支持向量机SVM介绍
SVM为了达到更好的泛化效果,会构建具有"max-margin"的分类器(如下图所示),即最大化所有类里面距离超平面最近的点到超平面的距离,数学公式表示为$$\max\limits_{\vec{w},b}Margin(\vec{w},b)=\max\limits_{\vec{w},b}\min\limits_{i=1,2,\cdots,n}\frac{1}{\lVert{\vec{w}}\rVert_2}y_i(\vec{w}\cdot\vec{x}_i+b),\text{ }y_i\in\{-1,1\}$$
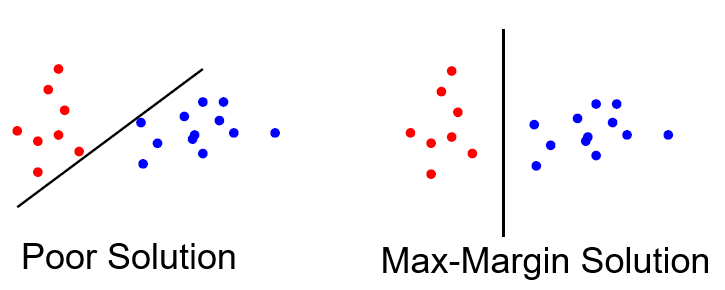
Linear SVM
上述公式可以改写为如下形式$$\min\limits_{\vec{w},b}\frac{1}{2}\lVert{\vec{w}}\rVert_2^2,\text{ subject to } y_i(\vec{w}\cdot\vec{x}_i+b)\geq{1} \text{ for all }i$$
这是一个典型的二次规划问题,并且仅当两个类是线性可分时才有解。可以使用拉格朗日乘数法进行求解,定义$$L(\vec{w},b,\alpha_1,\cdots,\alpha_n)=\frac{1}{2}\lVert{\vec{w}}\rVert_2^2+\sum_{i=1}^n\alpha_i[1-y_i(\vec{w}\cdot\vec{x}_i+b)]$$则SVM的求解问题转换为$\min\limits_{\vec{w},b}[\max\limits_{\alpha_1,\cdots,\alpha_n\geq{0}}L(\vec{w},b,\alpha_1,\cdots,\alpha_n)]$,基于SVM问题的强对偶性,下列等式成立:$$\min\limits_{\vec{w},b}[\max\limits_{\alpha_1,\cdots,\alpha_n\geq{0}}L(\vec{w},b,\alpha_1,\cdots,\alpha_n)]=\max\limits_{\alpha_1,\cdots,\alpha_n\geq{0}}[\min\limits_{\vec{w},b}L(\vec{w},b,\alpha_1,\cdots,\alpha_n)]$$针对上式等号右边的极值问题,首先有$$\frac{\partial{L}}{\partial{\vec{w}}}=0 \Rightarrow \vec{w}=\sum_{i=1}^n\alpha_iy_i\vec{x}_i \text{, }\frac{\partial{L}}{\partial{b}}=0 \Rightarrow \sum_{i=1}^ny_i\alpha_i=0$$将结果带入$L$中可以得到SVM的对偶形式:$$\max\limits_{\alpha_1,\cdots,\alpha_n\geq{0},\sum_{i=1}^ny_i\alpha_i=0}(\sum\limits_{i=1}^n\alpha_i-\frac{1}{2}\sum\limits_{i=1}^n\sum\limits_{j=1}^n\alpha_i\alpha_jy_iy_j\vec{x}_i\cdot\vec{x}_j)$$针对$b$的求解,可以利用KKT条件:$\alpha_i[1-y_i(\vec{w}\cdot\vec{x}_i+b)]=0\text{ for }i=1,2,\cdots,n$,即取任一不为0的$\alpha_i$,令$1-y_i(\vec{w}\cdot\vec{x}_i+b)=0$
最终求得的分类器为$g_{svm}(\vec{x})=sign(\vec{w}\cdot\vec{x}+b)\text{, with }\vec{w}=\sum_{i=1}^n\alpha_iy_i\vec{x}_i$
Kernel SVM
