[2] TensorFlow 向前传播算法(forward-propagation)与反向传播算法(back-propagation)
TensorFlow Playground
http://playground.tensorflow.org
帮助更好的理解,游乐场Playground可以实现可视化训练过程的工具
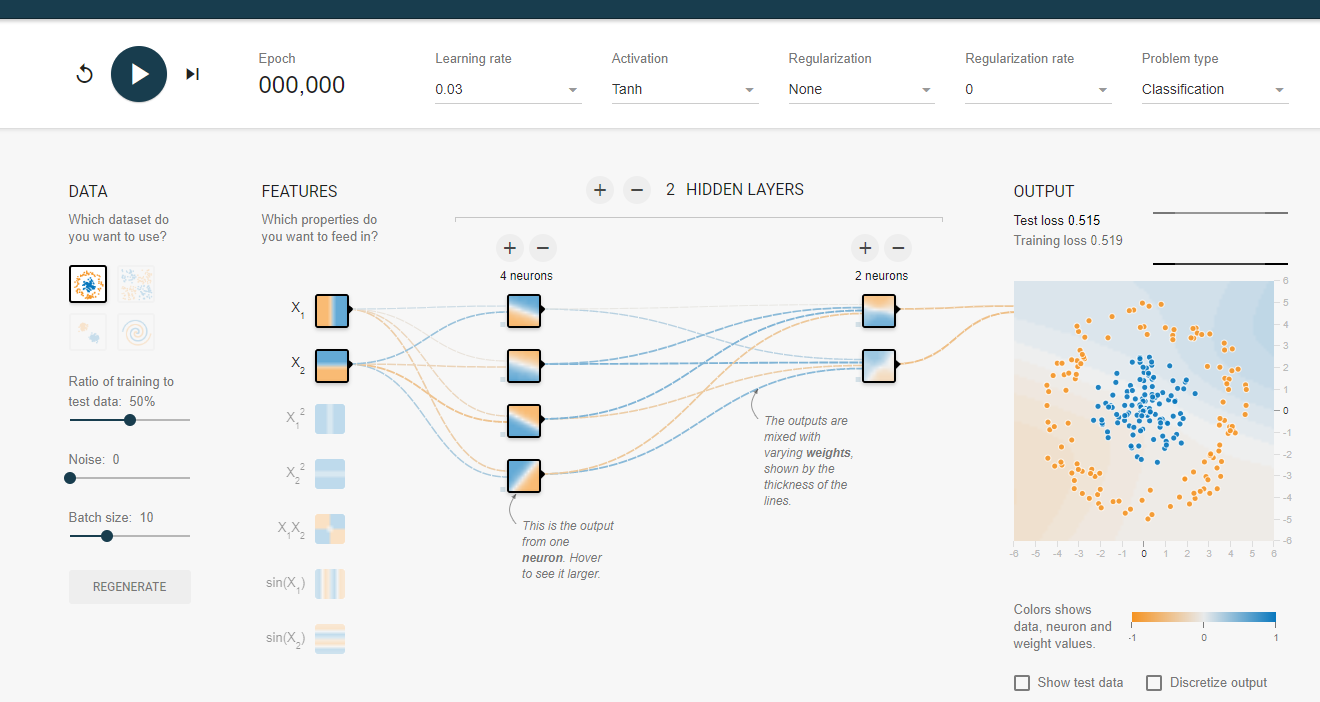
TensorFlow Playground的左侧提供了不同的数据集来测试神经网络。默认的数据为左上角被框出来的那个。被选中的数据也会显示在最右边的 “OUTPUT”栏下。在这个数据中,可以看到一个二维平面上有红色或者蓝色的点,每一个小点代表了一个样例,而点的颜色代表了样例的标签。因为点的颜色只有两种,所以这是 一个二分类的问题。在这里举一个例子来说明这个数据可以代表的实际问题。假设需要判断某工厂生产的零件是否合格,那么蓝色的点可以表示所有合格的零件而红色的表示不合格的零件。这样判断一个零件是否合格就变成了区分点的颜色。
为了将一个实际问题对应到平面上不同颜色点的划分,还需要将实际问题中的实体, 比如上述例子中的零件,变成平面上的一个点。 这就是特征提取解决的问题。还是以零件为例, 可以用零件的长度和质量来大致描述一个零件。这样一个物理意义上的零件就可以被转化成长度和质量这两个数字。在机器学习中,所有用于描述实体的数字的组合就是一 个实体的特征向量(feature vector)。特征向量的提取对机器学习的效果至关重要,通过特征提取,就可以将实际问题中的实体转化为空间中的点。假设使用长度和质量作为一个零件的特征向量,那么每个零件就是二维平面上的一个点。 TensorFlow Playground中 FEATURES 一栏对应了特征向量。 可以认为 x1代表零件的长度,而 x2代表零件的质量。
