scrapy框架(2)
一、使用scrapy框架发送post请求
1、需求一:使用scrapy发送百度翻译中的ajax请求
创建一个项目,如下目录,修改settings.py文件中的 "ROBOTSTXT_OBEY"和"USER_AGENT"
# postPro/postPro/spiders/post.py # -*- coding: utf-8 -*-
import scrapy class PostSpider(scrapy.Spider):
name = 'post'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://fanyi.baidu.com/sug'] def start_requests(self):
data = {
"kw":"dog"
}
for url in self.start_urls:
yield scrapy.FormRequest(url=url, formdata=data, callback=self.parse) def parse(self, response):
print(response.text)

2、需求二:基于scrapy实现模拟登录
自己尝试实现!
二、请求传参
我们知道有时候需要爬取的数据并不是都在一个页面中,而是在不同页面中,这时候用scrapy框架该如何做呢?下面以爬取:https://www.4567tv.tv/frim/index1.html 中的数据为例说明。
1、创建一个项目,目录结构如下,并修改settings.py文件中的 "ROBOTSTXT_OBEY"和"USER_AGENT"
2、各文件内容如下
# moviePro/moviePro/spiders/movie.py # -*- coding: utf-8 -*-
import scrapy from moviePro.items import MovieproItem class MovieSpider(scrapy.Spider):
name = 'movie'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.4567tv.tv/frim/index1.html'] # 解析详情页中的数据
def parse_detail(self, response):
# response.meta 返回接收到的meta字典
item = response.meta['item']
actor = response.xpath('/html/body/div[1]/div/div/div/div[2]/p[3]/a/text()').extract_first()
item['actor'] = actor yield item def parse(self, response):
li_list = response.xpath('//li[@class="col-md-6 col-sm-4 col-xs-3"]')
for li in li_list:
item = MovieproItem()
name = li.xpath('./div/a/@title').extract_first()
detail_url = 'https://www.4567tv.tv' + li.xpath('./div/a/@href').extract_first()
item['name'] = name
yield scrapy.Request(url=detail_url, callback=self.parse_detail, meta={'item': item})
# moviePro/moviePro/items.py import scrapy class MovieproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
actor = scrapy.Field()
# moviePro/moviePro/pipelines.py class MovieproPipeline(object):
def process_item(self, item, spider):
print(item)
return item
注意:要将settings.py中的"ITEM_PIPELINES"放开注释!
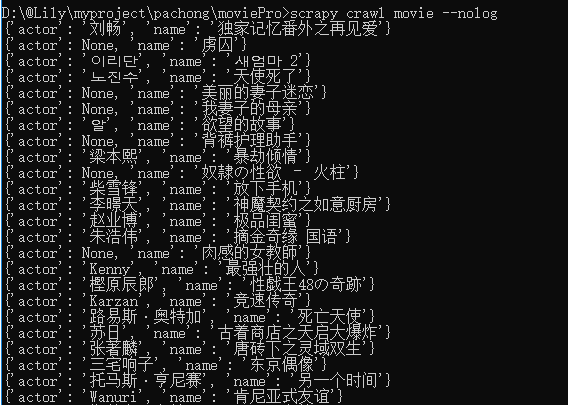
3、运行结果
三、日志等级
1、修改日志等级
通过修改settings.py中的参数 LOG_LEVEL 来修改日志等级,比如可以改为 ERROR
# settings.py
LOG_LEVEL = "ERROR"
2、指定日志输出文件
# settings.py
LOG_FILE = './log.txt'
四、scrapy的五大核心组件
1、五大核心组件工作流程如下图:
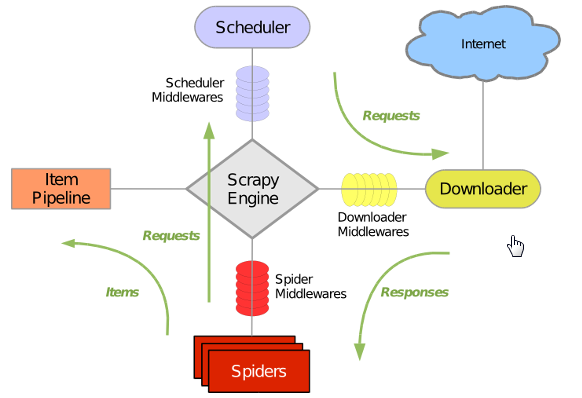
解释如下:
- 引擎(Scrapy)
用来处理整个系统的数据流处理,触发事务(框架核心)
- 调度器(Scheduler)
用来接收引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回,可以想象成一个URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是什么,同时去除重复的网址
- 下载器(Downloader)
用于下载网页内容,并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders)
爬虫是主要干活的,用于从特定的网页中提取自己需要的信息,即所谓的实体(Item)。用户也可以从中提取出链接,让scrapy继续抓取下一个页面
- 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体,验证实体的有效性,清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据
2、案例一
当批量请求时,对不同的请求使用不同的UA伪装和IP代理,可以利用DownloaderMiddleware,新建一个项目,目录结构如下:

各文件内容如下:
# middlePro/middlePro/middlewares.py
import random
from scrapy import signals
class MiddleproDownloaderMiddleware(object):
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 "
"(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
# 可被选用的代理IP
PROXY_http = [
'153.180.102.104:80',
'195.208.131.189:56055',