上述的Linear SVM为线性分类器,因此引入核的概念扩展原始数据的维数,使其可以在原始数据空间上变为非线性分类器。核函数的优点是相比于直接进行特征映射可以很大程度上减少计算量,并且维数的扩展形式更加灵活,具体做法是将Linear SVM的对偶形式中两个数据向量的相乘变为核函数的形式,即$$\max\limits_{\alpha_1,\cdots,\alpha_n\geq{0},\sum_{i=1}^ny_i\alpha_i=0}[\sum\limits_{i=1}^n\alpha_i-\frac{1}{2}\sum\limits_{i=1}^n\sum\limits_{j=1}^n\alpha_i\alpha_jy_iy_jK(\vec{x}_i,\vec{x}_j)]$$核函数$K$需要满足以下性质:定义核函数矩阵$K$($K$中的元素$K_{ij}=K(\vec{x}_i,\vec{x}_j)$),则矩阵$K$需为半正定对称矩阵。常用的核函数主要有以下两种:
- 多项式核函数$K(\vec{x}_i,\vec{x}_j)=(r\vec{x}_i\cdot\vec{x}_j+\epsilon)^d\text{, with }r>0,d\text{ is positive integer},\epsilon\geq{0}$
- 高斯核函数$K(\vec{x}_i,\vec{x}_j)=e^{-\gamma\lVert\vec{x}_i-\vec{x}_j\rVert_2^2}\text{, with }\gamma>0$
针对$b$的求解,仍利用KKT条件,取任一不为0的$\alpha_i$,令$1-y_i(\sum_{k=1}^n\alpha_ky_kK(\vec{x}_k,\vec{x}_i)+b)=0$
最终求得的分类器为$g_{svm}(\vec{x})=sign(\sum_{i=1}^n\alpha_iy_iK(\vec{x}_i,\vec{x})+b)$
Soft-Margin SVM
Linear SVM仅当数据为线性可分时才有解,这就使得其实际应用有很大的限制,因此对它的原始公式进行一定程度的改进,使其对错误分类有一定程度的容忍度,具体公式如下:$$\min\limits_{\vec{w},b}(\frac{1}{2}\lVert{\vec{w}}\rVert_2^2+C\sum\limits_{i=1}^n\epsilon_i),\text{ subject to } y_i(\vec{w}\cdot\vec{x}_i+b)\geq{1-\epsilon_i},\epsilon_i\geq{0} \text{ for all }i$$上式中的C越小,对错误分类的容忍度就越高;当C趋于无穷大时就变为了Linear SVM的形式。仍使用拉格朗日乘数法以及SVM的强对偶性质,定义$$L(\vec{w},b,\epsilon_i,\alpha_i,\mu_i)=\frac{1}{2}\lVert{\vec{w}}\rVert_2^2+C\sum\limits_{i=1}^n\epsilon_i+\sum_{i=1}^n\alpha_i[1-\epsilon_i-y_i(\vec{w}\cdot\vec{x}_i+b)]-\sum\limits_{i=1}^n\mu_i\epsilon_i$$上式可变为求解$$\min\limits_{\vec{w},b,\epsilon_i}[\max\limits_{\alpha_i,\mu_i\geq{0}}L(\vec{w},b,\epsilon_i,\alpha_i,\mu_i)]=\max\limits_{\alpha_i,\mu_i\geq{0}}[\min\limits_{\vec{w},b,\epsilon_i}L(\vec{w},b,\epsilon_i,\alpha_i,\mu_i)]$$同样令$\frac{\partial{L}}{\partial{\vec{w}}}=\frac{\partial{L}}{\partial{b}}=\frac{\partial{L}}{\partial{\epsilon_i}}=0$,则对偶问题可写为$$\max\limits_{0\leq\alpha_i\leq{C},\sum_{i=1}^ny_i\alpha_i=0}(\sum\limits_{i=1}^n\alpha_i-\frac{1}{2}\sum\limits_{i=1}^n\sum\limits_{j=1}^n\alpha_i\alpha_jy_iy_j\vec{x}_i\cdot\vec{x}_j)$$同样可以将$\vec{x}_i\cdot\vec{x}_j$替换为$K(\vec{x}_i,\vec{x}_j)$,在分类器中引入核函数,上述对偶问题的KKT条件为:$$\begin{cases} \alpha_i=0:\text{ the