Day035--Python--管道, Manager, 进程池, 线程切换
管道
- #创建管道的类:
- Pipe([duplex]):在进程之间创建一条管道,并返回元组(conn1,conn2),其中conn1,conn2表示管道两端的连接对象,强调一点:必须在产生Process对象之前产生管道
- #参数介绍:
- dumplex:默认管道是全双工的,如果将duplex设置成False,conn1只能用于接收,conn2只能用于发送。
- #主要方法:
- conn1.recv():接收conn2.send(obj)发送的对象。如果没有消息可接收,recv方法会一直阻塞。如果连接的另外一端已经关闭,那么recv方法会抛出EOFError。
- conn1.send(obj):通过连接发送对象。obj是与序列化兼容的任意对象
- #其他方法:
- conn1.close():关闭连接。如果conn1被垃圾回收,将自动调用此方法
- conn1.fileno():返回连接使用的整数文件描述符
- conn1.poll([timeout]):如果连接上的数据可用,返回True。timeout指定等待的最长时限。如果省略此参数,方法将立即返回结果。如果将timeout设成None,操作将无限期地等待数据到达。
- conn1.recv_bytes([maxlength]):接收c.send_bytes()方法发送的一条完整的字节消息。maxlength指定要接收的最大字节数。如果进入的消息,超过了这个最大值,将引发IOError异常,并且在连接上无法进行进一步读取。如果连接的另外一端已经关闭,再也不存在任何数据,将引发EOFError异常。
- conn.send_bytes(buffer [, offset [, size]]):通过连接发送字节数据缓冲区,buffer是支持缓冲区接口的任意对象,offset是缓冲区中的字节偏移量,而size是要发送字节数。结果数据以单条消息的形式发出,然后调用c.recv_bytes()函数进行接收
- conn1.recv_bytes_into(buffer [, offset]):接收一条完整的字节消息,并把它保存在buffer对象中,该对象支持可写入的缓冲区接口(即bytearray对象或类似的对象)。offset指定缓冲区中放置消息处的字节位移。返回值是收到的字节数。如果消息长度大于可用的缓冲区空间,将引发BufferTooShort异常。
- 管道介绍
了解
- from multiprocessing import Process, Pipe
- conn1, conn2 = Pipe()
- conn1.send('你好')
- print('>>>>>>>>>>>')
- msg = conn2.recv()
- print(msg)
- from multiprocessing import Process, Pipe
- def func1(conn2):
- msg = conn2.recv()
- print(msg)
- if __name__ == '__main__':
- conn1, conn2 = Pipe()
- p = Process(target=func1, args=(conn2,))
- p.start()
- conn1.send('你好啊,我叫赛利亚')
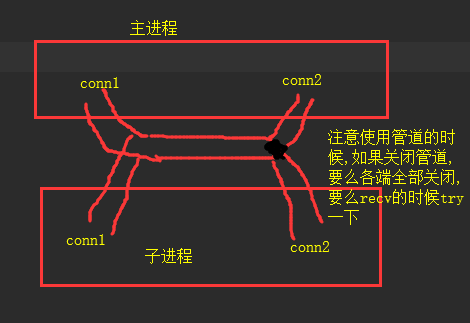
管道错误模拟: 管道关闭, 异常处理
- from multiprocessing import Process, Pipe
- def func(conn2):
- while 1:
- try:
- # 如果管道一端关闭了, 另外一端接收消息时会报错, 要使用异常处理
- msg = conn2.recv()
- print(msg)
- except EOFError:
- print('对方管道已关闭')
- conn2.close()
- break
- if __name__ == '__main__':
- conn1, conn2 = Pipe()
- p = Process(target=func, args=(conn2,))
- p.start()
- conn1.send('你好啊')
- conn1.close()
- # conn1.recv() # OSError: handle is closed
数据共享
Manager
- 进程间数据是独立的,可以借助于队列或管道实现通信,二者都是基于消息传递的
- 虽然进程间数据独立,但可以通过Manager实现数据共享,事实上Manager的功能远不止于此
- A manager object returned by Manager() controls a server process which holds Python objects and allows other processes to manipulate them using proxies.
- A manager returned by Manager() will support types list, dict, Namespace, Lock, RLock, Semaphore, BoundedSemaphore, Condition, Event, Barrier, Queue, Value and Array.
