沉淀,再出发:XPath的理解和使用
沉淀,再出发:XPath的理解和使用
一、前言
在很多查找的场合之下,我们需要使用正则表达式和其他的查找工具来进行内容的匹配和查找,特别是对于xml文件,我们可以使用xpath等工具来进行查找,通过树状结构我们可以很容易的对其中的元素,节点进行定位从而获取相应的内容,这样方便我们代码的规范性和可读性。
二、XPath的简介和使用
2.1、XPath简介
XPath 是一门在 XML 文档中查找信息的语言。XPath 是 XSLT 中的主要元素。XPath 于 1999 年 11 月 16 日 成为 W3C 标准。XQuery 和 XPointer 均构建于 XPath 表达式之上。XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。XPath 含有超过 100 个内建的函数(BIF)。这些函数用于字符串值、数值、日期和时间比较、节点和 QName 处理、序列处理、逻辑值等等。
2.2、XPath 术语
节点:在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
上面的XML文档中的节点例子:
<bookstore> (文档节点)
<author>J K. Rowling</author> (元素节点)
lang="en" (属性节点)
基本值(或称原子值,Atomic value):基本值是无父或无子的节点。
基本值的例子:
J K. Rowling
"en"
项目(Item):项目是基本值或者节点。
节点关系:
父(Parent):每个元素以及属性都有一个父。
在下面的例子中,book 元素是 title、author、year 以及 price 元素的父:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
子(Children):元素节点可有零个、一个或多个子。
在下面的例子中,title、author、year 以及 price 元素都是 book 元素的子:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
同胞(Sibling):拥有相同的父的节点
在下面的例子中,title、author、year 以及 price 元素都是同胞:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
先辈(Ancestor):某节点的父、父的父,等等。
在下面的例子中,title 元素的先辈是 book 元素和 bookstore 元素:
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
后代(Descendant):某个节点的子,子的子,等等。
在下面的例子中,bookstore 的后代是 book、title、author、year 以及 price 元素:
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
2.3、XPath 语法
XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
<?xml version="1.0" encoding="ISO-8859-1"?> <bookstore> <book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book> <book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book> </bookstore>
选取节点:XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。 下面列出了最有用的路径表达式:
表达式 描述
nodename 选取此节点的所有子节点。
/ 从根节点选取。
// 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
. 选取当前节点。
.. 选取当前节点的父节点。
@ 选取属性。
路径表达式 结果
bookstore 选取 bookstore 元素的所有子节点。
/bookstore 选取根元素 bookstore。
注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径!
bookstore/book 选取属于 bookstore 的子元素的所有 book 元素。
//book 选取所有 book 子元素,而不管它们在文档中的位置。
bookstore//book 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。
//@lang 选取名为 lang 的所有属性。
谓语(Predicates):谓语用来查找某个特定的节点或者包含某个指定的值的节点。谓语被嵌在方括号中。
路径表达式 结果
/bookstore/book[1] 选取属于 bookstore 子元素的第一个 book 元素。
/bookstore/book[last()] 选取属于 bookstore 子元素的最后一个 book 元素。
/bookstore/book[last()-1] 选取属于 bookstore 子元素的倒数第二个 book 元素。
/bookstore/book[position()<] 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。
//title[@lang] 选取所有拥有名为 lang 的属性的 title 元素。
//title[@lang='eng'] 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。
/bookstore/book[price>35.00] 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。
/bookstore/book[price>35.00]/title 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。
选取未知节点:XPath 通配符可用来选取未知的 XML 元素。
通配符 描述
* 匹配任何元素节点。
@* 匹配任何属性节点。
node() 匹配任何类型的节点。
路径表达式 结果
/bookstore/* 选取 bookstore 元素的所有子元素。
//* 选取文档中的所有元素。
//title[@*] 选取所有带有属性的 title 元素。
选取若干路径:通过在路径表达式中使用"|"运算符,您可以选取若干个路径。
路径表达式 结果
//book/title | //book/price 选取 book 元素的所有 title 和 price 元素。
//title | //price 选取文档中的所有 title 和 price 元素。
/bookstore/book/title | //price 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。
2.4、XPath 轴(Axes)
