Python NLTK 自然语言处理入门与例程(转)
转 https://blog.csdn.net/hzp666/article/details/79373720
Python NLTK 自然语言处理入门与例程
- 在这篇文章中,我们将基于 Python 讨论自然语言处理(NLP)。本教程将会使用 Python NLTK 库。NLTK 是一个当下流行的,用于自然语言处理的 Python 库。
那么 NLP 到底是什么?学习 NLP 能带来什么好处?
简单的说,自然语言处理( NLP )就是开发能够理解人类语言的应用程序和服务。
我们生活中经常会接触的自然语言处理的应用,包括语音识别,语音翻译,理解句意,理解特定词语的同义词,以及写出语法正确,句意通畅的句子和段落。
NLP的作用
正如大家所知,每天博客,社交网站和网页会产生数亿字节的海量数据。
有很多公司热衷收集所有这些数据,以便更好地了解他们的用户和用户对产品的热情,并对他们的产品或者服务进行合适的调整。
这些海量数据可以揭示很多现象,打个比方说,巴西人对产品 A 感到满意,而美国人却对产品 B 更感兴趣。通过NLP,这类的信息可以即时获得(即实时结果)。例如,搜索引擎正是一种 NLP,可以在正确的时间给合适的人提供适当的结果。
但是搜索引擎并不是自然语言处理(NLP)的唯一应用。还有更好更加精彩的应用。
NLP的应用
以下都是自然语言处理(NLP)的一些成功应用:
- 搜索引擎,比如谷歌,雅虎等等。谷歌等搜索引擎会通过NLP了解到你是一个科技发烧友,所以它会返回科技相关的结果。
- 社交网站信息流,比如 Facebook 的信息流。新闻馈送算法通过自然语言处理了解到你的兴趣,并向你展示相关的广告以及消息,而不是一些无关的信息。
- 语音助手,诸如苹果 Siri。
- 垃圾邮件程序,比如 Google 的垃圾邮件过滤程序 ,这不仅仅是通常会用到的普通的垃圾邮件过滤,现在,垃圾邮件过滤器会对电子邮件的内容进行分析,看看该邮件是否是垃圾邮件。
NLP库
现在有许多开源的自然语言处理(NLP)库。比如:
- Natural language toolkit (NLTK)
- Apache OpenNLP
- Stanford NLP suite
- Gate NLP library
自然语言工具包(NLTK)是最受欢迎的自然语言处理(NLP)库。它是用 Python 语言编写的,背后有强大的社区支持。
NLTK 也很容易入门,实际上,它将是你用到的最简单的自然语言处理(NLP)库。
在这个 NLP 教程中,我们将使用 Python NLTK 库。在开始安装 NLTK 之前,我假设你知道一些 Python入门知识。
安装 NLTK
如果你使用的是 Windows , Linux 或 Mac,你可以 使用PIP 安装NLTK: # pip install nltk。
在本文撰写之时,你可以在 Python 2.7 , 3.4 和 3.5 上都可以使用NLTK。或者可以通过获取tar 进行源码安装。
要检查 NLTK 是否正确地安装完成,可以打开你的Python终端并输入以下内容:Import nltk。如果一切顺利,这意味着你已经成功安装了 NLTK 库。
一旦你安装了 NLTK,你可以运行下面的代码来安装 NLTK 包:
import nltk
nltk.download()
这将打开 NLTK 下载器来选择需要安装的软件包。
你可以选择安装所有的软件包,因为它们的容量不大,所以没有什么问题。现在,我们开始学习吧!
使用原生 Python 来对文本进行分词
首先,我们将抓取一些网页内容。然后来分析网页文本,看看爬下来的网页的主题是关于什么。我们将使用 urllib模块来抓取网页:
import urllib.request
response = urllib.request.urlopen('http://php.net/')
html = response.read()
print (html)
从打印输出中可以看到,结果中包含许多需要清理的HTML标记。我们可以用这个 BeautifulSoup 库来对抓取的文本进行处理:
from bs4 import BeautifulSoup
import urllib.request
response = urllib.request.urlopen('http://php.net/')
html = response.read()
soup = BeautifulSoup(html,"html5lib")
text = soup.get_text(strip=True)
print (text)
现在,我们能将抓取的网页转换为干净的文本。这很棒,不是么?
