一起写一个JSON解析器
【本篇博文会介绍JSON解析的原理与实现,并一步一步写出来一个简单但实用的JSON解析器,项目地址:SimpleJSON。希望通过这篇博文,能让我们以后与JSON打交道时更加得心应手。由于个人水平有限,叙述中难免存在不准确或是不清晰的地方,希望大家可以指正:)】
一、JSON解析器介绍
相信大家在平时的开发中没少与JSON打交道,那么我们平常使用的一些JSON解析库都为我们做了哪些工作呢?这里我们以知乎日报API返回的JSON数据来介绍一下两个主流JSON解析库的用法。我们对地址 http://news-at.zhihu.com/api/4/news/latest进行GET请求,返回的JSON响应的整体结构如下:
{
date: "20140523",
stories: [
{
images:["http:\/\/pic1.zhimg.com\/4e7ecded780717589609d950bddbf95c.jpg"]
type: 0,
id: 3930445,
ga_prefix: "052321",
title: "中国古代家具发展到今天有两个高峰,一个两宋一个明末(多图)",
},
...
],
top_stories: [
{
image:"http:\/\/pic4.zhimg.com\/8f209bcfb5b6e0625ca808e43c0a0a73.jpg",
type:0,
id:8314043,
ga_prefix:"051717",
title:"怎样才能找到自己的兴趣所在,发自内心地去工作?"
},
...
]
}
以上JSON响应表示的是某天的最新知乎日报内容。顶层的date的值表示的是日期;stories的值是一个数组,数组的每个元素又包含images、type、id等域;top_stories的值也是一个数组,数组元素的结构与stories类似。我们先把把以上返回的JSON数据表示为一个model类:
public class LatestNews {
private String date;
private List<TopStory> top_stories;
private List<Story> stories;
//省略LatestNews类的getter与setter
public static class TopStory {
private String image;
private int type;
private int id;
private String title;
//省略TopStory类的getter与setter
}
public static class Story implements Serializable {
private List<String> images;
private int type;
private int id;
private String title;
//省略Story类的getter与setter
}
}
在以上的代码中,我们定义的域与返回的JSON响应的键一一对应。那么接下来我们就来完成JSON响应的解析吧。首先我们使用org.json包来完成JSON的解析。相关代码如下:
1 public class JSONParsingTest {
2 public static final String urlString = "http://news-at.zhihu.com/api/4/news/latest";
3 public static void main(String[] args) throws Exception {
4 try {
5 String jsonString = new String(HttpUtil.get(urlString));
6 JSONObject latestNewsJSON = new JSONObject(jsonString);
7 String date = latestNewsJSON.getString("date");
8 JSONArray top_storiesJSON = latestNewsJSON.getJSONArray("top_stories");
9 LatestNews latest = new LatestNews();
10
11
12 List<LatestNews.TopStory> stories = new ArrayList<>();
13
14 for (int i = 0; i < top_storiesJSON.length(); i++) {
15 LatestNews.TopStory story = new LatestNews.TopStory();
16 story.setId(((JObject) top_storiesJSON.get(i)).getInt("id"));
17 story.setType(((JObject) top_storiesJSON.get(i)).getInt("type"));
18 story.setImage(((JObject) top_storiesJSON.get(i)).getString("image"));
19 story.setTitle(((JObject) top_storiesJSON.get(i)).getString("title"));
20 stories.add(story);
21 }
22 latest.setDate(date);
23
24 System.out.println("date: " + latest.getDate());
25 for (int i = 0; i < stories.size(); i++) {
26 System.out.println(stories.get(i));
27 }
28
29 } catch (JSONException e) {
30 e.printStackTrace();
31 }
32 }
33
34 }
相信Android开发的小伙伴对org.json都不陌生,因为Android SDK中提供的JSON解析类库就是org.json,要是使用别的开发环境我们可能就需要手动导入org.json包。
第5行我们调用了HttpUtil.get方法来获取JSON格式的响应字符串,HttpUtil是我们封装的一个用于网络请求的静态代码库,代码见这里:
接着在第6行,我们以JSON字符串为参数构造了一个JSONObject对象;在第7行我们调用JSONObject的实例方法getString根据键名“date”获取了date对应的值并保存在了一个String变量中。
在第8行我们调用了JSONObject的getJSONArray方法来从JSONObject对象中获取一个JSON数组,这个JSON数组的每个元素均为JSONObject(代表了一个TopStory),每个JSONObject都可以通过在其上调用getInt、getString等方法获取type、title等键的值。正如我们在第14到21行所做的,我们通过一个循环读取JSONArray的每个JSONObject中的title、id、type、image域的值,并把他们写入TopStory对象的对应实例域。