在二分类问题中,比如 判断零件是否合格,神经网络的输出层往往只包含一个节点,而这个节点会输出一个实数值。通过这个输出值和一个事先设定的阀值,就可以得到最后的分类结果。以判断零件合格为例,可以认为当输出的数值大于 0 时,给出的判断结果是零件合格,反之则零件不合格。一般可以认为当输出值距离阈值越远时得到的判断越可靠。
主流的神经网络主体结构都是分层的结构:
输入层 - 隐藏层 - 输出层
综上,使用神经网络解决分类或回归问题主要可以分为以下 4 个步骤:
1. 提取问题中实体的特征向量作为神经网络的输入。不同的实体可以提取不同的特征向量。
2. 定义神经网络的结构,并定义如何从神经网络的输入得到输出。这个过程就是神经网络的前向传播算法
3. 通过训练数据来调整神经网络中参数的取值,这就是训练神经网络的过程。
4. 使用训练好的神经网络来预测未知的数据。
前向传播算法 forward-propagation
神经元(op)也称为节点是构成一个神经网络的最小单元,每个神经元的输入既可以是其他神经元的输出,也可以是整个神经网络的输入。所谓神经网络的结构指的就是不同神经元之间的连接结构。一个最简单的神经元结构的输出就是所有输入的加权和,而不同输入的权重就是神经元的参数。神经网络的训练过程就是优化神经元中参数取值的过程。
判断零件是否合格的三层前向传播全连接神经网络
其中全连接神经网络是指: 相临两层之间任意两个节点都有连接. 区别与卷积层和LSTM结构
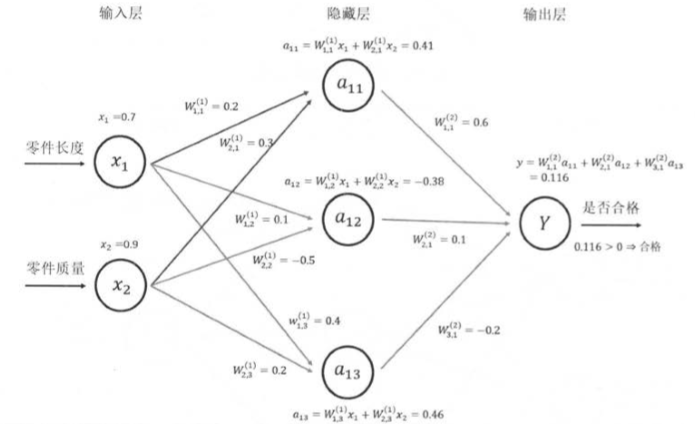
计算神经网络的前向传播结果需要三部分信息:
1.神经网络输入特征向量 比如两个特征,一个是零件的长度x1,一个是零件的质量x2,组成特征向量
2.神经网络的连接结构 (连接前后关系)
3.每个神经元中的参数 W(1)表示第一层节点的参数,W(1)1,2表示连接x1和a12节点的边上的权重.
