论SparkStreaming的数据可靠性和一致性
转自:
http://www.csdn.net/article/2015-06-21/2825011
摘要:眼下大数据领域最热门的词汇之一便是流计算了,而其中最耀眼的无疑是来自Spark社区的SparkStreaming项目。 对于流计算而言,最核心的特点毫无疑问就是它对低时的需求,但这也带来了相关的数据可靠性问题。
2Driver HA
由于流计算系统是长期运行、且不断有数据流入,因此其Spark守护进程(Driver)的可靠性至关重要,它决定了Streaming程序能否一直正确地运行下去。
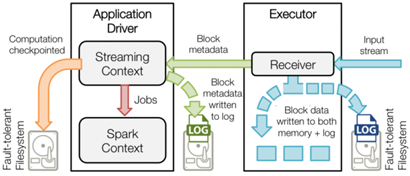
Driver实现HA的解决方案就是将元数据持久化,以便重启后的状态恢复。如图一所示,Driver持久化的元数据包括:
Block元数据(图1中的绿色箭头):Receiver从网络上接收到的数据,组装成Block后产生的Block元数据;
Checkpoint数据(图1中的橙色箭头):包括配置项、DStream操作、未完成的Batch状态、和生成的RDD数据等;
Driver失败重启后:
恢复计算(图2中的橙色箭头):使用Checkpoint数据重启driver,重新构造上下文并重启接收器。
恢复元数据块(图2中的绿色箭头):恢复Block元数据。
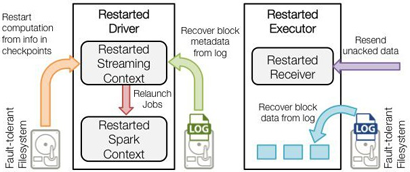
恢复未完成的作业(图2中的红色箭头):使用恢复出来的元数据,再次产生RDD和对应的job,然后提交到Spark集群执行。
通过如上的数据备份和恢复机制,Driver实现了故障后重启、依然能恢复Streaming任务而不丢失数据,因此提供了系统级的数据高可靠。
可靠的上下游IO系统
流计算主要通过网络socket通信来实现与外部IO系统的数据交互。由于网络通信的不可靠特点,发送端与接收端需要通过一定的协议来保证数据包的接收确认和失败重发机制。
不是所有的IO系统都支持重发,这至少需要实现数据流的持久化,同时还要实现高吞吐和低时延。在SparkStreaming官方支持的data source里面,能同时满足这些要求的只有Kafka,因此在最近的SparkStreaming release里面,也是把Kafka当成推荐的外部数据系统。
除了把Kafka当成输入数据源(inbound data source)之外,通常也将其作为输出数据源(outbound data source)。所有的实时系统都通过Kafka这个MQ来做数据的订阅和分发,从而实现流数据生产者和消费者的解耦。
一个典型的企业大数据中心数据流向视图如图3所示:
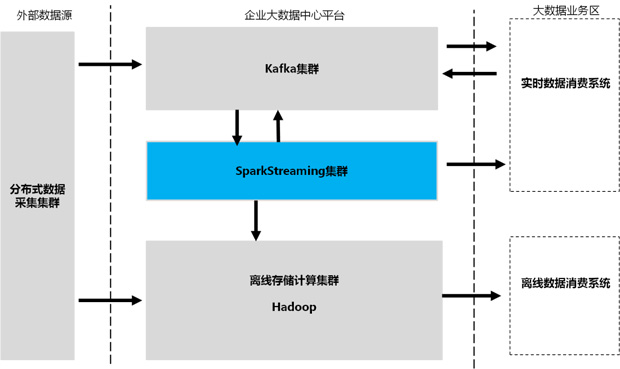
除了从源头保证数据可重发之外,Kafka更是流数据Exact Once语义的重要保障。Kafka提供了一套低级API,使得client可以访问topic数据流的同时也能访问其元数据。SparkStreaming每个接收的任务都可以从指定的Kafka topic、partition和offset去获取数据流,各个任务的数据边界很清晰,任务失败后可以重新去接收这部分数据而不会产生“重叠的”数据,因而保证了流数据“有且仅处理一次”。
可靠的接收器
在Spark 1.3版本之前,SparkStreaming是通过启动专用的Receiver任务来完成从Kafka集群的数据流拉取。
Receiver任务启动后,会使用Kafka的高级API来创建topicMessageStreams对象,并逐条读取数据流缓存,每个batchInerval时刻到来时由JobGenerator提交生成一个spark计算任务。