我们可以看到,当返回的JSON响应结构比较复杂时,使用org.json包来解析响应比较繁琐。那么我们看看如何使用gson(Google出品的JSON解析库,被广泛应用于Android开发中)来完成相同的工作:
public class GsonTest {
public static final String urlString = "http://news-at.zhihu.com/api/4/news/latest";
public static void main(String[] args) {
LatestNews latest = new LatestNews();
String jsonString = new String(HttpUtil.get(urlString));
latest = (new Gson()).fromJson(jsonString, LatestNews.class);
System.out.println(latest.getDate());
for (int i = 0; i < latest.getTop_stories().size(); i++) {
System.out.println(latest.getTop_stories().get(i));
}
}
}
我们可以看到,使用gson完成同样的工作只需要一行代码。那么让我们一起来看一下gson是如何做到的。在上面的代码中,我们调用了Gson对象的fromJson方法,传入了返回的JSON字符串和Latest.class作为参数。看到Latest.class,我们就大概能够知道fromJson方法的内部工作机制了。可以通过反射获取到LatestNews的各个实例域,然后帮助我们读取并填充这些实例域。那么fromJson怎么知道我们要填充LatestNews的哪些实例域呢?实际上我们必须保证LatestNews的域的名字与JSON字符串中对应的键的名字相同,这样gson就能够把我们的model类与JSON字符串“一一对应“起来,也就是说我们要保证我们的model类与JSON字符串具有相同的层级结构,这样gson就可以根据名称从JSON字符串中为我们的实例域寻找一个对应的值。我们可以做个小实验:把LatestNews中TopStory的title实例域的名字改为title1,这时再只执行以上程序,会发现每个story的title1域均变为null了。
通过上面的介绍,我们感受到了JSON解析库带给我们的便利,接下来我们一起来实现org.json包提供给我们的基本JSON解析功能,然后再进一步尝试实现gson提供给我们的更方便快捷的JSON解析功能。
二、JSON解析基本原理
现在,假设我们没有任何现成的JSON解析库可用,我们要自己完成JSON的解析工作。JSON解析的工作主要分一下几步:
- 词法分析:这个过程把输入的JSON字符串分解为一系列词法单元(token)。比如以下JSON字符串:
{
"date" : 20160517,
"id" : 1
}经过词法分析后,会被分解为以下token:“{”、 ”date“、 “:”、 “20160517”、 “,"、 “id”、 “:”、 “1”、 “}”。
- 语法分析:这一过程的输入是上一步得到的token序列。语法分析这一阶段完成的工作是把token构造成抽象语法单元。对于JSON的解析,这里的抽象语法对象就类似于org.json包中的JSONObject和JSONArray等。有了抽象语法对象,我们就可以进一步把它“映射到”Java数据类型。
实际上,在进行词法分析之前,JSON数据对计算机来说只是一个没有意义的字符串而已。词法分析的目的是把这些无意义的字符串变成一个一个的token,而这些token有着自己的类型和值,所以计算机能够区分不同的token,还能以token为单位解读JSON数据。接下来,语法分析的目的就是进一步处理token,把token构造成一棵抽象语法树(Abstract Syntax Tree)(这棵树的结点是我们上面所说的抽象语法对象)。比如上面的JSON数据我们经过词法分析后得到了一系列token,然后我们把这些token作为语法分析的输入,就可以构造出一个JSONObject对象(即只有一个结点的抽象语法树),这个JSONObject对象有date和id两个实例域。下面我们来分别介绍词法分析与语法分析的原理和实现。
1. 词法分析
JSON字符串中,一共有几种token呢?根据http://www.json.org/对JSON格式的相关定义,我们可以把token分为以下类型:
- STRING(字符串字面量)
- NUMBER(数字字面量)
- NULL(null)
- START_ARRAY([)
- END_ARRAY(])
- START_OBJ({)
- END_OBJ(})
- COMMA(,)
- COLON(:)
- BOOLEAN(true或者false)
- END_DOC(表示JSON数据的结束)
我们可以定义一个枚举类型来表示不同的token类型:
public enum TokenType {
START_OBJ, END_OBJ, START_ARRAY, END_ARRAY, NULL, NUMBER, STRING, BOOLEAN, COLON, COMMA, END_DOC
}
然后,我们还需要定义一个Token类用于表示token:
public class Token {
private TokenType type;
private String value;
public Token(TokenType type, String value) {
this.type = type;
this.value = value;
}
public TokenType getType() {
return type;
}
public String getValue() {
return value;
}
public String toString() {
return getValue();
}
}
在这之后,我们就可以开始写词法分析器了,词法分析器通常被称为lexer或是tokenizer。我们可以使用DFA(确定有限状态自动机)来实现tokenizer,也可以直接使用使用Java的regex包。这里我们使用DFA来实现tokenizer。
实现词法分析器(tokenizer)和语法分析器(parser)的依据都是JSON文法,完整的JSON文法如下(来自https://www.zhihu.com/question/24640264/answer/80500016):
object = {} | { members }
members = pair | pair , members
pair = string : value
array = [] | [ elements ]