最后,让我们通过以下方法将文本分词:
from bs4 import BeautifulSoup
import urllib.request
response = urllib.request.urlopen('http://php.net/')
html = response.read()
soup = BeautifulSoup(html,"html5lib")
text = soup.get_text(strip=True)
tokens = [t for t in text.split()]
print (tokens)
词频统计
现在的文本相比之前的 html 文本好多了。我们再使用 Python NLTK 来计算每个词的出现频率。NLTK 中的FreqDist( ) 函数可以实现词频统计的功能 :
from bs4 import BeautifulSoup
import urllib.request
import nltk
response = urllib.request.urlopen('http://php.net/')
html = response.read()
soup = BeautifulSoup(html,"html5lib")
text = soup.get_text(strip=True)
tokens = [t for t in text.split()]
freq = nltk.FreqDist(tokens)
for key,val in freq.items():
print (str(key) + ':' + str(val))
如果你查看输出结果,会发现最常用的词语是PHP。
你可以用绘图函数为这些词频绘制一个图形: freq.plot(20, cumulative=False)。
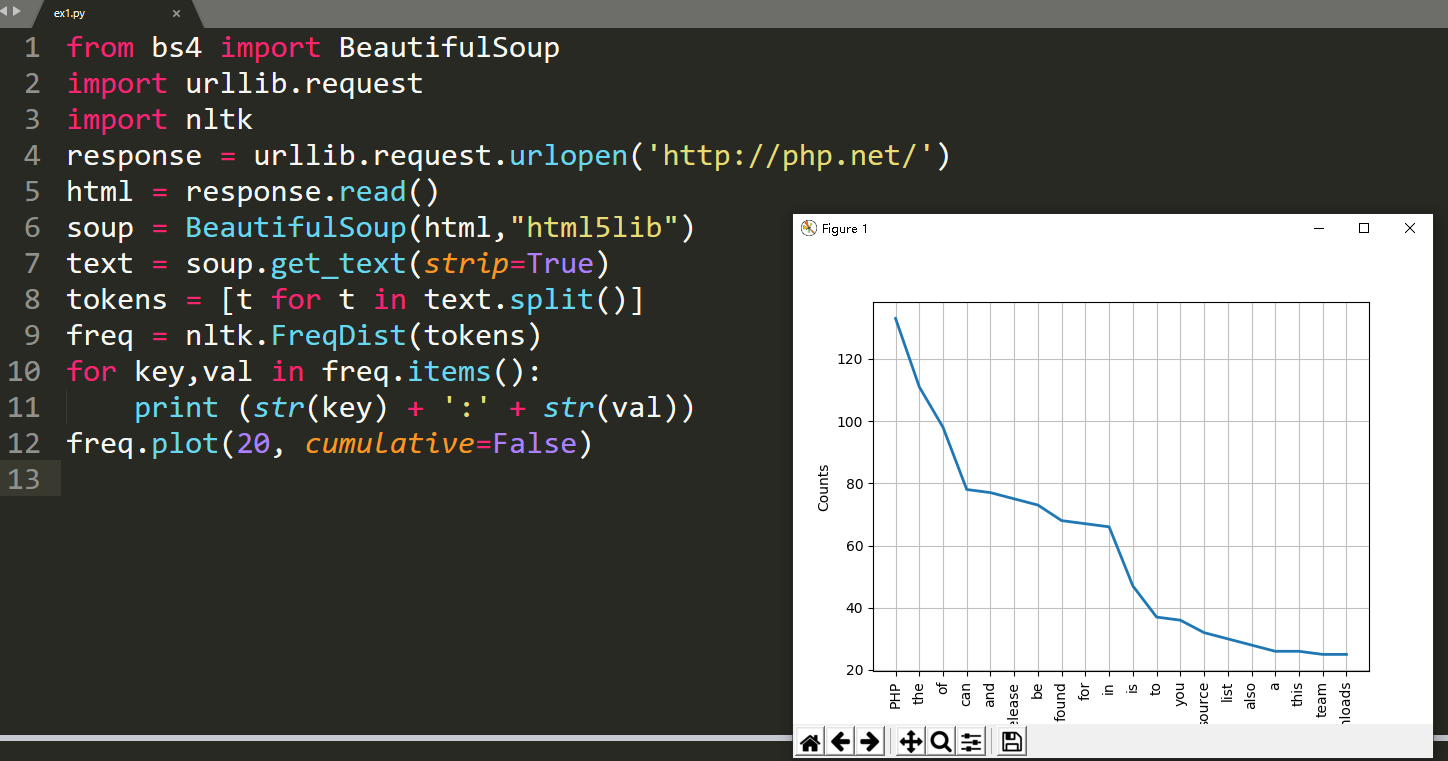
从图中,你可以肯定这篇文章正在谈论 PHP。这很棒!有一些词,如"the," "of," "a," "an," 等等。这些词是停止词。一般来说,停止词语应该被删除,以防止它们影响我们的结果。
使用 NLTK 删除停止词
NLTK 具有大多数语言的停止词表。要获得英文停止词,你可以使用以下代码:
from nltk.corpus import stopwords
stopwords.words('english')
现在,让我们修改我们的代码,并在绘制图形之前清理标记。首先,我们复制一个列表。然后,我们通过对列表中的标记进行遍历并删除其中的停止词:
clean_tokens = tokens[:]
sr = stopwords.words('english')
for token in tokens:
if token in stopwords.words('english'):
clean_tokens.remove(token)
你可以在这里查看Python List 函数, 了解如何处理列表。
最终的代码应该是这样的:
from bs4 import BeautifulSoup
import urllib.request
import nltk
from nltk.corpus import stopwords
response = urllib.request.urlopen('http://php.net/')
html = response.read()
soup = BeautifulSoup(html,"html5lib")
text = soup.get_text(strip=True)