<?xml version="1.0" encoding="ISO-8859-1"?> <bookstore> <book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book> <book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book> </bookstore>
XPath 轴(Axes):轴可定义相对于当前节点的节点集。
轴名称 结果
ancestor 选取当前节点的所有先辈(父、祖父等)。
ancestor-or-self 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。
attribute 选取当前节点的所有属性。
child 选取当前节点的所有子元素。
descendant 选取当前节点的所有后代元素(子、孙等)。
descendant-or-self 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。
following 选取文档中当前节点的结束标签之后的所有节点。
namespace 选取当前节点的所有命名空间节点。
parent 选取当前节点的父节点。
preceding 选取文档中当前节点的开始标签之前的所有节点。
preceding-sibling 选取当前节点之前的所有同级节点。
self 选取当前节点。
2.5、XPath 运算符
运算符 描述 实例 返回值
| 计算两个节点集 //book | //cd 返回所有拥有 book 和 cd 元素的节点集
+ 加法 6 + 4 10
- 减法 6 - 4 2
* 乘法 6 * 4 24
div 除法 8 div 4 2
= 等于 price=9.80
!= 不等于 price!=9.80
< 小于 price<9.80
<= 小于或等于 price<=9.80
> 大于 price>9.80
>= 大于或等于 price>=9.80
or 或 price=9.80 or price=9.70
and 与 price>9.00 and price<9.90
mod 计算除法的余数 5 mod 2 1
2.6、XPath 实例
<?xml version="1.0" encoding="ISO-8859-1"?> <bookstore> <book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book> <book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book> <book category="WEB">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book> <book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book> </bookstore>
books.xml
加载 XML 文档:
所有现代浏览器都支持使用 XMLHttpRequest 来加载 XML 文档的方法。
针对大多数现代浏览器的代码:
var xmlhttp=new XMLHttpRequest()
针对古老的微软浏览器(IE 5 和 6)的代码:
var xmlhttp=new ActiveXObject("Microsoft.XMLHTTP")
选取节点:Internet Explorer 和其他处理 XPath 的方式不同。
Internet Explorer 使用 selectNodes() 方法从 XML 文档中的选取节点:
xmlDoc.selectNodes(xpath);
Firefox、Chrome、Opera 以及 Safari 使用 evaluate() 方法从 XML 文档中选取节点:
xmlDoc.evaluate(xpath, xmlDoc, null, XPathResult.ANY_TYPE,null);
2.6.1、选取所有 title
/bookstore/book/title
<html> <body>
<script>
function loadXMLDoc(dname)
{
if (window.XMLHttpRequest)
{
xhttp=new XMLHttpRequest();
}
else
{
xhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",dname,false);
xhttp.send("");
return xhttp.responseXML;
} xml=loadXMLDoc("books.xml");
path="/bookstore/book/title"
// code for IE
if (window.ActiveXObject)
{
var nodes=xml.selectNodes(path); for (i=0;i<nodes.length;i++)
{
document.write(nodes[i].childNodes[0].nodeValue);
document.write("<br>");
}
}
// code for Mozilla, Firefox, Opera, etc.
else if (document.implementation && document.implementation.createDocument)
{
var nodes=xml.evaluate(path, xml, null, XPathResult.ANY_TYPE, null);
var result=nodes.iterateNext(); while (result)
{
document.write(result.childNodes[0].nodeValue);
document.write("<br>");
result=nodes.iterateNext();
}
}
</script> </body></html>
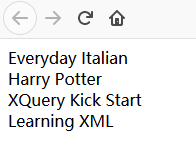
2.6.2、选取第一个 book 的 title
/bookstore/book[1]/title
<html> <body>
<script>
function loadXMLDoc(dname)
{
if (window.XMLHttpRequest)
{
xhttp=new XMLHttpRequest();
}
else
{
xhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",dname,false);
xhttp.send("");
return xhttp.responseXML;
} xml=loadXMLDoc("books.xml");
path="/bookstore/book[1]/title";
// code for IE
if (window.ActiveXObject)
{
var nodes=xml.selectNodes(path); for (i=0;i<nodes.length;i++)
{
document.write(nodes[i].childNodes[0].nodeValue);
document.write("<br>");
}
}
// code for Mozilla, Firefox, Opera, etc.