]
PROXY_https = [
'120.83.49.90:9000',
'95.189.112.214:35508',
]
# 拦截所有未发生异常的请求
def process_request(self, request, spider):
# 使用UA池进行请求的UA伪装
request.headers["User-Agent"] = random.choice(self.user_agent_list)
print(request.headers['User-Agent'])
return None
# 拦截所有的响应
def process_response(self, request, response, spider):
return response
# 拦截到产生异常的请求
def process_exception(self, request, exception, spider):
print('this is process_exception!')
if request.url.split(':')[0] == 'http':
request.meta['proxy'] = random.choice(self.PROXY_http)
else:
request.meta['proxy'] = random.choice(self.PROXY_https)
# middlePro/middlePro/spiders/middle.py # -*- coding: utf-8 -*-
import scrapy class MiddleSpider(scrapy.Spider):
name = 'middle'
allowed_domains = ['www.xxx.com']
start_urls = ['https://www.baidu.com/s?wd=ip'] def parse(self, response):
pass
注意:settings.py中的参数 "DOWNLOADER_MIDDLEWARES" 解开注释!
3、案例二
抓取网易新闻"军事"模块(http://war.163.com/)的页面信息,注意动态加载。
思路提示:页面是有动态加载信息,因此我们要使用selenium模块。
新建一个scrapy项目,目录结构如下:
各文件代码如下:
# wangyiPro/wangyiPro/spieders/wangyi.py # -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver class WangyiSpider(scrapy.Spider):
name = 'wangyi'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://war.163.com/'] def __init__(self):
self.bro = webdriver.Chrome(executable_path=r'D:\@Lily\myproject\pachong\chromedriver.exe') def parse(self, response):
div_list = response.xpath('//div[@class="data_row news_article clearfix "]')
for div in div_list:
title = div.xpath('.//div[@class="news_title"]/h3/a/text()').extract_first()
print(title) def closed(self, spider):
print('关闭浏览器对象!')
self.bro.quit()
# wangyiPro/wangyiPro/middlewares.py from time import sleep
from scrapy import signals
from scrapy.http import HtmlResponse class WangyiproDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects. @classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s def process_request(self, request, spider):
return None def process_response(self, request, response, spider):
# 获取动态加载出来的数据
bro = spider.bro
bro.get(url=request.url)
sleep(3)
# 包含了动态加载出来的新闻数据
page_text = bro.page_source
sleep(3)
return HtmlResponse(url=spider.bro.current_url, body=page_text, encoding='utf-8', request=request) def process_exception(self, request, exception, spider):
pass
注意:settings.py文件中要配置好参数"ROBOTSTXT_OBEY"和"ROBOTSTXT_OBEY",并且解开中间件参数"DOWNLOADER_MIDDLEWARES"的注释。
运行结果如下:

总结:在scrapy中使用selenium的编码流程:
1)在spider的构造方法中创建一个浏览器对象(作为当前spider的一个属性)
2)重写spider的一个方法closed(self,spider),在该方法中执行浏览器关闭的操作
3)在下载中间件的process_response方法中,通过spider参数获取浏览器对象
4)在中间件的process_response中定制基于浏览器自动化的操作代码(获取动态加载出来的页面源码数据)
5)实例化一个响应对象,且将page_source返回的页面源码封装到该对象中
6)返回该新的响应对象
五、相关参考博客
https://www.cnblogs.com/bobo-zhang/p/10069001.html
https://www.cnblogs.com/bobo-zhang/p/10069004.html
https://www.cnblogs.com/bobo-zhang/p/10013011.html
scrapy框架(2)的更多相关文章
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
- Scrapy框架使用—quotesbot 项目(学习记录一)
一.Scrapy框架的安装及相关理论知识的学习可以参考:http://www.yiibai.com/scrapy/scrapy_environment.html 二.重点记录我学习使用scrapy框架 ...