- from multiprocessing import Process, Manager
- def func(m_dic):
- m_dic['name'] = '大猪蹄子' # 修改共享数据
- if __name__ == '__main__':
- m = Manager()
- m_dic = m.dict({'name': '大佬'}) # 创建共享数据
- print('原始>>>', m_dic) # 打印初始共享数据
- p = Process(target=func, args=(m_dic,))
- p.start()
- p.join()
- print('主进程>>>>', m_dic) # 打印的是修改后的共享数据
- '''
- 多进程同时获取数据, 修改后重新赋值, 可能同时拿到100, 减1后都把99赋值回去, 得到的数据不准确,数据不安全
- 可以通过加锁解决
- '''
- from multiprocessing import Process, Manager
- def func(m_dic):
- m_dic['count'] -= 1
- if __name__ == '__main__':
- m = Manager()
- m_dic = m.dict({'count': 100})
- lst = []
- for i in range(50):
- p = Process(target=func, args=(m_dic,))
- p.start()
- lst.append(p)
- [p.join() for p in lst]
- print('主进程>>>', m_dic)
- # 加锁, 解决数据错乱问题
- from multiprocessing import Process, Manager, Lock
- def func(m_dic, ml):
- # with ml: 下面的缩进内容等同于 ml.acquire() ml.release() 之间的内容, 作用: 加锁
- with ml:
- m_dic['count'] -= 1
- if __name__ == '__main__':
- m = Manager()
- ml = Lock()
- m_dic = m.dict({'count': 100})
- lst = []
- for i in range(50):
- p = Process(target=func, args=(m_dic, ml))
- p.start()
- lst.append(p)
- [p.join() for p in lst]
- print(m_dic)
进程池
什么是进程池?进程池的作用. 并行 并发 同步 异步 阻塞 非阻塞 互斥 死锁.
- import time
- from multiprocessing import Process, Pool
- def func(n):
- time.sleep(1)
- print(n)
- if __name__ == '__main__':
- pool = Pool(4) # 设置进程数量, 如果不设置, 默认是CPU数量
- pool.map(func, range(100)) # map自带join功能, 异步执行任务, 参数是可迭代对象
进程池比多进程效率高
- import time
- from multiprocessing import Process, Pool
- def func(n):
- for i in range(100):
- n += 1
- print(n)
- if __name__ == '__main__':
- pool_start_time = time.time()
- pool = Pool()
- pool.map(func, range(100))
- pool_end_time = time.time()
- pool_dif_time = pool_end_time - pool_start_time
- lst = []
- p_s_time = time.time()
- for i in range(100):
- p = Process(target=func, args=(i,))
- p.start()
- lst.append(p)
- [p.join() for p in lst]
- p_e_time = time.time()
- pd_time = p_e_time - p_s_time
- print('进程池执行时间>>>', pool_dif_time)
- print('多进程执行时间>>>', pd_time)
进程池与多进程运行时间对比
- import time
- from multiprocessing import Process, Pool
- def func(i):
- time.sleep(0.5)
- print(i**2)
- if __name__ == '__main__':
- pool = Pool(4)
- pool_s_time = time.time()
- pool.map(func, range(100))
- pool_e_time = time.time()
- pool_dif_time = pool_e_time - pool_s_time
- p_lst = []
- p_s_time = time.time()
- for i in range(100):
- p = Process(target=func, args=(i,))
- p.start()
- p_lst.append(p)
- [p.join() for p in p_lst]
- p_e_time = time.time()
- p_dif_time = p_e_time - p_s_time
- print('数据池执行时间:', pool_dif_time)
- print('多进程运行时间:', p_dif_time)
这种情况下进程池比多进程 运行慢
进程池的同步方法: apply
- import time
- from multiprocessing import Process, Pool
- def fun(i):
- time.sleep(0.5)
- # print(i)
- return i**2
- if __name__ == '__main__':
- p = Pool(4)
- for i in range(10):
- res = p.apply(fun, args=(i,)) # 同步执行的方法, 它会等待任务的返回结果(return)
- print(res) # 打印的是fun的返回值(return)
- print('主进程结束') # 子进程都结束后打印
进程池的异步方法: apply_async # [ apply()方法的变体,它返回一个结果对象。]
- import time
- from multiprocessing import Process, Pool
- def fun(i):
- time.sleep(0.5)
- return i**2
- if __name__ == '__main__':
- p = Pool(4)
- res_lst = []
- for i in range(10):
- res = p.apply_async(fun, args=(i,)) # 异步执行, res是对象multiprocessing.pool.ApplyResult object 主进程代码执行完毕不会等待子进程, 直接关闭主进程.
