Kafka的生产者和消费者代码解析
:Kafka名词解释和工作方式
1.1:Producer :消息生产者,就是向kafka broker发消息的客户端。
1.2:Consumer :消息消费者,向kafka broker取消息的客户端
1.3:Topic :可以理解为一个队列。
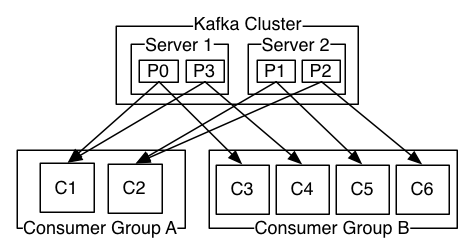
1.4:Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
1.5:Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
1.6:Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
1.7:Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka。 2:Consumer与topic关系?本质上kafka只支持Topic。
2.1:每个group中可以有多个consumer,每个consumer属于一个consumer group;
通常情况下,一个group中会包含多个consumer,这样不仅可以提高topic中消息的并发消费能力,而且还能提高"故障容错"性,如果group中的某个consumer失效那么其消费的partitions将会有其他consumer自动接管。
2.2:对于Topic中的一条特定的消息,只会被订阅此Topic的每个group中的其中一个consumer消费,此消息不会发送给一个group的多个consumer;
那么一个group中所有的consumer将会交错的消费整个Topic,每个group中consumer消息消费互相独立,我们可以认为一个group是一个"订阅"者。
2.3:在kafka中,一个partition中的消息只会被group中的一个consumer消费(同一时刻);
一个Topic中的每个partions,只会被一个"订阅者"中的一个consumer消费,不过一个consumer可以同时消费多个partitions中的消息。
2.4:kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息。
2.5:kafka只能保证一个partition中的消息被某个consumer消费时是顺序的;事实上,从Topic角度来说,当有多个partitions时,消息仍不是全局有序的。 3:Kafka消息的分发,Producer客户端负责消息的分发。
3.1:kafka集群中的任何一个broker都可以向producer提供metadata信息,这些metadata中包含"集群中存活的servers列表"/"partitions leader列表"等信息;
3.2:当producer获取到metadata信息之后, producer将会和Topic下所有partition leader保持socket连接;
3.3:消息由producer直接通过socket发送到broker,中间不会经过任何"路由层",事实上,消息被路由到哪个partition上由producer客户端决定;
比如可以采用"random""key-hash""轮询"等,如果一个topic中有多个partitions,那么在producer端实现"消息均衡分发"是必要的。
3.4:在producer端的配置文件中,开发者可以指定partition路由的方式。
3.5:Producer消息发送的应答机制:
设置发送数据是否需要服务端的反馈,三个值0,1,-1。
0: producer不会等待broker发送ack。
1: 当leader接收到消息之后发送ack。
-1: 当所有的follower都同步消息成功后发送ack。
request.required.acks=0。 4:Consumer的负载均衡:
当一个group中,有consumer加入或者离开时,会触发partitions均衡.均衡的最终目的,是提升topic的并发消费能力:
步骤如下:
a、假如topic1,具有如下partitions: P0,P1,P2,P3。
b、加入group中,有如下consumer: C1,C2。
c、首先根据partition索引号对partitions排序: P0,P1,P2,P3。
d、根据consumer.id排序: C0,C1。
e、计算倍数: M = [P0,P1,P2,P3].size / [C0,C1].size,本例值M=2(向上取整)。
f、然后依次分配partitions: C0 = [P0,P1],C1=[P2,P3],即Ci = [P(i * M),P((i + 1) * M -1)]。
6:Kafka文件存储基本结构:
6.1:在Kafka文件存储中,同一个topic下有多个不同partition,每个partition为一个目录,partiton命名规则为topic名称+有序序号,第一个partiton序号从0开始,序号最大值为partitions数量减1。
6.2:每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中。但每个段segment file消息数量不一定相等,这种特性方便old segment file快速被删除。默认保留7天的数据。
