数据库入门-基本sql语句及数据类型
一、基本sql语句
SQL语言主要用于存取数据、查询数据、更新数据和管理关系数据库系统,SQL语言由IBM开发。SQL语言分为3种类型:
- #1、DDL语句 数据库定义语言: 数据库、表、视图、索引、存储过程,例如CREATE DROP ALTER
- #2、DML语句 数据库操纵语言: 插入数据INSERT、删除数据DELETE、更新数据UPDATE、查询数据SELECT
- #3、DCL语句 数据库控制语言: 例如控制用户的访问权限GRANT、REVOKE
(一)数据库相关
1.系统数据库
information_schema: 虚拟库,不占用磁盘空间,存储的是数据库启动后的一些参数,如用户表信息、列信息、权限信息、字符信息等
performance_schema: MySQL 5.5开始新增一个数据库:主要用于收集数据库服务器性能参数,记录处理查询请求时发生的各种事件、锁等现象
mysql: 授权库,主要存储系统用户的权限信息
test: MySQL数据库系统自动创建的测试数据库
2.创建数据库
- CREATE DATABASE 数据库名 engine innodb charset utf8mb4;
数据库的命名规则:
- 可以由字母、数字、下划线、@、#、$
- 区分大小写
- 唯一性
- 不能使用关键字如 create select
- 不能单独使用数字
- 最长128位
3.数据库的增删改查
- 1 查看数据库
- show databases; #查看所有数据库
- show create database db1; #查看如何创建的
- select database();#查看当前所在数据库
- 2 选择数据库
- USE 数据库名
- 3 删除数据库
- DROP DATABASE 数据库名;
- 4 修改数据库
- alter database db1 charset utf8;
(二)、表相关操作
1.存储引擎介绍
存储引擎就是表的类型,mysql根据不同的表类型会有不同的处理机制。
表就相当于是文件,现实生活中我们用来存储数据的文件有不同的类型,每种文件类型对应各自不同的处理机制:比如处理文本用txt类型,处理表格用excel,处理图片用png等。表也有不同的类型,对应的称为存储引擎。
存储引擎就是如何实现存储数据、如何为存储的数据建立索引和如何更新、查询等技术的实现方法。
在Oracle 和SQL Server等数据库中只有一种存储引擎,所有数据存储管理机制都是一样的。而MySql数据库提供了多种存储引擎。用户可以根据不同的需求为数据表选择不同的存储引擎,用户也可以根据自己的需要编写自己的存储引擎。
- show engines\G #查看所有支持的存储引擎
- show variables like 'storage_engine%'; #查看正在使用的存储引擎
- #InnoDB 存储引擎
- 支持事务,其设计目标主要面向联机事务处理(OLTP)的应用。其
- 特点是行锁设计、支持外键,并支持类似 Oracle 的非锁定读,即默认读取操作不会产生锁。 从 MySQL 5.5.8 版本开始是默认的存储引擎。
- InnoDB 存储引擎将数据放在一个逻辑的表空间中,这个表空间就像黑盒一样由 InnoDB 存储引擎自身来管理。从 MySQL 4.1(包括 4.1)版本开始,可以将每个 InnoDB 存储引擎的 表单独存放到一个独立的 ibd 文件中。此外,InnoDB 存储引擎支持将裸设备(row disk)用 于建立其表空间。
- InnoDB 通过使用多版本并发控制(MVCC)来获得高并发性,并且实现了 SQL 标准 的 4 种隔离级别,默认为 REPEATABLE 级别,同时使用一种称为 netx-key locking 的策略来 避免幻读(phantom)现象的产生。除此之外,InnoDB 存储引擎还提供了插入缓冲(insert buffer)、二次写(double write)、自适应哈希索引(adaptive hash index)、预读(read ahead) 等高性能和高可用的功能。
- 对于表中数据的存储,InnoDB 存储引擎采用了聚集(clustered)的方式,每张表都是按 主键的顺序进行存储的,如果没有显式地在表定义时指定主键,InnoDB 存储引擎会为每一 行生成一个 6 字节的 ROWID,并以此作为主键。
- InnoDB 存储引擎是 MySQL 数据库最为常用的一种引擎,Facebook、Google、Yahoo 等 公司的成功应用已经证明了 InnoDB 存储引擎具备高可用性、高性能以及高可扩展性。对其 底层实现的掌握和理解也需要时间和技术的积累。如果想深入了解 InnoDB 存储引擎的工作 原理、实现和应用,可以参考《MySQL 技术内幕:InnoDB 存储引擎》一书。
- #MyISAM 存储引擎
