BeautifulSoup解析页面
beautiful soup是一个解析包,专门用来解析html语法的,lxml是一个解析器,用来分析以及定位内容的
.是class #是id
import requests
from bs4 import BeautifulSoup
html = requests.get('https://www.zygx8.com/forum.php')
soup = BeautifulSoup(html.text,'lxml')
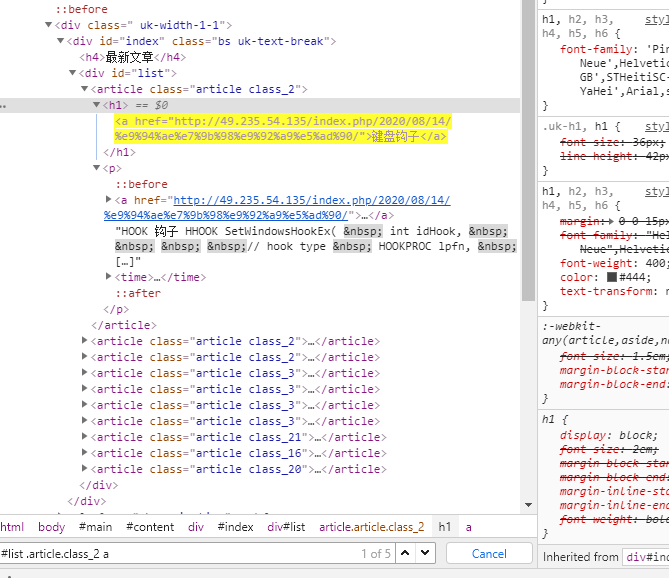
tbody = soup.select('a font b')
print(tbody)
输出

然后我们可以看到返回的都有个a标签,beautifulsoup其实有个自带的
for t in tbody:
print(t.text)
输出
键盘钩子
网络版cmd开发
Mycmd
这里选择器我们就用select,比如我们要获取title就直接soup.select('title'),通过tag逐层下找比如
soup.select('html head title')
soup.select('body a')
select_one只获取一个
这里我们来测试豆瓣
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
html = requests.get('https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4',headers=headers)
soup = BeautifulSoup(html.text,'lxml')
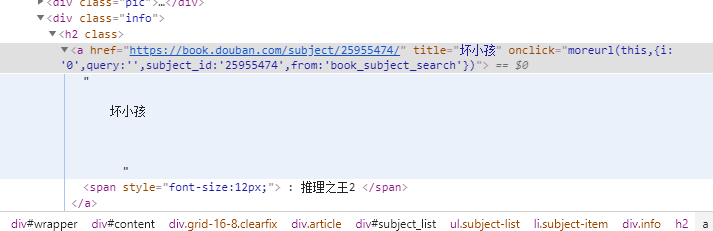
title = soup.select('.subject-list .subject-item .info h2 a')
for t in title:
print(t.text.strip().replace('\n',''))
输出
G:\python3.8\python.exe "F:/python post/code/zygx8.py"
坏小孩 : 推理之王2
活着
白夜行
小王子
解忧杂货店
红楼梦
追风筝的人
百年孤独
房思琪的初恋乐园
长夜难明 : 推理之王3
嫌疑人X的献身
平凡的世界(全三部)
1984
月亮与六便士
霍乱时期的爱情
围城
云边有个小卖部
杀死一只知更鸟
局外人
烧纸
Process finished with exit code 0
我们再清洗下
print(t.text.strip().replace('\n','').replace(' ',''))
输出
G:\python3.8\python.exe "F:/python post/code/zygx8.py"
坏小孩:推理之王2
活着
白夜行
小王子
解忧杂货店
红楼梦
追风筝的人
百年孤独
房思琪的初恋乐园
长夜难明:推理之王3
嫌疑人X的献身
平凡的世界(全三部)
1984
月亮与六便士
霍乱时期的爱情
围城
云边有个小卖部
杀死一只知更鸟
局外人
烧纸
BeautifulSoup解析页面的更多相关文章
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
本次python爬虫百步百科,里面详细分析了爬虫的步骤,对每一步代码都有详细的注释说明,可通过本案例掌握python爬虫的特点: 1.爬虫调度入口(crawler_main.py) # coding: ...