6.3:每个partiton只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定。(什么时候创建,什么时候删除)。
1:使用Idea进行开发,源码如下所示,首先加入Kafka必须依赖的包,这句话意味着你必须要先在Idea上面搭建好的你的maven环境:
pom.xml如下所示内容:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.</modelVersion> <groupId>com.bie</groupId>
<artifactId>storm</artifactId>
<version>1.0-SNAPSHOT</version> <!-- storm的依赖关系 -->
<dependencies>
<!--storm依赖的包-->
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>0.9.</version>
<!--<scope>provided</scope>-->
</dependency>
<!-- kafka依赖的包-->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.8.2</artifactId>
<version>0.8.</version>
<exclusions>
<exclusion>
<artifactId>jmxtools</artifactId>
<groupId>com.sun.jdmk</groupId>
</exclusion>
<exclusion>
<artifactId>jmxri</artifactId>
<groupId>com.sun.jmx</groupId>
</exclusion>
<exclusion>
<artifactId>jms</artifactId>
<groupId>javax.jms</groupId>
</exclusion>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies> <!--如果依赖外部包,就打不进去外部包,所以需要引入下面所示-->
<build>
<plugins>
<plugin>
<!--把其他外部依赖的jar包打成一个大jar包-->
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.bie.wordcount.WordCountTopologyMain</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build> </project>
然后呢,书写你的生产者源码,如下所示:
package com.bie.kafka; import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig; import java.util.Properties;
import java.util.UUID; /**
* 这是一个简单的Kafka producer代码
* 包含两个功能:
* 1、数据发送
* 2、数据按照自定义的partition策略进行发送
*
*
* KafkaSpout的类
*/
public class KafkaProducerSimple { public static void main(String[] args) {
/**
* 1、指定当前kafka producer生产的数据的目的地
* 创建topic可以输入以下命令,在kafka集群的任一节点进行创建。
* bin/kafka-topics.sh --create --zookeeper master:2181
* --replication-factor 1 --partitions 1 --topic orderMq
*/
String TOPIC = "orderMq8";
/**
* 2、读取配置文件
*/
Properties props = new Properties();
/*
* key.serializer.class默认为serializer.class
*/
props.put("serializer.class", "kafka.serializer.StringEncoder");
/*
* kafka broker对应的主机,格式为host1:port1,host2:port2
*/
props.put("metadata.broker.list", "master:9092,slaver1:9092,slaver2:9092");
/*
* request.required.acks,设置发送数据是否需要服务端的反馈,有三个值0,1,-1
* 0,意味着producer永远不会等待一个来自broker的ack,这就是0.7版本的行为。
* 这个选项提供了最低的延迟,但是持久化的保证是最弱的,当server挂掉的时候会丢失一些数据。
* 1,意味着在leader replica已经接收到数据后,producer会得到一个ack。
* 这个选项提供了更好的持久性,因为在server确认请求成功处理后,client才会返回。
* 如果刚写到leader上,还没来得及复制leader就挂了,那么消息才可能会丢失。
