Kafka基本原理概述
Kafka的基本介绍
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志、消息服务等等。
主要应用场景:日志收集系统和消息系统。
主要设计目标:
1、以时间复杂度O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
2、高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
3、支持kafka server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
4、同时支持离线数据处理和实时数据处理。
kafka设计原理分析
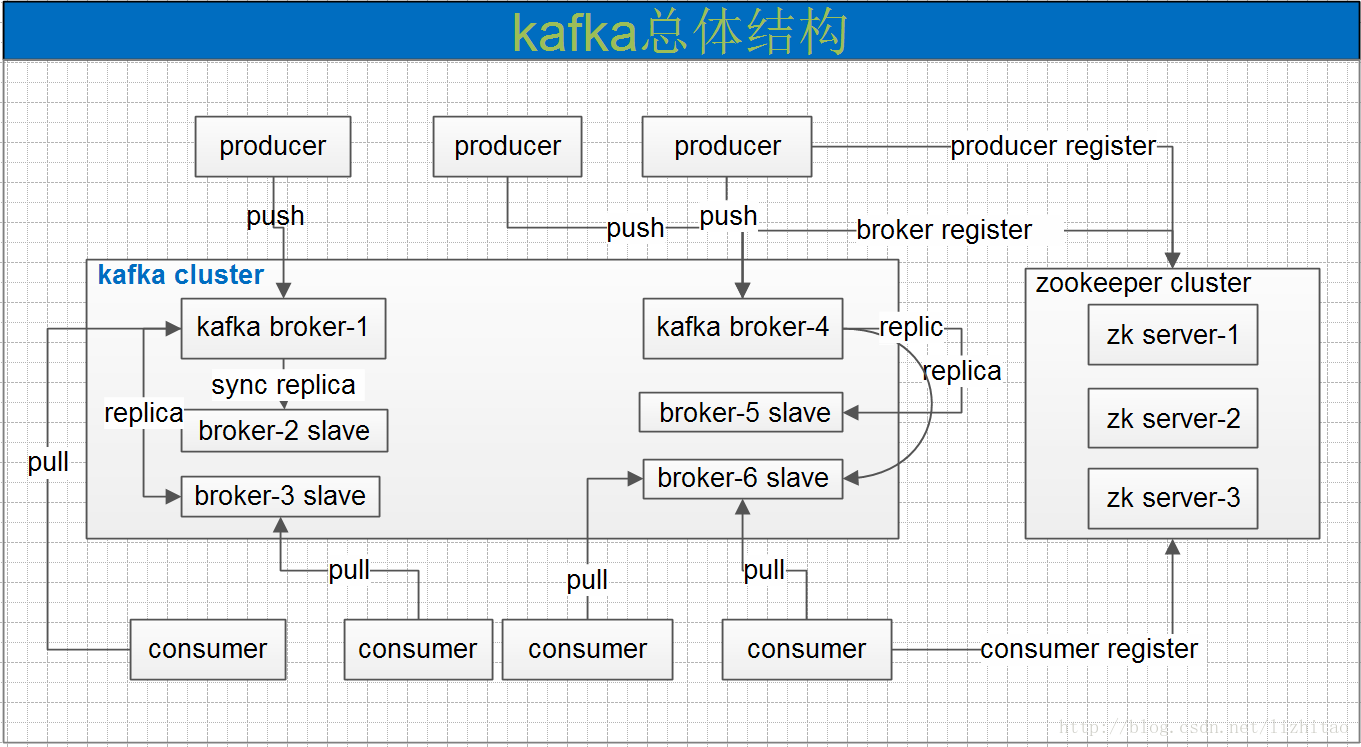
一个典型的kafka集群中包含若干producer,若干broker,若干consumer,以及一个zookeeper集群。kafka通过zookeeper管理集群配置,选举leader,以及在消费组发送变化时进行rebalance。producer使用push模式将消息发布到broker,consumer使用pull模式从broker订阅并消费消息。
kafka专用术语:
1、broker:消息中间件处理结点,一个kafka节点就是一个broker,多个broker可以组成一个kafka集群。
2、Topic:一类消息,kafka集群能够同时负责多个topic的分发。
3、partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。
4、Segment:partition物理上由多个segment组成。