elements = value | value , elements
value = string | number | object | array | true | false | null
string = "" | " chars "
chars = char | char chars
char = any-Unicode-character-except-"-or-\-or- control-character | \" | \\ | \/ | \b | \f | \n | \r | \t | \u four-hex-digits
number = int | int frac | int exp | int frac exp
int = digit | digit1-9 digits | - digit | - digit1-9 digits
frac = . digits
exp = e digits
digits = digit | digit digits
e = e | e+ | e- | E | E+ | E-
现在,我们就可以根据JSON的文法来构造DFA了,核心代码如下:
private Token start() throws Exception {
c = '?';
Token token = null;
do { //先读一个字符,若为空白符(ASCII码在[0, 20H]上)则接着读,直到刚读的字符非空白符
c = read();
} while (isSpace(c));
if (isNull(c)) {
return new Token(TokenType.NULL, null);
} else if (c == ',') {
return new Token(TokenType.COMMA, ",");
} else if (c == ':') {
return new Token(TokenType.COLON, ":");
} else if (c == '{') {
return new Token(TokenType.START_OBJ, "{");
} else if (c == '[') {
return new Token(TokenType.START_ARRAY, "[");
} else if (c == ']') {
return new Token(TokenType.END_ARRAY, "]");
} else if (c == '}') {
return new Token(TokenType.END_OBJ, "}");
} else if (isTrue(c)) {
return new Token(TokenType.BOOLEAN, "true"); //the value of TRUE is not null
} else if (isFalse(c)) {
return new Token(TokenType.BOOLEAN, "false"); //the value of FALSE is null
} else if (c == '"') {
return readString();
} else if (isNum(c)) {
unread();
return readNum();
} else if (c == -1) {
return new Token(TokenType.END_DOC, "EOF");
} else {
throw new JsonParseException("Invalid JSON input.");
}
}
我们可以看到,tokenizer的核心代码十分简洁,因为我们把一些稍繁杂的处理逻辑都封装在了一个个方法中,比如上面的readNum方法、readString方法等。
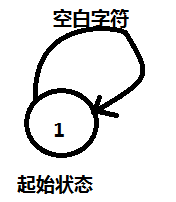
以上代码的第4到第6行的功能是消耗掉开头的所有空白字符(如space、tab等),直到读取到一个非空白字符,isSpace方法用于判断一个字符是否属于空白字符。也就是说,DFA从起始状态开始,若读到一个空字符,会在起始状态不断循环,直到遇到非空字符,状态转移情况如下:
接下来我们可以看到从代码的第7行到第33行是一个if语句块,外层的所有if分支覆盖了DFA的所有可能状态。在第7行我们会判断读入的是不是“null”,isNull方法的代码如下:
private boolean isNull(int c) throws IOException {
if (c == 'n') {
c = read();
if (c == 'u') {
c = read();
if (c == 'l') {
c = read();
if (c == 'l') {
return true;
} else {
throw new JsonParseException("Invalid JSON input.");
}
} else {
throw new JsonParseException("Invalid JSON input.");
}
} else {
throw new JsonParseException("Invalid JSON input.");
}
} else {
return false;
}
}
也就是说,当第一个非空字符为'n'时,我们会判断下一个是否为‘u',接着判断下面的是不是'u'、’l',这中间任何一步的判断结果为否,就说明我们遇到了一个非法关键字(比如null拼写错误,拼成了noll,这就是非法关键字),就会抛出异常,只有我们依次读取的4个字符分别为'n'、'u'、'l'、'l'时,isNull方法才会返回true。下面出现的isTrue、isFalse分别用来判断“true”和“false”,具体实现与isNull类似。
现在让我们回到以上的代码,接着看从第9行到第20行,我们会根据下一个字符的不同转移到不同的状态。若下一个字符为’{'、 '}'、 '['、 ']'、 ':'、 ','等6种中的一个,则DFA运行停止,此时我们构造一个新的相应类型的Token对象,并直接返回这个token,作为DFA本次运行的结果。这几个状态转移的示意图如下:

上图中圆圈中的数字仅仅表示状态的标号,我们仅画出了下一个字符分别为'{'、'['、':'时的状态转移(省略了3种情况)。
接下来,让我们看第25行到第26行的代码。这部分代码的主要作用是读取一个由双引号包裹的字符串字面量并构造一个TokenType为STRING的Token对象。若刚读取到的字符为双引号,意味着接下来的是一个字符串字面量,所以我们调用readString方法来读入一个字符串变量。readString方法的代码如下:
private Token readString() throws IOException {
StringBuilder sb = new StringBuilder();
while (true) {
c = read();
if (isEscape()) { //判断是否为\", \\, \/, \b, \f, \n, \t, \r.
