聚类K-Means
import numpy as np
x=np.random.randint(0,52,52)
x
k=3
y=np.zeros(20)
y
array([ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.])
def intcent(x,k):
return x[0:k].reshape(k)
kc=intcent(x,k)
kc array([21, 8, 45])
d=abs(2-kc)
np.where(d==np.min(d))[0][0] 1
def nearest(kc,i):
d=(abs(kc-i))
w=np.where(d==np.min(d))
return w[0][0]
def xclassfy(x,y,kc):
for i in range(x.shape[0]):
y[i]=nearst(kc,x[i])
return y
from sklearn.datasets import load_iris
iris=load_iris()
iris
x=iris.data
x
Out[1]:
array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
[5. , 3.6, 1.4, 0.2],
[5.4, 3.9, 1.7, 0.4],
[4.6, 3.4, 1.4, 0.3],
[5. , 3.4, 1.5, 0.2],
[4.4, 2.9, 1.4, 0.2],
[4.9, 3.1, 1.5, 0.1],
[5.4, 3.7, 1.5, 0.2],
[4.8, 3.4, 1.6, 0.2],
[4.8, 3. , 1.4, 0.1],
[4.3, 3. , 1.1, 0.1],
[5.8, 4. , 1.2, 0.2],
[5.7, 4.4, 1.5, 0.4],
[5.4, 3.9, 1.3, 0.4],
[5.1, 3.5, 1.4, 0.3],
[5.7, 3.8, 1.7, 0.3],
[5.1, 3.8, 1.5, 0.3],
[5.4, 3.4, 1.7, 0.2],
[5.1, 3.7, 1.5, 0.4],
[4.6, 3.6, 1. , 0.2],
[5.1, 3.3, 1.7, 0.5],
[4.8, 3.4, 1.9, 0.2],
[5. , 3. , 1.6, 0.2],
[5. , 3.4, 1.6, 0.4],
[5.2, 3.5, 1.5, 0.2],
[5.2, 3.4, 1.4, 0.2],
[4.7, 3.2, 1.6, 0.2],
[4.8, 3.1, 1.6, 0.2],
[5.4, 3.4, 1.5, 0.4],
[5.2, 4.1, 1.5, 0.1],
[5.5, 4.2, 1.4, 0.2],
[4.9, 3.1, 1.5, 0.1],
[5. , 3.2, 1.2, 0.2],
[5.5, 3.5, 1.3, 0.2],
[4.9, 3.1, 1.5, 0.1],
[4.4, 3. , 1.3, 0.2],
[5.1, 3.4, 1.5, 0.2],
[5. , 3.5, 1.3, 0.3],
[4.5, 2.3, 1.3, 0.3],
[4.4, 3.2, 1.3, 0.2],
[5. , 3.5, 1.6, 0.6],
[5.1, 3.8, 1.9, 0.4],
[4.8, 3. , 1.4, 0.3],
[5.1, 3.8, 1.6, 0.2],
[4.6, 3.2, 1.4, 0.2],
[5.3, 3.7, 1.5, 0.2],
[5. , 3.3, 1.4, 0.2],
[7. , 3.2, 4.7, 1.4],
[6.4, 3.2, 4.5, 1.5],
[6.9, 3.1, 4.9, 1.5],
[5.5, 2.3, 4. , 1.3],
[6.5, 2.8, 4.6, 1.5],
[5.7, 2.8, 4.5, 1.3],
[6.3, 3.3, 4.7, 1.6],
[4.9, 2.4, 3.3, 1. ],
[6.6, 2.9, 4.6, 1.3],
[5.2, 2.7, 3.9, 1.4],
[5. , 2. , 3.5, 1. ],
[5.9, 3. , 4.2, 1.5],
[6. , 2.2, 4. , 1. ],
[6.1, 2.9, 4.7, 1.4],
[5.6, 2.9, 3.6, 1.3],
[6.7, 3.1, 4.4, 1.4],