5、offset:每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息。
6、Producer:负责发布消息到Kafka broker。
7、Consumer:消息消费者,向Kafka broker读取消息的客户端。
8、Consumer Group:每个Consumer属于一个特定的Consumer Group。
kafka消息存储格式
Topic & Partition
一个topic可以任务一个一类消息,每个topic将被分成多个partition,每个partition在存储层面是append log文件。
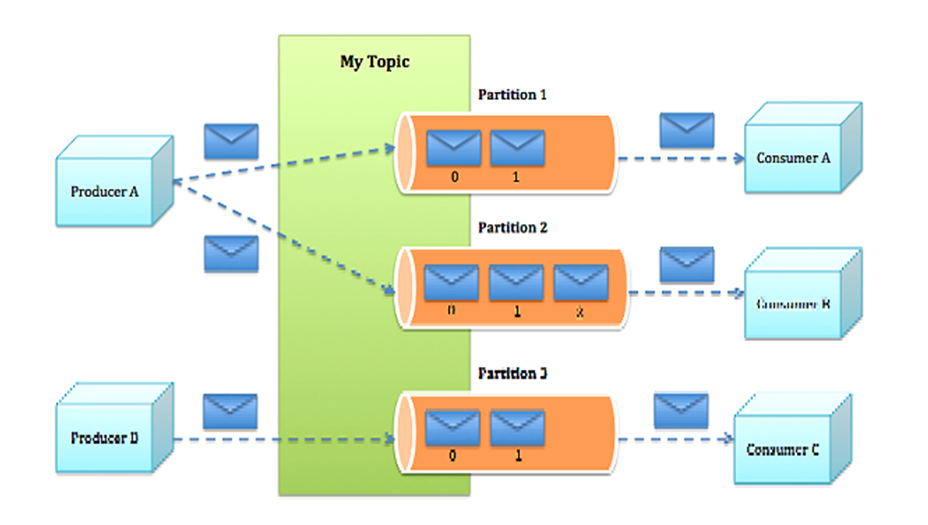
在kafka文件存储中,同一个topic下有多个不同partition,每个partition为一个目录,partition命名规则为:topic名称+有序序号,第一个partition序号从0开始,序号最大值为partition数量减1.
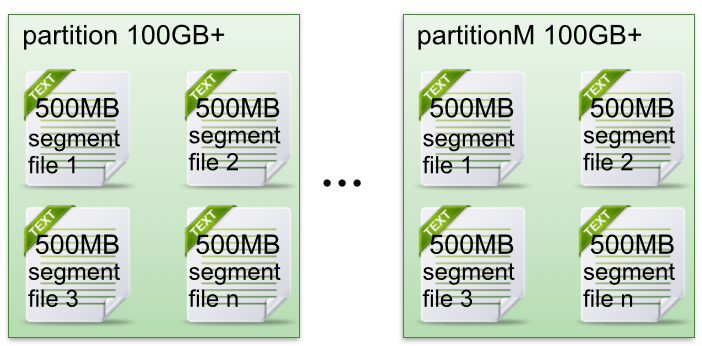
1、每个partitin(目录)相当于一个巨型文件被平均分配到多个segment(段)数据文件中。但每个段segment file消息数量不一定相等,这种特性方便old segment file快速被删除。
2、每个partition只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定。
上面两点这样做的好处就是能快速删除无用文件,有效提高磁盘利用率。
3、segment file组成:由2大部分组成,分别为index file和data file,此2个文件一一对应,成对出现,后缀".index"和“.log”分别表示为segment索引文件、数据文件.