if (c == 'u') {
sb.append('\\' + (char) c);
for (int i = 0; i < 4; i++) {
c = read();
if (isHex(c)) {
sb.append((char) c);
} else {
throw new JsonParseException("Invalid Json input.");
}
}
} else {
sb.append("\\" + (char) c);
}
} else if (c == '"') {
return new Token(TokenType.STRING, sb.toString());
} else if (c == '\r' || c == '\n'){
throw new JsonParseException("Invalid JSON input.");
} else {
sb.append((char) c);
}
}
}
我们来看一下readString方法的代码。第3到26行是一个无限循环,退出循环的条件有两个:一个是又读取到一个双引号(意味着字符串的结束),第二个条件是读取到了非法字符('\r'或’、'\n')。第5行的功能是判断刚读取的字符是否是转义字符的开始,isEscape方法的代码如下:
private boolean isEscape() throws IOException {
if (c == '\\') {
c = read();
if (c == '"' || c == '\\' || c == '/' || c == 'b' ||
c == 'f' || c == 'n' || c == 't' || c == 'r' || c == 'u') {
return true;
} else {
throw new JsonParseException("Invalid JSON input.");
}
} else {
return false;
}
}
我们可以看到这个方法是用来判断接下来的输入流中是否为以下字符组合:\", \\, \/, \b, \f, \n, \t, \r, \uhhhh(hhhh表示四位十六进制数)。若是以上几种中的一个,我们会接着判断是不是“\uhhhh“,并对他进行特殊处理,如readString方法的第7到15行所示,实际上就是先把'\u'添加到StringBuilder对象中,在依次读取它后面的4个字符,若是十六进制数字,则append,否则抛出异常。
现在让我们回到start方法,接着看第27到29行的代码,这两行代码用于读入一个数字字面量。isNum方法用于判断输入流中接下来的内容是否是数字字面量,这个方法的源码如下:
private boolean isNum(int c) {
return isDigit(c) || c == '-';
}
根据上面我们贴出的JSON文法,只有下一个字符为数字0~9或是'-',接下来的内容才可能是一个数字字面量,isDigit方法用于判断下一个字符是否是0~9这10个数字中的一个。
我们注意到第28行有一个unread方法调用,意味着我们下回调用read方法还是返回上回调用read方法返回的那个字符,为什么这么做我们看一下readNum方法的代码就知道了:
private Token readNum() throws IOException {
StringBuilder sb = new StringBuilder();
int c = read();
if (c == '-') { //-
sb.append((char) c);
c = read();
if (c == '0') { //-0
sb.append((char) c);
numAppend(sb);
} else if (isDigitOne2Nine(c)) { //-digit1-9
do {
sb.append((char) c);
c = read();
} while (isDigit(c));
unread();
numAppend(sb);
} else {
throw new JsonParseException("- not followed by digit");
}
} else if (c == '0') { //
sb.append((char) c);
numAppend(sb);
} else if (isDigitOne2Nine(c)) { //digit1-9
do {
sb.append((char) c);
c = read();
} while (isDigit(c));
unread();
numAppend(sb);
}
return new Token(TokenType.NUMBER, sb.toString()); //the value of 0 is null
}
我们来看一下第4到31行,外层的if语句有三种情况:分别对应着刚读取的字符为'-'、'0'和数字1~9中的一个。我们来看一下第5到9行的代码,对应了刚读取到的字符为'-'这种情况。这种情况表示这个数字字面量是个负数。然后我们再看这种情况下的内层if语句,共有两种情况,一是负号后面的字符为0,另一个是负号后面的字符为数字1~9中的一个。前者表示本次读取的数字字面量为-0(后面可以跟着frac或是exp),后者表示本次读取的字面量为负整数(后面也可以跟着frac或exp)。然后我们看第9行调用的numAppend方法,它的源码如下:
private void numAppend(StringBuilder sb) throws IOException {
c = read();
if (c == '.') { //int frac
sb.append((char) c); //apppend '.'