- 不支持事务、表锁设计、支持全文索引,主要面向一些 OLAP 数 据库应用,在 MySQL 5.5.8 版本之前是默认的存储引擎(除 Windows 版本外)。数据库系统 与文件系统一个很大的不同在于对事务的支持,MyISAM 存储引擎是不支持事务的。究其根 本,这也并不难理解。用户在所有的应用中是否都需要事务呢?在数据仓库中,如果没有 ETL 这些操作,只是简单地通过报表查询还需要事务的支持吗?此外,MyISAM 存储引擎的 另一个与众不同的地方是,它的缓冲池只缓存(cache)索引文件,而不缓存数据文件,这与 大多数的数据库都不相同。
- #NDB 存储引擎
- 2003 年,MySQL AB 公司从 Sony Ericsson 公司收购了 NDB 存储引擎。 NDB 存储引擎是一个集群存储引擎,类似于 Oracle 的 RAC 集群,不过与 Oracle RAC 的 share everything 结构不同的是,其结构是 share nothing 的集群架构,因此能提供更高级别的 高可用性。NDB 存储引擎的特点是数据全部放在内存中(从 5.1 版本开始,可以将非索引数 据放在磁盘上),因此主键查找(primary key lookups)的速度极快,并且能够在线添加 NDB 数据存储节点(data node)以便线性地提高数据库性能。由此可见,NDB 存储引擎是高可用、 高性能、高可扩展性的数据库集群系统,其面向的也是 OLTP 的数据库应用类型。
- #Memory 存储引擎
- 正如其名,Memory 存储引擎中的数据都存放在内存中,数据库重 启或发生崩溃,表中的数据都将消失。它非常适合于存储 OLTP 数据库应用中临时数据的临时表,也可以作为 OLAP 数据库应用中数据仓库的维度表。Memory 存储引擎默认使用哈希 索引,而不是通常熟悉的 B+ 树索引。
- #Infobright 存储引擎
- 第三方的存储引擎。其特点是存储是按照列而非行的,因此非常 适合 OLAP 的数据库应用。其官方网站是 http://www.infobright.org/,上面有不少成功的数据 仓库案例可供分析。
- #NTSE 存储引擎
- 网易公司开发的面向其内部使用的存储引擎。目前的版本不支持事务, 但提供压缩、行级缓存等特性,不久的将来会实现面向内存的事务支持。
- #BLACKHOLE
- 黑洞存储引擎,可以应用于主备复制中的分发主库。
- MySQL 数据库还有很多其他存储引擎,上述只是列举了最为常用的一些引擎。如果 你喜欢,完全可以编写专属于自己的引擎,这就是开源赋予我们的能力,也是开源的魅 力所在。
mysql存储引擎介绍
2.使用存储引擎
方法一:建表时指定
- create table innodb_t2(id int)engine=innodb;
方法二:配置文件中修改
- [mysqld]
- default-storage-engine=INNODB
- innodb_file_per_table=1
注:
memory,在重启mysql或者重启机器后,表内数据清空
blackhole,往表内插入任何数据,都相当于丢入黑洞,表内永远不存记录
3.表介绍
表相当于文件,表中的一条记录相当于文件中的一段数据,不同的是表中的记录都有对应的标题,称为表的字段,其余的一行一行的内容都称为记录。
4.创建表
- create table 表名(
- 字段名1 类型[(宽度) 约束条件],
- 字段名2 类型[(宽度) 约束条件],
- 字段名3 类型[(宽度) 约束条件]
- );
- #注意:
- 1. 在同一张表中,字段名是不能相同
- 2. 宽度和约束条件可选
- 3. 字段名和类型是必须的
4. 创建之前需要先选择数据库 #use 数据库名
5.查看表
- show tables;
查看表结构============>desc 表名
查看创建表的语句========》show create 表名
6.修改表
- 语法:
- 1. 修改表名
- ALTER TABLE 表名 RENAME 新表名;
- 2. 增加字段
- ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…],
- ADD 字段名 数据类型 [完整性约束条件…];
- ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…] FIRST;
- ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…] AFTER 字段名;
- 3. 删除字段
- ALTER TABLE 表名 DROP 字段名;
- 4. 修改字段
- ALTER TABLE 表名 MODIFY 字段名 数据类型 [完整性约束条件…];
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 新数据类型 [完整性约束条件…];
7.删除表
- drop table 表名;
8.复制表