else if (document.implementation && document.implementation.createDocument)
{
var nodes=xml.evaluate(path, xml, null, XPathResult.ANY_TYPE,null);
var result=nodes.iterateNext(); while(result)
{
document.write(result.childNodes[0].nodeValue);
document.write("<br>");
result=nodes.iterateNext();
}
}
</script> </body></html>
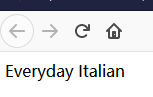
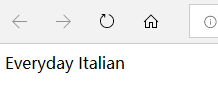
上面的例子IE5 以及更高版本将 [0] 视为第一个节点,而根据 W3C 的标准,应该是 [1]。为了解决 IE5+ 中 [0] 和 [1] 的问题,可以为 XPath 设置语言选择(SelectionLanguage)。
<html> <body>
<script>
function loadXMLDoc(dname)
{
if (window.XMLHttpRequest)
{
xhttp=new XMLHttpRequest();
}
else
{
xhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",dname,false);
xhttp.send("");
return xhttp.responseXML;
} xml=loadXMLDoc("books.xml");
path="/bookstore/book[1]/title";
// code for IE
if (window.ActiveXObject)
{
xml.setProperty("SelectionLanguage","XPath");
var nodes=xml.selectNodes(path); for (i=0;i<nodes.length;i++)
{
document.write(nodes[i].childNodes[0].nodeValue);
document.write("<br>");
}
}
// code for Mozilla, Firefox, Opera, etc.
else if (document.implementation && document.implementation.createDocument)
{
var nodes=xml.evaluate(path, xml, null, XPathResult.ANY_TYPE,null);
var result=nodes.iterateNext(); while (result)
{
document.write(result.childNodes[0].nodeValue);
document.write("<br>");
result=nodes.iterateNext();
}
}
</script> </body></html>
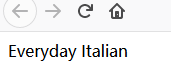
2.6.3、选取所有价格:选取 price 节点中的所有文本
/bookstore/book/price/text()
<html> <body>
<script>
function loadXMLDoc(dname)
{
if (window.XMLHttpRequest)
{
xhttp=new XMLHttpRequest();
}
else
{
xhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",dname,false);
xhttp.send("");
return xhttp.responseXML;
} xml=loadXMLDoc("books.xml");
path="/bookstore/book/price/text()"
// code for IE
if (window.ActiveXObject)
{
var nodes=xml.selectNodes(path); for (i=0;i<nodes.length;i++)
{
document.write(nodes[i].nodeValue);
document.write("<br>");
}
}
// code for Mozilla, Firefox, Opera, etc.
else if (document.implementation && document.implementation.createDocument)
{
var nodes=xml.evaluate(path, xml, null, XPathResult.ANY_TYPE,null);
var result=nodes.iterateNext(); while (result)
{
document.write(result.nodeValue + "<br>");
result=nodes.iterateNext();
}
}
</script> </body></html>

2.6.4、选取价格高于 35 的 price 节点
/bookstore/book[price>35]/price
<html> <body>
<script>
function loadXMLDoc(dname)
{
if (window.XMLHttpRequest)
{
xhttp=new XMLHttpRequest();
}
else
{
xhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",dname,false);
xhttp.send("");
return xhttp.responseXML;
} xml=loadXMLDoc("books.xml");
path="/bookstore/book[price>35]/price";
// code for IE
if (window.ActiveXObject)
{
var nodes=xml.selectNodes(path); for (i=0;i<nodes.length;i++)
{
document.write(nodes[i].childNodes[0].nodeValue);
document.write("<br>");
}
}
// code for Mozilla, Firefox, Opera, etc.
else if (document.implementation && document.implementation.createDocument)
{
var nodes=xml.evaluate(path, xml, null, XPathResult.ANY_TYPE,null);
var result=nodes.iterateNext(); while (result)
{
document.write(result.childNodes[0].nodeValue);
document.write("<br>");
result=nodes.iterateNext();
}
}
</script> </body></html>

XSLT 是针对 XML 文件的样式表语言。通过 XSLT,可以把 XML 文件转换为其他的格式,比如 XHTML。
XQuery 和 XML 数据查询有关。XQuery 被设计用来查询任何可作为 XML 形态呈现的数据,包括数据库。
XLink 和 XPointer,XML 中的链接被分为两个部分:XLink 和 XPointer。XLink 和 XPointer 定义了在 XML 文档中创建超级链接的标准方法。
三、总结
通过对XPath的学习,我们可以更加深刻地理解xml这种树状结构,以及对这种结构的查找遍历方法,方便对网页的抓取和解析。
参考文献:https://code.ziqiangxuetang.com/xpath/xpath-tutorial.html
沉淀,再出发:XPath的理解和使用的更多相关文章
- 沉淀再出发:Spring的架构理解
沉淀再出发:Spring的架构理解 一.前言 在Spring之前使用的EJB框架太庞大和重量级了,开发成本很高,由此spring应运而生.关于Spring,学过java的人基本上都会慢慢接触到,并且在 ...
- 沉淀再出发:spring boot的理解
沉淀再出发:spring boot的理解 一.前言 关于spring boot,我们肯定听过了很多遍了,其实最本质的东西就是COC(convention over configuration),将各种 ...