appendFrac(sb);
if (isExp(c)) { //int frac exp
sb.append((char) c); //append 'e' or 'E';
appendExp(sb);
}
} else if (isExp(c)) { // int exp
sb.append((char) c); //append 'e' or 'E'
appendExp(sb);
} else {
unread();
}
}
我们上面贴的JSON文法中对数字字面量的定义如下:
number = int | int frac | int exp | int frac exp
numAppend方法的功能就是在我们读取了数字字面量的int部分后,接着读取后面可能还有的frac或exp部分,上面的appendFrac方法用于读取frac部分,appendExp方法用于读取exp部分。具体的逻辑比较直接,大家直接看代码就可以了。( 这部分的处理逻辑是否正确未经过严格测试,如有错误希望大家可以指出,谢谢:) )
到了这里,tokenizer的核心——start()方法我们已经介绍的差不多了,tokenizer的完整代码请参考文章开头给出的链接,接下来让我们看一下如何实现JSON parser。
2. 语法分析
经过前一步的词法分析,我们已经得到了一个token序列,现在让我们来用这个序列构造出类似于org.json包的JSONObject与JSONArray对象。现在我们的任务就是编写一个语法分析器(parser),以词法分析得到的token序列为输入,产生JSONObject或是JSONArray抽象语法对象。语法分析的依据同样是上面我们贴出的JSON文法。
语法分析器依据JSON文法的以下部分实现:
object = {} | { members }
members = pair | pair , members
pair = string : value
array = [] | [ elements ]
elements = value | value , elements
value = string | number | object | array | true | false | null
具体代码如下:
public class Parser {
private Tokenizer tokenizer;
public Parser(Tokenizer tokenizer) {
this.tokenizer = tokenizer;
}
private JObject object() {
tokenizer.next(); //consume '{'
Map<String, Value> map = new HashMap<>();
if (isToken(TokenType.END_OBJ)) {
tokenizer.next(); //consume '}'
return new JObject(map);
} else if (isToken(TokenType.STRING)) {
map = key(map);
}
return new JObject(map);
}
private Map<String, Value> key(Map<String, Value> map) {
String key = tokenizer.next().getValue();
if (!isToken(TokenType.COLON)) {
throw new JsonParseException("Invalid JSON input.");
} else {
tokenizer.next(); //consume ':'
if (isPrimary()) {
Value primary = new Primary(tokenizer.next().getValue());
map.put(key, primary);
} else if (isToken(TokenType.START_ARRAY)) {
Value array = array();
map.put(key, array);
}
if (isToken(TokenType.COMMA)) {
tokenizer.next(); //consume ','
if (isToken(TokenType.STRING)) {
map = key(map);
}
} else if (isToken(TokenType.END_OBJ)) {
tokenizer.next(); //consume '}'
return map;
} else {
throw new JsonParseException("Invalid JSON input.");
}
}
return map;
}
private JArray array() {
tokenizer.next(); //consume '['
List<Json> list = new ArrayList<>();
JArray array = null;
if (isToken(TokenType.START_ARRAY)) {
array = array();
list.add(array);
if (isToken(TokenType.COMMA)) {
tokenizer.next(); //consume ','
list = element(list);
}
} else if (isPrimary()) {
list = element(list);
} else if (isToken(TokenType.START_OBJ)) {
list.add(object());
while (isToken(TokenType.COMMA)) {
tokenizer.next(); //consume ','
list.add(object());
}
} else if (isToken(TokenType.END_ARRAY)) {
tokenizer.next(); //consume ']'
array = new JArray(list);
return array;
}
tokenizer.next(); //consume ']'
array = new JArray(list);
return array;
}
private List<Json> element(List<Json> list) {
list.add(new Primary(tokenizer.next().getValue()));
if (isToken(TokenType.COMMA)) {
tokenizer.next(); //consume ','
if (isPrimary()) {
list = element(list);
} else if (isToken(TokenType.START_OBJ)) {
list.add(object());
} else if (isToken(TokenType.START_ARRAY)) {
list.add(array());
} else {
throw new JsonParseException("Invalid JSON input.");
}
} else if (isToken(TokenType.END_ARRAY)) {
return list;
} else {
throw new JsonParseException("Invalid JSON input.");
}
return list;
}
private Json json() {
TokenType type = tokenizer.peek(0).getType();
if (type == TokenType.START_ARRAY) {
return array();
} else if (type == TokenType.START_OBJ) {
return object();
} else {
throw new JsonParseException("Invalid JSON input.");
}
}
private boolean isToken(TokenType tokenType) {
Token t = tokenizer.peek(0);
return t.getType() == tokenType;
}
private boolean isToken(String name) {
Token t = tokenizer.peek(0);
return t.getValue().equals(name);
}
private boolean isPrimary() {
TokenType type = tokenizer.peek(0).getType();
return type == TokenType.BOOLEAN || type == TokenType.NULL ||
type == TokenType.NUMBER || type == TokenType.STRING;
}
public Json parse() throws Exception {
Json result = json();
return result;
}
}
我们先来看以上代码的第98到107行的json方法,这个方法可以作为语法分析的起点。它会根据第一个Token的类型是START_OBJ或START_ARRAY而选择调用object方法或是array方法。object方法会返回一个JObject对象(JSONObject),array方法会返回一个JArray对象(JSONArray)。JArray与JObject的定义如下:
public class JArray extends Json implements Value {
private List<Json> list = new ArrayList<>();
public JArray(List<Json> list) {
this.list = list;
}
public int length() {
return list.size();
}
public void add(Json element) {
list.add(element);
}
public Json get(int i) {
return list.get(i);
}
@Override
public Object value() {
return this;
}
public String toString() {
. . .
}
}
public class JObject extends Json {
private Map<String, Value> map = new HashMap<>();
public JObject(Map<String, Value> map) {
this.map = map;
}
public int getInt(String key) {
return Integer.parseInt((String) map.get(key).value());
}
public String getString(String key) {
return (String) map.get(key).value();
}
public boolean getBoolean(String key) {
return Boolean.parseBoolean((String) map.get(key).value());
}
public JArray getJArray(String key) {
return (JArray) map.get(key).value();
}
public String toString() {
. . .