- 拷贝结构与数据---->CREATE TABLE 新表SELECT * FROM 旧表
- 仅拷贝结构---->create table copy_table select *from customer where 0 > 1;
注:索引(主键)和描述(自增)不能拷贝。
(三)、表内记录相关操作
1.插入数据
- 1. 插入完整数据(顺序插入)
- 语法一:
- INSERT INTO 表名(字段1,字段2,字段3…字段n) VALUES(值1,值2,值3…值n);
- 语法二:
- INSERT INTO 表名 VALUES (值1,值2,值3…值n);
- 2. 指定字段插入数据
- 语法:
- INSERT INTO 表名(字段1,字段2,字段3…) VALUES (值1,值2,值3…);
- 3. 插入多条记录
- 语法:
- INSERT INTO 表名 VALUES
- (值1,值2,值3…值n),
- (值1,值2,值3…值n),
- (值1,值2,值3…值n);
- 4. 插入查询结果
- 语法:
- INSERT INTO 表名(字段1,字段2,字段3…字段n)
- SELECT (字段1,字段2,字段3…字段n) FROM 表2
- WHERE …;
- 注:插入时表中的最后一个字段不要加逗号
2.修改数据
- 语法:
- UPDATE 表名 SET
- 字段1=值1,
- 字段2=值2,
- WHERE 条件;
- #不加条件就将所有 字段的值都更新
3.删除数据
- DELETE FROM 表名
- WHERE CONITION;
- #不加条件默认删除全部
(补)清空表:
- delete from t1; #如果有自增id,新增的数据,仍然是以删除前的最后一样作为起始。
- truncate table t1;数据量大,删除速度比上一条快,且直接从零开始,
- auto_increment 表示:自增
- primary key 表示:约束(不能重复且不能为空);加速查找
4.查询表数据
- SELECT 字段1,字段2... FROM 表名
- WHERE 条件
- GROUP BY field
- HAVING 筛选
- ORDER BY field
- LIMIT 限制条数
表数据的详细操作见后面章节内容!
二、数据类型
存储引擎决定了表的类型,而表内存放的数据也要有不同的类型,每种数据类型都有自己的宽度,但宽度是可选的
mysql常用数据类型预览:
- #1. 数字:
- 整型:tinyinit int bigint
- 小数:
- float :在位数比较短的情况下不精准
- double :在位数比较长的情况下不精准
- 0.000001230123123123
- 存成:0.000001230000
- decimal:(如果用小数,则用推荐使用decimal)
- 精准
- 内部原理是以字符串形式去存
- #2. 字符串:
- char(10):简单粗暴,浪费空间,存取速度快
- root存成root000000
- varchar:精准,节省空间,存取速度慢
- sql优化:创建表时,定长的类型往前放,变长的往后放
- 比如性别 比如地址或描述信息
- >255个字符,超了就把文件路径存放到数据库中。
- 比如图片,视频等找一个文件服务器,数据库中只存路径或url。
- #3. 时间类型:
- 最常用:datetime
- #4. 枚举类型与集合类型
- 枚举enum('a','b','c'):多选一
- 集合set('a','b','c'):多选多
预览
(一)、整数类型
整数类型:TINYINT SMALLINT MEDIUMINT INT BIGINT
- ========================================
- tinyint[(m)] [unsigned] [zerofill]
- 小整数,数据类型用于保存一些范围的整数数值范围:
- 有符号:
- -128 ~ 127
- 无符号:
- 0 ~ 255
- PS: MySQL中无布尔值,使用tinyint(1)构造。
- ========================================
- int[(m)][unsigned][zerofill]
- 整数,数据类型用于保存一些范围的整数数值范围:
- 有符号:
- -2147483648 ~ 2147483647
- 无符号:
- 0 ~ 4294967295
- ========================================
- bigint[(m)][unsigned][zerofill]
- 大整数,数据类型用于保存一些范围的整数数值范围:
- 有符号:
- -9223372036854775808 ~ 9223372036854775807
- 无符号:
- 0 ~ 18446744073709551615
介绍
注:为该类型指定宽度时,仅仅只是指定查询结果的显示宽度,与存储范围无关!