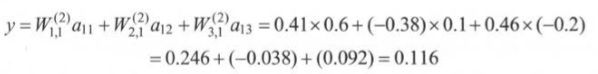
因为这个输出值大于阈值 0,所以在这个样例中最后给出的答案是:这个产品是合格的。这就是整个前向传播的算法。
前向传播算法可以表示为矩阵乘法,其中tf.matmul实现了矩阵乘法的功能
a = tf.matmul(x,w1)
y = tf.matmul(a,w2)
神经网络参数与TensorFlow变量
神经网络中的参数是神经网络实现分类或者回归问题中重要的部分
变量 (tf.Variable)的作用就是保存和更新神经网络中的参数。TensorFlow 中的变量需要指定初始值。 一般使用随机数给 TensorFlow 中的变量初始化
调用 TensorFlow 变量的声明函数 tf.Variable 声明一个 2 * 3的矩阵变量
weights = tf.Variable(tf.random_normal([2,3],mean=0,stddev=2)
随机数生成器
tf.random normal 正态分布 平均值、 标准差、驭伯类型
tf.truncated normal 正态分布,但如果随机出来的值偏离平均值超过 2个标准差,那么这个数将会被重新随机
tf.random uniform 均匀分布
常数生成器
tf.zeros 产生全 0 的数组
tf.ones 产生全 1的数组
tf.ones([2, 3], int32) -> [[1 , 1, 1), [1 , 1, 1))
tf.fill 产生一个全部为给定数字的数组
tf.fill([2, 3), 9) -> ((9, 9, 9), (9, 9, 9))
tf.constant 产生一个给定值的常量
biases= tf.Variable(tf. zeros([3]))
以上代码将会生成一个初始值全部为 0 且长度为 3 的变量
TensorFlow 也支持通过其他变量的初始值 来初始化新的变量(另一个)
w2 = tf.Variable(weights.initialized_value()*2.0)
w2输入的是weights的初始值的两倍
TensorFlow 中, 一个变量的值在被使用之前,这个变量的初始化过程需要被显式地调用。
下面通过变量实现神经网络的参数初始化并实现前向传播的过程:
import tensorflow as tf
# 声明 w1, w2 两个变量, 这里还通过seed参数设定了随机种子 seed=1
# 这样可以保证每次运行得到的结果是一样的
w1 = tf.Variable(tf.random_normal((2, 3), stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal((3, 1), stddev=1, seed=1)) # 暂时将输入的特征向盘定义为一个常量。注意这里 x 是一个 1x2 的矩阵
x = tf.constant([[0.7, 0.9]]) # 通过 3.4.2 节描述的前向传播算法获得神经网络的输出
a = tf.matmul(x, w1)
y = tf.matmul(a, w2) with tf.Session() as sess:
# 因为wl和w2都还没有运行初始化,不能直接sess.run(y)来获取y的取值
sess.run(w1.initializer) # 初始化 w1
sess.run(w2.initializer) # 初始化 w2
print(sess.run(y))
当声明了变量 w1, w2 之后,可以通过 w1 和 w2 来定义神经网络的前向传播过程并得到中间结果 a 和最后答 案,此过程对应 [1] 从零开始 TensorFlow 学习 中A阶段: 定义计算图中的所有计算() 但没有真正运行计算
with tf.Session() as sess 声明一个会话(session)通过会话计算结果,但在计算y之前,需要将所有用到的变量初始化,也就是说虽然在变量定义时给出的变量初始化的方法,但这个方法并没有被真正运行(因为初始化也是一种运算),所以在运行y之前需要通过运行w1.initializer和w2.initializer来初始化权重进行赋值, 虽然直接指定每个变量的初始化是一个可行的方案,但是随着节点增多或节点之间的依赖关系增多,单个调用的方法会变得复杂,这里TensorFlow提供了一种便利的方式tf.global_variables_initializer()来初始化所有变量.
import tensorflow as tf
# 声明 w1, w2 两个变量, 这里还通过seed参数设定了随机种子 seed=1
# 这样可以保证每次运行得到的结果是一样的
w1 = tf.Variable(tf.random_normal((2, 3), stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal((3, 1), stddev=1, seed=1)) # 暂时将输入的特征向盘定义为一个常量。注意这里 x 是一个 1x2 的矩阵
x = tf.constant([[0.7, 0.9]]) # 通过 3.4.2 节描述的前向传播算法获得神经网络的输出
a = tf.matmul(x, w1)
y = tf.matmul(a, w2) with tf.Session() as sess:
# 因为wl和w2都还没有运行初始化,不能直接sess.run(y)来获取y的取值
init_op = tf.global_variables_initializer()
sess.run(init_op) # 初始化全部节点op
print(sess.run(y))
TensorFlow 的核心概念是张量(tensor),所有的数据都是通过张量的形式来组织的,那么变量和张量是什么关系呢? 变量的声明函数 tf.Variable 是一个运算。这个运算的输出结果就是一个张量, 而这个张量即是variable,所以变量可以看作是一种特殊的张量
那么tf.Variable底层是如何实现的呢, 下面是神经网络前向传播样例中变量 w1 相关部分的计算图可视化结果

w1是一个 Variable 运算
在这张图 的下方可以看到 w1 通过一个 read 操作将值提供给了一个乘法运算,这个乘法操作就是 tf.matmul(x, w1), 初始化变量 w1 的操作是通过 Assign 操作 输入random_normal随机值完成的.整个过程就是变量初始化过程.