tokens = [t for t in text.split()]
clean_tokens = tokens[:]
sr = stopwords.words('english')
for token in tokens:
if token in stopwords.words('english'):
clean_tokens.remove(token)
freq = nltk.FreqDist(clean_tokens)
for key,val in freq.items():
print (str(key) + ':' + str(val))
如果你现在检查图表,会感觉比之前那张图标更加清晰,因为没有了停止词的干扰。
freq.plot(20,cumulative=False)使用 NLTK 对文本分词
我们刚刚了解了如何使用 split( ) 函数将文本分割为标记 。现在,我们将看到如何使用 NLTK 对文本进行标记化。对文本进行标记化是很重要的,因为文本无法在没有进行标记化的情况下被处理。标记化意味着将较大的部分分隔成更小的单元。
你可以将段落分割为句子,并根据你的需要将句子分割为单词。NLTK 具有内置的句子标记器和词语标记器。
假设我们有如下的示例文本:
Hello Adam, how are you? I hope everything is going well. Today is a good day, see you dude.为了将这个文本标记化为句子,我们可以使用句子标记器:
from nltk.tokenize import sent_tokenize
mytext = "Hello Adam, how are you? I hope everything is going well. Today is a good day, see you dude."
print(sent_tokenize(mytext))
输出如下:
['Hello Adam, how are you?', 'I hope everything is going well.', 'Today is a good day, see you dude.']你可能会说,这是一件容易的事情。我不需要使用 NLTK 标记器,并且我可以使用正则表达式来分割句子,因为每个句子前后都有标点符号或者空格。
那么,看看下面的文字:
Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude.呃!Mr. 是一个词,虽然带有一个符号。让我们来试试使用 NLTK 进行分词:
from nltk.tokenize import sent_tokenize
mytext = "Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude."
print(sent_tokenize(mytext))
输出如下所示:
['Hello Mr. Adam, how are you?', 'I hope everything is going well.', 'Today is a good day, see you dude.']Great!结果棒极了。然后我们尝试使用词语标记器来看看它是如何工作的:
from nltk.tokenize import word_tokenize
mytext = "Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude."