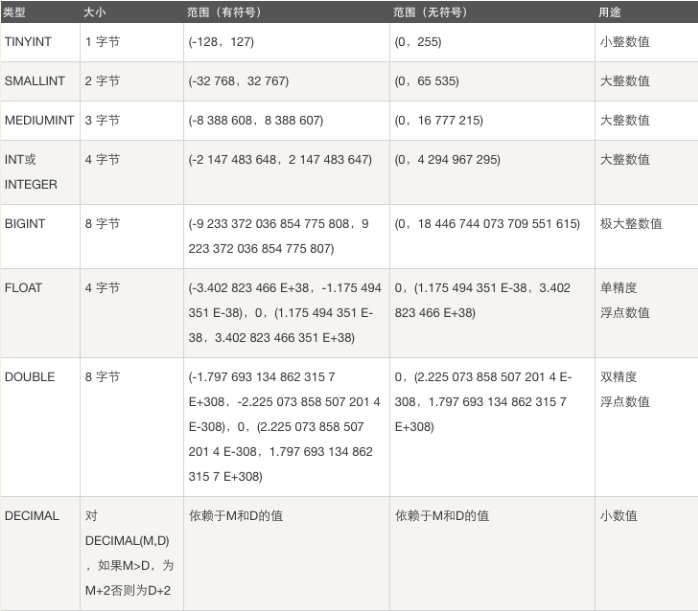
int的存储宽度是4个Bytes,即32个bit,即2**32
有符号和无符号的最大数字需要的显示宽度均为10,而针对有符号的最小值则需要11位才能显示完全,所以int类型默认的显示宽度为11是非常合理的,使用默认类型就可以了。(整型默认是有符号的)
(补)mysql中的严格模式:
就是mysql自身对数据进行严格的检验(格式、长度、类型),比如在非严格模式下,我们写入的数值数据超过了定义的长度也不会报错,他会截取最大长度存入,余下的数据丢失;将整型数据希尔字符串中也不会报错(结果没有存入),因此我们最好开启MySQL的严格模式。
5.6.6以后的版本默认开启严格模式
查看是否为严格模式:
- show variables like "sql_mode";
设置sql_mode(严格模式):
- set global sql_mode="strict_trans_tables";
- select @@sql_mode;#查看sql_mode设置
注:修改sql_mode为严格模式,必须重启客户端才能生效
(二)、浮点类型
- ======================================
- #FLOAT[(M,D)] [UNSIGNED] [ZEROFILL]
- 定义:
- 单精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。m最大值为255,d最大值为30
- 有符号:
- -3.402823466E+38 to -1.175494351E-38,
- 1.175494351E-38 to 3.402823466E+38
- 无符号:
- 1.175494351E-38 to 3.402823466E+38
- 精确度:
- **** 随着小数的增多,精度变得不准确 ****
- ======================================
- #DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL]
- 定义:
- 双精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。m最大值为255,d最大值为30
- 有符号:
- -1.7976931348623157E+308 to -2.2250738585072014E-308
- 2.2250738585072014E-308 to 1.7976931348623157E+308
- 无符号:
- 2.2250738585072014E-308 to 1.7976931348623157E+308
- 精确度:
- ****随着小数的增多,精度比float要高,但也会变得不准确 ****
- ======================================
- decimal[(m[,d])] [unsigned] [zerofill]
- 定义:
- 准确的小数值,m是数字总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。
- 精确度:
- **** 随着小数的增多,精度始终准确 ****
- 对于精确数值计算时需要用此类型
- decaimal能够存储精确值的原因在于其内部按照字符串存储。
浮点介绍
(三)、日期类型
year(年)、date(年月日)、time(时分秒)、datetime(年月日时分秒)、timestamp(当前时间的年月日时分秒)
- ============year===========
- MariaDB [db1]> create table t10(born_year year); #无论year指定何种宽度,最后都默认是year(4)
- MariaDB [db1]> insert into t10 values
- -> (1900),
- -> (1901),
- -> (2155),
- -> (2156);
- MariaDB [db1]> select * from t10;
- +-----------+
- | born_year |
- +-----------+
- | 0000 |
- | 1901 |
- | 2155 |
- | 0000 |
- +-----------+
- ============date,time,datetime===========
- MariaDB [db1]> create table t11(d date,t time,dt datetime);
- MariaDB [db1]> desc t11;
- +-------+----------+------+-----+---------+-------+
- | Field | Type | Null | Key | Default | Extra |
- +-------+----------+------+-----+---------+-------+
- | d | date | YES | | NULL | |
- | t | time | YES | | NULL | |
- | dt | datetime | YES | | NULL | |
- +-------+----------+------+-----+---------+-------+
- MariaDB [db1]> insert into t11 values(now(),now(),now());
- MariaDB [db1]> select * from t11;
- +------------+----------+---------------------+