TensorFlow 中集合(collection)的概念,所有的变量都会被自动地加入 到 GraphKeys.VARIABLES 这个集合中。 通过 tf.global_variables()函数可以拿到当前计算图 上所有的变量。拿到计算图上所有的变量有助于持久化整个计算图的运行状态.
通过变量声明函数 中的 trainable 参数来区分需要优化的参数(比如神经网络中的参数) 和其他参数(比如选代的轮数) .如果声明变量时参数 trainable 为 True ,那么这个变量将会被加入到GraphKeys.TRAINABLE_VARIABLES集合. 在TensorFlow 中可以通过tf.trainable_variables函数得到所有需要优化的参数. TensorFlow 中提供的神 经网络优化算法会将GraphKeys.TRAINABLE_VARIABLES 集合中的变量作为默认的优化对象
维度(shape)和类型 (type) 也是变量最重要的两个属性。和大部分程序 语言类似,变量的类型是不可改变的。一个变量在构建之后,它的类型就不能再改变了 。比如在上面给出的前向传播样例中, w1的类型为 random_normal结果的默认类型 tf.float32, 那么它将不能被赋予其他类型的值
w1.assign(2)
报错TypeError : type float64 that does not match type float32 of argument '' ref ''
反向传播算法(back-propagation)
只有经过有效训练的神经网络模型才可以真正地解决分类或者回归问题. 使用监督学习的方式设置神经网络参数需要有一个标注好的训练数据集,通过调整神经网络中的参数对训练数据进行拟合,可以使得模型对未知的样本提供预测的能力.
神经网络优化算法中,最常用的是反向传播算法(back-propagation)
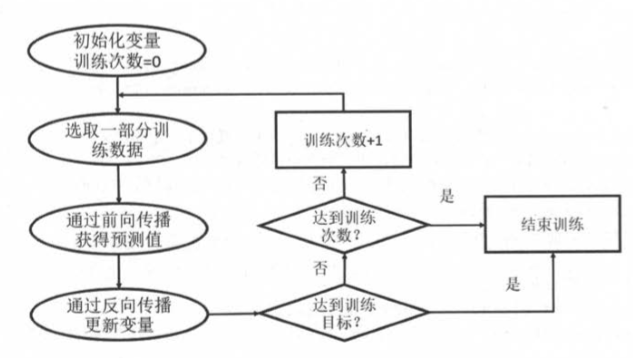
反向传播算法实现了一个法代的过程。在每次迭代的开始,首先需要选取一小部分训练数据, 这一小部分数据叫做一个 batch
这个 batch 的样例会通过前向传播算法得到神经网络模型的预测结果。因为训练数据都是有正确答案标注的, 所以可以计算出当前神经网络模型的预测答案与正确答案之间的差距。最后,基于预测值 和真实值之间的差距,反向传播算法会相应更新神经网络参数的取值,使得在这个 batch 上神经网络模型的预测结果和真实答案更加接近
通过TensorFlow实现反向传播算法的第一步是使用 TensorFlow表达一个batch 的数据。
x = tf.constant([[0.7, 0.9]])
使用tf.placeholder代替tf.constant
但如果每轮迭代中选取的数据都要通过常量来表示,那么TensorFlow 的计算图将会太大。因为每生成一个常量,TensorFlow都会在计算图中增加一个节点。 一个神经网络的训练过程会需要经过几百万轮甚至几亿轮的迭代,这样计算图就会非常大,而且利用率很低. 为了避免这个问题, TensorFlow 提供了 placeholder 机制用于提供输入数据。placeholder 相当于定义了一个位置,这个位置中的数据在程序运行时再指定. 这样在程序 中就不需要生成大量常量来提供输入数据,而只需要将数据通过 placeholder 传入 TensorFlow 计算图。在 placeholder 定义时,这个位置上的数据类型是需要指定的。和其他张量一样,placeholder 的类型也是不可以改变的。 placeholder 中数据的维度信息可以根据 提供的数据推导得出,所以不一定要给出。下面给出了通过 placeholder 实现前向传播算法的代码。
import tensorflow as tf
w1 = tf.Variable(tf.random_normal((2, 3), stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal((3, 1), stddev=1, seed=1))
x = tf.placeholder(tf.float32,shape=(1,2),name="input")
a = tf.matmul(x, w1)
y = tf.matmul(a, w2) with tf.Session() as sess:
# 因为wl和w2都还没有运行初始化,不能直接sess.run(y)来获取y的取值
init_op = tf.global_variables_initializer()
sess.run(init_op) # 初始化全部节点op
print(sess.run(y))
"""
报错
InvalidArgumentError (see above for traceback):
You must feed a value for placeholder tensor 'input' with dtype float
and shape [1,2]
"""
tf.placeholder替换了原来通过常量tf.constant定义,但额外的需要提供一个feed_dict字典(map)来assign x的取值,在feed_dict中需要给出每个用到的placeholder的取值
正确写法
import tensorflow as tf
