大数据技术 - MapReduce的Shuffle及调优
本章内容我们学习一下 MapReduce 中的 Shuffle 过程,Shuffle 发生在 map 输出到 reduce 输入的过程,它的中文解释是 “洗牌”,顾名思义该过程涉及数据的重新分配,主要分为两部分:1. map 任务输出的数据分组、排序,写入本地磁盘 2. reduce 任务拉取排序。由于该过程涉及排序、磁盘IO、以及网络IO 等消耗资源和 CPU 比较大的操作,因此该过程向来是“兵家必争”之地,即大家会重点优化的一个地方,因此也是大数据面试中经常会被重点考察的地方。本文力求通俗、简单地将 Shuffle 过程描述清楚。
包含 Shuffle 过程的 MapReduce 任务处理流程如下图,图片来自《Hadoop权威指南(第四版)》
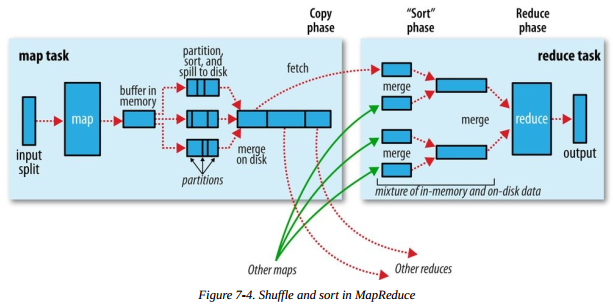
接下来,分别介绍 Shuffle 所涉及的主要操作。
map 端
map 端输出时,先将数据写入内存中的环形缓冲区,默认大小为 100M,可以通过 mapreduce.task.io.sort.mb 来设置。map 端输出过程如下:
- 当缓冲区的内容大小达到阈值(默认 0.8,即缓冲区大小的 80%,可通过 mapreduce.map.sort.spill.percent 设置),便有一个后台线程会将写入缓冲区的内容溢写到磁盘。溢写的过程中 map 任务仍然可以写缓冲区,一旦缓冲区写满,map 任务阻塞,直到后台线程写磁盘结束
- 后台线程写磁盘之前会计算输出的 key 的分区(一个分区对应一个 reduce 任务),同一个分区的 key 分在一组并按照 key 排序。最后写到本地磁盘。如果设置 combiner 函数,会在写磁盘之前调用 combaner 函数。我们之前没有介绍 combiner,不理解的同学可以先忽略,只需知道它是先将数据聚合为了减少网络IO,且不会影响 reduce 计算结果的一个操作即可
- 每一次溢写都会产生一个溢出文件,map 输出结束后会产生多个溢出文件。最终会被合并成一个分区的且有序的文件。这里为什么要合并成 1 个,因为如果 map 输出的数据比较多,产生本地的小文件会太多,影响系统性能。因此需要进行合并,通过 mapreduce.task.io.sort.factor 设置一次可以合并的文件个数,默认为 10
- 输出到磁盘的过程中可以设置压缩, 默认不压缩。通过设置 mapreduce.map.output.compress 为 true 开启压缩
以上便是 map 任务输出过程的主要操作,输出到磁盘后,reducer 会通过 http 服务拉取输出文件中属于自己分区的数据。
reduce 端
reduce 端在 Shuffle 阶段主要涉及复制和排序两个过程。 reduce 端拉取 map 输出数据的过程是复制阶段,对应上图中的 fetch。一个 reduce 任务需要从多个 map 输出复制。因此只要有 map 任务完成,reduce 任务就可以进行复制。复制的过程可以是多线程并发进行,并发的线程个数由 mapreduce.reduce.shuffle.parallelcopies 设置,默认是 5 。
- map 任务完成后通过心跳通知 application master,reduce 端会有一个线程定期查询 application master,以获取完成的 map 任务的位置,从而去对应的机器复制数据
- reduce 复制的数据先写到 reduce 任务的 JVM 内存,通过 mapreduce.reduce.shuffle.input.buffer.percent 控制可以用的内存比例
- 如果复制的数据大小达到内存阈值(通过 mapreduce.reduce.shuffle.merge.percent 控制)或者复制的文件数达到阈值(通过 mapreduce.reduce.merge.inmem.threshold 控制,默认 1000)则将内存的数据合并溢写到磁盘,如果设置了 combine 函数,写磁盘前会调用 combine 函数以减少写入磁盘的数据量
- 复制阶段结束后,reduce 将进入排序阶段。如果发生了上面第三步,即产生溢写,那么磁盘可能会有多个溢写文件,此时需要将磁盘文件合并并排序。如果溢写的文件较多,需要多次合并,每次合并的文件数由 mapreduce.task.io.sort.factor 控制。最后一次合并排序的时候不会将数据写到磁盘而直接作为 reduce 任务的输入