- | d | t | dt |
- +------------+----------+---------------------+
- | 2017-07-25 | 16:26:54 | 2017-07-25 16:26:54 |
- +------------+----------+---------------------+
- ============timestamp===========
- MariaDB [db1]> create table t12(time timestamp);
- MariaDB [db1]> insert into t12 values();
- MariaDB [db1]> insert into t12 values(null);
- MariaDB [db1]> select * from t12;
- +---------------------+
- | time |
- +---------------------+
- | 2017-07-25 16:29:17 |
- | 2017-07-25 16:30:01 |
- +---------------------+
- ============注意啦,注意啦,注意啦===========
- 1. 单独插入时间时,需要以字符串的形式,按照对应的格式插入
- 2. 插入年份时,尽量使用4位值
- 3. 插入两位年份时,<=69,以20开头,比如50, 结果2050
- >=70,以19开头,比如71,结果1971
- MariaDB [db1]> create table t12(y year);
- MariaDB [db1]> insert into t12 values
- -> (50),
- -> (71);
- MariaDB [db1]> select * from t12;
- +------+
- | y |
- +------+
- | 2050 |
- | 1971 |
- +------+
test
(四)、字符串类型
- #char类型:定长,简单粗暴,浪费空间,存取速度快
- 字符长度范围:0-255(一个中文是一个字符,是utf8编码的3个字节)
- 存储:
- 存储char类型的值时,会往右填充空格来满足长度
- 例如:指定长度为10,存>10个字符则报错,存<10个字符则用空格填充直到凑够10个字符存储
- 检索:
- 在检索或者说查询时,查出的结果会自动删除尾部的空格,除非我们打开pad_char_to_full_length SQL模式(SET sql_mode = 'PAD_CHAR_TO_FULL_LENGTH';)
- #varchar类型:变长,精准,节省空间,存取速度慢
- 字符长度范围:0-65535(如果大于21845会提示用其他类型 。mysql行最大限制为65535字节,字符编码为utf-8:https://dev.mysql.com/doc/refman/5.7/en/column-count-limit.html)
- 存储:
- varchar类型存储数据的真实内容,不会用空格填充,如果'ab ',尾部的空格也会被存起来
- 强调:varchar类型会在真实数据前加1-2Bytes的前缀,该前缀用来表示真实数据的bytes字节数(1-2Bytes最大表示65535个数字,正好符合mysql对row的最大字节限制,即已经足够使用)
- 如果真实的数据<255bytes则需要1Bytes的前缀(1Bytes=8bit 2**8最大表示的数字为255)
- 如果真实的数据>255bytes则需要2Bytes的前缀(2Bytes=16bit 2**16最大表示的数字为65535)
- 检索:
- 尾部有空格会保存下来,在检索或者说查询时,也会正常显示包含空格在内的内容
官网:https://dev.mysql.com/doc/refman/5.7/en/char.html
- 相同点:宽度指的都是最大存储的字符个数,超过了都无法正常存储
- 不同点:
- char(5):
- 'm'--->'m '5个字符
- varchar(5)
- 'm'--->'m'1个字符
- set global sql_mode="strict_trans_tables,PAD_CHAR_TO_FULL_LENGTH";
- 注意:mysql在查询时针对where 字段="值 "会忽略掉右面的空格,即where 字段="值"
- 如果是like模糊匹配就不会忽略右面的空格了
在本质上,使用固定长度的CHAR列不一定比使用可变长度VARCHAR列性能要好。因而,主要的性能因素是数据行使用的存储总量。由于CHAR平均占用的空间多于VARCHAR,因此使用VARCHAR来最小化需要处理的数据行的存储总量和磁盘I/O是比较好的。
(五)、枚举与集合类型
字段的值只能在给定范围中选择,如单选框,多选框
enum 单选 只能在给定的范围内选一个值,如性别 sex 男male/女female
set 多选 在给定的范围内可以选择一个或一个以上的值(爱好1,爱好2,爱好3...)
- create table emp(
- name varchar(15),
- sex enum('male','female','unkown'),
- hobbies set('read','music','yinshi','play')
- );
test
不足的地方后面会续继续更新!
数据库入门-基本sql语句及数据类型的更多相关文章
- 通过MyEclipse工具直接操作数据库,执行sql语句,方便快捷
原文:通过MyEclipse工具直接操作数据库,执行sql语句,方便快捷 通过MyEclipse操作数据库,执行sql语句使我们不用切换多个工具,直接工作,方便快捷.效果如下: 步骤1:通过MyEcl ...
