虚拟机Ubuntu(18.04.2)下安装配置Hadoop(2.9.2)(伪分布式+Java8)
【本文结构】
- 【1】安装Hadoop前的准备工作
- 【1.1】 创建新用户
- 【1.2】 更新APT
- 【1.3】 安装SSH
- 【1.4】 安装Java环境
- 【2】安装和配置hadoop
- 【2.1】 Hadoop下载
- 【2.2】 Hadoop伪分布式配置
【踩过的坑】
- 【1】 需要在Java8上安装Hadoop,开始用Java11一直失败;
- 【2】 一定要再熟悉大致流程后再安装,专注于一篇笔记的同时参考其他笔记。
- 【3】 本文参考笔记
【所需下载的文件】
- 【1】 JDK–Java8环境
- 【2】 Apache Hadoop2.9.2
【其他知识点】
【1】 查看本机ip
sudo apt install net-tools
ifconfig # 查看虚拟机Ip【2】 VIM命令
vi filename # 进入文件
insert键 # 编辑文本
esc键 # 退出编辑
:wq # 退出并保存
ctrl+s # 锁屏
ctrl+q # 解锁
fi # 文件结尾标识
【1】安装hadoop前的准备
- 【1.1】 创建Hadoop用户
为了方便以后的实验进行,推荐创建一个新的Hadoop用户,所有的实验内容都登录该用户进行,具体的shell代码和注释如下:
$ sudo useradd -m hadoop -s /bin/bash # 创建hadoop用户,并使用/bin/bash 作为shell
$ sudo passwd hadoop # 为hadoop用户设置密码,之后需要连续输入两次密码
$ sudo adduser hadoop sudo # 为hadoop用户添加管理员权限
$ su - hadoop # 切换当前用户为hadoop
- 【1.2】更新apt
APT是一款软件管理工具,Linux采用APT来安装和管理各种软件,安装成功Linux系统以后,需要及时更新APT软件,否则后序的一些软件可能无法正常安装,更新APT使用以下命令:
$ sudo apt-get update # 更新hadoop用户的apt,方便后面的安装
- 【1.3】安装SSH,设置SSH无密码登录
SSH是Secure Shell的缩写,
为什么安装hadoop之前需要配置SSH呢? 这是因为Hadoop名称节点(NameNode) 需要启动集群中所有机器的Hadoop守护进程,这个过程需要通过SSH登录来实现。Hadoop并没有提供SSH输入密码登录的形式,因此,为了能够顺利登录集群中的每台机器,需要将所有机器配置为“名称节点可以无密码登录它们”
Ubuntu默认已安装SSH客户端,故只需要安装SSH服务器,在终端执行以下命令:
$ sudo apt-get install openssh-server # 安装ssh服务器
然后可以使用如下命令登录本机(因为是伪分布式集群,只有一台机器,同时作为名称节点和普通节点),如果提示输入密码,则表示安装成功了。
$ ssh localhost # 登录ssh,第一次登录输入yes 或者让输入密码直接两次回车
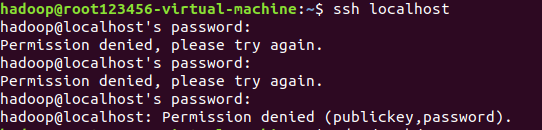
由于这样登录需要每次输入密码,所以,需要配置SSH为无密码登录,这样在hadoop集群中,名称节点要登录某台机器就不需要人工输入密码了。
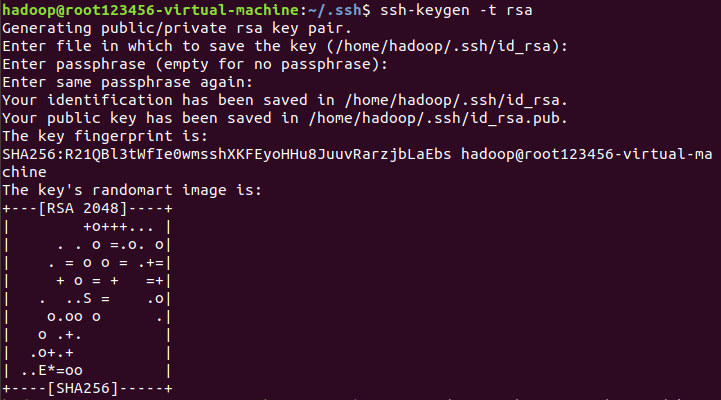
$ cd ~/.ssh # 切换目录
$ ssh-keygen -t rsa # 会有提示,按enter即可(即不设置密码),这条语句生成公钥和私钥两个文件
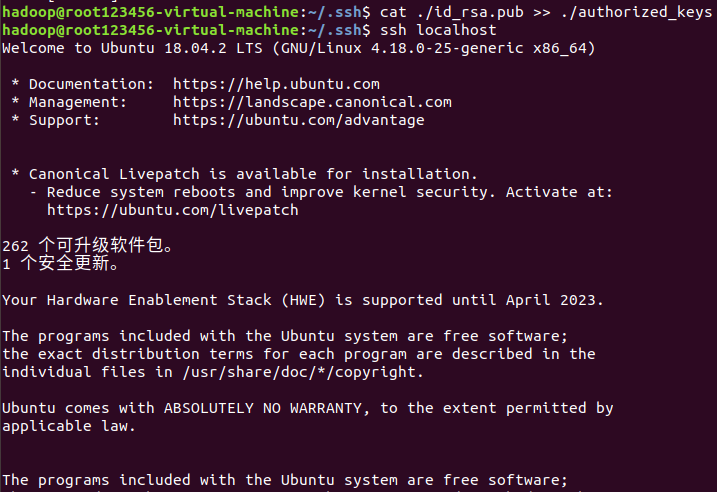
$ cat ./id_rsa.pub >> ./authorized_keys # 加入授权,cat file1 >> file2 的含义是将file1的内容写到file2尾部
$ ssh localhost # 此次再登录ssh,无需输入密码即可。
- 【1.4安装Java环境】
Hadoop是基于Java环境开发的,同时Java语言也可以用来编写Hadoop应用程序,在Linux系统中安装Java环境有两种方式:Oracle的JDK和openJdk,本文采用第一种:
首先在Oracle官网下载JDK1.8,接下来安装并配置。这里选择的是(jdk-8u211-linux-x64.tar.gz)
注意是usr !!! 不是user
$ mkdir /usr/lib/jvm # 创建jvm文件夹
# 解压到/usr/lib/jvm目录下(因为压缩包在在桌面放着)
$ sudo tar zxvf /home/root123456/桌面/jdk-8u211-linux-x64.tar.gz -C /usr/lib/jvm
$ cd usr/lib/jvm # 进入usr/lib/jvm目录
$ mv jdk1.8.0_211 java # 将jdk1.8.0_211重命名为java 此步可能权限不够,在其前加上sudo

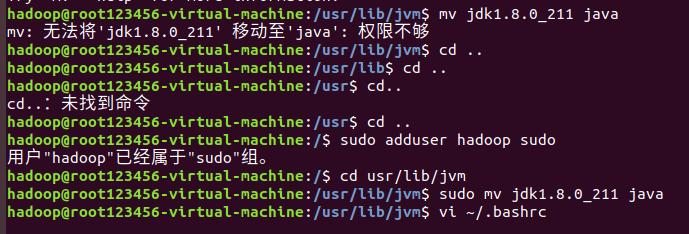
$ vi ~/.bashrc # 给JDK配置环境变量
编辑.bashrc文件,添加如下指令:
export JAVA_HOME=/usr/lib/jvm/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
文件修改完毕后,输入以下代码:
$ source ~/.bashrc # 使新配置的环境变量生效