- res_lst.append(res)
- for i in res_lst:
- print(i.get())
- print('主进程结束') # 如果没有i.get()方法, 则主进程不会等待子进程执行完就会结束

get([timeout])
在产生结果时返回该结果。如果超时限制不是空, 而且结果没有在时限内返回, 则抛出多进程超时错误。 如果远程调用报出异常,那么get()方法将再次抛出这个异常。
- # 如果不加close和join, 程序会直接随主进程结束运行,不会等待打印i. 加join后可以感知进程的运行
- import time
- from multiprocessing import Process, Pool
- def fun(i):
- time.sleep(0.5)
- print(i)
- return i**2
- if __name__ == '__main__':
- p = Pool(4)
- res_lst = []
- for i in range(10):
- res = p.apply_async(fun, args=(i,))
- res_lst.append(res)
- # print(res) # 异步执行, res是多个对象 <multiprocessing.pool.ApplyResult object at 0x000001B5BBD7C128>
- p.close() # 不是关闭进程池,而是不允许再有其他任务来使用进程池
- p.join() # 这是感知进程池中任务的方法,等待进程池的任务全部执行完
- for el in res_lst:
- print('结果>>>', el.get())
# time.sleep(4) # 如果把close和join还有for循环都注释掉, 此处等待几秒也可以打印出i- print('主进程结束')
回调函数 callback
- import os
- from multiprocessing import Process, Pool
- def func1(n):
- print('func1', os.getpid())
- return n*n
- def func2(nn):
- print('func2', os.getpid())
- print(nn)
- if __name__ == '__main__':
- print('主进程:', os.getpid())
- p = Pool(4)
- p.apply_async(func1, args=(10,), callback=func2) #把func的返回结果传参给func2, func2 在主进程中运行 如果func1返回多个结果, 那么将以元组的形式传给func2
- p.close()
- p.join()
线程切换
- #什么是线程:
- #指的是一条流水线的工作过程,关键的一句话:一个进程内最少自带一个线程,其实进程根本不能执行,进程不是执行单位,是资源的单位,分配资源的单位
- #线程才是执行单位
- #进程:做手机屏幕的工作过程,刚才讲的
- #我们的py文件在执行的时候,如果你站在资源单位的角度来看,我们称为一个主进程,如果站在代码执行的角度来看,它叫做主线程,只是一种形象的说法,其实整个代码的执行过程成为线程,也就是干这个活儿的本身称为线程,但是我们后面学习的时候,我们就称为线程去执行某个任务,其实那某个任务的执行过程称为一个线程,一条流水线的执行过程为线程
- #进程vs线程
- #1 同一个进程内的多个线程是共享该进程的资源的,不同进程内的线程资源肯定是隔离的
- #2 创建线程的开销比创建进程的开销要小的多
- #并发三个任务:1启动三个进程:因为每个进程中有一个线程,但是我一个进程中开启三个线程就够了
- #同一个程序中的三个任务需要执行,你是用三个进程好 ,还是三个线程好?
- #例子:
- # pycharm 三个任务:键盘输入 屏幕输出 自动保存到硬盘
- #如果三个任务是同步的话,你键盘输入的时候,屏幕看不到
- #咱们的pycharm是不是一边输入你边看啊,就是将串行变为了三个并发的任务
- #解决方案:三个进程或者三个线程,哪个方案可行。如果是三个进程,进程的资源是不是隔离的并且开销大,最致命的就是资源隔离,但是用户输入的数据还要给另外一个进程发送过去,进程之间能直接给数据吗?你是不是copy一份给他或者通信啊,但是数据是同一份,我们有必要搞多个进程吗,线程是不是共享资源的,我们是不是可以使用多线程来搞,你线程1输入的数据,线程2能不能看到,你以后的场景还是应用多线程多,而且起线程我们说是不是很快啊,占用资源也小,还能共享同一个进程的资源,不需要将数据来回的copy!
什么是线程
线程的创建方法一:
- # 线程和进程很像, 一个进程中至少有一个线程, 进程是资源层面的, 线程负责实际的操作
- import time
- from threading import Thread
- def func(n):
- time.sleep(1) # 子线程运行地太快了, 如果不加time.sleep,会在打印主线程之前跑完
- print(123)
- if __name__ == '__main__':
- t = Thread(target=func, args=(1,))
- t.start()
- t.join() # 等待子线程跑完再执行主线程下面的内容
- print('主线程')
线程的创建方法二:
- from threading import Thread
- class MyThread(Thread):
- def __init__(self, n):
- super().__init__()
- self.n = n
- def run(self):
- print('换汤不换药')
- print('self.n>>>', self.n)
- if __name__ == '__main__':
- t = MyThread('你好')
- t.start()
- t.join()
- print('主线程结束')
Day035--Python--管道, Manager, 进程池, 线程切换的更多相关文章
- python并发编程-进程池线程池-协程-I/O模型-04
目录 进程池线程池的使用***** 进程池/线程池的创建和提交回调 验证复用池子里的线程或进程 异步回调机制 通过闭包给回调函数添加额外参数(扩展) 协程*** 概念回顾(协程这里再理一下) 如何实现 ...