- 【转载】 Sqlserver查看数据库死锁的SQL语句
在Sqlsever数据库中,有时候操作数据库过程中会进行锁表操作,在锁表操作的过程中,有时候会出现死锁的情况出现,这时候可以使用SQL语句来查询数据库死锁情况,主要通过系统数据库Master数据库来查 ...
- oracle数据库查询日期sql语句(范例)、向已经建好的表格中添加一列属性并向该列添加数值、删除某一列的数据(一整列)
先列上我的数据库表格: c_date(Date格式) date_type(String格式) 2011-01-01 0 2012-03-07 ...
- 在一个千万级的数据库查寻中,如何提高查询效率?分别说出在数据库设计、SQL语句、java等层面的解决方案。
在一个千万级的数据库查寻中,如何提高查询效率?分别说出在数据库设计.SQL语句.java等层面的解决方案. 解答: 1)数据库设计方面: a. 对查询进行优化,应尽量避免全表扫描,首先应考虑在 whe ...
- Oracle数据库常用的Sql语句整理
Oracle数据库常用的Sql语句整理 查看当前用户的缺省表空间 : select username,default_tablespace from user_users; 2.查看用户下所有的表 : ...
- Oracle中查询和定位数据库问题的SQL语句
--1)查询和定位数据库问题的SQL语句--Oracle常用性能监控SQL语句.sql --1查询锁表信息 select vp.SPID, vs.P1, vs.P1RAW, vs.P2, vs.EVE ...
- sql server 2008 数据库管理系统使用SQL语句创建登录用户步骤详解
介绍了sql server 2008 数据库管理系统使用SQL语句创建登录用户步骤详解 --服务器角色: --固定服务器角色具有一组固定的权限,并且适用于整个服务器范围. 它们专门用于管理 SQL S ...
- 通过MyEclipse操作数据库,执行sql语句使我们不用切换多个工具,直接工作,方便快捷
通过MyEclipse操作数据库,执行sql语句使我们不用切换多个工具,直接工作,方便快捷.效果如下: 步骤1:通过MyEclipse中的window->show View->ot ...
- 数据库学习之二--SQL语句以及数据类型
一.SQL语句种类: 1. DDL(Data Definition Language,数据定义语言)用来创建或者删除存储数据用的数据库以及数据库中的表;包含以下几种指令: a. CREATE:CREA ...
随机推荐
- ButterKnife官方使用例子
Introduction Annotate fields with @BindView and a view ID for Butter Knife to find and automatically ...
- 简单配置,让ES6脚本在浏览器里飞
如果你只是想学习ES6语法,找个地方练习下写法.不想看环境如何搭配,就想简单的学习,那有两种简单的方式. 1.在Chrome浏览器里直接F12调出控制台 2.在浏览器里跑引用ES6的HTML页面 ...
- 三十、Linux 进程与信号——信号的概念及 signal 函数
30.1 信号的基本概念 信号(signal)机制是Linux 系统中最为古老的进程之间的通信机制,解决进程在正常运行过程中被中断的问题,导致进程的处理流程会发生变化 信号是软件中断 信号是异步事件 ...
- 三、文件IO——系统调用(续)
3.2.4 read 函数--- 读文件 read(由已打开的文件读取数据) #include<unistd.h> ssize_t read(int fd, void * buf, siz ...
- Gossip
http://www.cnblogs.com/xingzc/p/6165084.html 敬请期待...
- Docker 空间大小设置 - 十
一.容器启动 默认存储大小: 1.一种在启动项 docker.service 中配置. 2.在启动项配置调用的 docker-storage 配置文件中配置: 二.Docker 容器默认启动文件: / ...
- Coursera, Deep Learning 5, Sequence Models, week1 Recurrent Neural Networks
有哪些sequence model Notation: RNN - Recurrent Neural Network 传统NN 在解决sequence input 时有什么问题? RNN就没有上面的问 ...
- luogu P3242 [HNOI2015]接水果
传送门 其实这题难点在于处理路径包含关系 先求出树的dfn序,现在假设路径\(xy\)包含\(uv(dfn_x<dfn_y,dfn_u<dfn_v)\) 如果\(lca(u,v)!=u\) ...
- AbstractQueuedSynchronizer源码解析
1.简介 AbstractQueuedSynchronizer队列同步器,用来实现锁或者其他同步组件的基础框架 AbstractQueuedSynchronizer使用int类型的volatile变量 ...
- jquery正则表达式
参考链接: http://www.bkjia.com/Javascript/1084651.html