Python爬虫教程-04-response简介
Spider-04-response简介
本小节介绍urlopen的返回对象,和简单调试方法
案例v3
- 研究request的返回值,输出返回值类型,打印内容
- geturl:返回请求对象的url
- info:请求返回对象的meta信息
- getcode:返回的http code
- py04v3.py文件:https://xpwi.github.io/py/py爬虫/py04v3.py
# py04v3.py
from urllib import request
if __name__ == '__main__':
url = 'https://jobs.zhaopin.com/CC375882789J00033399409.htm'
rsp = request.urlopen(url)
# 按住Ctrl键不送,同时点击urlopen,可以查看文档,有函数的具体参数和使用方法
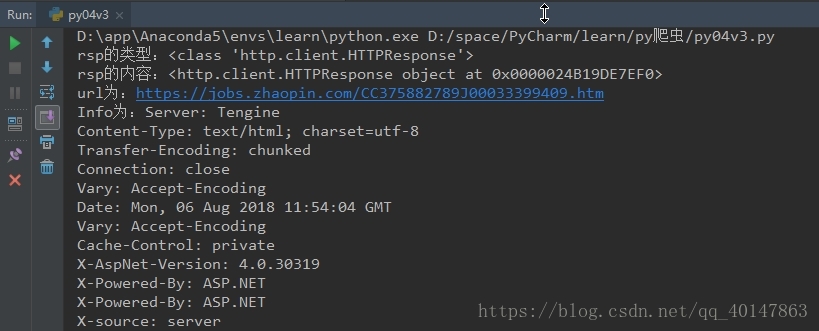
print("rsp的类型:{0}".format(type(rsp)))
print("rsp的内容:{0}".format(rsp))
print("url为:{0}".format(rsp.geturl()))
print("Info为:{0}".format(rsp.info()))
print("Code为:{0}".format(rsp.getcode()))
html = rsp.read()
右键运行,截图如下
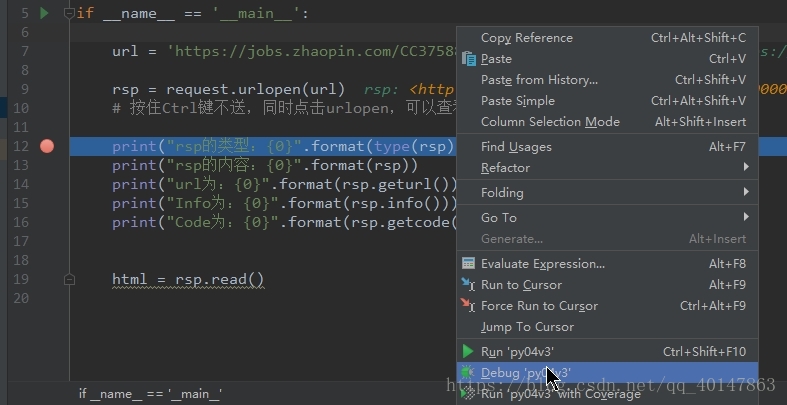
关于调试
- 在代码左侧【行号】上单击,出现红点,及断点
- 右键【Debug '项目名'】
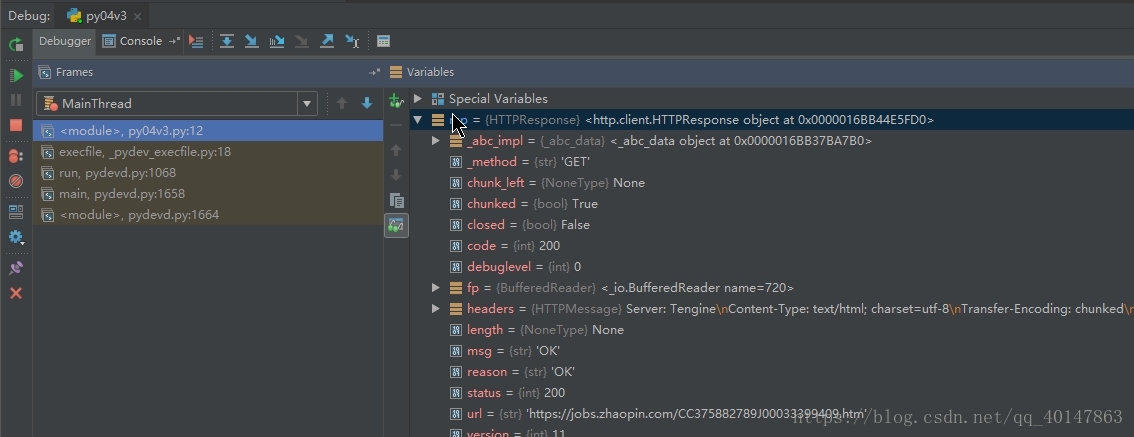
控制台截图如下
包括请求过程中的参数
urlopen的返回对象,和简单调试方法就介绍到这里了
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-04-response简介的更多相关文章
- Python爬虫教程-20-xml 简介
本篇简单介绍 xml 在python爬虫方面的使用,想要具体学习 xml 可以到 w3school 查看 xml 文档 xml 文档链接:http://www.w3school.com.cn/xmld ...