w1 = tf.Variable(tf.random_normal((2, 3), stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal((3, 1), stddev=1, seed=1))
x = tf.placeholder(tf.float32,shape=(1,2),name="input")
a = tf.matmul(x, w1)
y = tf.matmul(a, w2) with tf.Session() as sess:
# 因为wl和w2都还没有运行初始化,不能直接sess.run(y)来获取y的取值
init_op = tf.global_variables_initializer()
sess.run(init_op) # 初始化全部节点op
feed_dict ={x:[[0.7,0.9]]}
print(sess.run(y,feed_dict))
以上程序只计算了 x = [[0.7, 0.9]] 这1个batch的训练样例,如果要增加更多的训练样例,首先要调整tf.placeholder的shape参数改为n × 2, 将输入的 1 x 2 矩阵改为 n x 2 的矩阵,其中n × 2的矩阵的每1行为1个样例数据,可以得到 n x 1 矩阵形式的前向传播结果 ( n个样例 )
import tensorflow as tf
w1 = tf.Variable(tf.random_normal((2, 3), stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal((3, 1), stddev=1, seed=1))
x = tf.placeholder(tf.float32,shape=(4,2),name="input")
a = tf.matmul(x, w1)
y = tf.matmul(a, w2) with tf.Session() as sess:
# 因为wl和w2都还没有运行初始化,不能直接sess.run(y)来获取y的取值
init_op = tf.global_variables_initializer()
sess.run(init_op) # 初始化全部节点op
feed_dict ={x:[[0.7,0.9],[0.7,0.9],[0.7,0.9],[0.7,0.9]]}
print(sess.run(y,feed_dict)) """
结果:
[[3.957578]
[3.957578]
[3.957578]
[3.957578]]
"""
损失函数
得到前向传播结果之后,需要定义一个损失函数来刻画当前的预测值与真实值(标记好的数据集)之间的差距, 然后通过反向传播算法(back-propagation)来调整神经网络参数的取值,使得差距可以被缩小.
简单的损失函数
# 使用 sigmoid 函数将 y 转换为 0~1 之间的数值。转换后 y 代表预测是正样本的概率
# 1-y 代表 预测是负样本的概率
y=tf.sigmoid(y)
# 定义损失函数(交叉熵)来刻画预测值与真实值的差距
cross_entropy = -tf.reduce_mean(y * tf.log(tf.clip_by_value(y,1e-10,1.0))+
(1-y)*tf.log(tf.clip_by_value(1-y,1e-10,1.0)))
# 学习率
learning_rate = 0.001
# 定义反向传播算法来优化神经网络中的参数
train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)
其中 cross_entropy定义了真实值和预测值之间的交叉熵 (cross entropy), 这是分类问题中一个常用的损失函数
train_step定义了反向传播的优化方法 目前TensorFlow支持10种不同的优化器, 常用的有tf.train.GradientDescentOptimizer、tf.train.AdamOptimizer和tf.train.MomentumOptimizer
在定义了反向传播算法之后,通过sess.run(train_step)就可以对所有在GraphKeys.TRAINABLE_VARIABLES集合中的变量进行优化,使得当前batch下损失函数值更小
完整的神经网络样例程序
import tensorflow as tf
# 通过RandomState生成模拟数据集
from numpy.random import RandomState
# 定义训练数据 batch 的大小
batch_size = 8
# 定义神经网络的参数
w1 = tf.Variable(tf.random_normal((2, 3), stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal((3, 1), stddev=1, seed=1)) # 在 shape 的一个维度上使用 None 可以方便使用不同的 batch 大小. 在训练时需要把数据分成
# 成比较小的 batch, 但是在测试时,可以一次性使用全部的数据. 当数据集比较小时这样比较方便
# 测试, 当数据集比较大时,将大量数据放入一个 batch 可能会导致内存溢出
x = tf.placeholder(tf.float32,shape=(None,2),name="x-input")