point away from the margin boundary with }\epsilon_i=0 \\ 0<\alpha_i<C:\text{ the point on the margin boundary with }\epsilon_i=0\text{ and }1-y_i(\sum_{k=1}^n\alpha_ky_kK(\vec{x}_k,\vec{x}_i)+b)=0 \\ \alpha_i=C:\text{ the point violate the margin boundary with }\epsilon_i>0(\text{the violate amount}) \end{cases}$$
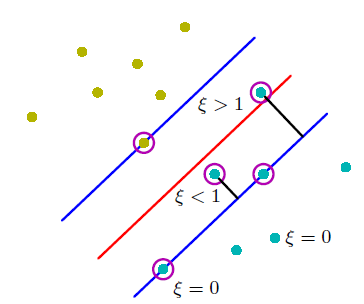
最终求得的分类器为$g_{svm}(\vec{x})=sign(\sum_{i=1}^n\alpha_iy_iK(\vec{x}_i,\vec{x})+b)$
Unconstraint Soft-Margin and SVR
Soft-Margin SVM还可以改写成以下形式:$$\min\limits_{\vec{w},b}[\underbrace{\frac{1}{2C}\lVert{\vec{w}}\rVert_2^2}_\text{Regularization Term}+\sum\limits_{i=1}^n\underbrace{\max(1-y_i(\vec{w}\cdot\vec{x}_i+b),0)}_\text{Loss Function}]$$若在训练中对每个样本分配不同的权重,则上式变为$$\min\limits_{\vec{w},b}[\frac{1}{2C}\lVert{\vec{w}}\rVert_2^2+\sum\limits_{i=1}^ns_i\max(1-y_i(\vec{w}\cdot\vec{x}_i+b),0)]$$求解过程与不加权重的Soft-Margin SVM是一致的,只不过需要将$0\leq\alpha_i\leq{C}$变为$0\leq\alpha_i\leq{Cs_i}$
受上述形式的启发,支持向量机也可用于回归问题(SVR),定义$\epsilon\text{-insensitive loss function }err(y,\hat{y})=\max(\lvert{y-\hat{y}}\rvert-\epsilon,0)$,则SVR为L2正则化的回归问题:$$\min\limits_{\vec{w},b}[\sum\limits_{i=1}^nerr(y_i,\hat{y}_i)+\frac{1}{2C}\lVert{\vec{w}}\rVert_2^2]=\min\limits_{\vec{w},b}[\sum\limits_{i=1}^n\max(\lvert{y_i-(\vec{w}\cdot\vec{x}_i+b)}\rvert-\epsilon,0)+\frac{1}{2C}\lVert{\vec{w}}\rVert_2^2]$$具体求解思路和Soft-Margin SVM基本相同,这里就不再详细叙述了。
支持向量机SVM介绍的更多相关文章
- OpenCV支持向量机(SVM)介绍
支持向量机(SVM)介绍 目标 本文档尝试解答如下问题: 如何使用OpenCV函数 CvSVM::train 训练一个SVM分类器, 以及用 CvSVM::predict 测试训练结果. 什么是支持向 ...
- OpenCV支持向量机SVM对线性不可分数据的处理
支持向量机对线性不可分数据的处理 目标 本文档尝试解答如下问题: 在训练数据线性不可分时,如何定义此情形下支持向量机的最优化问题. 如何设置 CvSVMParams 中的参数来解决此类问题. 动机 为 ...
- 机器学习:Python中如何使用支持向量机(SVM)算法
(简单介绍一下支持向量机,详细介绍尤其是算法过程可以查阅其他资) 在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别.分类(异 ...
- 以图像分割为例浅谈支持向量机(SVM)
1. 什么是支持向量机? 在机器学习中,分类问题是一种非常常见也非常重要的问题.常见的分类方法有决策树.聚类方法.贝叶斯分类等等.举一个常见的分类的例子.如下图1所示,在平面直角坐标系中,有一些点 ...