4、segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。

segment中index与data file对应关系物理结构如下:

上图中索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中message的物理偏移地址。
其中以索引文件中元数据3,497为例,依次在数据文件中表示第3个message(在全局partiton表示第368772个message),以及该消息的物理偏移地址为497。
副本(Replication)策略
kafka的高可靠性的保障来源于其健壮的副本(replication)策略。
1、数据同步
kafka在0.8版本前没有提供Partition的Replication机制,一旦Broker宕机,其上的所有Partition就都无法提供服务,而Partition又没有备份数据,数据的可用性就大大降低了。所以0.8后提供了Replication机制来保证Broker的failover(故障转移)。
引入Replication之后,同一个Partition可能会有多个Replica,而这时需要在这些Replication之间选出一个Leader,Producer和Consumer只与这个Leader交互,其它Replica作为Follower从Leader中复制数据。

2、副本放置策略:
为了更好的做负载均衡,kafka尽量将所有的partition均匀分配到整个集群上。
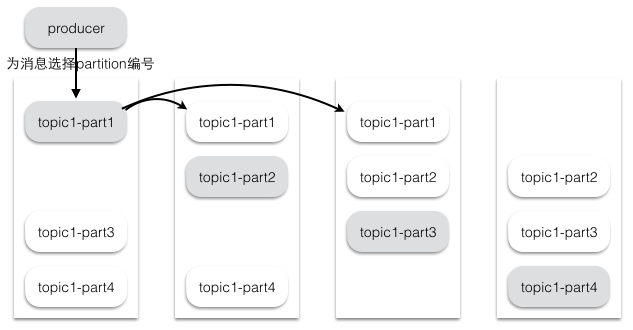
kafka分配Replica的算法如下:
a、将所有存活的N个Brokers和待分配的Partition排序。
b、将第i个partition分配到第(i mod n)个Broker上,这个Partition的第一个Replica存在于这个分配的Broker上,并且会作为partition的优先副本
c、将第i个Partition的第j个Replica分配到第((i + j) mod n)个Broker上
假设集群一共有4个brokers,一个topic有4个partition,每个Partition有3个副本。下图是每个Broker上的副本分配情况。
3、同步策略
Producer在发布消息到某个Partition时,先通过Zookeeper找到该Partition的Leader,然后无论该Topic的Replication Factor为多少,Producer只将该消息发送到该Partition的Leader。Leader会将该消息写入其本地log。每个Fllower都从Leader pull数据。这种方式上,Follower存储的数据顺序与Leader保持一致。Follower在收到该消息并写入其LOG后,向Leader发送ACK。一旦Leader收到了ISR中的所有Replica的ACK,该消息就被认为已经commit了,Leader将增加HW并且向Producer发送ACK。
为了提高性能,每个Follower在接收到数据后就立马向Leader发送ACK,而非等到数据写入Log中。因此,对于已经commit的消息,Kafka只能保证它被存于多个Replica的内存中,而不能保证它们被持久化到磁盘中,也就不能完全保证异常发生后该条消息一定能被Consumer消费。