_y = tf.placeholder(tf.float32,shape=(None,1),name="y-input") # 定义神经网络的前向传播过程
a = tf.matmul(x, w1)
y = tf.matmul(a, w2) # 定义损失函数和反向传播的算法
y=tf.sigmoid(y) # 定义损失函数(交叉熵)来刻画预测值与真实值的差距
cross_entropy = -tf.reduce_mean( _y * tf.log(tf.clip_by_value(y,1e-10,1.0))+
(1-y)*tf.log(tf.clip_by_value(1-y,1e-10,1.0)))
# 学习率
learning_rate = 0.001
# 定义反向传播算法来优化神经网络中的参数
train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy) # 通过随机数生成一个模拟的数据集
rdm = RandomState(1)
dataset_size = 128 # 样本数量
X = rdm.rand(dataset_size,2) # 定义规则来给出样本的标签. x1+x2<1的样例都认为是正样本(比如零件合格),其他为情况为负样本(零件不合格)
# 大部分解决分类问题的神经网络都采用0来表示负样本,1来表示正样本
Y = [[int(x1+x2<1)] for (x1,x2) in X] # 创建一个会话来运行TensorFlow程序
with tf.Session() as sess:
# 因为wl和w2都还没有运行初始化,不能直接sess.run(y)来获取y的取值
init_op = tf.global_variables_initializer()
sess.run(init_op) # 初始化全部节点op
# 打印最初的神经网络节点参数值
print("w1: ",sess.run(w1))
print("w2: ",sess.run(w2)) # 设定训练的轮数
STEPS = 50000
for i in range(STEPS):
# 每次选取batch_size个样本进行训练
start = (i*batch_size) % dataset_size
end = min(start+batch_size,dataset_size) # 通过选取的样本训练神经网络并更新参数
sess.run(train_step,feed_dict={x:X[start:end],_y:Y[start:end]}) # 每隔1000轮 就计算在所有的数据上的交叉熵并输出
if i % 1000 == 0:
total_cross_entropy = sess.run(cross_entropy,feed_dict={x:X,_y:Y})
print("After {0} training step(s),cross entropy on all data is {1}".format(i,total_cross_entropy)) """
输出:
After 43000 training step(s),cross entropy on all data is 1.3634375761739648e-07
After 44000 training step(s),cross entropy on all data is 9.776589138255076e-08
After 45000 training step(s),cross entropy on all data is 7.139959734558943e-08
After 46000 training step(s),cross entropy on all data is 4.426699007353818e-08
After 47000 training step(s),cross entropy on all data is 3.026656614224521e-08
After 48000 training step(s),cross entropy on all data is 1.577882535741537e-08
After 49000 training step(s),cross entropy on all data is 1.577882535741537e-08
"""
按照这段程序可以总结训练神经网络的三个步骤:
1. 定义神经网络的结构和前向传播的输出结果
2. 定义损失函数,选择反向传播优化的算法
3. 设定会话(tf.Session)并且在训练数据上反复迭代运行反向传播优化算法
[2] TensorFlow 向前传播算法(forward-propagation)与反向传播算法(back-propagation)的更多相关文章
- 前向传播算法(Forward propagation)与反向传播算法(Back propagation)
虽然学深度学习有一段时间了,但是对于一些算法的具体实现还是模糊不清,用了很久也不是很了解.因此特意先对深度学习中的相关基础概念做一下总结.先看看前向传播算法(Forward propagation)与 ...
- BP(back propagation)反向传播
转自:http://www.zhihu.com/question/27239198/answer/89853077 机器学习可以看做是数理统计的一个应用,在数理统计中一个常见的任务就是拟合,也就是给定 ...