print(word_tokenize(mytext))
输出如下:
['Hello', 'Mr.', 'Adam', ',', 'how', 'are', 'you', '?', 'I', 'hope', 'everything', 'is', 'going', 'well', '.', 'Today', 'is', 'a', 'good', 'day', ',', 'see', 'you', 'dude', '.']正如所料,Mr. 是一个词,也确实被 NLTK 当做一个词。NLTK使用 nltk.tokenize.punkt module 中的 PunktSentenceTokenizer 进行文本分词。这个标记器经过了良好的训练,可以对多种语言进行分词 。
标记非英语语言文本
为了标记其他语言,可以像这样指定语言:
from nltk.tokenize import sent_tokenize
mytext = "Bonjour M. Adam, comment allez-vous? J'espère que tout va bien. Aujourd'hui est un bon jour."
print(sent_tokenize(mytext,"french"))
结果将是这样的:
['Bonjour M. Adam, comment allez-vous?', "J'espère que tout va bien.", "Aujourd'hui est un bon jour."]NLTk 对其他非英语语言的支持也非常好!
从 WordNet 获取同义词
如果你还记得我们使用 nltk.download( ) 安装 NLTK 的扩展包时。其中一个扩展包名为 WordNet。WordNet 是为自然语言处理构建的数据库。它包括部分词语的一个同义词组和一个简短的定义。
通过 NLTK 你可以得到给定词的定义和例句:
from nltk.corpus import wordnet
syn = wordnet.synsets("pain")
print(syn[0].definition())
print(syn[0].examples())
结果是:
a symptom of some physical hurt or disorder
['the patient developed severe pain and distension']
WordNet 包含了很多词的定义:
from nltk.corpus import wordnet
syn = wordnet.synsets("NLP")
print(syn[0].definition())
syn = wordnet.synsets("Python")
print(syn[0].definition())
结果是:
the branch of information science that deals with natural language information
large Old World boas
您可以使用 WordNet 来获得同义词:
from nltk.corpus import wordnet
synonyms = []
for syn in wordnet.synsets('Computer'):
for lemma in syn.lemmas():
synonyms.append(lemma.name())
print(synonyms)
输出是:
['computer', 'computing_machine', 'computing_device', 'data_processor', 'electronic_computer', 'information_processing_system', 'calculator', 'reckoner', 'figurer', 'estimator', 'computer']Cool!
从 WordNet 获取反义词
你可以用同样的方法得到单词的反义词。你唯一要做的是在将 lemmas 的结果加入数组之前,检查结果是否确实是一个正确的反义词。
from nltk.corpus import wordnet
antonyms = []
for syn in wordnet.synsets("small"):
for l in syn.lemmas():
if l.antonyms():
antonyms.append(l.antonyms()[0].name())
print(antonyms)
输出是:
['large', 'big', 'big']这就是 NLTK 在自然语言处理中的力量。
NLTK词干提取
单词词干提取就是从单词中去除词缀并返回词根。(比方说 working 的词干是 work。)搜索引擎在索引页面的时候使用这种技术,所以很多人通过同一个单词的不同形式进行搜索,返回的都是相同的,有关这个词干的页面。
词干提取的算法有很多,但最常用的算法是 Porter 提取算法。NLTK 有一个 PorterStemmer 类,使用的就是 Porter 提取算法。
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
print(stemmer.stem('working'))
结果是: work
结果很清楚。
还有其他一些提取算法,如 Lancaster 提取算法。这个算法的输出同 Porter 算法的结果在几个单词上不同。你可以尝试他们两个算法来查看有哪些不同结果。
提取非英语单词词干
SnowballStemmer 类,除了英语外,还可以适用于其他 13 种语言。支持的语言如下:
from nltk.stem import SnowballStemmer
print(SnowballStemmer.languages)
'danish', 'dutch', 'english', 'finnish', 'french', 'german', 'hungarian', 'italian', 'norwegian', 'porter', 'portuguese', 'romanian', 'russian', 'spanish', 'swedish'
你可以使用 SnowballStemmer 类的 stem( )函数来提取非英语单词,如下所示:
from nltk.stem import SnowballStemmer
french_stemmer = SnowballStemmer('french')
print(french_stemmer.stem("French word"))
来自法国的朋友欢迎在评论区 poll 出你们测试的结果!