- 一步步教你轻松学支持向量机SVM算法之案例篇2
一步步教你轻松学支持向量机SVM算法之案例篇2 (白宁超 2018年10月22日10:09:07) 摘要:支持向量机即SVM(Support Vector Machine) ,是一种监督学习算法,属于 ...
- 支持向量机SVM 参数选择
http://ju.outofmemory.cn/entry/119152 http://www.cnblogs.com/zhizhan/p/4412343.html 支持向量机SVM是从线性可分情况 ...
- 大数据-10-Spark入门之支持向量机SVM分类器
简介 支持向量机SVM是一种二分类模型.它的基本模型是定义在特征空间上的间隔最大的线性分类器.支持向量机学习方法包含3种模型:线性可分支持向量机.线性支持向量机及非线性支持向量机.当训练数据线性可分时 ...
- [转] 从零推导支持向量机 (SVM)
原文连接 - https://zhuanlan.zhihu.com/p/31652569 摘要 支持向量机 (SVM) 是一个非常经典且高效的分类模型.但是,支持向量机中涉及许多复杂的数学推导,并需要 ...
- 线性可分支持向量机--SVM(1)
线性可分支持向量机--SVM (1) 给定线性可分的数据集 假设输入空间(特征向量)为,输出空间为. 输入 表示实例的特征向量,对应于输入空间的点: 输出 表示示例的类别. 线性可分支持向量机的定义: ...
随机推荐
- c# Winfrom-DataGridView实现筛选功能
//应对用户需求,需要在DataGridView中直接进行筛选功能,在网上找了一些代码加上自己修改整理过后的类,仅供参考! //上面代码可以直接创建类库项目生成DLL文件,下面代码为另外项目引用创 ...
- threadLocal源码土话解说
前言 废话不多说,先了解什么是threadLocal,下面是threadLocal类的说明注释, 这段话大致(猜的)意思是,改类为线程提供了一个局部变量,但是呢,这个变量和普通的变量又有所不同,怎么不 ...
- p44_IP数据包格式
一.IP数据报格式 二.IP分片 数据链路层每帧可封装数据有上限,IP数据超过的要分片. 标识:同一数据报的分片使用同一标识 标志: 片偏移(13bit):用于还原数据报顺序,指出某片在原分组1中的相 ...
- 题解 CF785E 【Anton and Permutation】
考虑用分块解决这个题,一次交换对当前逆序对个数的影响是,加上两倍的在区间\([l+1,r-1]\)中比\(a_r\)小的元素个数,减去两倍的在区间\([l+1,r-1]\)中比\(a_l\)小的元素个 ...
- 题解 洛谷 P3247 【[HNOI2016]最小公倍数】
题意可以转化为是否能找一条从\(u\)到\(v\)的路径,经过的边的\(a\)和\(b\)的最大值恰好都是询问所给定的值. 若只有\(a\)的限制,可以将询问离线,对边和询问都从小到大排序,然后双指针 ...
- JDBC 连接 MySQL 8.0.15+ 常见错误记录
课后复习 1. No suitable driver found for mysql:jdbc://localhost:3306/test 错误原因: mysql:jdbc://localhost:3 ...
- 图论相关知识(DFS、BFS、拓扑排序、最小代价生成树、最短路径)
图的存储 假设是n点m边的图: 邻接矩阵:很简单,但是遍历图的时间复杂度和空间复杂度都为n^2,不适合数据量大的情况 邻接表:略微复杂一丢丢,空间复杂度n+m,遍历图的时间复杂度为m,适用情况更广 前 ...
- Statezhong shiyong redux props
在构造方法中使用props给state赋值不允许, 原因需要检查
- 2. 妈呀,Jackson原来是这样写JSON的
没有人永远18岁,但永远有人18岁.本文已被 https://www.yourbatman.cn 收录,里面一并有Spring技术栈.MyBatis.JVM.中间件等小而美的专栏供以免费学习.关注公众 ...
- 【论文笔记】Self-Supervised GAN :辅助性旋转损失的自监督生成式对抗网络
这是CVPR2019上UCLA和google brain的一个工作.模型非常简单,利用辅助损失解决GAN不稳定问题:用旋转分类将辅助分类器对label的需求去掉,使图片可以直接对自己标注类别. Sel ...