Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数
本文只讲解视觉层(Vision Layers)的参数,视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层。
1、Convolution层:
就是卷积层,是卷积神经网络(CNN)的核心层。
层类型:Convolution
lr_mult: 学习率的系数,最终的学习率是这个数乘以solver.prototxt配置文件中的base_lr。如果有两个lr_mult, 则第一个表示权值的学习率,第二个表示偏置项的学习率。一般偏置项的学习率是权值学习率的两倍。
在后面的convolution_param中,我们可以设定卷积层的特有参数。
必须设置的参数:
num_output: 卷积核(filter)的个数
kernel_size: 卷积核的大小。如果卷积核的长和宽不等,需要用kernel_h和kernel_w分别设定
其它参数:
stride: 卷积核的步长,默认为1。也可以用stride_h和stride_w来设置。
pad: 扩充边缘,默认为0,不扩充。 扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。也可以通过pad_h和pad_w来分别设定。
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
pooling层的运算方法基本是和卷积层是一样的。
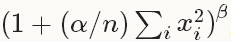 ,得到归一化后的输出
,得到归一化后的输出layers {
name: "norm1"
type: LRN
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
4、im2col层
如果对matlab比较熟悉的话,就应该知道im2col是什么意思。它先将一个大矩阵,重叠地划分为多个子矩阵,对每个子矩阵序列化成向量,最后得到另外一个矩阵。
看一看图就知道了:
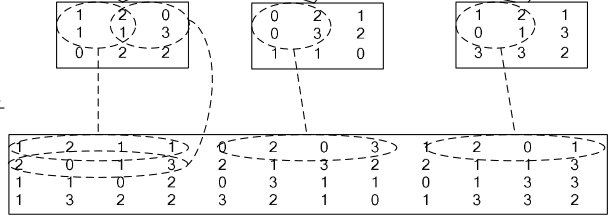
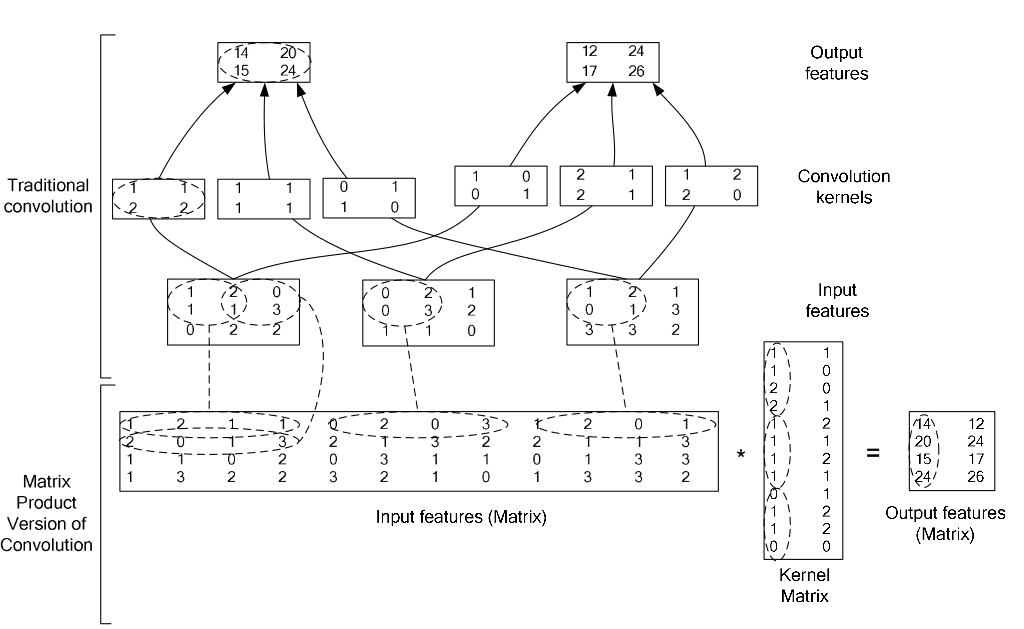
在caffe中,卷积运算就是先对数据进行im2col操作,再进行内积运算(inner product)。这样做,比原始的卷积操作速度更快。
看看两种卷积操作的异同:
Caffe学习系列(3):视觉层(Vision Layers)及参数的更多相关文章
- [转] caffe视觉层Vision Layers 及参数
视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层. 1.Convolution层: 就是卷积层,是卷积神经 ...