$ java -version # 检测是否安装成功,查看java版本
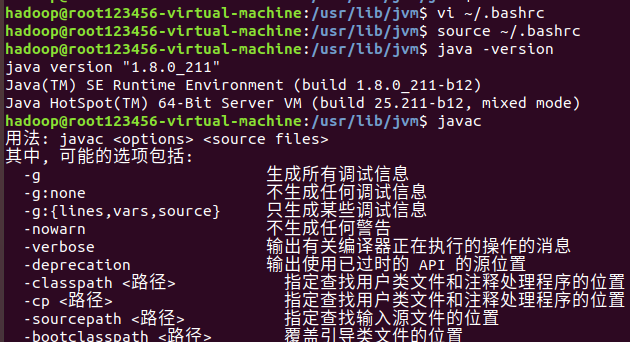
java安装成功后,就可以进行Hadoop的安装了。
【2】安装配置Hadoop
- 【2.1】Hadoop的下载安装
我的虚拟机Ubuntu安装了VMWare Tools,可以在win10桌面和Ubuntu桌面之间直接交换文件。所以在apache hadoop上直接下载的文件之后拷贝到Ubuntu桌面上。
#解压到/usr/local目录下
$ sudo tar -zxvf /home/root123456/桌面/hadoop-2.9.2.tar.gz -C /usr/local
$ cd /usr/local # 切换目录值
$ sudo mv hadoop-2.9.2 hadoop # 重命名为hadoop
$ sudo chown -R hadoop ./hadoop # 修改文件权限
给hadoop配置环境变量,
vi /.bashrc
将下面的代码添加到.bashrc文件中:
export HADOOP_HOME=/usr/local/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
配置完后,执行source ~/.bashrc使设置生效,并查看hadoop是否安装成功。
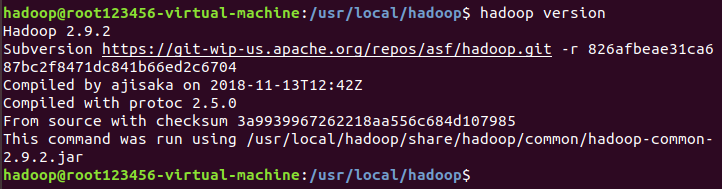
- 【2.2】伪分布式配置
Hadoop的默认模式即为本地模式(即单机模式),无需配置就可以运行,值得注意的是,Hadoop的模式变更(单机模式、伪分布式、分布式)完全是通过修改配置文件实现的。
这里配置的是伪分布式模式,即只有一个节点(一台机器),这个节点既作为名称节点(NameNode),也作为数据节点(DataNode),伪分布式模式配置涉及三个配置文件: hadoop目录/etc/hadoop/下的hadoop-env.sh、core-site.xml 和 hdfs-site.xml :
【2.2.1】首先将jdk1.8的路径添加到/etc/hadoop/hadoop-env.sh文件中
export JAVA_HOME=/usr/lib/jvm/java
【2.2.2】在core-site.xml文件中增加
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
【2.2.3】在hdfs-site.xml文件中增加
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
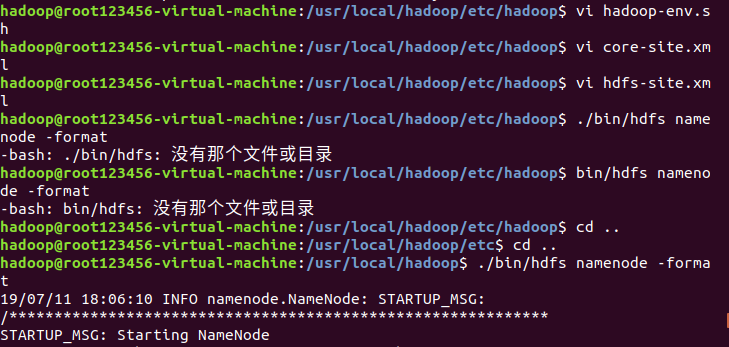