使用 WordNet 引入词汇
词汇的词汇化与提取词干类似,但不同之处在于词汇化的结果是一个真正的词汇。与词干提取不同,当你试图提取一些词干时,有可能会导致这样的情况:
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
print(stemmer.stem('increases'))
结果是:increas。
现在,如果我们试图用NLTK WordNet来还原同一个词,结果会是正确的:
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('increases'))
结果是 increase。
结果可能是同义词或具有相同含义的不同词语。有时,如果你试图还原一个词,比如 playing,还原的结果还是 playing。这是因为默认还原的结果是名词,如果你想得到动词,可以通过以下的方式指定。
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('playing', pos="v"))
结果是: play。
实际上,这是一个非常好的文本压缩水平。最终压缩到原文本的 50% 到 60% 左右。结果可能是动词,名词,形容词或副词:
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('playing', pos="v"))
print(lemmatizer.lemmatize('playing', pos="n"))
print(lemmatizer.lemmatize('playing', pos="a"))
print(lemmatizer.lemmatize('playing', pos="r"))
结果是:
play
playing
playing
playing
词干化和词化差异
好吧,让我们分别尝试一些单词的词干提取和词形还原:
from nltk.stem import WordNetLemmatizer
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()
print(stemmer.stem('stones'))
print(stemmer.stem('speaking'))
print(stemmer.stem('bedroom'))
print(stemmer.stem('jokes'))
print(stemmer.stem('lisa'))
print(stemmer.stem('purple'))
print('----------------------')
print(lemmatizer.lemmatize('stones'))
print(lemmatizer.lemmatize('speaking'))
print(lemmatizer.lemmatize('bedroom'))
print(lemmatizer.lemmatize('jokes'))
print(lemmatizer.lemmatize('lisa'))
print(lemmatizer.lemmatize('purple'))
结果是:
stone
speak
bedroom
joke
lisa
purpl
----------------------
stone
speaking
bedroom
joke
lisa
purple
词干提取的方法可以在不知道语境的情况下对词汇使用,这就是为什么它相较词形还原方法速度更快但准确率更低。
在我看来,词形还原比提取词干的方法更好。词形还原,如果实在无法返回这个词的变形,也会返回另一个真正的单词;这个单词可能是一个同义词,但不管怎样这是一个真正的单词。当有时候,你不关心准确度,需要的只是速度。在这种情况下,词干提取的方法更好。
我们在本 NLP 教程中讨论的所有步骤都涉及到文本预处理。在以后的文章中,我们将讨论使用Python NLTK进行文本分析。
python机器学习——NLTK及分析文本数据(自然语言处理基础)
自然语言处理—文本情感分析
Python NLTK 自然语言处理入门与例程(转)的更多相关文章
- Python+NLTK自然语言处理学习(一):环境搭建
Python+NLTK自然语言处理学习(一):环境搭建 参考黄聪的博客地址:http://www.cnblogs.com/huangcong/archive/2011/08/29/2157437.ht ...
- python之自然语言处理入门(一)
前言 NTLK是著名的Python自然语言处理工具包,记录一下学习NTLK的总结. 安装nltk pip install nltk # 测试 import nltk 安装相关的包 import nlt ...
- python+NLTK 自然语言学习处理:环境搭建
首先在http://nltk.org/install.html去下载相关的程序.需要用到的有python,numpy,pandas, matplotlib. 当安装好所有的程序之后运行nltk.dow ...
- python+NLTK 自然语言学习处理二:文本
在前面讲nltk安装的时候,我们下载了很多的文本.总共有9个文本.那么如何找到这些文本呢: text1: Moby Dick by Herman Melville 1851 text2: Sense ...