* -1,意味着在所有的ISR都接收到数据后,producer才得到一个ack。
* 这个选项提供了最好的持久性,只要还有一个replica存活,那么数据就不会丢失
*/
props.put("request.required.acks", "");
/*
* 可选配置,如果不配置,则使用默认的partitioner partitioner.class
* 默认值:kafka.producer.DefaultPartitioner
* 用来把消息分到各个partition中,默认行为是对key进行hash。
*/
props.put("partitioner.class", "com.bie.kafka.MyLogPartitioner");
//props.put("partitioner.class", "kafka.producer.DefaultPartitioner");
/**
* 3、通过配置文件,创建生产者
*/
Producer<String, String> producer = new Producer<String, String>(new ProducerConfig(props));
/**
* 4、通过for循环生产数据
*/
for (int messageNo = ; messageNo < ; messageNo++) {
String messageStr = new String(messageNo + "注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey," +
"注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发" +
"注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发" +
"注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发" +
"注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发" +
"注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发" +
"注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发" +
"注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发" +
"用来配合自定义的MyLogPartitioner进行数据分发"); /**
* 5、调用producer的send方法发送数据
* 注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发
*/
producer.send(new KeyedMessage<String, String>(TOPIC, messageNo + "", "appid" + UUID.randomUUID() + messageStr)); //producer.send(new KeyedMessage<String, String>(TOPIC, messageNo + "", "appid" + UUID.randomUUID() + "biexiansheng"));
}
}
}
生产者需要的Partitioner如下所示内容:
package com.bie.kafka; import kafka.producer.Partitioner;
import kafka.utils.VerifiableProperties;
import org.apache.log4j.Logger; public class MyLogPartitioner implements Partitioner {
private static Logger logger = Logger.getLogger(MyLogPartitioner.class); public MyLogPartitioner(VerifiableProperties props) {
} public int partition(Object obj, int numPartitions) {
return Integer.parseInt(obj.toString())%numPartitions;
// return 1;
} }
生产者运行效果如下所示:
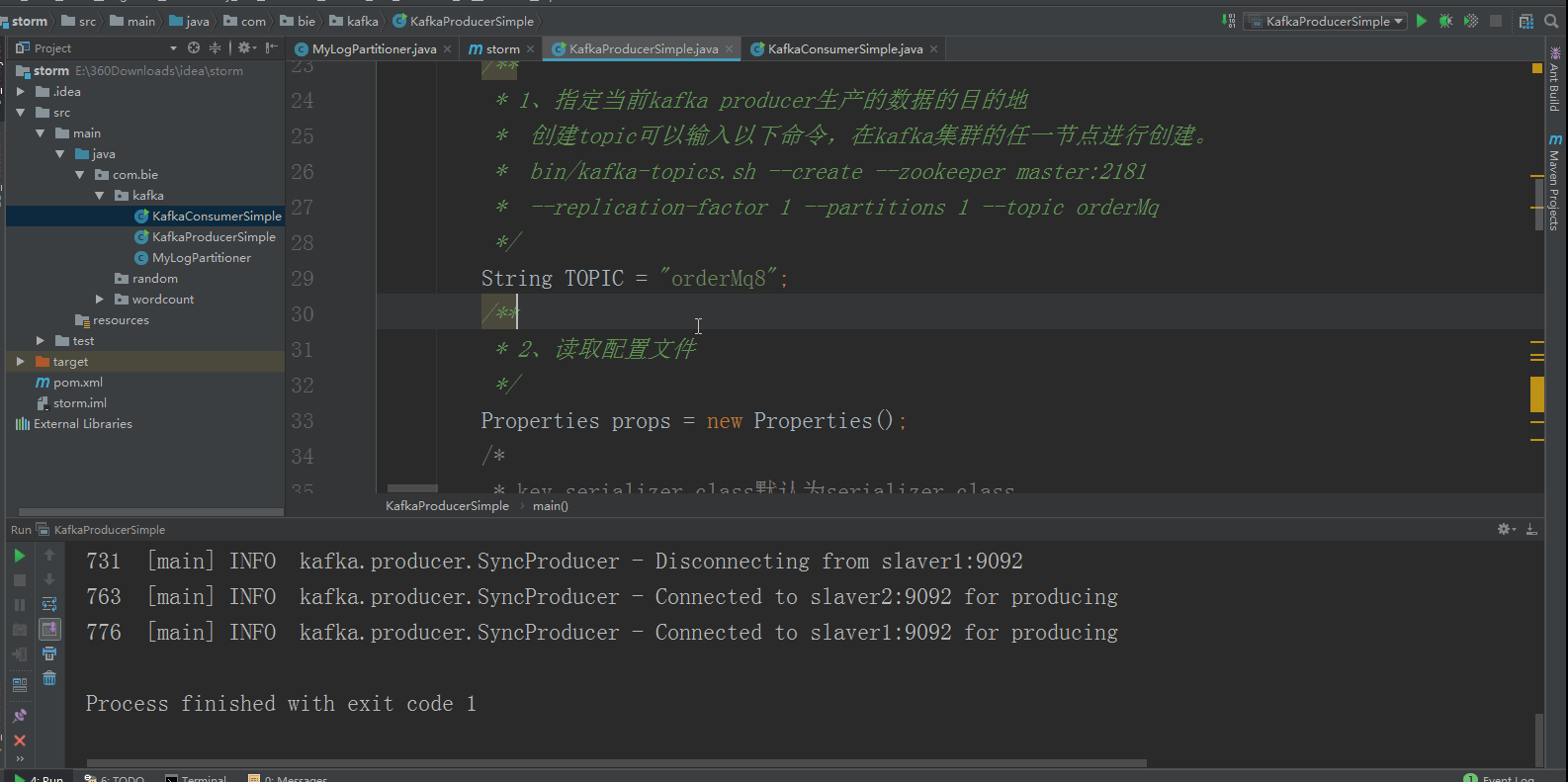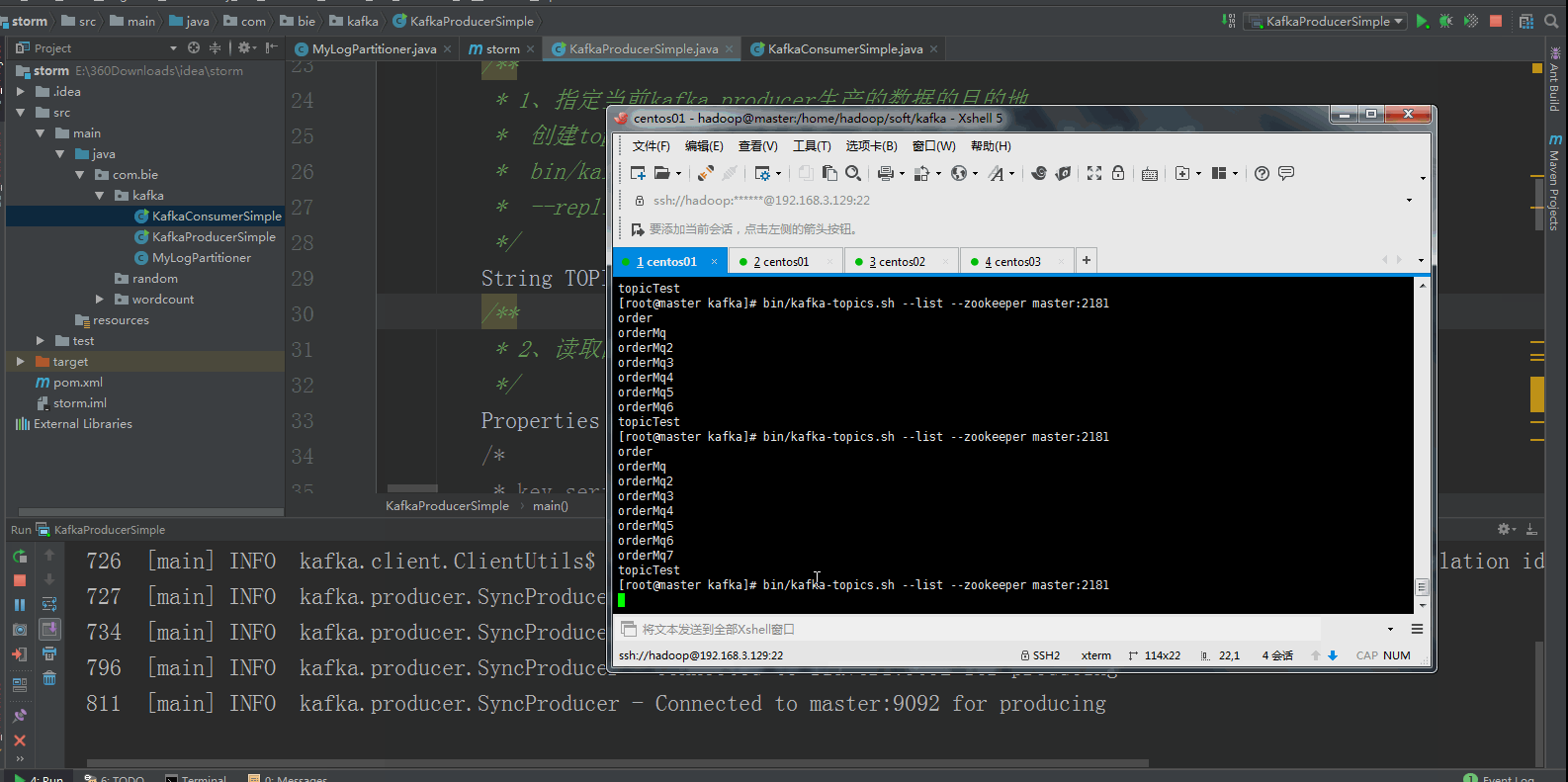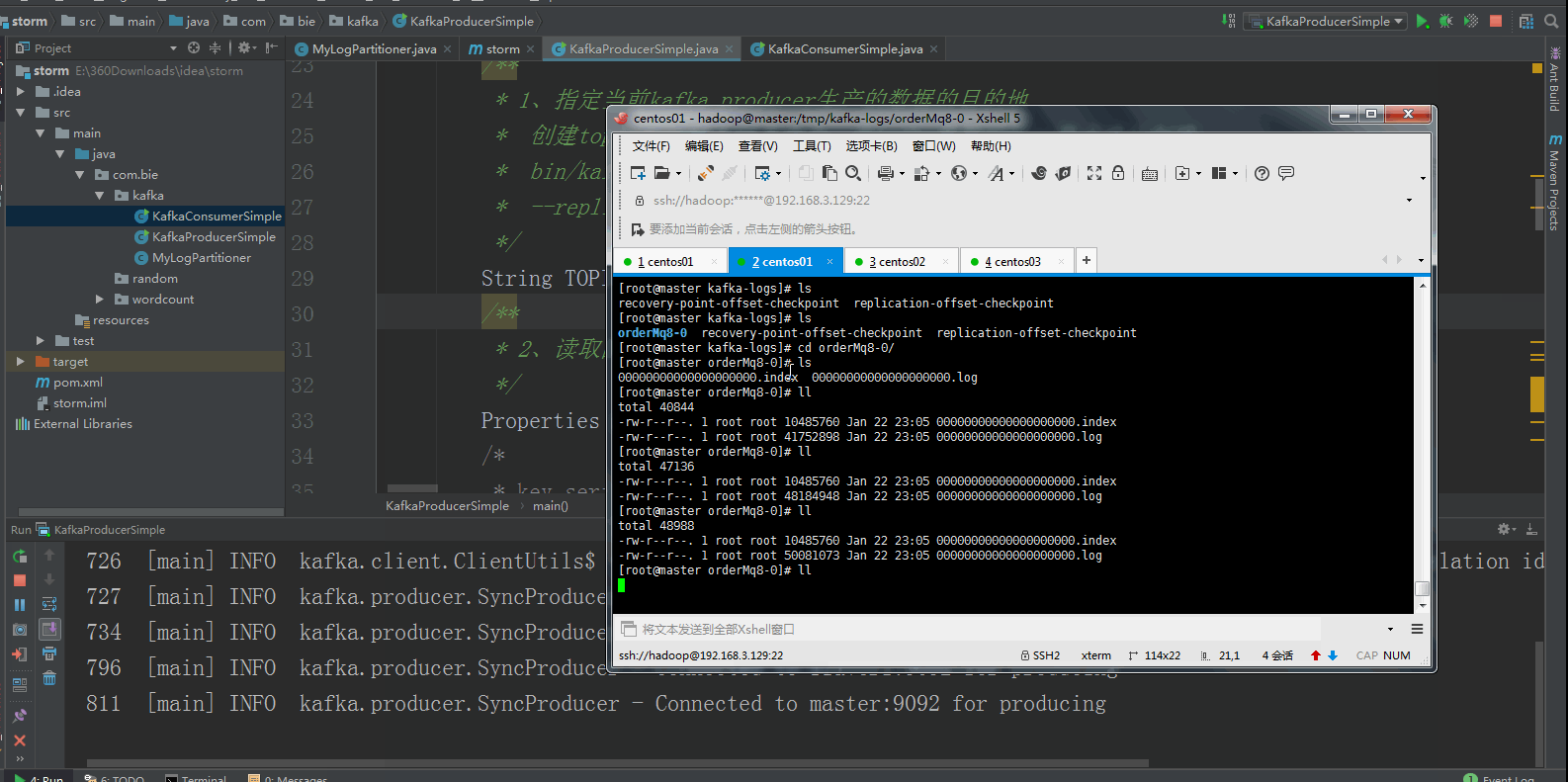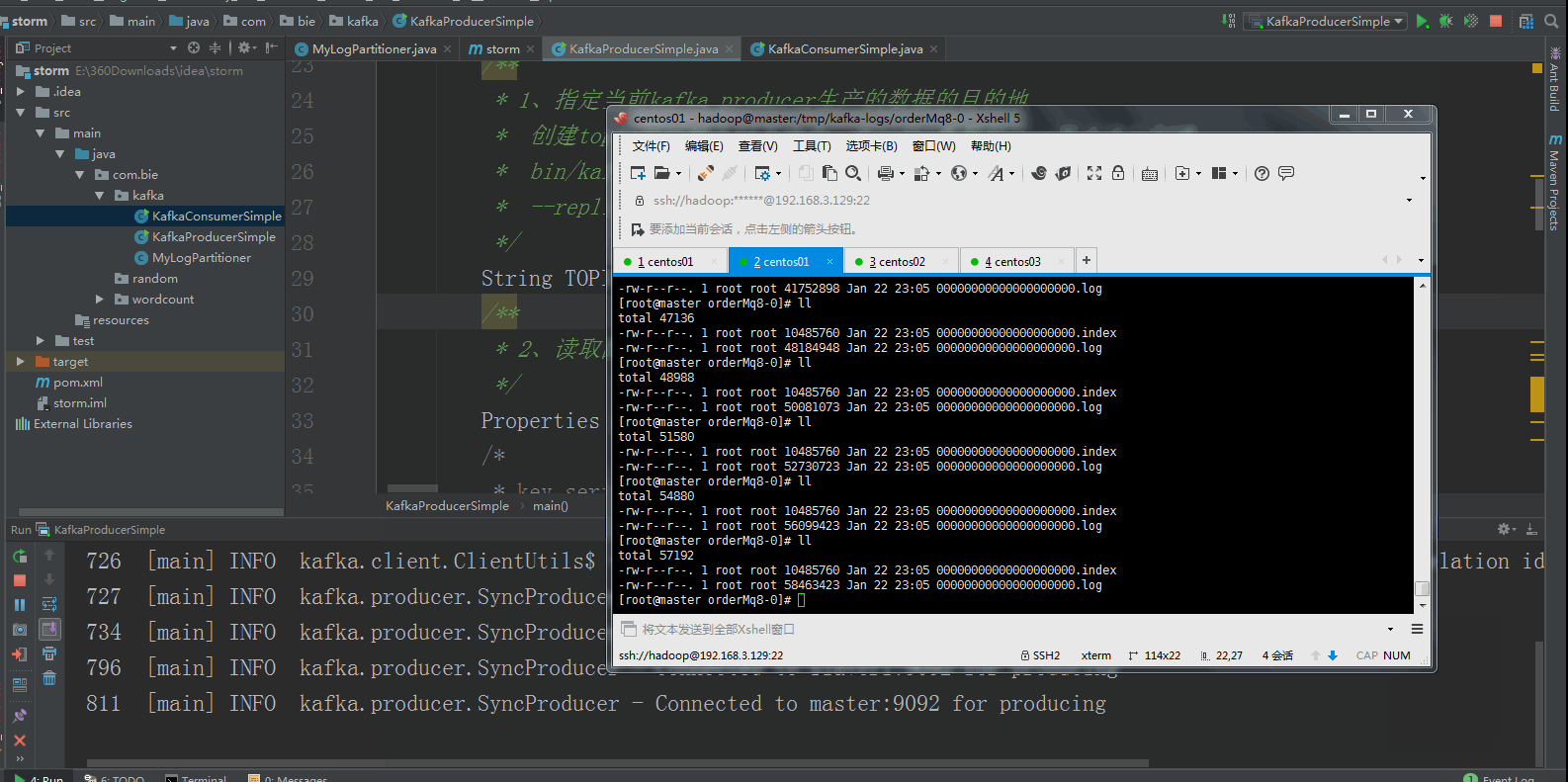
消费者代码如下所示:
package com.bie.kafka; import kafka.consumer.Consumer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.message.MessageAndMetadata; import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors; public class KafkaConsumerSimple implements Runnable {