Consumer读消息也是从Leader读取,只有被commit过的消息才会暴露给Consumer。
Kafka Replication的数据流如下图所示:
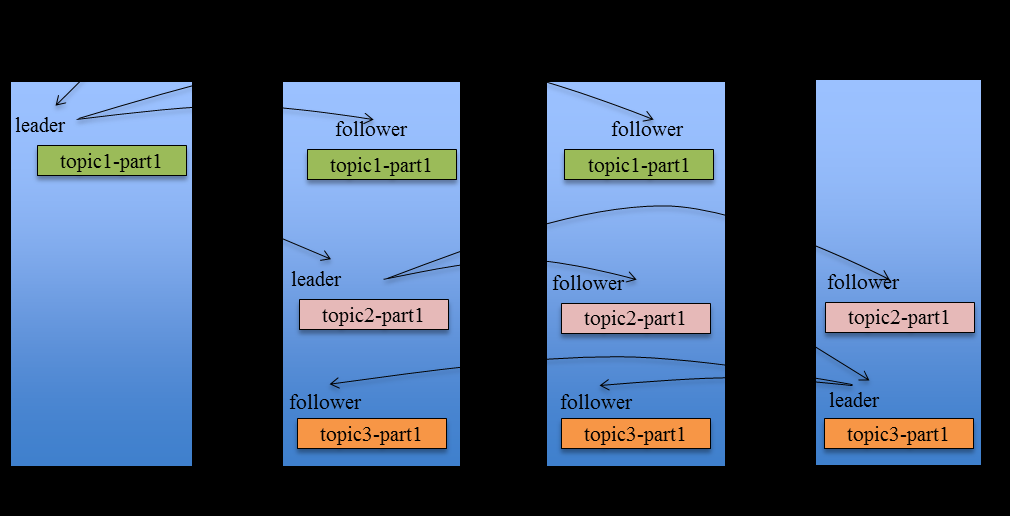
对于kafka而言,定义一个Broker是否“活着”包含两个条件:
1、一是它必须维护与Zookeeper的session(这个可以通过ookeeper的心跳机制来实现)
2、二是Follower必须能够及时将Leader的消息复制过来,不能“落户太多”
Leader会跟踪与其保持同步的Replica列表,该列表称为ISR(即in-sync Replica)。如果一个Follower宕机,或者落后太多,Leader将把它从ISR中移除。这里所描述的“落后太多”指Follower复制的消息落后于Leader后的条数超过预定值或者Follower超过一定时间未向Leader发送fetch请求。
Kafka只解决fail/recover,一条消息只有被ISR里的所有Follower都从Leader复制过去才会被认为已提交。这样就避免了部分数据被写进了Leader,还没来得及被任何Follower复制就宕机了,而造成数据丢失(Consumer无法消费这些数据)。而对于Producer而言,它可以选择是否等待消息commit。这种机制确保了只要ISR有一个或以上的Follower,一条被commit的消息就不会丢失。
4、Leader选举
Leader选举本质上是一个分布式锁,有两种方式实现基于ZooKeeper的分布式锁:
a、节点名称唯一性:多个客户端创建一个节点,只有成功创建节点的客户端才能获得锁
b、临时顺序节点:所有客户端在某个目录下创建自己的临时顺序节点,只有序号最小的才获得锁
kafka消息分组,消息消费原理
同一Topic的一条消息只能被同一个Consumer Group内的一个Consumer消费,但多个Consumer Group可同时消费这一消息。
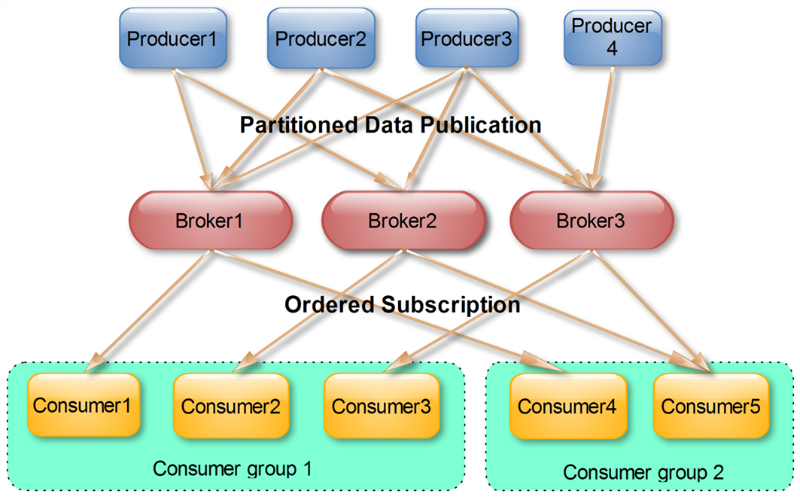
这是Kafka用来实现一个Topic消息的广播(发给所有的Consumer)和单播(发给某一个Consumer)的手段。一个Topic可以对应多个Consumer Group。如果需要实现广播,只要每个Consumer有一个独立的Group就可以了。要实现单播只要所有的Consumer在同一个Group里。用Consumer Group还可以将Consumer进行自由的分组而不需要多次发送消息到不同的Topic。
Push vs Pull
作为一个消息系统,Kafka遵循了传统的方式,选择由Producer向broker push消息并由Consumer从broker pull消息。
push模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。push模式的目标是尽可能以最快速度传递消息,但是这样很容易造成Consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据Consumer的消费能力以适当的速率消费消息。
对于Kafka而言,pull模式更合适。pull模式可简化broker的设计,Consumer可自主控制消费消息的速率,同时Consumer可以自己控制消费方式——即可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的传输语义。