Hadoop的运行方式是由配置文件决定的(运行Hadoop时会读取配置文件),因此如果需要从伪分布式切换为单机模式,需要删除core-site.xml中的配置项。
伪分布式虽然只需要配置fs.defaultFS和dfs.replication就可以运行,不过若没有配置hadoop.tmp.dir参数,则默认使用的临时目录为/temp/hadoop-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行format才行。同时我们也指定了dfs.namenode.name.dir和dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
配置完成后,执行NameNode的格式化
$ ./bin/hdfs namenode -format
启动namanode和datanode进程
启动完后,可以通过jps来判断是否成功启动,若成功,则会出现以下四个进程“NameNode”、”DataNode” 和 “SecondaryNameNode”
$ ./sbin/start-dfs.sh
$ jps
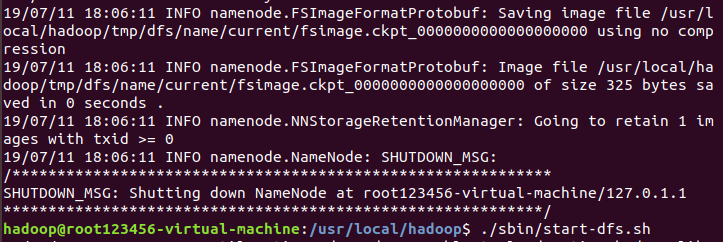
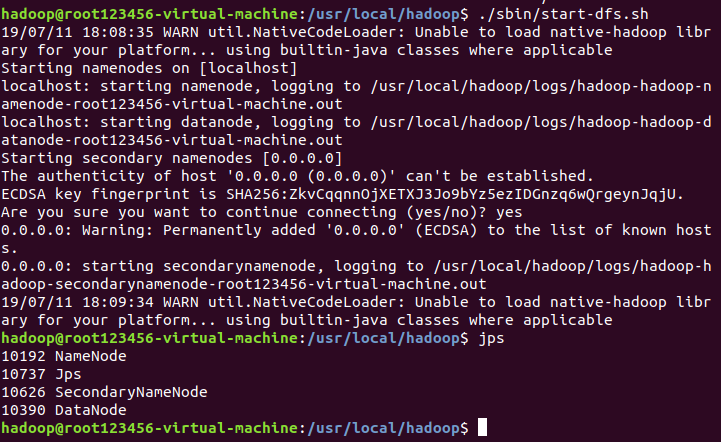
成功启动后,可以通过web界面 http://localhost:50070 查看NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
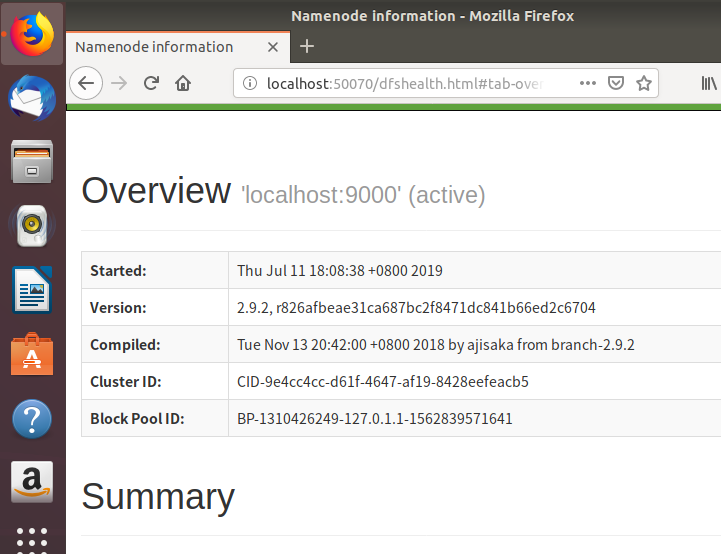
至此,Hadoop的伪分布式部署已完成啦!需要使用YARN的话,还需要单独配置mapred-site.xml和yarn-site.xml文件。
虚拟机Ubuntu(18.04.2)下安装配置Hadoop(2.9.2)(伪分布式+Java8)的更多相关文章
- Ubuntu 18.04 环境下安装 Matlab2018
由于实验环境要求,最近在 Ubuntu 18.04 上安装了 Matlab2018b , 这里简单记录过程. (1) 首先是获取对应的 Matlab2018b 的安装包,这里笔者是在一个外国的网站上获 ...
- protobuf ubuntu 18.04环境下安装
(t20190518) luo@luo-All-Series:~/MyFile$ (t20190518) luo@luo-All-Series:~/MyFile$ (t20190518) luo@lu ...
- Ubuntu 18.04版本下安装网易云音乐
这是我迄今为止发现的最完美的解决方法,不用改任何东西,只需要安装然后打开即可,后台也有. 参考:http://archive.ubuntukylin.com:10006/ubuntukylin/poo ...