由于Receiver任务存在宕机风险,因此Spark提供了一个高级的可靠接收器-ReliableKafkaReceiver类型来实现可靠的数据收取,它利用了Spark 1.2提供的WAL(Write Ahead Log)功能,把接收到的每一批数据持久化到磁盘后,更新topic-partition的offset信息,再去接收下一批Kafka数据。万一Receiver失败,重启后还能从WAL里面恢复出已接收的数据,从而避免了Receiver节点宕机造成的数据丢失(以下代码删除了细枝末节的逻辑):

启用WAL后,虽然Receiver的数据可靠性风险降低了,但却由于磁盘持久化带来的开销,系统整体吞吐率会明显下降。因此,最新发布的Spark 1.3版本,SparkStreaming增加了使用Direct API的方式来实现Kafka数据源的访问。
引入了Direct API后,SparkStreaming不再启动常驻的Receiver接收任务,而是直接分配给每个Batch及RDD最新的topic partition offset。job启动运行后Executor使用Kafka的simple consumer API去获取那一段offset的数据。
这样做的好处不仅避免了Receiver宕机带来数据可靠性的风险,也由于避免使用ZooKeeper做offset跟踪,而实现了数据的精确一次性(以下代码删除了细枝末节的逻辑):

预写日志 Write Ahead Log
Spark 1.2开始提供预写日志能力,用于Receiver数据及Driver元数据的持久化和故障恢复。WAL之所以能提供持久化能力,是因为它利用了可靠的HDFS做数据存储。
SparkStreaming预写日志机制的核心API包括:
管理WAL文件的WriteAheadLogManager
读/写WAL的WriteAheadLogWriter和WriteAheadLogReader
基于WAL的RDD:WriteAheadLogBackedBlockRDD
基于WAL的Partition:WriteAheadLogBackedBlockRDDPartition
以上核心API在数据接收和恢复阶段的交互示意图如图4所示。

从WriteAheadLogWriter的源码里可以清楚看到,每次写入一块数据buffer到HDFS后都会调用flush方法去强制刷入磁盘,然后才去取下一块数据。因此receiver接收的数据是可以保证持久化到磁盘了,因而做到较好的数据可靠性。

结束语
得益于Kafka这类可靠的data source以及自身的checkpoint/WAL等机制,SparkStreaming的数据可靠性得到了很好的保证,数据能保证“至少一次”(at least once)被处理。但由于其outbound端的一致性实现还未完善,因此Exact once语义仍然不能端到端保证。SparkStreaming社区已经在跟进这个特性的实现(SPARK-4122),预计很快将合入trunk发布。
论SparkStreaming的数据可靠性和一致性的更多相关文章
- Kafka数据可靠性与一致性解析
Partition Recovery机制 每个Partition会在磁盘记录一个RecoveryPoint, 记录已经flush到磁盘的最大offset.broker fail 重启时,会进行load ...
- Kafka数据可靠性深度解读
原文链接:http://www.infoq.com/cn/articles/depth-interpretation-of-kafka-data-reliability Kafka起初是由Linked ...
- 【Kafka】Kafka数据可靠性深度解读
转帖:http://www.infoq.com/cn/articles/depth-interpretation-of-kafka-data-reliability Kafka起初是由LinkedIn ...
- kafka数据可靠性深度解读【转】
1 概述 Kakfa起初是由LinkedIn公司开发的一个分布式的消息系统,后成为Apache的一部分,它使用Scala编写,以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cl ...