public String title;
public KafkaStream<byte[], byte[]> stream;
public KafkaConsumerSimple(String title, KafkaStream<byte[], byte[]> stream) {
this.title = title;
this.stream = stream;
}
@Override
public void run() {
System.out.println("开始运行 " + title);
ConsumerIterator<byte[], byte[]> it = stream.iterator();
/**
* 不停地从stream读取新到来的消息,在等待新的消息时,hasNext()会阻塞
* 如果调用 `ConsumerConnector#shutdown`,那么`hasNext`会返回false
* */
while (it.hasNext()) {
MessageAndMetadata<byte[], byte[]> data = it.next();
Object topic = data.topic();
int partition = data.partition();
long offset = data.offset();
String msg = new String(data.message());
System.out.println(String.format(
"Consumer: [%s], Topic: [%s], PartitionId: [%d], Offset: [%d], msg: [%s]",
title, topic, partition, offset, msg));
}
System.out.println(String.format("Consumer: [%s] exiting ...", title));
} public static void main(String[] args) throws Exception{
Properties props = new Properties();
props.put("group.id", "biexiansheng");
props.put("zookeeper.connect", "master:2181,slaver1:2181,slaver2:2181");
props.put("auto.offset.reset", "largest");
props.put("auto.commit.interval.ms", "");
props.put("partition.assignment.strategy", "roundrobin");
ConsumerConfig config = new ConsumerConfig(props);
String topic1 = "orderMq8";
//String topic2 = "paymentMq";
//只要ConsumerConnector还在的话,consumer会一直等待新消息,不会自己退出
ConsumerConnector consumerConn = Consumer.createJavaConsumerConnector(config);
//定义一个map
Map<String, Integer> topicCountMap = new HashMap<>();
topicCountMap.put(topic1, );
//Map<String, List<KafkaStream<byte[], byte[]>> 中String是topic, List<KafkaStream<byte[], byte[]>是对应的流
Map<String, List<KafkaStream<byte[], byte[]>>> topicStreamsMap = consumerConn.createMessageStreams(topicCountMap);
//取出 `kafkaTest` 对应的 streams
List<KafkaStream<byte[], byte[]>> streams = topicStreamsMap.get(topic1);
//创建一个容量为4的线程池
ExecutorService executor = Executors.newFixedThreadPool();
//创建20个consumer threads
for (int i = ; i < streams.size(); i++) {
executor.execute(new KafkaConsumerSimple("消费者" + (i + ), streams.get(i)));
}
}
}
消费者运行如下所示:
运行消费者出现下面的错误,解决方法将pomx.ml里面的zookeeper配置注释了即可:
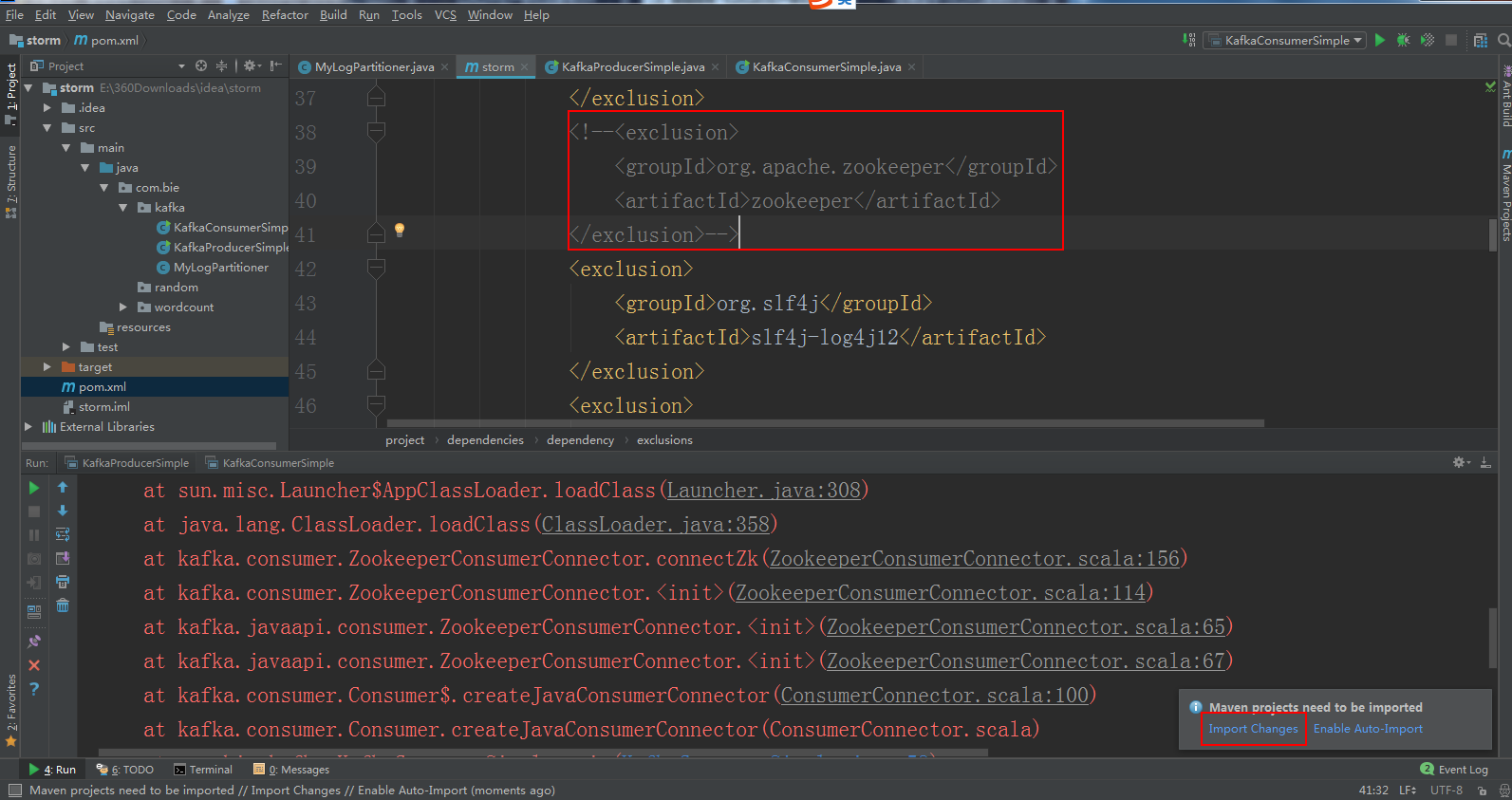
错误如下所示:
D:\soft\Java\jdk1..0_80\bin\java -javaagent:E:\360Downloads\idea\lib\idea_rt.jar=:E:\360Downloads\idea\bin -Dfile.encoding=UTF- -classpath D:\soft\Java\jdk1..0_80\jre\lib\charsets.jar;D:\soft\Java\jdk1..0_80\jre\lib\deploy.jar;D:\soft\Java\jdk1..0_80\jre\lib\ext\access-bridge-.jar;D:\soft\Java\jdk1..0_80\jre\lib\ext\dnsns.jar;D:\soft\Java\jdk1..0_80\jre\lib\ext\jaccess.jar;D:\soft\Java\jdk1..0_80\jre\lib\ext\localedata.jar;D:\soft\Java\jdk1..0_80\jre\lib\ext\sunec.jar;D:\soft\Java\jdk1..0_80\jre\lib\ext\sunjce_provider.jar;D:\soft\Java\jdk1..0_80\jre\lib\ext\sunmscapi.jar;D:\soft\Java\jdk1..0_80\jre\lib\ext\zipfs.jar;D:\soft\Java\jdk1..0_80\jre\lib\javaws.jar;D:\soft\Java\jdk1..0_80\jre\lib\jce.jar;D:\soft\Java\jdk1..0_80\jre\lib\jfr.jar;D:\soft\Java\jdk1..0_80\jre\lib\jfxrt.jar;D:\soft\Java\jdk1..0_80\jre\lib\jsse.jar;D:\soft\Java\jdk1..0_80\jre\lib\management-agent.jar;D:\soft\Java\jdk1..0_80\jre\lib\plugin.jar;D:\soft\Java\jdk1..0_80\jre\lib\resources.jar;D:\soft\Java\jdk1..0_80\jre\lib\rt.jar;E:\360Downloads\idea\storm\target\classes;E:\maven\repository\org\apache\storm\storm-core\0.9.\storm-core-0.9..jar;E:\maven\repository\org\clojure\clojure\1.5.\clojure-1.5..jar;E:\maven\repository\clj-time\clj-time\0.4.\clj-time-0.4..jar;E:\maven\repository\joda-time\joda-time\2.0\joda-time-2.0.jar;E:\maven\repository\compojure\compojure\1.1.\compojure-1.1..jar;E:\maven\repository\org\clojure\core.incubator\0.1.\core.incubator-0.1..jar;E:\maven\repository\org\clojure\tools.macro\0.1.\tools.macro-0.1..jar;E:\maven\repository\clout\clout\1.0.\clout-1.0..jar;E:\maven\repository\ring\ring-core\1.1.\ring-core-1.1..jar;E:\maven\repository\commons-fileupload\commons-fileupload\1.2.\commons-fileupload-1.2..jar;E:\maven\repository\javax\servlet\servlet-api\2.5\servlet-api-2.5.jar;E:\maven\repository\hiccup\hiccup\0.3.\hiccup-0.3..jar;E:\maven\repository\ring\ring-devel\0.3.\ring-devel-0.3..jar;E:\maven\repository\clj-stacktrace\clj-stacktrace\0.2.\clj-stacktrace-0.2..jar;E:\maven\repository\ring\ring-jetty-adapter\0.3.\ring-jetty-adapter-0.3..jar;E:\maven\repository\ring\ring-servlet\0.3.\ring-servlet-0.3..jar;E:\maven\repository\org\mortbay\jetty\jetty\6.1.\jetty-6.1..jar;E:\maven\repository\org\mortbay\jetty\jetty-util\6.1.\jetty-util-6.1..jar;E:\maven\repository\org\clojure\tools.logging\0.2.\tools.logging-0.2..jar;E:\maven\repository\org\clojure\math.numeric-tower\0.0.\math.numeric-tower-0.0..jar;E:\maven\repository\org\clojure\tools.cli\0.2.