- Ubuntu 18.04 手动编译安装 ffmpeg
ffmpeg 是一个由提供对视频.音频和其他多媒体流文件进行处理功能的库和程序构成的自由软件项目,其常被用于适用于不同格式的音频和视频的录影.转换和流处理等场合.这里记录在 Ubuntu 18.04 ...
- ubuntu 18.04 64bit下如何安装安卓虚拟机anbox?
一. 安装snapd sudo apt-get install snapd 二. 安装adb sudo apt-get install adb 三. 安装必要的内核模块 wget https://la ...
- 如何在Ubuntu 18.04 LTS上安装和配置MongoDB
MongoDB是一款非关系型数据库,提供高性能,高可用性和自动扩展企业数据库. MongoDB是一个非关系型数据库,因此您不能使用SQL(结构化查询语言)插入和检索数据,也不会将数据存储在MySQL或 ...
- 在Ubuntu 12.04系统中安装配置OpenCV 2.4.3的方法
在Ubuntu 12.04系统中安装配置OpenCV 2.4.3的方法 对于,在Linux系统下做图像识别,不像在windows下面我们可以利用Matlab中的图像工具箱来实现,我们必须借助Ope ...
- 在Ubuntu 18.04系统上安装Systemback的方法(抄)
在Ubuntu 18.04系统上安装Systemback的方法 2018-12-26 21:39:05作者:林莉稿源:云网牛站 本文介绍如何在Ubuntu 18.04或者Ubuntu 18.10系统上 ...
- Ubuntu 18.04 Numix主题安装设置
Ubuntu 18.04 Numix主题安装设置 一.首先安装Numix主题 展现效果如下图 1.安装numix sudo add-apt-repository ppa:numix/ppa 2.安装主 ...
随机推荐
- linux命令--大小写转换命令
1.tr命令 tr命令转换小写为大写 cat aa.txt | tr a-z A-Z 或者 cat aa.txt | tr [:lower:] [:upper:] tr命令大写转换小写 ...
- Mybatis入门(一)------基本概念操作
Mybatis简介 Mybatis是支持定制化 SQL.存储过程以及高级映射的优秀的持久层框架.MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集.MyBatis 可以对配置 ...
- 怎么创建一个良好的Git提交信息
译 原文:https://dev.to/chrissiemhrk/git-commit-message-5e21 提交信息是对提交之前添加和更改的文件所做的更改的简短描述. 良好的提交信息不仅对你 ...
- [转]camera的构成
camera的构成 拍摄景物通过镜头,将生成的光学图像投射到传感器上,然后光学图像被转换成电信号,电信号再经过模数转换变为数字信号,数字信号经过DSP加工处理,再被送到电脑中进行处理,最终转换成手机屏 ...
- 重学c#系列——盛派自定义异常源码分析(八)
前言 接着异常七后,因为以前看过盛派这块代码,正好重新整理一下. 正文 BaseException 首先看下BaseException 类: 继承:public class BaseException ...
- muduo源码解析9-timezone类
timezone class timezone:public copyable { }: 作用: 感觉有点看不懂,detail内部实现文件类不明白跟时区有什么关系.timezone类主要是完成各个时区 ...
- 第5章 if 语句
第5章 if 语句 5.1 一个简单示例 cars = ['audi', 'bmw', 'subaru', 'toyota'] for car in cars: if car == 'bmw': pr ...
- 初识ABP vNext(7):vue身份认证管理&租户管理
Tips:本篇已加入系列文章阅读目录,可点击查看更多相关文章. 目录 前言 开始 按钮级权限 身份认证管理 R/U权限 权限刷新 租户管理 租户切换 效果 最后 前言 上一篇介绍了vue+ABP国际化 ...
- 字段在class文件中的存在形式——FieldInfo
每个字段(Field)都有field_info结构所定义,一个class文件中,不会有两个字段同时具有相同的名字和描述符 name_index:值为一个整数(常量池表中的有效索引),例如name_in ...
- Android开发之ScrollView去掉右侧滚动条,gridview如何去掉外边框
android:scrollbars="none" android:listSelector="@null"