中的数据仓库是对模型建设要求最高也是最为成熟的一个行业,在多年的金融行业数据仓库项目建设过程中,基本上都形成了缓冲层,基础模型层,汇总层(共性加工层),以及集市层。不同的客户会依托这四层模型做不同的演化,可能经过合并形成三层,也可能经过细分,形成5层或者6层。本文简单介绍最常见的四层模型:
缓冲层:有的项目也称为ODS层,简单说这一层数据的模型就是贴源的,对于仓库的用户就是在仓库里面形成一个上游系统的落地缓冲带,原汁原味的生产数据在这一层得以保存和体现,所以这一层数据保留时间周期较短,常见的是7~15天,最大的用途是直接提供基于源系统结构的简单原貌访问,如审计等。
基础层:也称为核心层,基础模型层,PDM层等等。数据按照主题域进行划分整合后,较长周期地保存详细数据。这一层数据高度整合,是整个数据仓库的核心区域,是所有后面数据层的基础。这一层保存的保存的数据最少13个月,常见的是2~5年。
集市层:先跳到最后一层。集市层的数据模型具备强烈的业务意义,便于业务人员理解和使用,是为了满足部门用户,业务用户,关键管理用户的访问和查询所使用的,而往往对接前段门户的数据查询,报表工具的访问,以及数据挖掘分析工具的探索。
汇总层:汇总层其实并不是一开始就建立起来的。往往是基础层和集市层建立起来后,发现众多的集市层数据进行汇总,统计,加工的时候存在对基础层数据的反复查询和扫描,而不同部门的数据集市的统计算法实际上是有共性的,所以主键的在两层之间,把具有共性的汇总结果形成一个独立的数据层次,承上启下,节省整个系统计算资源。
2.3数据仓库常见ETL算法
虽然数据仓库里面数据模型对于不同行业,不同业务场景有着千差万别,但从本质上从缓冲层到基础层的数据加工就是对于增/全量数据如何能够高效地追加到基础层的数据表中,并形成合理的数据历史变化信息链条;而从基础层到汇总层进而到集市层,则是如何通过关联,汇总,聚合,分组这几种手段进行数据处理。所以长期积累下来,对于数据层次之间的数据转换算法实际上也能形成固定的ETL算法,这也是市面上很多数据仓库代码生成工具能够自动化地智能化地形成无编码方式开发数据仓库ETL脚本的原因所在。这里由于篇幅关系,只简单列举一下缓冲层到基础层常见的几种ETL算法,具体的算法对应的SQL脚本可以找时间另起篇幅详细地介绍。
1.全表覆盖A1
算法说明:删除目标表全部数据,再插入当前数据
来源数据量:全量数据
适用场景:无需保留历史轨迹,只使用最新状态数据
2.更新插入(Upsert)A2
算法说明:本日数据按照主键比对后更新数据,新增的数据采用插入的方式增加数据
来源数据量:增量或全量数据
适用场景:无需保留历史轨迹,只使用最新状态数据
3.历史拉链(Historychain)A3
算法说明:数据按照主键与上日数据进行比对,对更新数据进行当日的关链和当日开链操作,对新增数据增加当日开链的记录
来源数据:增量或全量数据
适用场景:需要保留历史变化轨迹的数据,这部分数据会忽略删除信息,例如客户表、账户表等
4.全量拉链(FullHistorychain)A4
算法说明:本日全量数据与拉链表中上日数据进行全字段比对,比对结果中不存在的数据进行当日关链操作,对更新数据进行当日关链和当日开链操作,对新增数据增加当日开链的记录
来源数据量:全量数据
适用场景:需要保留历史变化轨迹的数据,这部分数据会由数据比对出删除信息进行关链
5.带删除增量拉链(Fx:DeltaHistoryChain)A5
算法说明:本日增量数据根据增量中变更标志对删除数据进行当日关链操作,对更新和新增数据与上日按主键比对后根据需要进行当日关链和当日开链操作,对新增数据增加当日开链的记录
来源数据量:增量数据
适用场景:需要保留历史变化轨迹的数据,这部分数据会根据CHG_CODE来判断删除信息
6.追加算法(Append)A6
算法说明:删除当日/月的增量数据,插入本日/月的增量数据
来源数据量:增量数据
适用场景:流水类或事件类数据三、GaussDB(DWS)和数据仓库
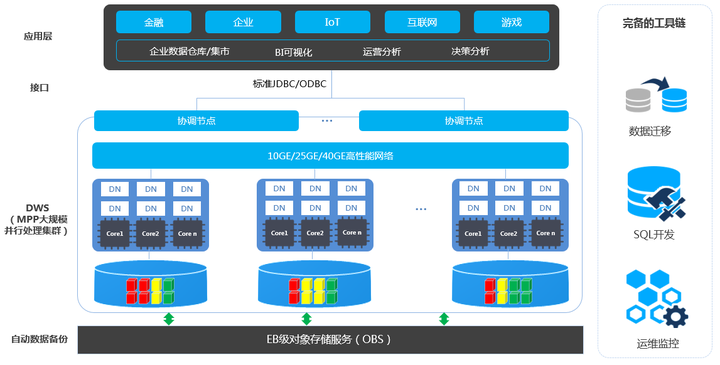
华为的GaussDB(DWS)是一种基于公有云基础架构的分布式MPP数据库。其主要面向海量数据分析场景。MPP数据库是业界实现数据仓库系统最主流的数据库架构,这种架构的主要特点就是Shared-nothing分布式架构,由众多拥有独立且互不共享的CPU、内存、存储等系统资源的逻辑节点(也就是DN节点)组成。
在这样的系统架构中,业务数据被分散存储在多个节点上,SQL被推送到数据所在位置就近执行,并行地完成大规模的数据处理工作,实现对数据处理的快速响应。基于Shared-Nothing无共享分布式架构,也能够保证随着集群规模地扩展,业务处理能力得到线性增长。
技术分享丨数据仓库的建模与ETL实践技巧的更多相关文章
- 数据仓库建模与ETL实践技巧
数据分析系统的总体架构分为四个部分 —— 源系统.数据仓库.多维数据库.客户端(图一:pic1.bmp) 其中,数据仓库(DW)起到了数据大集中的作用.通过数据抽取,把数据从源系统源源不断地抽取出来, ...