\tools.cli-0.2..jar;E:\maven\repository\commons-io\commons-io\2.4\commons-io-2.4.jar;E:\maven\repository\org\apache\commons\commons-exec\1.1\commons-exec-1.1.jar;E:\maven\repository\commons-lang\commons-lang\2.5\commons-lang-2.5.jar;E:\maven\repository\com\googlecode\json-simple\json-simple\1.1\json-simple-1.1.jar;E:\maven\repository\com\twitter\carbonite\1.4.\carbonite-1.4..jar;E:\maven\repository\com\esotericsoftware\kryo\kryo\2.21\kryo-2.21.jar;E:\maven\repository\com\esotericsoftware\reflectasm\reflectasm\1.07\reflectasm-1.07-shaded.jar;E:\maven\repository\org\ow2\asm\asm\4.0\asm-4.0.jar;E:\maven\repository\com\esotericsoftware\minlog\minlog\1.2\minlog-1.2.jar;E:\maven\repository\org\objenesis\objenesis\1.2\objenesis-1.2.jar;E:\maven\repository\com\twitter\chill-java\0.3.\chill-java-0.3..jar;E:\maven\repository\org\yaml\snakeyaml\1.11\snakeyaml-1.11.jar;E:\maven\repository\commons-logging\commons-logging\1.1.\commons-logging-1.1..jar;E:\maven\repository\commons-codec\commons-codec\1.6\commons-codec-1.6.jar;E:\maven\repository\com\googlecode\disruptor\disruptor\2.10.\disruptor-2.10..jar;E:\maven\repository\org\jgrapht\jgrapht-core\0.9.\jgrapht-core-0.9..jar;E:\maven\repository\ch\qos\logback\logback-classic\1.0.\logback-classic-1.0..jar;E:\maven\repository\ch\qos\logback\logback-core\1.0.\logback-core-1.0..jar;E:\maven\repository\org\slf4j\slf4j-api\1.7.\slf4j-api-1.7..jar;E:\maven\repository\org\slf4j\log4j-over-slf4j\1.6.\log4j-over-slf4j-1.6..jar;E:\maven\repository\jline\jline\2.11\jline-2.11.jar;E:\maven\repository\org\apache\kafka\kafka_2.8.2\0.8.\kafka_2.8.2-0.8..jar;E:\maven\repository\org\scala-lang\scala-library\2.8.\scala-library-2.8..jar;E:\maven\repository\com\yammer\metrics\metrics-annotation\2.2.\metrics-annotation-2.2..jar;E:\maven\repository\com\yammer\metrics\metrics-core\2.2.\metrics-core-2.2..jar;E:\maven\repository\org\xerial\snappy\snappy-java\1.0.\snappy-java-1.0..jar;E:\maven\repository\net\sf\jopt-simple\jopt-simple\3.2\jopt-simple-3.2.jar;E:\maven\repository\com\101tec\zkclient\0.3\zkclient-0.3.jar;E:\maven\repository\log4j\log4j\1.2.\log4j-1.2..jar com.bie.kafka.KafkaConsumerSimple
[main] INFO kafka.utils.VerifiableProperties - Verifying properties
[main] INFO kafka.utils.VerifiableProperties - Property auto.commit.interval.ms is overridden to