- 沉淀再出发:关于java中的AQS理解
沉淀再出发:关于java中的AQS理解 一.前言 在java中有很多锁结构都继承自AQS(AbstractQueuedSynchronizer)这个抽象类如果我们仔细了解可以发现AQS的作用是非常大的 ...
- 沉淀再出发:关于netty的一些理解和使用
沉淀再出发:关于netty的一些理解和使用 一.前言 Netty是由JBOSS提供的一个java开源框架.Netty提供异步的.事件驱动的网络应用程序框架和工具,用以快速开发高性能.高可靠性的网络服务 ...
- 沉淀再出发:在python3中导入自定义的包
沉淀再出发:在python3中导入自定义的包 一.前言 在python中如果要使用自己的定义的包,还是有一些需要注意的事项的,这里简单记录一下. 二.在python3中导入自定义的包 2.1.什么是模 ...
- 沉淀再出发:jetty的架构和本质
沉淀再出发:jetty的架构和本质 一.前言 我们在使用Tomcat的时候,总是会想到jetty,这两者的合理选用是和我们项目的类型和大小息息相关的,Tomcat属于比较重量级的容器,通过很多的容器层 ...
- 沉淀再出发:dubbo的基本原理和应用实例
沉淀再出发:dubbo的基本原理和应用实例 一.前言 阿里开发的dubbo作为服务治理的工具,在分布式开发中有着重要的意义,这里我们主要专注于dubbo的架构,基本原理以及在Windows下面开发出来 ...
- 沉淀再出发:Bean,JavaBean,POJO,VO,PO,EJB等名词的异同
沉淀再出发:Bean,JavaBean,POJO,VO,PO,EJB等名词的异同 一.前言 想必大家都有这样的困惑,接触的东西越多却越来越混乱了,这个时候就要进行对比和深入的探讨了,抓住每一个概念背后 ...
- 沉淀再出发:java中注解的本质和使用
沉淀再出发:java中注解的本质和使用 一.前言 以前XML是各大框架的青睐者,它以松耦合的方式完成了框架中几乎所有的配置,但是随着项目越来越庞大,XML的内容也越来越复杂,维护成本变高.于是就有人提 ...
- 沉淀再出发:IoC和AOP的本质
沉淀再出发:IoC和AOP的本质 一.前言 关于IoC和AOP这两个概念,如果我们没有深入的理解可以说是根本就不理解Spring这个架构的,同样的由Spring演变出来的Spring Boot和Spr ...
随机推荐
- WPF DataTemplate與ControlTemplate
一. 前言 什麼是DataTemplate? 什麼是ControlTemplate? 在stackoverflow有句簡短的解釋 "A DataTemplate, therefore ...
- Dubbo源码解读
1.提升SOA的微服务架构设计能力 通过读dubbo源码是一条非常不错的通往SOA架构设计之路,毕竟SOA的服务治理就是dubbo首先提出来的,比起你去看市面上的SOA微服务架构的书籍,学到的架构 ...
- js Array vs [],以及是否为空的判断
两者基本相同,唯一不同点在于初始化: var a = [], // these are the same b = new Array(), // a and b are arrays with len ...
- Linux 的启动流程--转
http://cloudbbs.org/forum.php?mod=viewthread&tid=17814 半年前,我写了<计算机是如何启动的?>,探讨BIOS和主引导记录的作用 ...
- jar 不是内部或外部命令 CLASS_PATH设置
JDK安装没有问题,%JAVA_HOME% 和 path %JAVA_HOME%\bin 设置都没有问题 设置CLASS_PATH CLASS_PATH .;%JAVA_HOME%\l ...
- 安装caffe(opencv3+anaconda3)
目录 仅安装CPU版本的caffe 1.下载相关的依赖包: 2.安装opencv3 3.安装caffe 参考文献: 仅安装CPU版本的caffe 1.下载相关的依赖包: sudo apt-get in ...
- ExcelHelper----根据指定样式的数据,生成excel(一个sheet1页)文件流
/// <summary> /// Excel导出类 /// </summary> public class ExcelHelper { /// <summary> ...
- SQL 之开启远程访问
转载自 http://blog.csdn.net/happymagic/article/details/51835522 SQL Server 开启远程访问的方法: 注意事项:(重点) 此次演示版本 ...
- [javaSE] 网络编程(URL)
获取URL对象,new出来,构造参数:String的路径 调用URL对象的getProtocal()方法,获取协议 调用URL对象的getHost()方法,获取主机 调用URL对象的getPath() ...
- Java8实战Lambda和Stram API学习
public class Trader{ private String name; private String city; public Trader(String n, St ...