Kafka顺序写入与数据读取
生产者(producer)是负责向Kafka提交数据的,Kafka会把收到的消息都写入到硬盘中,它绝对不会丢失数据。为了优化写入速度Kafak采用了两个技术,顺序写入和MMFile(文件管理系统)。
顺序写入
因为硬盘是机械结构,每次读写都会寻址,写入,其中寻址是一个“机械动作”,它是最耗时的。所以硬盘最“讨厌”随机I/O,最喜欢顺序I/O。为了提高读写硬盘的速度,Kafka就是使用顺序I/O。
每条消息都被append到该Partition中,属于顺序写磁盘,因此效率非常高。

对于传统的message queue而言,一般会删除已经被消费的消息,而Kafka是不会删除数据的,它会把所有的数据都保留下来,每个消费者(Consumer)对每个Topic都有一个offset用来表示读取到了第几条数据。

即便是顺序写入硬盘,硬盘的访问速度还是不可能追上内存。所以Kafka的数据并不是实时的写入硬盘,它充分利用了现代操作系统分页存储来利用内存提高I/O效率。
在Linux Kernal 2.2之后出现了一种叫做“零拷贝(zero-copy)”系统调用机制,就是跳过“用户缓冲区”的拷贝,建立一个磁盘空间和内存空间的直接映射,数据不再复制到“用户态缓冲区”系统上下文切换减少2次,可以提升一倍性能。
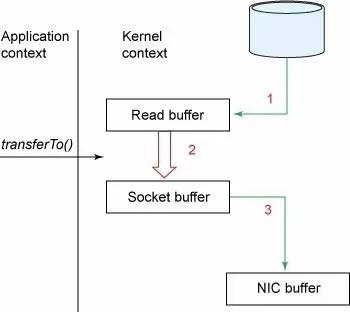
通过mmap,进程像读写硬盘一样读写内存(当然是虚拟机内存)。使用这种方式可以获取很大的I/O提升,省去了用户空间到内核空间复制的开销(调用文件的read会把数据先放到内核空间的内存中,然后再复制到用户空间的内存中。)
消费者(读取数据)
试想一下,一个Web Server传送一个静态文件,如何优化?答案是zero copy。传统模式下我们从硬盘读取一个文件是这样的。
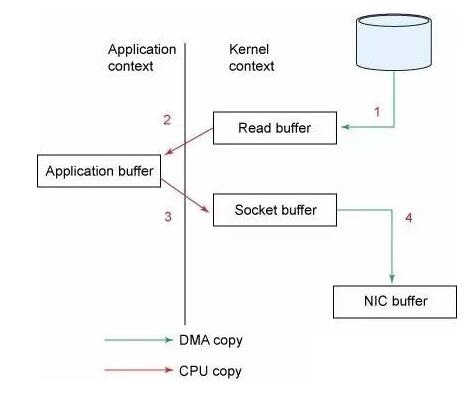
先复制到内核空间(read是系统调用,放到了DMA,所以用内核空间),然后复制到用户空间(1、2);从用户空间重新复制到内核空间(你用的socket是系统调用,所以它也有自己的内核空间),最后发送给网卡(3、4)。
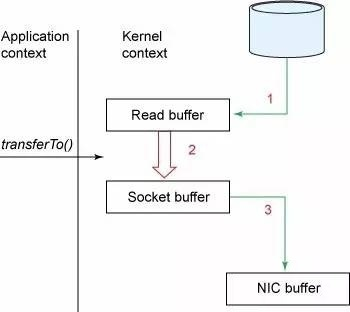
Zero Copy中直接从内核空间(DMA的)到内核空间(Socket的),然后发送网卡。这个技术非常普遍,Nginx也是用的这种技术。
实际上,Kafka把所有的消息都存放在一个一个的文件中,当消费者需要数据的时候Kafka直接把“文件”发送给消费者。当不需要把整个文件发出去的时候,Kafka通过调用Zero Copy的sendfile这个函数,这个函数包括:
out_fd作为输出(一般及时socket的句柄)
in_fd作为输入文件句柄
off_t表示in_fd的偏移(从哪里开始读取)
size_t表示读取多少个
转自:http://www.linkedkeeper.com/detail/blog.action?bid=1016
Kafka基本原理概述的更多相关文章
- kafka基本原理概述——patition与replication分配
kafka一直在大数据中承受着数据的压力也扮演着对数据维护转换的角色,下面重点介绍kafka大致组成及其partition副本的分配原则: 文章参考:http://www.linkedkeeper.c ...