- Python爬虫从入门到放弃(十一)之 Scrapy框架整体的一个了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- 一个scrapy框架的爬虫(爬取京东图书)
我们的这个爬虫设计来爬取京东图书(jd.com). scrapy框架相信大家比较了解了.里面有很多复杂的机制,超出本文的范围. 1.爬虫spider tips: 1.xpath的语法比较坑,但是你可以 ...
- 安装scrapy框架的常见问题及其解决方法
下面小编讲一下自己在windows10安装及配置Scrapy中遇到的一些坑及其解决的方法,现在总结如下,希望对大家有所帮助. 常见问题一:pip版本需要升级 如果你的pip版本比较老,可能在安装的过程 ...
- 关于使用scrapy框架编写爬虫以及Ajax动态加载问题、反爬问题解决方案
Python爬虫总结 总的来说,Python爬虫所做的事情分为两个部分,1:将网页的内容全部抓取下来,2:对抓取到的内容和进行解析,得到我们需要的信息. 目前公认比较好用的爬虫框架为Scrapy,而且 ...
- 利用scrapy框架进行爬虫
今天一个网友问爬虫知识,自己把许多小细节都忘了,很惭愧,所以这里写一下大概的步骤,主要是自己巩固一下知识,顺便复习一下.(scrapy框架有一个好处,就是可以爬取https的内容) [爬取的是杨子晚报 ...
随机推荐
- Oracle 12c安装详细步骤,带截图
1,在官网上下载oracle的压缩文件,两个都要下载. 并两个同时选中解压在一个文件夹里面. 2,解压之后,如下图,点击setup.exe稍等一会儿 ,3,开始安装: 不选点击下一步,或者直接点击下一 ...
- 【Java面试题】44 java中有几种类型的流?JDK为每种类型的流提供了一些抽象类以供继承,请说出他们分别是哪些类?
字节流,字符流.字节流继承于InputStream OutputStream,字符流继承于InputStreamReader OutputStreamWriter.在java.io包中还有许多其他的流 ...
- js时间转化
const defaultTicks = 621355968000000000; export function convertDateToTicks(date = new Date()) { ret ...
- Oracle从字符串资源中得到想要的数据分析
[oracle]从字符串资源中得到想要的数据分析需求:订单分析,按照游戏,帐号级别,游戏帐号职业,区服,价格区间分析各款交易数据走势 .目标:订单表(order)处理分析:订单中可以直接读到的标示有游 ...
- 【matlab】使用VideoReader提取视频的每一帧,不能用aviread函数~
这个问题是matlab版本问题,已经不用aviread函数了~ VideoReader里面没有cdata这个函数! MATLAB不支持avireader了,而且没有cdata这个属性了,详情去官网ht ...
- OpenCV学习:Windows+VS2010+OpenCV配置
OpenCV下载: 百度云下载:https://pan.baidu.com/s/1mhAExdu (2.4.9版本) 下载完成后,双击运行exe,选择输出目录,我选择的是C:\OpenCV 配置环境变 ...
- 记录下DynamicXml和HtmlDocument 使用方式
之前解析都是XmlDocument.Load 而现在可以利用DynamicXml生成Dynamic对象实现强类型操作,很好用. /// <summary> /// 根据Xml路径动态解析成 ...
- 移动HTML 5前端性能优化指南
概述 PC优化手段在Mobile侧同样适用 在Mobile侧我们提出三秒种渲染完成首屏指标 基于第二点,首屏加载3秒完成或使用Loading 基于联通3G网络平均338KB/s(2.71Mb/s),所 ...
- webpack之跨域
前后端分离开发中,本地前端开发调用接口会有跨域问题,一般有以下几种解决方法: 直接启动服务端项目,再将项目中的资源url指向到前端服务中的静态资源地址,好处在于因为始终在服务端的环境中进行资源调试,不 ...
- 图论之最短路径(3)队列优化的Bellman-Ford算法(SPFA算法)
在Bellman-Ford算法中 我们可以看到大量的优化空间:如果一个点的最短路径已经确定了,那么它就不会再改变,因此不需要再处理.换句话说:我们每次只对最短路径改变了的顶点的所有出边进行操作 使用一 ...