}
}
JSON parser的逻辑也没有太复杂的地方,如果哪位同学不太理解,可以写一个test case跟着走几遍。
接下来,我们要进入有意思的部分了——实现类似org.json包的根据JSON字符串直接构造JSONObject与JSONArray。
3. parseJSONObject方法与parseJSONArray方法
基于以上的tokenizer与parser,我们可以实现两个实用的JSON解析方法,有了这两个方法,可以说我们就完成了一个基本的JSON解析库。
(1)parseJSONObject方法
该方法以一个JSON字符串为输入,返回一个JObject,代码如下:
public static JObject parseJSONObject(String jsonString) throws Exception {
Tokenizer tokenizer = new Tokenizer(new BufferedReader(new StringReader(jsonString)));
tokenizer.tokenize();
Parser parser = new Parser(tokenizer);
return parser.object();
}
(2)parseJSONArray方法
该方法以一个JSON字符串为输入,返回一个JArray,代码如下:
public static JObject parseJSONArray(String jsonString) throws Exception {
Tokenizer tokenizer = new Tokenizer(new BufferedReader(new StringReader(jsonString)));
tokenizer.tokenize();
Parser parser = new Parser(tokenizer);
return parser.array();
}
接下来,我们来测试以下这两个放究竟能不能用,test case如下:
public static void main(String[] args) throws Exception {
try {
String jsonString = new String(HttpUtil.get(urlString));
JObject latestNewsJSON = parseJSONObject(jsonString);
String date = latestNewsJSON.getString("date");
JArray top_storiesJSON = latestNewsJSON.getJArray("top_stories");
LatestNews latest = new LatestNews();
List<LatestNews.TopStory> stories = new ArrayList<>();
for (int i = 0; i < top_storiesJSON.length(); i++) {
LatestNews.TopStory story = new LatestNews.TopStory();
story.setId(((JObject) top_storiesJSON.get(i)).getInt("id"));
story.setType(((JObject) top_storiesJSON.get(i)).getInt("type"));
story.setImage(((JObject) top_storiesJSON.get(i)).getString("image"));
story.setTitle(((JObject) top_storiesJSON.get(i)).getString("title"));
stories.add(story);
}
latest.setDate(date);
System.out.println("date: " + latest.getDate());
for (int i = 0; i < stories.size(); i++) {
System.out.println(stories.get(i));
}
} catch (JSONException e) {
e.printStackTrace();
}
}
实际上,上面的代码只是把我们使用org.json包的代码稍作修改。然后我们可以得到了同使用org.json包一样的输出,这说明我们的JSON解析器工作正常。以上代码中的getInt方法与getString方法定义在JObject中,只需要根据要取得的值的类型做类型转换即可,具体实现可以参考开头给出的项目地址。接下来,让我们更上一层楼,实现一个类似与gson中fromJson方法的便捷方法。
4. fromJson方法的实现
这个方法的核心思想是:根据给定的JSON字符串和model类的class对象,通过反射获取model类的各个实例域的类型及名称。然后用java.lang.reflect包提供给我们的方法在运行时创建一个model类的对象,然后根据它的实例域的名称从JObject中获取相应的值并为model类对象的对应实例域赋值。若实例域为List<T>,我们需要特殊进行处理,这里我们实现了一个inflateList方法来处理这种情况。fromJson方法的代码如下:
public static <T> T fromJson(String jsonString, Class<T> classOfT) throws Exception {
Tokenizer tokenizer = new Tokenizer(new BufferedReader(new StringReader(jsonString)));
tokenizer.tokenize();
Parser parser = new Parser(tokenizer);
JObject result = parser.object();
Constructor<T> constructor = classOfT.getConstructor();
Object latestNews = constructor.newInstance();
Field[] fields = classOfT.getDeclaredFields();
int numField = fields.length;
String[] fieldNames = new String[numField];
String[] fieldTypes = new String[numField];
for (int i = 0; i < numField; i++) {
String type = fields[i].getType().getTypeName();
String name = fields[i].getName();
fieldTypes[i] = type;
fieldNames[i] = name;
}
for (int i = 0; i < numField; i++) {
if (fieldTypes[i].equals("java.lang.String")) {
fields[i].setAccessible(true);
fields[i].set(latestNews, result.getString(fieldNames[i]));
} else if (fieldTypes[i].equals("java.util.List")) {
fields[i].setAccessible(true);
JArray array = result.getJArray(fieldNames[i]);
ParameterizedType pt = (ParameterizedType) fields[i].getGenericType();
Type elementType = pt.getActualTypeArguments()[0];
