HDFS Namenode&Datanode
HDFS Namenode&Datanode
HDFS 机制粗略示意图
客户端写入文件流程:
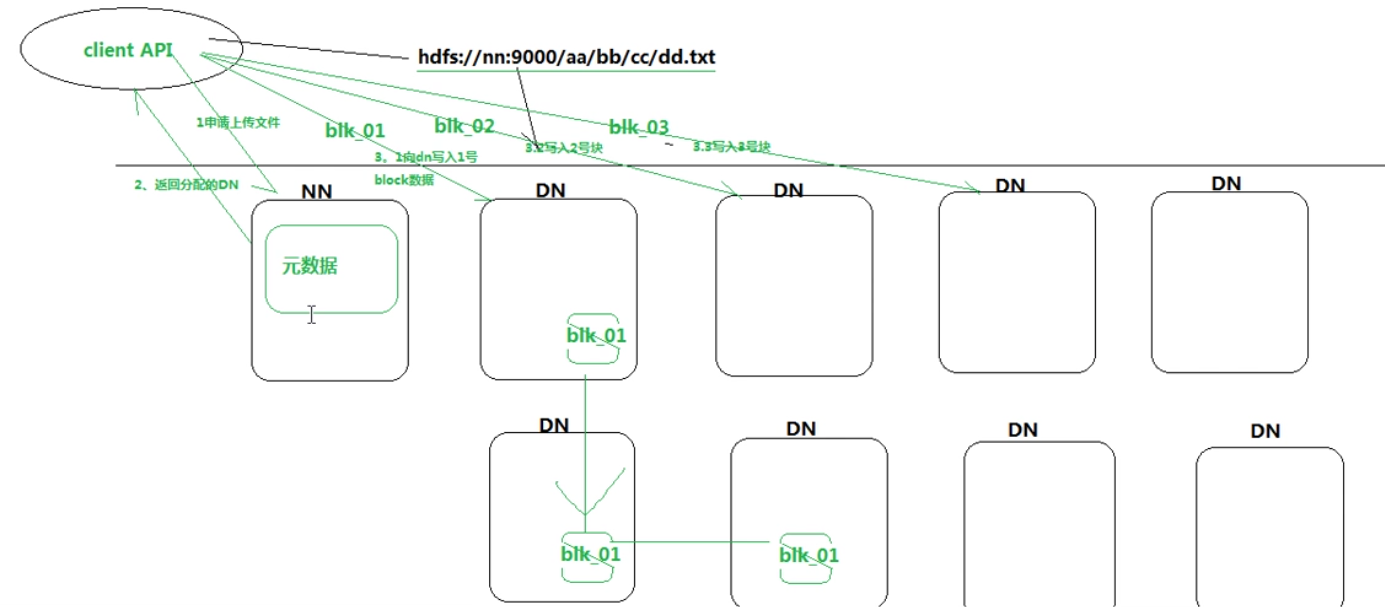
NN && DN
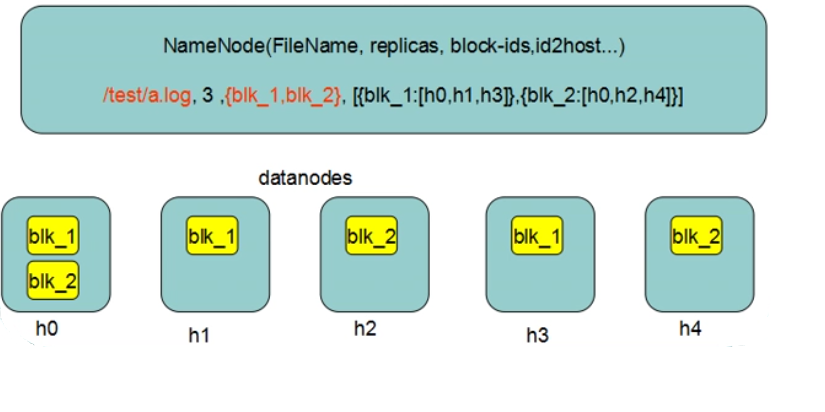
Namenode(NN)工作机制
NN是整个文件系统的管理节点。维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表(管理元数据)。接收用户的操作请求。
fsimage:元数据镜像文件。存储某一时段NN内存元数据信息
edits:操作日志文件
fstime:保存最近一次checkpoint的时间
(以上文件保存在linux文件系统中)
主流程
- 客户端上传文件时,NN首先往edits log文件中记录元数据操作日志
- 客户端开始上传文件,完成后返回成功信息给NN。NN就在内存中写入这次上传操作而新产生的元数据信息。既实现了客户端可以从内存中查询(读写速度比从磁盘快),又保证了可靠性(若断电内存中的信息丢失,则可以从edits log文件中找回)。
- 每当edits log写满时,由secondary namenode将这部分新的元数据合并到fsimage文件中(checkpoint操作)。
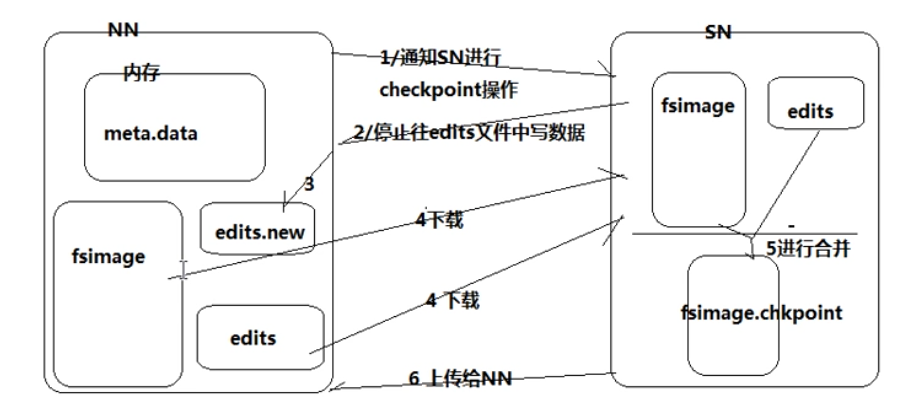
secondary namenode 的 checkpoint 操作
工作流程
- secondary通知namenode切换edits文件(改为写到edits.new)
- secondary从namenode获得fsimage和edits(通过http)
- secondary将fsimage载入内存,然后开始合并edits,产生新的fsimage
- secondary将新的fsimage发回给namenode
- namenode用新的fsimage替换旧的fsimage,并将edits.new重命名为edits