[main] INFO kafka.utils.VerifiableProperties - Property auto.offset.reset is overridden to largest
[main] INFO kafka.utils.VerifiableProperties - Property group.id is overridden to biexiansheng
[main] WARN kafka.utils.VerifiableProperties - Property partition.assignment.strategy is not valid
[main] INFO kafka.utils.VerifiableProperties - Property zookeeper.connect is overridden to master:,slaver1:,slaver2:
[main] INFO kafka.consumer.ZookeeperConsumerConnector - [biexiansheng_HY---bffb9bfb], Connecting to zookeeper instance at master:,slaver1:,slaver2:
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/zookeeper/Watcher
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:)
at java.net.URLClassLoader.access$(URLClassLoader.java:)
at java.net.URLClassLoader$.run(URLClassLoader.java:)
at java.net.URLClassLoader$.run(URLClassLoader.java:)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:)
at java.lang.ClassLoader.loadClass(ClassLoader.java:)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:)
at java.lang.ClassLoader.loadClass(ClassLoader.java:)
at kafka.consumer.ZookeeperConsumerConnector.connectZk(ZookeeperConsumerConnector.scala:)
at kafka.consumer.ZookeeperConsumerConnector.<init>(ZookeeperConsumerConnector.scala:)
at kafka.javaapi.consumer.ZookeeperConsumerConnector.<init>(ZookeeperConsumerConnector.scala:)
at kafka.javaapi.consumer.ZookeeperConsumerConnector.<init>(ZookeeperConsumerConnector.scala:)
at kafka.consumer.Consumer$.createJavaConsumerConnector(ConsumerConnector.scala:)
at kafka.consumer.Consumer.createJavaConsumerConnector(ConsumerConnector.scala)
at com.bie.kafka.KafkaConsumerSimple.main(KafkaConsumerSimple.java:)
Caused by: java.lang.ClassNotFoundException: org.apache.zookeeper.Watcher
at java.net.URLClassLoader$.run(URLClassLoader.java:)
at java.net.URLClassLoader$.run(URLClassLoader.java:)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:)
at java.lang.ClassLoader.loadClass(ClassLoader.java:)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:)
at java.lang.ClassLoader.loadClass(ClassLoader.java:)
... more Process finished with exit code
运行效果如下所示:
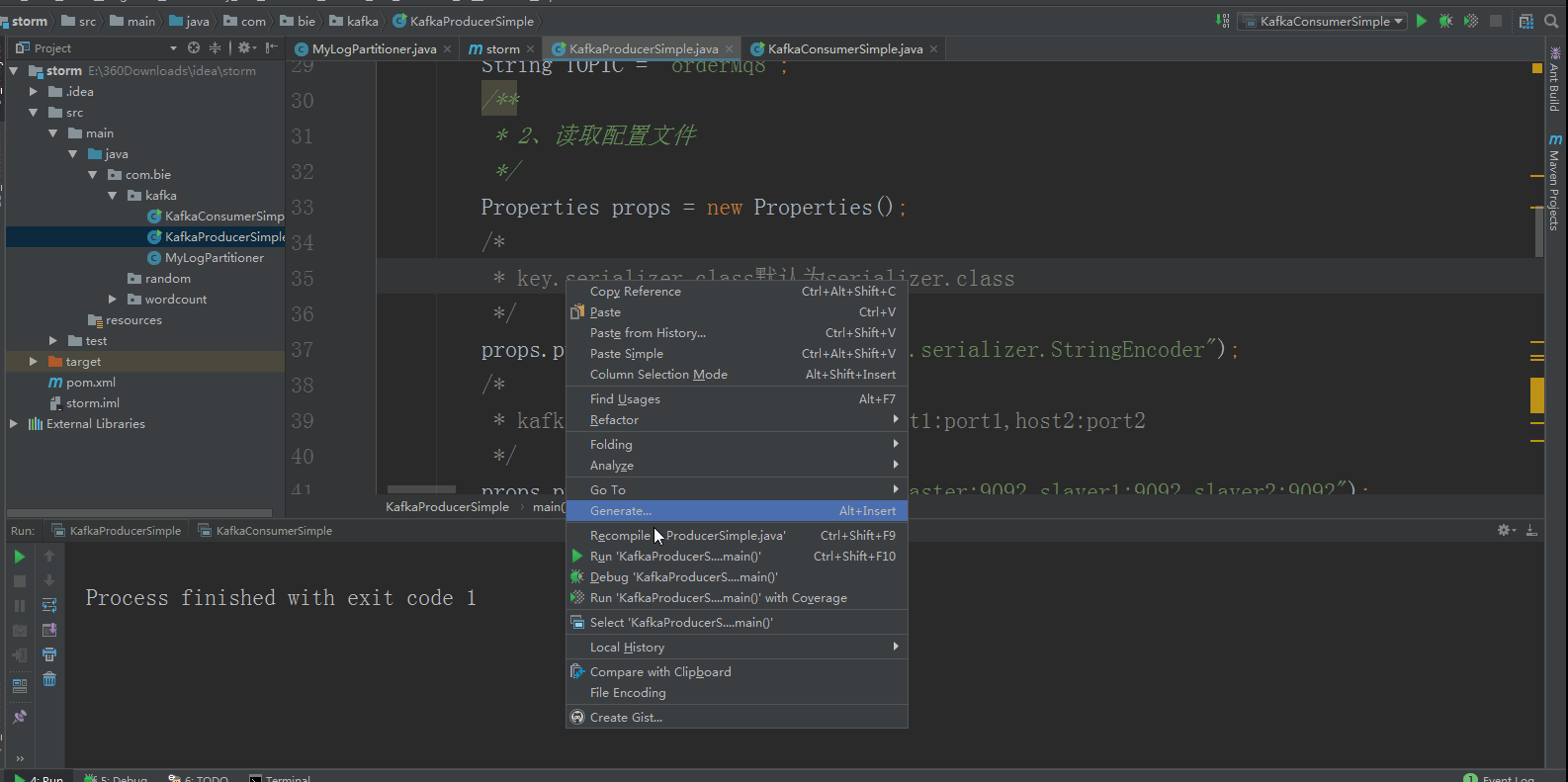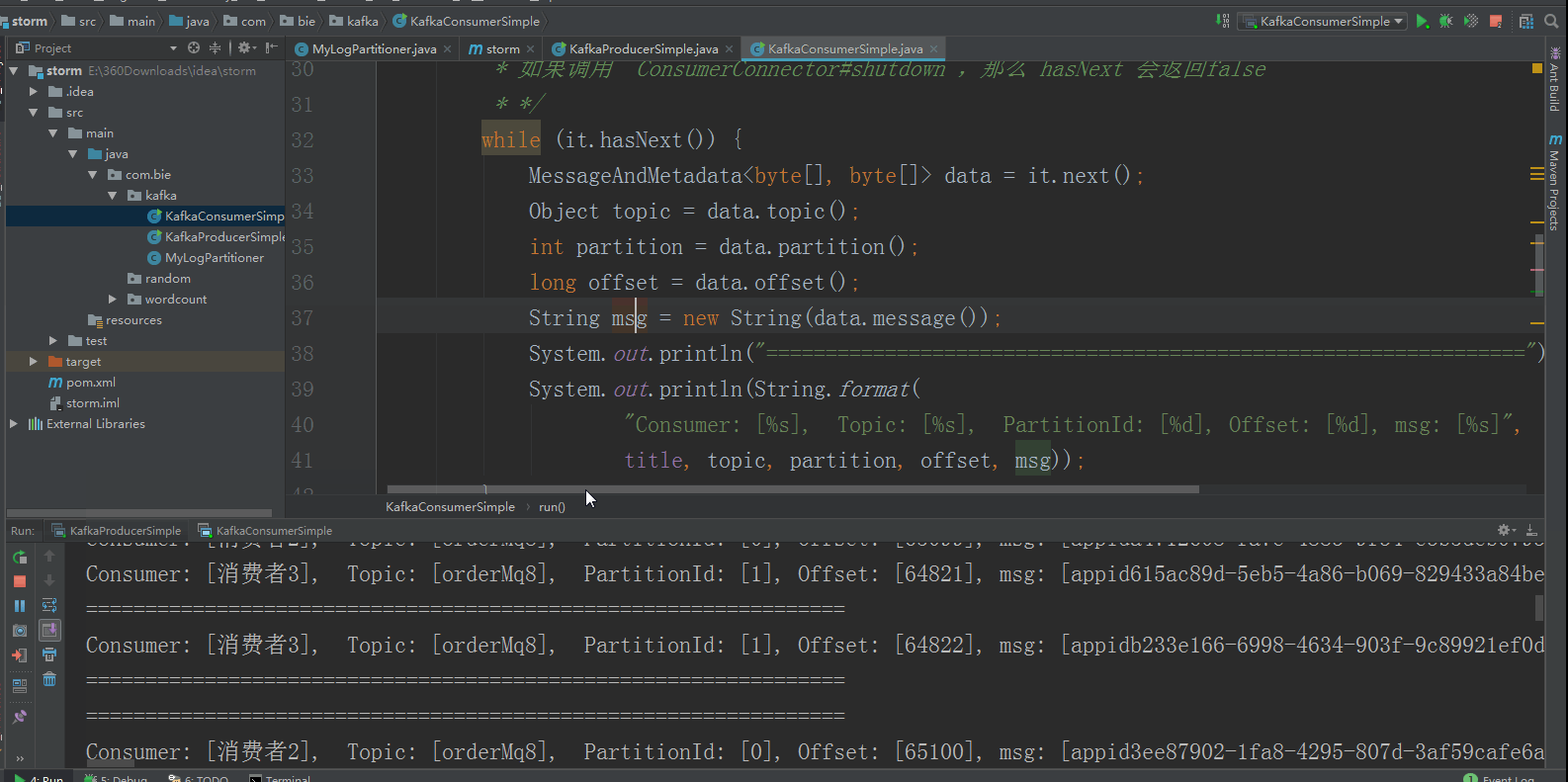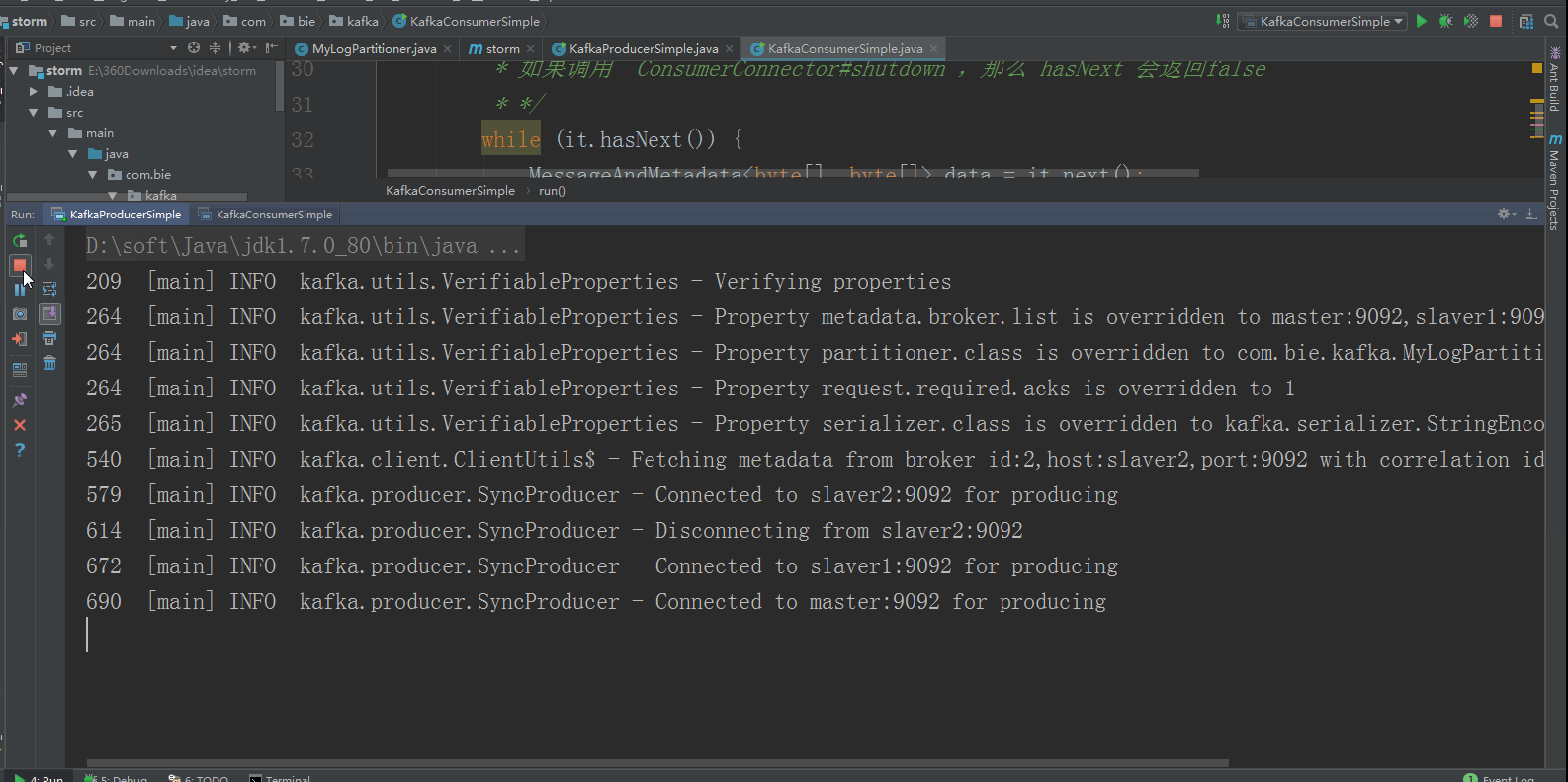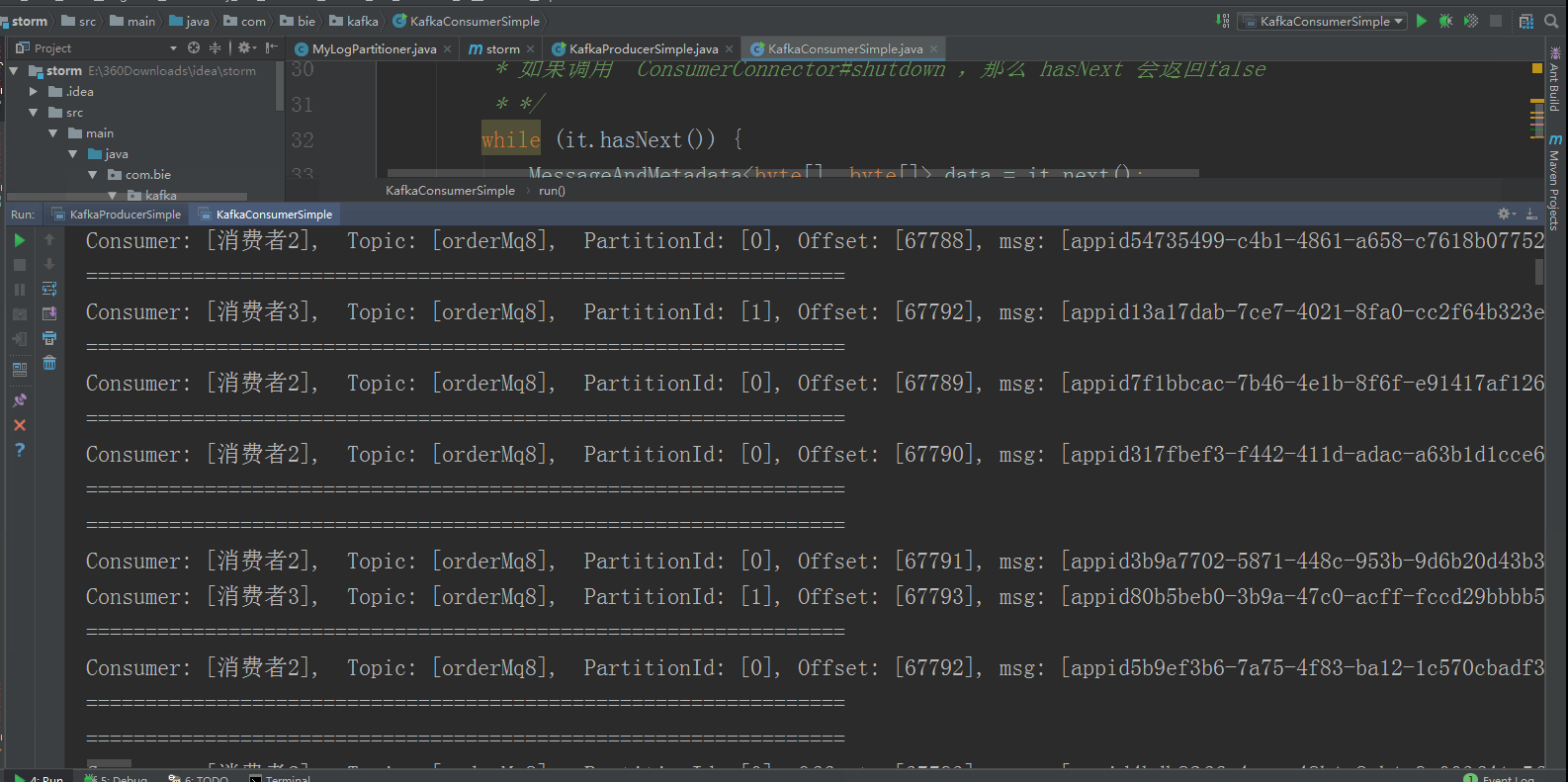
待续......
Kafka的生产者和消费者代码解析的更多相关文章