- kafka如何保证数据可靠性和数据一致性
数据可靠性 Kafka 作为一个商业级消息中间件,消息可靠性的重要性可想而知.本文从 Producter 往 Broker 发送消息.Topic 分区副本以及 Leader 选举几个角度介绍数据的可靠 ...
- Storm的数据可靠性(理论)
Storm的数据可靠性(理论) .note-content {font-family: "Helvetica Neue",Arial,"Hiragino Sans GB& ...
- Oracle的数据并发与一致性详解(下)
上篇介绍了数据并发与一致性的相关概念.以及oracle的事务隔离级别等内容,本篇继续介绍锁机制.自动锁.手动锁.用户自定义锁的相关内容. 请尊重作者劳动成果,转载请标明原文链接: https://ww ...
- Oracle的数据并发与一致性详解(上)
今天想了解下oracle中事务与锁的原理,但百度了半天,发现网上介绍的内容要么太短,要么版本太旧,而且抄袭现象严重,所以干脆查官方帮助文档(oracle 11.2),并将其精华整理成中文,供大家一起学 ...
- 大数据学习day34---spark14------1 redis的事务(pipeline)测试 ,2. 利用redis的pipeline实现数据统计的exactlyonce ,3 SparkStreaming中数据写入Hbase实现ExactlyOnce, 4.Spark StandAlone的执行模式,5 spark on yarn
1 redis的事务(pipeline)测试 Redis本身对数据进行操作,单条命令是原子性的,但事务不保证原子性,且没有回滚.事务中任何命令执行失败,其余的命令仍会被执行,将Redis的多个操作放到 ...
随机推荐
- php 文件上传,下载
文件下载: html: <html> <body> <a href="1.rar">下载1.rar</a> <br /> ...
- 乙醇的webdriver实用指南ruby版本
webdriver实用指南是乙醇2013年分享计划的一部分,作为对已逝去的selenium2时代的追忆. 目录如下 启动浏览器 关闭浏览器 浏览器最大化 设置浏览器大小 访问链接 打印当前页面的tit ...
- Nginx访问PHP文件的File not found错误处理,两种情况
这个错误很常见,原有有下面两种几种 1. php-fpm找不到SCRIPT_FILENAME里执行的php文件 2. php-fpm不能访问所执行的php,也就是权限问题 第一种情况 可以在你的loc ...
- Win8.1的IE11无法打开,必须使用管理员身份运行
不知道大家有没有遇到这种情况,在毫不知情的情况下 IE11 突然打不开了,必须要用管理员身份运行才可以打开,而且重置浏览器这个方法也不奏效. 今天本人也遇到了,上网查找发现是注册表权限的问题,原因尚不 ...
- MFC程序开始的执行过程详述
1)我们知道在WIN32API程序当中,程序的入口为WinMain函数,在这个函数当中我们完成注册窗口类,创建窗口,进入消息循环,最后由操作系统根据发送到程序窗口的消息调用程序的窗口函数.而在MFC程 ...
- Scala之集合Collection
概述 Scala的集合类能够从三个维度进行切分: 可变与不可变集合(Immutable and mutable collections) 静态与延迟载入集合 (Eager and delayed ev ...
- [cocos2dx笔记005]一个字符串管理配置类
在用vs开发cocos2dx过程中.要显示的中文,要求是UTF-8格式的才干正常显示出来.但VS通常是ANSI格式保存,这样,在代码中写入的中文字符串,执行后.显示的就是乱码. 为了正确显示中文.或支 ...
- ASP.NET MVC 入门9、Action Filter 与 内置的Filter实现(介绍)
原帖地址:http://www.cnblogs.com/QLeelulu/archive/2008/10/09/1307660.html 有时候你想在调用action方法之前或者action方法之后处 ...
- vue2.0的学习
vue-router 除了使用 <router-link> 创建 a 标签来定义导航链接,我们还可以借助 router 的实例方法,通过编写代码来实现. 1)router.push(loc ...
- ubuntu tftp 配置
1:sudo apt-get install tftp tftpd openbsd-inetd特别指出很多文章里用的是netkit-inetd,但是实际下载时发现这个软件是下不到的,特改用openbs ...