- Python爬虫教程-21-xpath 简介
本篇简单介绍 xpath 在python爬虫方面的使用,想要具体学习 xpath 可以到 w3school 查看 xpath 文档 xpath文档:http://www.w3school.com.cn ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-33-scrapy shell 的使用
本篇详细介绍 scrapy shell 的使用,也介绍了使用 xpath 进行精确查找 Python爬虫教程-33-scrapy shell 的使用 scrapy shell 的使用 条件:我们需要先 ...
- Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
本篇介绍项目开发的过程中,对 Setting 文件的配置和使用 Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍 settings.py 文件的使用 想要详细查看 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python爬虫教程-30-Scrapy 爬虫框架介绍
从本篇开始学习 Scrapy 爬虫框架 Python爬虫教程-30-Scrapy 爬虫框架介绍 框架:框架就是对于相同的相似的部分,代码做到不出错,而我们就可以将注意力放到我们自己的部分了 常见爬虫框 ...
- Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影)
Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影) ProxyHandler处理(代理服务器),使用代理IP,是爬虫的常用手段,通常使用UserAgent 伪装浏览器爬取仍然可能被网 ...
- Python爬虫教程-10-UserAgent和常见浏览器UA值
Python爬虫教程-10-UserAgent和常见浏览器UA值 有时候使用爬虫会被网站封了IP,所以需要去模拟浏览器,隐藏用户身份, UserAgent 包含浏览器信息,用户身份,设备系统信息 Us ...
随机推荐
- prim /kruskal 最小生成树
#include<iostream> #include<cstdio> #include<cstring> #include<cstdlib> #inc ...
- [转] gitlab 的 CI/CD 配置管理
[From] http://blog.51cto.com/flyfish225/2156602 gitlab 的 CI/CD 配置管理 (二) 标签(空格分隔):运维系列 一:gitlab CI/CD ...
- Manjaro安装笔记
安装后就可以先配置国内的软件源.使用以下命令: #排列源 sudo pacman-mirrors -g https://www.jianshu.com/p/f2c9ee00698c https://w ...
- springboot-21-maven多环境打包
前几天项目需要用到分环境打包, 于是研究了下, 由于项目基于springboot的, 所以分两个情况进行说明: 1), springboot的多环境配置 2), maven-springboot的多环 ...
- springboot-20-全局异常处理
springboot的全局异常处理 . 新建一个类GlobalDefaultExceptionHandler 在class上注解 @ControllerAdvice 方法上注解 @ExceptionH ...
- [心平气和读经典]The TCP/IP Guide(001)
The TCP/IP Guide[Page 40,41] Introduction To the TCP/IP Guide | TCP/IP指南概述 As I sit here writing thi ...
- 认识HDFS分布式文件系统
1.设计基础目标 (1) 错误是常态,需要使用数据冗余 (2)流式数据访问.数据批量读而不是随机速写,不支持OLTP,hadoop擅长数据分析而不是事物处理. (3)文件采用一次性写多次读的模型, ...
- leetcode简单题目两道(2)
Problem Given an integer, write a function to determine if it is a power of three. Follow up: Could ...
- [译]用R语言做挖掘数据《七》
时间序列与数据挖掘 一.实验说明 1. 环境登录 无需密码自动登录,系统用户名shiyanlou,密码shiyanlou 2. 环境介绍 本实验环境采用带桌面的Ubuntu Linux环境,实验中会用 ...
- Python——如何搭建Python的环境
最近在学Python,只知道python一般是用来写爬虫的,以前看过一个朋友用Python做的爬虫从妹子图网站上下载图片,觉得很有趣,自己也想学一学. 俗话说,万事开头难,首先第一步就是搭建Pytho ...