- Python爬虫 | Beautifulsoup解析html页面
引入 大多数情况下的需求,我们都会指定去使用聚焦爬虫,也就是爬取页面中指定部分的数据值,而不是整个页面的数据.因此,在聚焦爬虫中使用数据解析.所以,我们的数据爬取的流程为: 指定url 基于reque ...
- python爬虫解析页面数据的三种方式
re模块 re.S表示匹配单行 re.M表示匹配多行 使用re模块提取图片url,下载所有糗事百科中的图片 普通版 import requests import re import os if not ...
- beautifulsoup解析
beautifulsoup解析 python独有 优势:简单.便捷.高效 - 环境安装 需要将pip源设置为国内源 -需要安装:pip install bs4 bs4在使用时需要一个第三方库 pip ...
- python3+beautifulSoup4.6抓取某网站小说(三)网页分析,BeautifulSoup解析
本章学习内容:将网站上的小说都爬下来,存储到本地. 目标网站:www.cuiweijuxs.com 分析页面,发现一共4步:从主页进入分版打开分页列表.打开分页下所有链接.打开作品页面.打开单章内容. ...
- MiseringThread.java 解析页面线程
MiseringThread.java 解析页面线程 http://injavawetrust.iteye.com package com.iteye.injavawetrust.miner; imp ...
- MinerUrl.java 解析页面后存储URL类
MinerUrl.java 解析页面后存储URL类 package com.iteye.injavawetrust.miner; /** * 解析页面后存储URL类 * @author InJavaW ...
- BeautifulSoup解析器的选择
BeautifulSoup解析器 在我们使用BeautifulSoup的时候,选择怎样的解析器是至关重要的.使用不同的解析器有可能会出现不同的结果! 今天遇到一个坑,在解析某html的时候.使用htm ...
- Python3.x的BeautifulSoup解析html常用函数
Python3.x的BeautifulSoup解析html常用函数 1,初始化: soup = BeautifulSoup(html) # html为html源代码字符串,type(html) == ...
随机推荐
- 阿里云鼠标垫,云中谁寄锦书来,阿里云定制GIT指令集鼠标垫
活动地址 云中谁寄锦书来 活动时间 2020.8.19-8.28 奖品 必得,每日200份,共2000份 参考答案 tips:单选选择以上都是,多选就是全选 云效DevOps包含哪些产品- ABCDE ...
- 弱校验之@NotNull@NotEmpty@NotBlank
@NotNull 适用于非空判断 The annotated element must not be {@code null}. CharSequence, Collection, Map 和 Arr ...
- 牛客网数据库SQL实战解析(21-30题)
牛客网SQL刷题地址: https://www.nowcoder.com/ta/sql?page=0 牛客网数据库SQL实战解析(01-10题): https://blog.csdn.net/u010 ...
- 7. Jackson用树模型处理JSON是必备技能,不信你看
每棵大树,都曾只是一粒种子.本文已被 https://www.yourbatman.cn 收录,里面一并有Spring技术栈.MyBatis.JVM.中间件等小而美的专栏供以免费学习.关注公众号[BA ...
- Linux bpytop工具介绍
一.工具简介: Easy to use, with a game inspired menu system. Full mouse support, all buttons with a highli ...
- 关于函数式接口, printable 自定义
这段代码在jdk1.8可以使用, 由于我是jdk14, 会报错. 这里可以优化, lambda表达式进一步优化写为: printString(System.Out::println); 注意案例版 ...
- 温故知新——Spring AOP(二)
上一篇我们介绍Spring AOP的注解的配置,也叫做Java Config.今天我们看看比较传统的xml的方式如何配置AOP.整体的场景我们还是用原来的,"我穿上跑鞋",&quo ...
- JVM大作业5——指令集
JVM的每一个线程都有一个虚拟机栈,方法调用时,JVM会在虚拟机栈内为该方法创建一个栈帧. 一条线程,只有正在执行的方法对应的栈帧时可活动的,这个栈帧被称为当前栈帧,当前栈帧对应的方法被称为当前方法, ...
- WPF实现飞控姿态仪表盘控件Attitude dashboard
一.概要 近期项目当中需要用到飞机控制仪表盘的姿态仪,一开始去各大网站搜索解决方案要么就是winfrom要么就是很老的代码根本不能运行更甚者是居然有的还要下载积分. 只能自己手动从0开始写一个控件.这 ...
- js区别对象和数组的三种方法
var arr = {}||[]; 区分arr是数组还是对象 1.arr.constructor ...