Spark Shuffle之Sort Shuffle
源文件放在github,随着理解的深入,不断更新,如有谬误之处,欢迎指正。原文链接https://github.com/jacksu/utils4s/blob/master/spark-knowledge/md/sort-shuffle.md
正如你所知,spark实现了多种shuffle方法,通过 spark.shuffle.manager来确定。暂时总共有三种:hash shuffle、sort shuffle和tungsten-sort shuffle,从1.2.0开始默认为sort shuffle。本节主要介绍sort shuffle。
从1.2.0开始默认为sort shuffle(spark.shuffle.manager = sort),实现逻辑类似于Hadoop MapReduce,Hash Shuffle每一个reducers产生一个文件,但是Sort Shuffle只是产生一个按照reducer id排序可索引的文件,这样,只需获取有关文件中的相关数据块的位置信息,并fseek就可以读取指定reducer的数据。但对于rueducer数比较少的情况,Hash Shuffle明显要比Sort Shuffle快,因此Sort Shuffle有个“fallback”计划,对于reducers数少于 “spark.shuffle.sort.bypassMergeThreshold” (200 by default),我们使用fallback计划,hashing相关数据到分开的文件,然后合并这些文件为一个,具体实现为BypassMergeSortShuffleWriter。
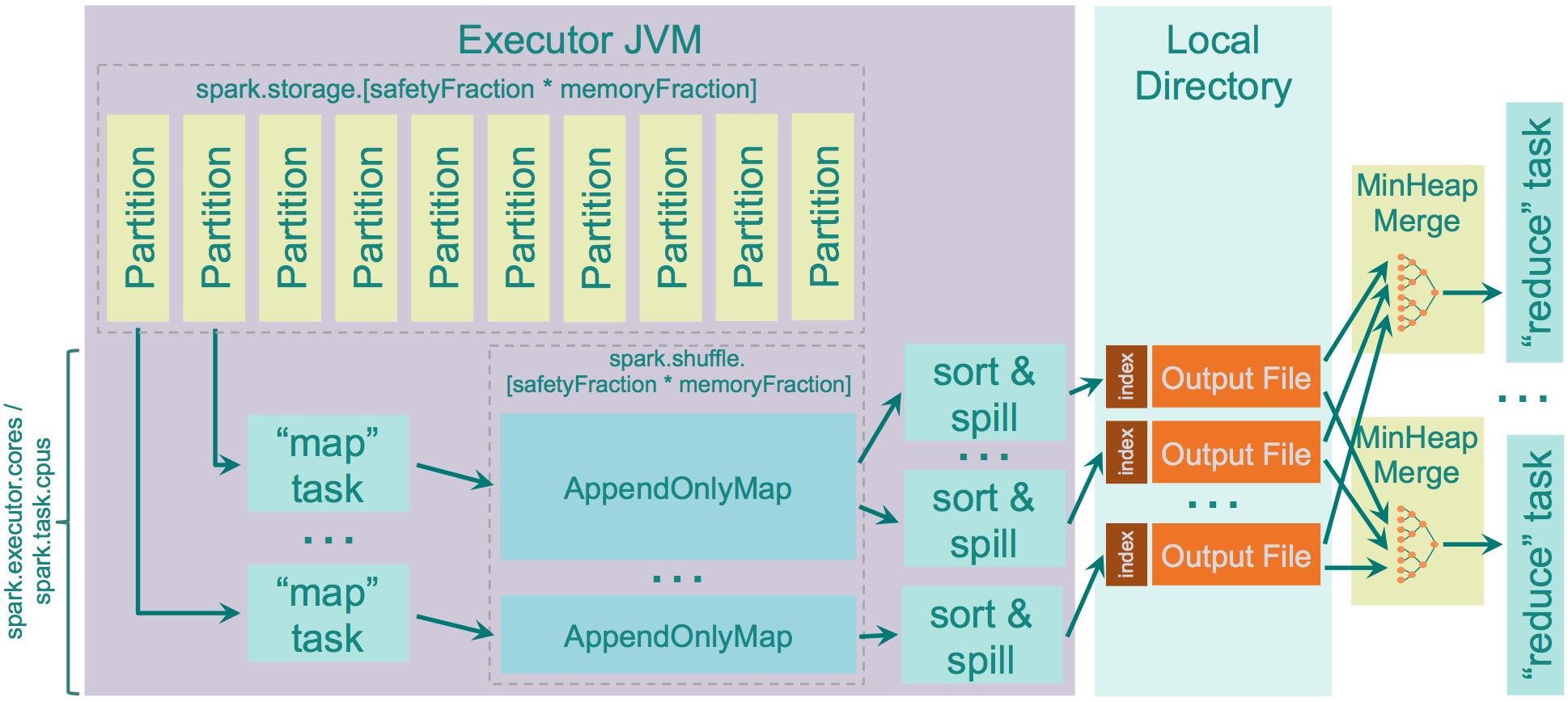
在map进行排序,在reduce端应用Timsort[1]进行合并。map端是否容许spill,通过spark.shuffle.spill来设置,默认是true。设置为false,如果没有足够的内存来存储map的输出,那么就会导致OOM错误,因此要慎用。
用于存储map输出的内存为:“JVM Heap Size” \* spark.shuffle.memoryFraction \* spark.shuffle.safetyFraction,默认为“JVM Heap Size” \* 0.2 \* 0.8 = “JVM Heap Size” \* 0.16。如果你在同一个执行程序中运行多个线程(设定spark.executor.cores/ spark.task.cpus超过1),每个map任务存储的空间为“JVM Heap Size” * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction / spark.executor.cores * spark.task.cpus, 默认2个cores,那么为0.08 * “JVM Heap Size”。