[5.6, 3. , 4.5, 1.5],
[5.8, 2.7, 4.1, 1. ],
[6.2, 2.2, 4.5, 1.5],
[5.6, 2.5, 3.9, 1.1],
[5.9, 3.2, 4.8, 1.8],
[6.1, 2.8, 4. , 1.3],
[6.3, 2.5, 4.9, 1.5],
[6.1, 2.8, 4.7, 1.2],
[6.4, 2.9, 4.3, 1.3],
[6.6, 3. , 4.4, 1.4],
[6.8, 2.8, 4.8, 1.4],
[6.7, 3. , 5. , 1.7],
[6. , 2.9, 4.5, 1.5],
[5.7, 2.6, 3.5, 1. ],
[5.5, 2.4, 3.8, 1.1],
[5.5, 2.4, 3.7, 1. ],
[5.8, 2.7, 3.9, 1.2],
[6. , 2.7, 5.1, 1.6],
[5.4, 3. , 4.5, 1.5],
[6. , 3.4, 4.5, 1.6],
[6.7, 3.1, 4.7, 1.5],
[6.3, 2.3, 4.4, 1.3],
[5.6, 3. , 4.1, 1.3],
[5.5, 2.5, 4. , 1.3],
[5.5, 2.6, 4.4, 1.2],
[6.1, 3. , 4.6, 1.4],
[5.8, 2.6, 4. , 1.2],
[5. , 2.3, 3.3, 1. ],
[5.6, 2.7, 4.2, 1.3],
[5.7, 3. , 4.2, 1.2],
[5.7, 2.9, 4.2, 1.3],
[6.2, 2.9, 4.3, 1.3],
[5.1, 2.5, 3. , 1.1],
[5.7, 2.8, 4.1, 1.3],
[6.3, 3.3, 6. , 2.5],
[5.8, 2.7, 5.1, 1.9],
[7.1, 3. , 5.9, 2.1],
[6.3, 2.9, 5.6, 1.8],
[6.5, 3. , 5.8, 2.2],
[7.6, 3. , 6.6, 2.1],
[4.9, 2.5, 4.5, 1.7],
[7.3, 2.9, 6.3, 1.8],
[6.7, 2.5, 5.8, 1.8],
[7.2, 3.6, 6.1, 2.5],
[6.5, 3.2, 5.1, 2. ],
[6.4, 2.7, 5.3, 1.9],
[6.8, 3. , 5.5, 2.1],
[5.7, 2.5, 5. , 2. ],
[5.8, 2.8, 5.1, 2.4],
[6.4, 3.2, 5.3, 2.3],
[6.5, 3. , 5.5, 1.8],
[7.7, 3.8, 6.7, 2.2],
[7.7, 2.6, 6.9, 2.3],
[6. , 2.2, 5. , 1.5],
[6.9, 3.2, 5.7, 2.3],
[5.6, 2.8, 4.9, 2. ],
[7.7, 2.8, 6.7, 2. ],
[6.3, 2.7, 4.9, 1.8],
[6.7, 3.3, 5.7, 2.1],
[7.2, 3.2, 6. , 1.8],
[6.2, 2.8, 4.8, 1.8],
[6.1, 3. , 4.9, 1.8],
[6.4, 2.8, 5.6, 2.1],
[7.2, 3. , 5.8, 1.6],
[7.4, 2.8, 6.1, 1.9],
[7.9, 3.8, 6.4, 2. ],
[6.4, 2.8, 5.6, 2.2],
[6.3, 2.8, 5.1, 1.5],
[6.1, 2.6, 5.6, 1.4],
[7.7, 3. , 6.1, 2.3],
[6.3, 3.4, 5.6, 2.4],
[6.4, 3.1, 5.5, 1.8],
[6. , 3. , 4.8, 1.8],
[6.9, 3.1, 5.4, 2.1],
[6.7, 3.1, 5.6, 2.4],
[6.9, 3.1, 5.1, 2.3],
[5.8, 2.7, 5.1, 1.9],
[6.8, 3.2, 5.9, 2.3],
[6.7, 3.3, 5.7, 2.5],
[6.7, 3. , 5.2, 2.3],
[6.3, 2.5, 5. , 1.9],
[6.5, 3. , 5.2, 2. ],
[6.2, 3.4, 5.4, 2.3],
[5.9, 3. , 5.1, 1.8]])
x1=x[:,0]
x1 array([5.1, 4.9, 4.7, 4.6, 5. , 5.4, 4.6, 5. , 4.4, 4.9, 5.4, 4.8, 4.8,