以上便是 reduce 任务前的复制、排序阶段。至此,整个 Shuffle 过程就介绍完毕。
参数调优
我们在上面介绍 Shuffle 过程时已经提到了一些参数,这里统一整理并说明一下
map 端调优参数
| 参数名 | 默认值 | 说明 |
| mapreduce.task.io.sort.mb | 100 | map 输出是所使用的内存缓冲区大小,单位:MB |
| mapreduce.map.sort.spill.percent | 0.80 | map 输出溢写到磁盘的内存阈值 |
| mapreduce.task.io.sort.factor | 10 | 排序文件是一次可以合并的流数 |
| mapreduce.map.output.compress | false | map 输出是否压缩 |
| mapreduce.map.output.compress.codec | org.apache.hadoop.io.compress.DefaultCodec | map 输出压缩的编解码器 |
我们希望在 map 输出阶段能够提供更多的内存空间,以提升性能。因此 map 函数应该尽量少占用内存,以便留出内存用于输出。我们也可以评估 map 输出,通过增大 mapreduce.task.io.sort.mb 值来减少溢写的文件数。
reduce 端调优参数
| 参数名 |
默认值 |
说明 |
| mapreduce.reduce.shuffle.parallelcopies | 5 | 并发复制的线程数 |
| mapreduce.task.io.sort.factor | 10 | 同 map 端 |
| mapreduce.reduce.shuffle.input.buffer.percent | 0.70 | Shuffle 的复制阶段,用来存放 map 输出缓冲区占reduce 堆内存的百分比 |
| mapreduce.reduce.shuffle.merge.percent | 0.66 | map 输出缓冲区的阈值,超过该比例将进行合并和溢写磁盘 |
| mapreduce.reduce.merge.inmem.threshold | 1000 | 阈值,当累积的 map 输出文件数超过该值,进行合并和溢写磁盘,0或者负值意味着改参数无效,合并和溢写只由 mapreduce.reduce.shuffle.merge.percent 控制 |
| mapreduce.reduce.input.buffer.percent | 0.0 |
在 reduce 过程(开始运行 reduce 函数时),内存中保存 map 输出的空间站整个堆空间的比例。 默认情况下,reduce 任务开始前所有的 map 输出合并到磁盘,以便为 reducer 提供尽可能多的内存。 如果 reducer 需要的内存较少,可以增加此值以最小化磁盘访问次数 |
在 reduce 端,进行 reduce 函数前,如果中间数据全部驻留内存可以获得最佳性能,默认情况是不能实现的。如果 reduce 函数内存需求不大,把 mapreduce.reduce.input.buffer.percent 参数设置大一些可以提升性能。
总结
今天这章,我们详细介绍了 Shuffle 过程,关注 Shuffle 过程的性能对整个 MR 作业的性能调优至关重要。经过这章的介绍,我们能够掌握 Shuffle 过程的关键技术点,虽然还不算深入。同时,我们介绍了常见的参数以及调优方法,希望能够在实际应用中不断的尝试、总结,写出性能最佳的任务。
大数据技术 - MapReduce的Shuffle及调优的更多相关文章
- 大数据技术 - MapReduce的Combiner介绍
本章来简单介绍下 Hadoop MapReduce 中的 Combiner.Combiner 是为了聚合数据而出现的,那为什么要聚合数据呢?因为我们知道 Shuffle 过程是消耗网络IO 和 磁盘I ...
- 大数据技术 —— MapReduce 简介
本文为senlie原创,转载请保留此地址:http://www.cnblogs.com/senlie/ 1.概要很多计算在概念上很直观,但由于输入数据很大,为了能在合理的时间内完成,这些计算必须分布在 ...