spark使用AppendOnlyMap存储map输出的数据,利用开源hash函数MurmurHash3和平方探测法把key和value保存在相同的array中。这种保存方法可以是spark进行combine。如果spill为true,会在spill前sort。
Sort Shuffle内存的源码级别更详细说明可以参考[4],读写过程可以参考[5]
优点
- map创建文件量较少
- 少量的IO随机操作,大部分是顺序读写
缺点
- 要比Hash Shuffle要慢,需要自己通过
spark.shuffle.sort.bypassMergeThreshold来设置合适的值。 - 如果使用SSD盘存储shuffle数据,那么Hash Shuffle可能更合适。
参考
[1][Timsort原理介绍](http://blog.csdn.net/yangzhongblog/article/details/8184707)
[2][形式化方法的逆袭——如何找出Timsort算法和玉兔月球车中的Bug?](http://bindog.github.io/blog/2015/03/30/use-formal-method-to-find-the-bug-in-timsort-and-lunar-rover/)
[3][Spark Architecture: Shuffle](http://0x0fff.com/spark-architecture-shuffle/)
[4][Spark Sort Based Shuffle内存分析](http://www.jianshu.com/p/c83bb237caa8)
[5][Spark Shuffle Write阶段磁盘文件分析](http://www.jianshu.com/p/2d837bf2dab6)
Spark Shuffle之Sort Shuffle的更多相关文章
- Spark Shuffle之Hash Shuffle
源文件放在github,如有谬误之处,欢迎指正.原文链接https://github.com/jacksu/utils4s/blob/master/spark-knowledge/md/hash-sh ...
- Spark Shuffle原理、Shuffle操作问题解决和参数调优
摘要: 1 shuffle原理 1.1 mapreduce的shuffle原理 1.1.1 map task端操作 1.1.2 reduce task端操作 1.2 spark现在的SortShuff ...
- Spark技术内幕:Shuffle的性能调优
通过上面的架构和源码实现的分析,不难得出Shuffle是Spark Core比较复杂的模块的结论.它也是非常影响性能的操作之一.因此,在这里整理了会影响Shuffle性能的各项配置.尽管大部分的配置项 ...
- 【Spark调优】Shuffle原理理解与参数调优
[生产实践经验] 生产实践中的切身体会是:影响Spark性能的大BOSS就是shuffle,抓住并解决shuffle这个主要原因,事半功倍. [Shuffle原理学习笔记] 1.未经优化的HashSh ...