- 技术分享丨华为鲲鹏架构Redis知识二三事
摘要:华为云鲲鹏Redis,业界首个基于自研ARM-Based全栈整合的Redis云服务,支持双机热备的HA架构,提供单机.主备.Proxy集群.Cluster集群实例类型,满足高读写性能场景及弹性变 ...
- 技术分享 | app自动化测试(Android)--高级定位技巧
原文链接 XPath高级定位技巧 XPath 简介 XPath 的英文全称为:XML Path Language,意旨对 XML 中的元素进行路径定位的一种语言,它可适用 XML 标记语言,Html ...
- 技术干货丨卷积神经网络之LeNet-5迁移实践案例
摘要:LeNet-5是Yann LeCun在1998年设计的用于手写数字识别的卷积神经网络,当年美国大多数银行就是用它来识别支票上面的手写数字的,它是早期卷积神经网络中最有代表性的实验系统之一.可以说 ...
- PM技术分享——《构建之法》初步实践
软件理论 软件=程序+软件工程:软件开发活动(构建管理.源代码管理.软件设计.软件测试.项目管理)相关的内容的完成,才能完成把整个程序转化成为一个可用的软件的过程. 软件企业=软件+商业模式 软件开发 ...
- [转载]DW数据仓库建模与ETL的实践技巧
一.Data仓库的架构 Data仓库(Data Warehouse DW)是为了便于多维分析和多角度展现而将Data按特定的模式进行存储所建立起来的关系型Datcbase,它的Data基于OLTP源S ...
- 数据仓库建模与ETL的实践
一.Data仓库的架构 Data仓库(Data Warehouse DW)是为了便于多维分析和多角度展现而将Data按特定的模式进行存储所建立起来的关系型Datcbase,它的Data基于OLTP源S ...
- 数据仓库建模与ETL的实践技巧(转载)
一.Data仓库的架构 Data仓库(Data Warehouse DW)是为了便于多维分析和多角度展现而将Data按特定的模式进行存储所建立起来的关系型Datcbase,它的Data基于OLTP源S ...
- 技术分享预告丨k3s在边缘计算中的应用实践
技术分享是在[Rancher官方微信技术交流群]里以图文直播+QA实时互动的方式,邀请国内已落地经验的公司或团队负责人分享生产落地的最佳实践.记得添加微信小助手(微信号:rancher2)入群,实时参 ...
随机推荐
- [jvm] -- 引用篇
四种引用及其应用场景 强引用 强引用是平常中使用最多的引用,强引用在程序内存不足(OOM)的时候也不会被回收. 使用场景:啥时候都在使用 软引用 软引用在程序内存不足时,会被回收. 使用场景:创建缓存 ...
- MySQL数据管理
3.MySQL数据管理 3.1外键 方式一: create table `grade`( `gradeid` int(10) not null auto_increment comment '年纪 ...
- BuuCTF Web Writeup
WarmUp index.php <html lang="en"> <head> <meta charset="UTF-8"> ...
- pandas巩固
导包 import pandas as pd 设置输出结果列对齐 pd.set_option('display.unicode.ambiguous_as_wide',True) pd.set_opti ...
- Django学习路29_css样式渲染 h3 标签
在 static 静态文件夹下创建 css 文件夹 home.css 此时 home.css 路径是 'static/css/home.css' 在 对应的 home.html 文件中添加 css 样 ...
- HTML5 Canvas小游戏基础:用户交互
交互是游戏的根本.缺少了用户交互,游戏就不能称之为游戏,只能说是动画或电影.事件是浏览器响应用户交互操作的一种机制. 1.事件和事件执行 事件定义了用户与页面交互时产生的各种操作(主要通过鼠标或热键的 ...
- Python execfile() 函数
描述 execfile() 函数可以用来执行一个文件.每组词 www.cgewang.com 语法 以下是 execfile() 方法的语法: execfile(filename[, globals[ ...
- Python os.utime() 方法
概述 os.utime() 方法用于设置指定路径文件最后的修改和访问时间.高佣联盟 www.cgewang.com 在Unix,Windows中有效. 语法 utime()方法语法格式如下: os.u ...
- ABPHelper.CLI及其依赖项简单介绍
目录 目录 ABPHelper.CLI 入门 使用指南 命令行 技术点如下 Scriban 通过Microsoft.Extensions.FileProviders.Embedded获取嵌入资源 通过 ...
- luogu P2304 [NOI2015]小园丁与老司机 dp 上下界网络流
LINK:小园丁与老司机 苦心人 天不负 卧薪尝胆 三千越甲可吞吴 AC的刹那 真的是泪目啊 很久以前就写了 当时记得特别清楚 写到肚子疼.. 调到胳膊疼.. ex到根不不想看的程度. 当时wa了 一 ...