- 深度神经网络(DNN)反向传播算法(BP)
在深度神经网络(DNN)模型与前向传播算法中,我们对DNN的模型和前向传播算法做了总结,这里我们更进一步,对DNN的反向传播算法(Back Propagation,BP)做一个总结. 1. DNN反向 ...
- 循环神经网络(RNN)模型与前向反向传播算法
在前面我们讲到了DNN,以及DNN的特例CNN的模型和前向反向传播算法,这些算法都是前向反馈的,模型的输出和模型本身没有关联关系.今天我们就讨论另一类输出和模型间有反馈的神经网络:循环神经网络(Rec ...
- 再谈反向传播(Back Propagation)
此前写过一篇<BP算法基本原理推导----<机器学习>笔记>,但是感觉满纸公式,而且没有讲到BP算法的精妙之处,所以找了一些资料,加上自己的理解,再来谈一下BP.如有什么疏漏或 ...
- 深度学习——深度神经网络(DNN)反向传播算法
深度神经网络(Deep Neural Networks,简称DNN)是深度学习的基础. 回顾监督学习的一般性问题.假设我们有$m$个训练样本$\{(x_1, y_1), (x_2, y_2), …, ...
- CS231n课程笔记翻译5:反向传播笔记
译者注:本文智能单元首发,译自斯坦福CS231n课程笔记Backprop Note,课程教师Andrej Karpathy授权翻译.本篇教程由杜客翻译完成,堃堃和巩子嘉进行校对修改.译文含公式和代码, ...
- 【cs231n】反向传播笔记
前言 首先声明,以下内容绝大部分转自知乎智能单元,他们将官方学习笔记进行了很专业的翻译,在此我会直接copy他们翻译的笔记,有些地方会用红字写自己的笔记,本文只是作为自己的学习笔记.本文内容官网链接: ...
- DL反向传播理解
作者:寒小阳 时间:2015年12月. 出处:http://blog.csdn.net/han_xiaoyang/article/details/50321873 声明:版权所有,转载请联系作者并注明 ...
随机推荐
- 【Tomcat】Tomcat工作原理
Tomcat 总体结构 Tomcat 的结构很复杂,但是 Tomcat 也非常的模块化,找到了 Tomcat 最核心的模块,您就抓住了 Tomcat 的“七寸”.下面是 Tomcat 的总体结构图: ...
- linux的 .bashrc文件是干什么的?
使用man bash命令查看到的联机帮助文件中的相关解释如下: .bashrc - The individual per-interactive-shell startup file. 这个文件主要保 ...
- 有哪些Java性能优化方法?
面试官:"有性能优化经验没?" 应聘者:"有一点." 面试官:"那你们从哪些方面做了优化?" 应聘者:"sql优化.JV ...
- BZOJ 2940: [Poi2000]条纹(Multi-Nim)
Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 110 Solved: 70[Submit][Status][Discuss] Description ...
- 【20190226】JavaScript-知识点记录:dom0级事件,dom2级事件
DOM0级事件处理程序: 通过将元素的事件处理程序属性(如onclick)的值设置为一个函数来指定事件处理程序的方法称为DOM0级方法,它被认为是元素的方法,这时候的事件处理程序是在元素的作用域中运行 ...
- @meda媒体查询
定义和使用 使用 @media 查询,你可以针对不同的媒体类型定义不同的样式. @media 可以针对不同的屏幕尺寸设置不同的样式,特别是如果你需要设置设计响应式的页面,@media 是非常有用的. ...
- Android为TV端助力 最简单的自定义圆点view
首先创建一个选择器,用来判断圆点状态,可以根本自己的需求改 <selector xmlns:android="http://schemas.android.com/apk/res/an ...
- ORA-12514, TNS:listener does not currently know of service requested in connect descriptor案例2
今天使用SQL Developer连接一台测试服务器数据库(ORACLE 11g)时,遇到了"ORA-12514, TNS:listener does not currently know ...
- C# 混合模式程序集是针对“v2.0.50727”版的运行时生成的,在没有配置其他信息的情况下,无法在 4.0 运行时中加载该程序集
1.在项目解决方案中,找到项目的app.config文件
- 获取Bing每日图片API接口
bing图片每日更新,对于这一点感觉挺不错的,如果能够把bing每日图片作为博客背景是不是很不错呢?首先我们进入Bing首页,会发现自动转到中国版.不过这没关系,中国版更符合国情,速度也比国际版快一些 ...