- 大数据技术 - MapReduce 作业的运行机制
前几章我们介绍了 Hadoop 的 MapReduce 和 HDFS 两大组件,内容比较基础,看完后可以写简单的 MR 应用程序,也能够用命令行或 Java API 操作 HDFS.但要对 Hadoo ...
- 大数据技术 - MapReduce 应用的配置和单元测试
上一章的 MapReduce 应用中,我们使用了自定义配置,并用 GenericOptionsParser 处理命令行输入的配置,这种方式简单粗暴.但不是 MapReduce 应用常见的写法,本章第一 ...
- Google大数据技术架构探秘
原文地址:https://blog.csdn.net/bingdata123/article/details/79927507 Google是大数据时代的奠基者,其大数据技术架构一直是互联网公司争相学 ...
- 大数据技术之Hadoop(MapReduce)
第1章 MapReduce概述 1.1 MapReduce定义 1.2 MapReduce优缺点 1.2.1 优点 1.2.2 缺点 1.3 MapReduce核心思想 MapReduce核心编程思想 ...
- 大数据技术 vs 数据库一体机[转]
http://blog.sina.com.cn/s/blog_7ca5799101013dtb.html 目前,虽然大数据与数据库一体机都很火热,但相当一部分人却无法对深入了解这两者的本质区别.这里便 ...
- 大数据技术生态圈形象比喻(Hadoop、Hive、Spark 关系)
[摘要] 知乎上一篇很不错的科普文章,介绍大数据技术生态圈(Hadoop.Hive.Spark )的关系. 链接地址:https://www.zhihu.com/question/27974418 [ ...
- 【学习笔记】大数据技术原理与应用(MOOC视频、厦门大学林子雨)
1 大数据概述 大数据特性:4v volume velocity variety value 即大量化.快速化.多样化.价值密度低 数据量大:大数据摩尔定律 快速化:从数据的生成到消耗,时间窗口小,可 ...
随机推荐
- Confluence 6 配置索引语言
修改你 Confluence 的索引语言将有助于你提高搜索的准确性,如果你网站使用的主要语言是除了英语以外的其他语言. Confluence 可以支持下面语言的的内容索引: Arabic Brazil ...
- 基于 Confluence 6 数据中心在你的 Atlassian 应用中配置 SAML 授权
希望在 Confluence 中配置SAML: Go to > 基本配置(General Configuration) > SAMl 授权(SAML Authentication). 选 ...
- 再谈树形dp
上次说了说树形dp的入门 那么这次该来一点有难度的题目了: UVA10859 Placing Lampposts 给定一个n个点m条边的无向无环图,在尽量少的节点上放灯,使得所有边都与灯相邻(被灯照亮 ...
- 第十七单元 Samba服务
Samba的功能 Samba的安装 Samba服务的启动.停止.重启 Samba服务的配置 Samba服务的主配置文件 samba服务器配置实例 Samba客户端设置 windows客户端 Linux ...
- LeetCode(104):二叉树的最大深度
Easy! 题目描述: 给定一个二叉树,找出其最大深度. 二叉树的深度为根节点到最远叶子节点的最长路径上的节点数. 说明: 叶子节点是指没有子节点的节点. 示例:给定二叉树 [3,9,20,null, ...
- SpringBoot图片上传(二)
需求简介:做新增的时候,需要上传图片.(⊙o⊙)…这需求描述也太简单了吧,限制文件大小60*60 512kb ,第一次做,记录一下嗷,废话就不啰嗦了 上代码 代码: //html代码<div c ...
- Linux编程学习笔记(一)
Linux的发展趋势势在必行,国内的服务器的操作系统Linux占到主导地位,不光是操作系统,还有嵌入式系统. 1. 今天就Linux的其中一个版本做一介绍,如下是Centos的版本之间的区别. ins ...
- OrCAD Capture CIS 16.6 导出BOM
OrCAD Capture CIS 16.6 一.选择设计文件:菜单:Tools > Bill of Materials... 二.Bill of Materials > Open in ...
- python截图
import time import os, win32gui, win32ui, win32con, win32api def window_capture(dpath,name,srcbmp=[0 ...
- Python(字符串操作实例1)一个字符串用空格隔开
# 将字符中单词用空格隔开# 已知传入的字符串中只有字母,每个单词的首字母大写,# 请将每个单词用空格隔开,只保留第一个单词的首字母大写传入:“HelloMyWorld”# 返回“Hello my w ...