- Spark性能优化:shuffle调优
调优概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO.序列化.网络数据传输等操作.因此,如果要让作业的性能更上一层楼,就有必要对shuffle过程进行 ...
- Add, remove, shuffle and sort
To deal cards, we would like a method that removes a card from the deck and returns it. The list met ...
- Partitioning, Shuffle and sort
Partitioning, Shuffle and sort what happened? - Partitioning Partitioning is the process of determi ...
- Hadoop-2.2.0中文文档—— MapReduce下一代- 可插入的 Shuffle 和 Sort
简单介绍 可插入的 shuffle 和 sort 功能,同意在shuffle 和 sort 逻辑中用可选择的实现类替换.这个情况的样例是:用一个不是HTTP的应用协议,如RDMA来 shuffle 从 ...
- shuffle和sort分析
MapReduce中的Shuffle和Sort分析 MapReduce 是现今一个非常流行的分布式计算框架,它被设计用于并行计算海量数据.第一个提出该技术框架的是Google 公司,而Google 的 ...
随机推荐
- PHP的strtotime()函数2038年bug问题
最近在开发一个订单查询模块的时候,想当然的写了个2099年的日期,结果PHP返回了空值,肯定是发生溢出错误了,搜索了网上,发现下面这篇文章,但是我的问题依然没有解决,要怎么得到2038年以后的时间戳呢 ...
- python 数据类型、进制转换
数据类型 存储单位 最小单位是bit,表示二进制的0或1,一般写作b 最小的存储单位是字节,用byte表示,1B = 8b 1024B = 1KB 1024KB = 1MB 1024MB = 1GB ...
- Go语言中结构体的使用-第2部分OOP
1 概述 结构体的基本语法请参见:Go语言中结构体的使用-第1部分结构体.结构体除了是一个复合数据之外,还用来做面向对象编程.Go 语言使用结构体和结构体成员来描述真实世界的实体和实体对应的各种属性. ...
- # 2017-2018-1 20155232《信息安全技术》实验二——Windows口令破解
2017-2018-1 20155232<信息安全技术>实验二--Windows口令破解 [实验目的] 了解Windows口令破解原理 对信息安全有直观感性认识 能够运用工具实现口令破解 ...
- PANIC: HOME is defined but could not find Nexus_4_API_22.ini file in $HOME/.android/avd (Note: avd is searched in the order of $ANDROID_AVD_HOME,$ANDROID_SDK_HOME/.android/avd and $HOME/.android/avd)
sudo cp /root/.android/avd/*.ini $Home/.android/avd/ sudo cp -r /root/.android/avd/*.avd $Home/.a ...
- MySQL入门篇(四)之MySQL主从复制
一.MySQL主从复制原理 随机站点访问量的鞥集啊,单台的MySQL服务器压力也不断地增加,此时需要对MySQL进行优化,如果在MySQL优化无明显改善时期,可以使用高可用.主从复制.读写分离.分库分 ...
- idea alt+enter导包时被锁定导某一个包时的解决方法
在只有一个包指向的时候,把光标放在Test这种字符之间的话 就会直接导这个 所以把光标放在最后就可以导别的了
- Django模型层:多表查询
一 创建模型 实例:我们来假定下面这些概念,字段和关系 作者模型:一个作者有姓名和年龄. 作者详细模型:把作者的详情放到详情表,包含生日,手机号,家庭住址等信息.作者详情模型和作者模型之间是一对一的关 ...
- php-laravel中间件使用
中间件使用 1.项目目录下cmd中php artisan make:middleware adminLogin,创建中间件 2.注册中间件(\Http\kernel.php) protected $r ...
- WebAPI学习笔记
WebAPI WebApi是添加到Asp.Net平台的一个新特性,可以快速的创建Web服务,并对客户端提供HTTP的API调用接口 WebApi是建立在MVC框架基础之上,但不属于MVC的一部分. 序 ...