4.3, 5.8, 5.7, 5.4, 5.1, 5.7, 5.1, 5.4, 5.1, 4.6, 5.1, 4.8, 5. ,
5. , 5.2, 5.2, 4.7, 4.8, 5.4, 5.2, 5.5, 4.9, 5. , 5.5, 4.9, 4.4,
5.1, 5. , 4.5, 4.4, 5. , 5.1, 4.8, 5.1, 4.6, 5.3, 5. , 7. , 6.4,
6.9, 5.5, 6.5, 5.7, 6.3, 4.9, 6.6, 5.2, 5. , 5.9, 6. , 6.1, 5.6,
6.7, 5.6, 5.8, 6.2, 5.6, 5.9, 6.1, 6.3, 6.1, 6.4, 6.6, 6.8, 6.7,
6. , 5.7, 5.5, 5.5, 5.8, 6. , 5.4, 6. , 6.7, 6.3, 5.6, 5.5, 5.5,
6.1, 5.8, 5. , 5.6, 5.7, 5.7, 6.2, 5.1, 5.7, 6.3, 5.8, 7.1, 6.3,
6.5, 7.6, 4.9, 7.3, 6.7, 7.2, 6.5, 6.4, 6.8, 5.7, 5.8, 6.4, 6.5,
7.7, 7.7, 6. , 6.9, 5.6, 7.7, 6.3, 6.7, 7.2, 6.2, 6.1, 6.4, 7.2,
7.4, 7.9, 6.4, 6.3, 6.1, 7.7, 6.3, 6.4, 6. , 6.9, 6.7, 6.9, 5.8,
6.8, 6.7, 6.7, 6.3, 6.5, 6.2, 5.9])
from sklearn.cluster import KMeans
est=KMeans(n_clusters=3)
est.fit(x)
est.cluster_centers_
y=est.predict(x)
y array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 2, 2, 2, 2, 1, 2, 2, 2,
2, 2, 2, 1, 1, 2, 2, 2, 2, 1, 2, 1, 2, 1, 2, 2, 1, 1, 2, 2, 2, 2,
2, 1, 2, 2, 2, 2, 1, 2, 2, 2, 1, 2, 2, 2, 1, 2, 2, 1])
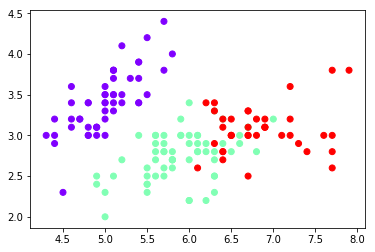
import matplotlib.pyplot as plt
plt.scatter(x[:,0],x[:,1],c=y,cmap='rainbow')
plt.show()
est1=KMeans(n_clusters=4)
x1=x[:,0].reshape(-1,1)
est1.fit(x1)
y=est1.labels_
plt.scatter(x1,x1)
plt.show()
est1=KMeans(n_clusters=4)
x1=x[:,0]
est=KMeans(n_clusters=4)
est.fit(x) KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=4, n_init=10, n_jobs=1, precompute_distances='auto',
random_state=None, tol=0.0001, verbose=0)
est1=KMeans(n_clusters=4)
x1=x[:,0].reshape(-1,1)
x1 array([[5.1],
[4.9],
[4.7],
[4.6],
[5. ],
[5.4],
[4.6],
[5. ],
[4.4],
[4.9],
[5.4],
[4.8],
[4.8],
[4.3],
[5.8],
[5.7],
[5.4],
[5.1],
[5.7],
[5.1],
[5.4],
[5.1],
[4.6],
[5.1],
[4.8],
[5. ],
[5. ],
[5.2],
[5.2],
[4.7],
[4.8],
[5.4],
[5.2],
[5.5],
[4.9],
[5. ],
[5.5],
[4.9],
[4.4],
[5.1],
[5. ],
[4.5],
[4.4],
[5. ],
[5.1],
[4.8],
[5.1],
[4.6],
[5.3],
[5. ],
[7. ],
[6.4],
[6.9],
[5.5],
[6.5],
[5.7],
[6.3],
[4.9],
[6.6],
[5.2],
[5. ],