- python+NLTK 自然语言学习处理八:分类文本一
从这一章开始将进入到关键部分:模式识别.这一章主要解决下面几个问题 1 怎样才能识别出语言数据中明显用于分类的特性 2 怎样才能构建用于自动执行语言处理任务的语言模型 3 从这些模型中我们可以学到那些 ...
- python+NLTK 自然语言学习处理七:N-gram标注
在上一章中介绍了用pos_tag进行词性标注.这一章将要介绍专门的标注器. 首先来看一元标注器,一元标注器利用一种简单的统计算法,对每个标识符分配最有可能的标记,建立一元标注器的技术称为训练. fro ...
- python+NLTK 自然语言学习处理六:分类和标注词汇一
在一段句子中是由各种词汇组成的.有名词,动词,形容词和副词.要理解这些句子,首先就需要将这些词类识别出来.将词汇按它们的词性(parts-of-speech,POS)分类并相应地对它们进行标注.这个过 ...
- python+NLTK 自然语言学习处理五:词典资源
前面介绍了很多NLTK中携带的词典资源,这些词典资源对于我们处理文本是有大的作用的,比如实现这样一个功能,寻找由egivronl几个字母组成的单词.且组成的单词每个字母的次数不得超过egivronl中 ...
- python+NLTK 自然语言学习处理四:获取文本语料和词汇资源
在前面我们通过from nltk.book import *的方式获取了一些预定义的文本.本章将讨论各种文本语料库 1 古腾堡语料库 古腾堡是一个大型的电子图书在线网站,网址是http://www.g ...
随机推荐
- InstallUtil操作WindowsService
要安装windows service 首先要找到 InstallUtil.exe,InstallUtil.exe位置在 C:\Windows\Microsoft.NET\Framework\v4.0. ...
- Confluence 6 注册单一小工具
如果你不能订阅一个应用的小工具,你需要将小工具一个一个的添加进来.针对网站不支持小工具订阅和你的应用和你的 Confluence 不能建立信任连接的情况,你就只能这样添加了. 首先你需要获得小工具的 ...
- Java的家庭记账本程序(E)
日期:2019.2.9 博客期:032 星期二 今天是把程序的相关Bug补一补,嗯`: 1.添加了跳转说明 生成了一个对于成员的权限声明内容,用户再登陆界面点击Go按钮后,切换至说明页面,再次点击Go ...
- django模板导入外部js和css等文件
1.新建文件夹templates(存放模板文件),新建文件夹media(存放js.css.images文件夹),并把两个文件夹放到了项目的根目录下 2.设定模板路径 设置模板路径比较简单,只要在set ...
- 声明寄存器ROM
:] ROM [:] ; integer i; initial begin ;i<=;i=i+) begin ROM[i] <= {{'b0}}; end end 同时可以考虑双端口ROM ...
- linux下安装mysql-5.6.41
1.下载安装包,下载地址:https://dev.mysql.com/downloads/mysql/5.7.html#downloads .选择完版本,然后点击下方 No thanks, just ...
- 获取表单内的所有元素的值 表单格式化插件jquery.serializeJSON
简单描述:一个form表单里有十几个input或者select,要获取到他们的值,我的做法一直都是$("#id").val();这样做本来没什么说的,但是如果有很多呢,就很麻烦,看 ...
- Metasploit 使用后门和Rootkit维持访问
1.内存攻击指的是攻击者利用软件的漏洞,构造恶意的输入导致软件在处理输入数据时出现非预期的错误,将输入数据写入内存中的某些敏感位置,从而劫持软件控制流,转而执行外部的指令代码,造成目标系统获取远程控制 ...
- Niagara 泵阀
1.泵阀系统 2.Niagara 每次在启动workbench的时候安装一下daemon,后启动platform 启动station的时候,当station的status变成Running之后启动
- selenium 操作键盘
send_keys(Keys.ENTER) 按下回车键send_keys(Keys.TAB) 按下Tab制表键send_keys(Keys.SPACE) 按下空格键spacesend_keys(Kye ...