- day 32 管道,信号量,进程池,线程的创建
1.管道(了解) Pipe(): 在进程之间建立一条通道,并返回元组(conn1,conn2),其中conn1,conn2表示管道两端的连接对象,强调一点:必须在产生Process对象之前产生管道. ...
- Python中的进程池与线程池(包含代码)
Python中的进程池与线程池 引入进程池与线程池 使用ProcessPoolExecutor进程池,使用ThreadPoolExecutor 使用shutdown 使用submit同步调用 使用su ...
- Python并发编程05 /死锁现象、递归锁、信号量、GIL锁、计算密集型/IO密集型效率验证、进程池/线程池
Python并发编程05 /死锁现象.递归锁.信号量.GIL锁.计算密集型/IO密集型效率验证.进程池/线程池 目录 Python并发编程05 /死锁现象.递归锁.信号量.GIL锁.计算密集型/IO密 ...
- python中的进程、线程(threading、multiprocessing、Queue、subprocess)
Python中的进程与线程 学习知识,我们不但要知其然,还是知其所以然.你做到了你就比别人NB. 我们先了解一下什么是进程和线程. 进程与线程的历史 我们都知道计算机是由硬件和软件组成的.硬件中的CP ...
- concurrent.futures模块(进程池/线程池)
需要注意一下不能无限的开进程,不能无限的开线程最常用的就是开进程池,开线程池.其中回调函数非常重要回调函数其实可以作为一种编程思想,谁好了谁就去掉 只要你用并发,就会有锁的问题,但是你不能一直去自己加 ...
- concurrent.futures模块(进程池&线程池)
1.线程池的概念 由于python中的GIL导致每个进程一次只能运行一个线程,在I/O密集型的操作中可以开启多线程,但是在使用多线程处理任务时候,不是线程越多越好,因为在线程切换的时候,需要切换上下文 ...
- python中的进程池
1.进程池的概念 python中,进程池内部会维护一个进程序列.当需要时,程序会去进程池中获取一个进程. 如果进程池序列中没有可供使用的进程,那么程序就会等待,直到进程池中有可用进程为止. 2.进程池 ...
- 13 并发编程-(线程)-异步调用与回调机制&进程池线程池小练习
#提交任务的两种方式 #1.同步调用:提交完任务后,就在原地等待任务执行完毕,拿到结果,再执行下一行代码,导致程序是串行执行 一.提交任务的两种方式 1.同步调用:提交任务后,就在原地等待任务完毕,拿 ...
随机推荐
- 如何在网页中用echarts图表插件做出静态呈现效果
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- python数学第四天【古典概型】
- JS--innerHTML属性
innerHTML属性,不是DOM的组成部分(常用) 获取标签里的文本内容,var span=document.getElementById("span").innerHTML; ...
- iOS的非常全的三方库,插件,大牛博客
转自: http://www.cnblogs.com/zyjzyj/p/6015625.html github排名:https://github.com/trending, github搜索:http ...
- int,String转换
int -> String 第一种方法:s=i+""; //会产生两个String对象 第二种方法:s=String.valueOf(i); //直接使用String类的静态 ...
- [BZOJ 2705] [SDOI 2012] Longge的问题
Description Longge的数学成绩非常好,并且他非常乐于挑战高难度的数学问题.现在问题来了:给定一个整数 \(N\),你需要求出 \(\sum gcd(i, N)(1\le i \le N ...
- Quartz基础+实例
1. 介绍 Quartz体系结构: 明白Quartz怎么用,首先要了解Scheduler(调度器).Job(任务)和Trigger(触发器)这3个核心的概念. 1. Job: 是一个接口,只定义一个方 ...
- 用牛顿-拉弗森法定义平方根函数(Newton-Raphson method Square Root Python)
牛顿法(Newton’s method)又称为牛顿-拉弗森法(Newton-Raphson method),是一种近似求解实数方程式的方法.(注:Joseph Raphson在1690年出版的< ...
- 基于FPGA的数字秒表(数码管显示模块和按键消抖)实现
本文主要是学习按键消抖和数码管动态显示,秒表显示什么的,个人认为,拿FPGA做秒表真是嫌钱多. 感谢 感谢学校和至芯科技,笔者专业最近去北京至芯科技培训交流了一周.老师的经验还是可以的,优化了自己的代 ...
- 【BZOJ3157/3516】国王奇遇记(数论)
[BZOJ3157/3516]国王奇遇记(数论) 题面 BZOJ3157 BZOJ3516 题解 先考虑怎么做\(m\le 100\)的情况. 令\(f(n,k)=\displaystyle \sum ...