- Kafka 基本原理
Kafka 基本原理 来源:阿凡卢 , www.cnblogs.com/luxiaoxun/p/5492646.html 简介 Apache Kafka是分布式发布-订阅消息系统.它最初由Link ...
- NAT64与DNS64基本原理概述
NAT64与DNS64基本原理概述 1.NAT64与DNS64背景 在IPv6网络的发展过程中,面临最大的问题应该是IPv6与IPv4的不兼容性,因此无法实现二种不兼容网络之间的互访.为了实现 ...
- Docker基本原理概述
Docker基本原理概述 Docker是一个用于开发,交付和运行应用程序的开放平台.Docker能够将应用程序与基础架构分开,从而可以快速交付软件.借助Docker,可以以与管理应用程序相同的方式来管 ...
- Kafka之概述
Kafka之概述 一.消息队列内部实现原理 (1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除) 点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消 ...
- Kafka基本原理
简介 Apache Kafka是分布式发布-订阅消息系统.它最初由LinkedIn公司开发,之后成为Apache项目的一部分.Kafka是一种快速.可扩展的.设计内在就是分布式的,分区的和可复制的提交 ...
- kafka模块概述
简介 kafka主要用于实现低延迟的发送和收集大量的事件和日志数据--通常是活跃的数据(PV.访问记录等),数据以日志形式记录下来,然后由一个专门的系统来进行日志的收集与统计: 吞吐量极高的分布式消息 ...
- kafka基本原理学习
下载安装地址:http://kafka.apache.org/downloads.html 原文链接:http://www.jasongj.com/2015/01/02/Kafka深度解析 Kafk ...
- Kafka(2)--kafka基本原理之消息的分发与接收
关于 Topic 和 Partition Topic 在 kafka 中,topic 是一个存储消息的逻辑概念,可以认为是一个消息集合.每条消息发送到 kafka 集群的消息都有一个类别.物理上来说, ...
随机推荐
- PyQt(Python+Qt)学习随笔:QListWidget获取当前选中项的selectedItems方法
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 QListWidget的selectedItems方法返回列表部件中所有选中项的一个列表,调用语法如 ...
- 如何利用Excel快速批量生成想要的代码
如何利用Excel快速批量生成想要的代码 使用场景 在HTML DOM Video 对象这个页面 我想要将所有的中文描述和对应的属性(共32个属性)打印出来--console.log(descript ...
- pytorch Dataset Dataloader用法(一个示例)
from torch.utils.data import Dataset from torch.utils.data import DataLoader from torch.utils.data i ...
- Codeforces Edu Round 48 A-D
A. Death Note 简单模拟,可用\(\%\)和 \(/\)来减少代码量 #include <iostream> #include <cstdio> using nam ...
- 数据结构—— Trie (前缀树)
实现一个 Trie (前缀树),包含 插入, 查询, 和 查询前缀这三个操作. Trie trie = new Trie(); trie.insert("apple"); trie ...
- docker 添加Portainer容器图形化管理工具
主要参照了这边博客,但还是有些问题https://www.cnblogs.com/Bug-Hunter/p/12023130.html 比如端口9000得开启,docker端口映射得开启,得开启ip4 ...
- Hive JDBC执行load时无法从本地加载数据
通过hive-jdcv连接hive server,在应用服务端执行以下命令,报错:Hiver Server节点上找不到data.txt load data local inpath '/home/dw ...
- [日常摸鱼]bzoj1968 [Ahoi2005]COMMON 约数研究
题意:记$f(n)$为$n$的约数个数,求$\sum_{i=1}^n f(i)$,$n \leq 10^6$. 我也不知道为什么我要来做这个- 直接枚举每个数会是哪些数的约数-复杂度$O(n log ...
- Eureka系列(二) 服务注册Server端具体实现
服务注册 Server端流程 我们先看下面这张图片,这张图片简单描述了下我们EurekaClient 在调用EurekaServer 提供的服务注册Http接口,Server端实现接口执行的大致流 ...
- js--数组的filter()过滤方法的使用
前言 你还在通过for循环遍历数组吗?你还在遍历之后一项一项的通过if判断过滤你需要的数据吗?你还在写着一大堆代码实现一个简单的过滤数据功能吗?那么,今天他来了.他就是这里要介绍的es6中数组filt ...