- 转 Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- Caffe 学习系列
学习列表: Google protocol buffer在windows下的编译 caffe windows 学习第一步:编译和安装(vs2012+win 64) caffe windows学习:第一 ...
- Caffe学习系列(23):如何将别人训练好的model用到自己的数据上
caffe团队用imagenet图片进行训练,迭代30多万次,训练出来一个model.这个model将图片分为1000类,应该是目前为止最好的图片分类model了. 假设我现在有一些自己的图片想进行分 ...
- Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- 转 Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- Caffe学习系列——工具篇:神经网络模型结构可视化
Caffe学习系列——工具篇:神经网络模型结构可视化 在Caffe中,目前有两种可视化prototxt格式网络结构的方法: 使用Netscope在线可视化 使用Caffe提供的draw_net.py ...
- Caffe学习系列(12):训练和测试自己的图片--linux平台
Caffe学习系列(12):训练和测试自己的图片 学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测 ...
- Caffe学习系列(22):caffe图形化操作工具digits运行实例
上接:Caffe学习系列(21):caffe图形化操作工具digits的安装与运行 经过前面的操作,我们就把数据准备好了. 一.训练一个model 右击右边Models模块的” Images" ...
随机推荐
- MVC模式与三层架构和表示层
1.MVC模式 - Model-View-Controller - 模型-视图-控制器 - Model(模型) > 模型分为业务模型,和数据模型 ...
- JQuery+ajax+jsonp 跨域访问
Jsonp(JSON with Padding)是资料格式 json 的一种“使用模式”,可以让网页从别的网域获取资料. 关于Jsonp更详细的资料请参考http://baike.baidu.com/ ...
- Cookie/Session机制
这些都是基础知识,不过有必要做深入了解.先简单介绍一下. 二者的定义: 当你在浏览网站的时候,WEB 服务器会先送一小小资料放在你的计算机上,Cookie 会帮你在网站上所打的文字或是一些选择, 都纪 ...
- (视频) 开源,免费和跨平台 - MVP ComCamp 2015 KEYNOTE
2015年1月31日,作为KEYNOTE演讲嘉宾,我和来自全国各地的开发人员分享了作为一名MVP的一些体会. Keynote – Open Source, Free Tools and Cross P ...
- JavaScript Patterns 7.1 Singleton
7.1 Singleton The idea of the singleton pattern is to have only one instance of a specific class. Th ...
- Java并发之死锁实例
package com.thread.test.thread; /** * Created by windwant on 2016/6/3. */ public class MyTestDeadLoc ...
- java -jar 执行 eclipse export 的 jar 包报错处理
1. 错误1:打 jar 包执行,报错,找不到 类库的 jar 包 F:\>java -jar remoteLogin.jarException in thread "AWT-Even ...
- Seafile内部云盘
软件列表 软件 版本 备注 centos 6.4 x86_64 64位系统 mysql mysql5.5.49 本机使用 python 2.7 seafile 依赖python pip 8.1.2 安 ...
- spring 注入一个以枚举类型对象
1.枚举 在实际编程中,往往存在着这样的“数据集”,它们的数值在程序中是稳定的,而且“数据集”中的元素是有限的. 例如星期一到星期日七个数据元素组成了一周的“数据集”,春夏秋冬四个数据元素组成了四季的 ...
- Android Native 程序逆向入门(一)—— Native 程序的启动流程
八月的太阳晒得黄黄的,谁说这世界不是黄金?小雀儿在树荫里打盹,孩子们在草地里打滚.八月的太阳晒得黄黄的,谁说这世界不是黄金?金黄的树林,金黄的草地,小雀们合奏着欢畅的清音:金黄的茅舍,金黄的麦屯,金黄 ...