- 基于kafka_2.11-2.1.0实现的生产者和消费者代码样例
1.搭建部署好zookeeper集群和kafka集群,这里省略. 启动zk: bin/zkServer.sh start conf/zoo.cfg. 验证zk是否启动成功: bin/zkServer. ...
- Go 关于 kafka 的生产者、消费者实例
zookeeper + kafka 首先要在 apche 官网下载 kafka 的程序包(linux版本),然后放到服务器上解压,得到以下目录 bin 目录下包含了服务的启动脚本 启动 zookeep ...
- kafka中生产者和消费者API
使用idea实现相关API操作,先要再pom.xml重添加Kafka依赖: <dependency> <groupId>org.apache.kafka</groupId ...
- Scala调用Kafka的生产者和消费者Demo,以及一些配置参数整理
kafka简介 Kafka是apache开源的一款用Scala编写的消息队列中间件,具有高吞吐量,低延时等特性. Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受 ...
- 使用java创建kafka的生产者和消费者
创建一个Kafka的主题,连接到zk集群,副本因子3,分区3,主题名是test111 [root@h5 kafka]# bin/kafka-topics.sh --create --zo ...
- 生产者与消费者 代码实现 java
首先,我利用忙测试写出了第一次版本的代码 package How; //自写代码 缺陷 无法完全实现pv操作线程处于忙测试状态 public class bin_1_1 { public static ...
- [GO]kafka的生产者和消费者
生产者: package main import ( "github.com/Shopify/sarama" "fmt" "time" ) ...
- Java实现Kafka的生产者和消费者例子
Kafka的结构与RabbitMQ类似,消息生产者向Kafka服务器发送消息,Kafka接收消息后,再投递给消费者.生产者的消费会被发送到Topic中,Topic中保存着各类数据,每一条数据都使用键. ...
- RabbitMQ的使用(五)RabbitMQ Java Client简单生产者、消费者代码示例
pom文件: <dependencies> <dependency> <groupId>com.rabbitmq</groupId> <artif ...
随机推荐
- 【转】Python3 configparse模块(配置)
[转]Python3 configparse模块(配置) ConfigParser模块在python中是用来读取配置文件,配置文件的格式跟windows下的ini配置文件相似,可以包含一个或多个节(s ...
- HardNet解读
论文:Working hard to know your neighbor’s margins: Local descriptor learning loss 为什么介绍此文:这篇2018cvpr文 ...
- Golang -- Signal处理
我们在生产环境下运行的系统要求优雅退出,即程序接收退出通知后,会有机会先执行一段清理代码,将收尾工作做完后再真正退出.我们采用系统Signal来 通知系统退出,即kill pragram-pid.我们 ...
- Light OJ 1214
简单大数模拟题: #include<bits/stdc++.h> using namespace std; typedef long long ll; string Num; vector ...
- highcharts之柱状图
<div class="row"> <div class="col-md-12"> <div id="container ...
- 如何将代码通过vs2017加载到GitHub
(1)登陆GitHub并注册账户,在用户中新建repository (2)建立后,会给出新建repository地址,将其复制 (3)用VS新建一个项目,勾选“新建Git存储库”或者打开一个已经创 ...
- centos7搭建smb服务
1 yum install samba samba-client samba-common -y 安装smb服务 2 cp -a /etc/samba/smb.conf /etc/samba/sm ...
- Confluence 6 为登录失败配置使用验证码
如果你具有 Confluence 管理员的权限,你可以限制 Confluence 登录失败的最大尝试次数.在给予最大登录失败尝试(默认为 3 次)次数后,Confluence 将会在用户进行再次尝试的 ...
- Confluence 6 用户宏示例 - NoPrint
这个示例演示了如何创建一个用户宏,这个宏包括了在查看页面中显示的内容,但是不被打印. Macro name noprint Visibility Visible to all users in the ...
- IOS 命令行工具开发
例子 我们需要查看手机APP里面的某个应用的架构 新建一个Single View App 的ios项目 ToolCL 然后在 main函数中加入以下代码 // // main.m // ToolCL ...