String elementTypeName = elementType.getTypeName();
Class<?> elementClass = Class.forName(elementTypeName);
fields[i].set(latestNews, inflateList(array, elementClass));//类型捕获
} else if (fieldTypes[i].equals("int")) {
fields[i].setAccessible(true);
fields[i].set(latestNews, result.getInt(fieldNames[i]));
}
}
return (T) latestNews;
}
在第8行,我们构造了一个LatestNews对象。在第9到18行,我们获取了LatestNews类的所有实例域,并把它们的名称存在了String数组fieldNames中,把它们的类型存在了String数组fieldTypes中。然后在第19到36行,我们遍历Field数组fields,对每个实例域进行赋值。若实例域的类型为int或是String或是primitive types(int、double等基本类型),则直接调用set方法对相应实例域赋值(简单起见,上面只实现了对String类型实例域的处理,对于primitive types的处理与之类似,感兴趣的同学可以自己尝试实现下);若实例域的类型为List,则我们需要为这个List中的每个元素赋值。在第26到29行,我们获取了List中存储的元素的类型名称,然后根据这个名称获取了对应的class对象。在第30行,我们调用了inflateList方法来“填充“这个List,这里存在一个”类型捕获“,具体来说,就是inflateList方法接收的第2个参数Class<T>中的类型参数T捕获了List中存储元素的实际类型(第29行我们获取了这个实际类型并用类型通配符接收了它)。inflateList方法的代码如下:
public static <T> List<T> inflateList(JArray array, Class<T> clz) throws Exception {
int size = array.length();
List<T> list = new ArrayList<T>();
Constructor<T> constructor = clz.getConstructor();
String className = clz.getName();
if (className.equals("java.lang.String")) {
for (int i = 0; i < size; i++) {
String element = (String) ((Primary) array.get(i)).value();
list.add((T) element);
return list;
}
}
Field[] fields = clz.getDeclaredFields();
int numField = fields.length;
String[] fieldNames = new String[numField];
String[] fieldTypes = new String[numField];
for (int i = 0; i < numField; i++) {
String type = fields[i].getType().getTypeName();
String name = fields[i].getName();
fieldTypes[i] = type;
fieldNames[i] = name;
}
for (int i = 0; i < size; i++) {
T element = constructor.newInstance();
JObject object = (JObject) array.get(i);
for (int j = 0; j < numField; j++) {
if (fieldTypes[j].equals("java.lang.String")) {
fields[j].setAccessible(true);
fields[j].set(element, (object.getString(fieldNames[j])));
} else if (fieldTypes[j].equals("java.util.List")) {
fields[j].setAccessible(true);
JArray nestArray = object.getJArray(fieldNames[j]);
ParameterizedType pt = (ParameterizedType) fields[j].getGenericType();
Type elementType = pt.getActualTypeArguments()[0];
String elementTypeName = elementType.getTypeName();
Class<?> elementClass = Class.forName(elementTypeName);
String value = null;
fields[j].set(element, inflateList(nestArray, elementClass));//Type Capture
} else if (fieldTypes[j].equals("int")) {
fields[j].setAccessible(true);
fields[j].set(element, object.getInt(fieldNames[j]));
}
}
list.add(element);
}
return list;
}
在这个方法中,我们会根据对JSON解析获取的JArray所含的元素个数,以及我们之前获取到的元素的类型,构造相应数目的对象,并添加到list中去。具体的执行过程大家可以参考代码,逻辑比较直接。
需要注意的是以上代码的第7到13行,它的意思是若列表的元素类型为String,我们就应直接从相应的JArray中获取元素并添加到list中,然后直接返回list。实际上,对于primitive types我们都应该做相似处理,简单起见,这里只对String类型做了处理,其他primitive types的处理方式类似。
接下来测试一下我们实现的fromJson方法是否能如我们预期那样工作,test case还是解析上面的知乎日报API返回的数据:
public class SimpleJSONTest {
public static final String urlString = "http://news-at.zhihu.com/api/4/news/latest";
public static void main(String[] args) throws Exception {
LatestNews latest = new LatestNews();
String jsonString = new String(HttpUtil.get(urlString));
latest = Parser.fromJson(jsonString, LatestNews.class);
System.out.println(latest.getDate());
for (int i = 0; i < latest.getTop_stories().size(); i++) {
System.out.println(latest.getTop_stories().get(i));
}
}
}
我们还可以对比一下我们的实现与gson的实现的性能,我这里测试的结果是SimpleJSON的速度大约是gson速度的三倍,考虑到我们的SimpleJSON在不少地方”偷懒“了,这个测试结果并不能说明我们的实现性能要优于gson,不过这或许可以说明我们的JSON解析库还是具备一定的实用性...