进行checkpoint的时间
- fs.checkpoint.period 指定两次checkpoint的间隔(默认3600秒)
- fs.chekpoint.size 规定edits文件的最大值,一旦超过则强制checkpoint,不管是否达到时间间隔(默认64M)
(以上可在hdfs-site.xml中设置)
Datanode(DN)工作原理
DN提供真实文件数据的存储服务。
文件块(block):最基本的存储单位。对于文件而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小顺序对文件进行划分并编号,划分好的每一块称一个block。
block的默认大小是128M,可以修改dfs.block.size参数进行更改
上传一个文件看看分块情况
上传 hadoop fs -put xxx(随便一个稍大一些的文件) /
打开datanode的数据文件夹 cd /app/hadoop-3.0.0/data/dfs/data/current/BP-1998331996-192.168.216.100-1521773499028/current/finalized/subdir0/subdir0
查看 du -sh *
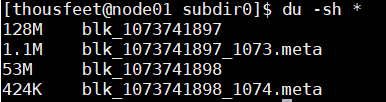
能看到被分作了两个block,其中一个正是128M。(.mate是校验和文件不是一个block)
HDFS Namenode&Datanode的更多相关文章
- hdfs namenode/datanode工作机制
一. namenode工作机制 1. 客户端上传文件时,namenode先检查有没有同名的文件,如果有,则直接返回错误信息.如果没有,则根据要上传文件的大小以及block的大小,算出需要分成几个blo ...
- 【Hadoop】hdfs的秘密,namenode,datanode,yarn,安全模式,fsimage,edits...