由于本篇博文重点在介绍一个JSON解析器的实现思路,在具体实现上很多部分做的并不好。比如没有做足够多的测试来验证JSON解析的正确性,业务逻辑上也尽量使用直接的方式,许多地方没使用更加高效的实现,另外在抛出异常方面也比较随便,“一言不合”就抛异常...由于个人水平有限,代码中难免存在谬误,希望大家多多包涵,更希望可以指出不足之处,谢谢大家:)
三、参考资料
2. https://www.zhihu.com/question/24640264/answer/80500016
3. http://docs.oracle.com/javase/specs/jls/se8/jls8.pdf
4. 《Java核心技术(卷一)》
一起写一个JSON解析器的更多相关文章
- 几百行代码实现一个 JSON 解析器
前言 之前在写 gscript时我就在想有没有利用编译原理实现一个更实际工具?毕竟真写一个语言的难度不低,并且也很难真的应用起来. 一次无意间看到有人提起 JSON 解析器,这类工具充斥着我们的日常开 ...
- 如何编写一个JSON解析器
编写一个JSON解析器实际上就是一个函数,它的输入是一个表示JSON的字符串,输出是结构化的对应到语言本身的数据结构. 和XML相比,JSON本身结构非常简单,并且仅有几种数据类型,以Java为例,对 ...
- java 写一个JSON解析的工具类
上面是一个标准的json的响应内容截图,第一个红圈”per_page”是一个json对象,我们可以根据”per_page”来找到对应值是3,而第二个红圈“data”是一个JSON数组,而不是对象,不能 ...
- Python+Flask+Gunicorn 项目实战(一) 从零开始,写一个Markdown解析器 —— 初体验
(一)前言 在开始学习之前,你需要确保你对Python, JavaScript, HTML, Markdown语法有非常基础的了解.项目的源码你可以在 https://github.com/zhu-y ...
- 一个JSON解析器
来源 <JavaScript语言精粹(修订版)> 代码 <!DOCTYPE html> <html> <head> <meta charset=& ...
- 自己动手实现一个简单的JSON解析器
1. 背景 JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式.相对于另一种数据交换格式 XML,JSON 有着诸多优点.比如易读性更好,占用空间更少等.在 ...
- 面试题|手写JSON解析器
这周的 Cassidoo 的每周简讯有这么一个面试题:: 写一个函数,这个函数接收一个正确的 JSON 字符串并将其转化为一个对象(或字典,映射等,这取决于你选择的语言).示例输入: fakePars ...
- 手写Json解析器学习心得
一. 介绍 一周前,老同学阿立给我转了一篇知乎回答,答主说检验一门语言是否掌握的标准是实现一个Json解析器,网易游戏过去的Python入门培训作业之一就是五天时间实现一个Json解析器. 知乎回答- ...
- 用c#自己实现一个简单的JSON解析器
一.JSON格式介绍 JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式.相对于另一种数据交换格式 XML,JSON 有着很多优点.例如易读性更好,占用空间更 ...
随机推荐
- GlassFish: 001 安装、启动
安装 在GlassFish项目的首页就可以找到如何安装: https://glassfish.java.net/download.html#gfoseTab 上面给出了5个步骤:0,1,2,3,4 第 ...
- Activiti之 Exclusive Gateway
一.Exclusive Gateway Exclusive Gateway(也称为XOR网关或更多技术基于数据的排他网关)经常用做决定流程的流转方向.当流程到达该网关的时候,所有的流出序列流到按照已定 ...
- SQLHelp帮助类
public readonly static string connStr = ConfigurationManager.ConnectionStrings["conn"].Con ...
- linux创建用户、设置密码、修改用户、删除用户
创建用户.设置密码.修改用户.删除用户:useradd testuser 创建用户testuserpasswd testuser 给已创建的用户testuser设置密码说明:新创建的用户会在/home ...
- linux centos使用xrdp远程界面登陆
redhat6 安装xrdp 直接使用windows远程桌面连接登陆 下面介绍实现方法: 第一步:下载源码包,并安装一些依赖的软件下载xrdp源码包 wget http://downloads.so ...
- XSS Payload知识备忘
参考资料:<白帽子讲Web安全>吴翰清 著 参见: 百度百科 http://baike.baidu.com/view/50325.htm 维基百科 http://zh.wikipedia. ...
- Unity自学路线整理(参看微信公众号Unity墙外的世界的文章 )
目前还是个新手. 发现自己有时候还是会一脸蒙...的对着电脑屏幕不知所措,为了利用好在大学零散的时间所以整理一下学习unity的路线. 计划好才能更好的利用时间. 1. 先学好C#再去看引擎,我看的是 ...
- appium 常用api介绍(1)
前言:android手机大家都很熟悉,操作有按键.触摸.点击.滑动等,各种操作方法可以通过api的方法来实现. 参考博文:http://blog.csdn.net/bear_w/article/det ...
- SQL Learning Notes
Sams Teach Yourself SQL in 10 Minutes
- WPF学习笔记(一):数据绑定之元素到元素绑定
前言 作为一只菜鸟,之前学了一段时间的WPF,但是没有总结,过了一学期发现好多东西都忘记了,很多东西还是需要记下来,以备后续复习. 数据绑定在事件中应用非常广泛,可以有效地减少代码量,那么什么是数据绑 ...