1.bin/hdfs namenode -format ** 注意事项 1.在配置好了配置文件之后,首次启动之前,做初始化操作 2.在后续启动的时候,不需要再初始化 3.初始化的一些影响 一.初始化操 ...
- Hadoop(五)—— HDFS NameNode、DataNode工作机制
一.NN与2NN工作机制 NameNode(NN) 1.当HDFS启动时,会加载日志(edits)和镜像文件(fsImage)到内存中. 2-4.当元数据的增删改查请求进来时,NameNode会先将操 ...
- HDFS NameNode 设计实现解析
接前文 分布式存储-HDFS 架构解析,我们总体分析了 HDFS 架构的主要构成组件包括:NameNode.DataNode 和 Client.本文首先进一步解析 HDFS NameNode 的设计和 ...
- NameNode & DataNode
NameNode类位于org.apache.hadoop.hdfs.server.namenode包下. NameNode serves as both directory namespace man ...
- 后端分布式系列:分布式存储-HDFS NameNode 设计实现解析
接前文 分布式存储-HDFS 架构解析,我们总体分析了 HDFS 架构的主要构成组件包括:NameNode.DataNode 和 Client.本文首先进一步解析 HDFS NameNode 的设计和 ...
- Hadoop:HDFS NameNode内存全景
原文转自:https://tech.meituan.com/namenode.html 感谢原作者 一.概述 从整个HDFS系统架构上看,NameNode是其中最重要.最复杂也是最容易出现问题的地方, ...
- Hadoop HDFS NameNode工作机制
Secondary namenode 首先,我们假设如果存储在Namenode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低.因此,元数据需要存放在内存中.但如果只存在内存中 ...
- 启动HDFS时datanode无法启动的坑
启动HDFS 启动hdfs,进入sbin目录,也可以执行./start-all.sh - $cd /app/hadoop/hadoop-2.2.0/sbin - $./start-dfs.sh 在此之 ...
随机推荐
- Spring @Transactional踩坑记
@Transactional踩坑记 总述 Spring在1.2引入@Transactional注解, 该注解的引入使得我们可以简单地通过在方法或者类上添加@Transactional注解,实现事务 ...
- Redis(1):入门
在Linux下安装redis: wget http://download.redis.io/redis-stable.tar.gz tax xzf redis-stable.tar.gz cd re ...
- java并发编程(4)性能与可伸缩性
性能与可伸缩性 一.Amdahl定律 1.问题和资源的关系 在某些问题中,资源越多解决速度越快:而有些问题则相反: 注意:每个程序中必然有串行的部分,而合理的分析出串行和并行的部分对程序的影响极大:串 ...
- XAMPP环境的搭建
XAMPP是一个强大的集成软件包(什么是集成软件包?就是多个软件打包一起安装了,比如office办公软件包括了word.Excel.PPT) XAMPP包括了Apache,MySQL,PHP,Perl ...
- Linux下一个最简单的不依赖第三库的的C程序(1)
如下代码是一段汇编代码,虽然标题中使用了C语言这个词语,但下面确实是一段汇编代码,弄清楚了这个代码,后续的知识点才会展开. simple_asm.s: #PURPOSE: Simple program ...
- 最简单,有效的学习mysql教程(一)
数据库 1 定义 数据库,可以简单的解释为:高效的存储和处理数据的介质(主要分为磁盘和内存两种). 2 分类 根据数据库存储介质的不同,可以将其分为两类,即:关系型数据库(SQL)和非关系型数据库(N ...
- express中间件笔记整理
expressexpress概念:express是基于nodejs的HTTPS模块构建出来的一个web应用开发框架,在nodejs之上扩展了 Web 应用所需的基本功能.本质上express应用就是调 ...
- DOM操作表单
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title>& ...
- js判断是手机还是PC端
有时接触一些手机上的适应,需要知道是pc 还是移动端 function IsPC() { var userAgentInfo = navigator.userAgent; var Agents = [ ...
- HBase性能优化方法总结
1. 表的设计 1.1 Pre-Creating Regions 默认情况下,在创建HBase表的时候会自动创建一个region分区,当导入数据的时候,所有的HBase客户端都向这一个region写数 ...