[5.9],
[6. ],
[6.1],
[5.6],
[6.7],
[5.6],
[5.8],
[6.2],
[5.6],
[5.9],
[6.1],
[6.3],
[6.1],
[6.4],
[6.6],
[6.8],
[6.7],
[6. ],
[5.7],
[5.5],
[5.5],
[5.8],
[6. ],
[5.4],
[6. ],
[6.7],
[6.3],
[5.6],
[5.5],
[5.5],
[6.1],
[5.8],
[5. ],
[5.6],
[5.7],
[5.7],
[6.2],
[5.1],
[5.7],
[6.3],
[5.8],
[7.1],
[6.3],
[6.5],
[7.6],
[4.9],
[7.3],
[6.7],
[7.2],
[6.5],
[6.4],
[6.8],
[5.7],
[5.8],
[6.4],
[6.5],
[7.7],
[7.7],
[6. ],
[6.9],
[5.6],
[7.7],
[6.3],
[6.7],
[7.2],
[6.2],
[6.1],
[6.4],
[7.2],
[7.4],
[7.9],
[6.4],
[6.3],
[6.1],
[7.7],
[6.3],
[6.4],
[6. ],
[6.9],
[6.7],
[6.9],
[5.8],
[6.8],
[6.7],
[6.7],
[6.3],
[6.5],
[6.2],
[5.9]])
est1=KMeans(n_clusters=4)
x1=x[:,0].reshape(-1,1)
est1=KMeans(n_clusters=4)
est1.fit(x1)
est1.labels_ array([1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 2, 3, 3, 0, 3, 0, 3, 1, 3, 1, 1, 0, 0, 0, 0, 3,
0, 0, 3, 0, 0, 0, 3, 0, 3, 3, 3, 3, 0, 0, 0, 0, 0, 0, 0, 0, 3, 3,
0, 0, 0, 0, 0, 1, 0, 0, 0, 3, 1, 0, 3, 0, 2, 3, 3, 2, 1, 2, 3, 2,
3, 3, 3, 0, 0, 3, 3, 2, 2, 0, 3, 0, 2, 3, 3, 2, 3, 0, 3, 2, 2, 2,
3, 3, 0, 2, 3, 3, 0, 3, 3, 3, 0, 3, 3, 3, 3, 3, 3, 0])
1)设定好K的大小,随机选取K个点作为初始中心点;
(2)计算每个点到这K个中心点的距离大小,选取最近的中心点,划分到以该中心点为中心的集群中去;
(3)重新计算K个新集群的中心点;
(4)如果中心点保持不变,则结束K-Means过程。否则,重复进行(2)、(3)步;
复制代码
import numpy as np
x = np.random.randint(1,50,[20,1])
y = np.zeros(20)
k = 3
#1) 选取数据空间中的K个对象作为初始中心,每个对象代表一个聚类中心;
def initcen(x,k):
return x[:k]
#2) 对于样本中的数据对象,根据它们与这些聚类中心的欧氏距离,按距离最近的准则将它们分到距离它们最近的聚类中心(最相似)所对应的类;
def nearest(kc,i):
d = abs(kc-i)
w = np.where(d == np.min(d))
return w[0][0] def xclassify(x,y,kc):
for i in range(x.shape[0]):
y[i] = nearest(kc,x[i])
return y #3) 更新聚类中心:将每个类别中所有对象所对应的均值作为该类别的聚类中心,计算目标函数的值; def kcmean(x,y,kc,k):
l = list(kc)
flag = False
for c in range(k):
m = np.where(y ==0)
n = np.mean(x[m])
if l[c] != n:
l[c] = n
flag = True
print(l,flag)
return (np.array(l),flag)
#4) 判断聚类中心和目标函数的值是否发生改变,若不变,则输出结果,若改变,则返回2)
kc = initcen(x,k) flag = True
print(x,y,kc,flag)
while flag:
y = xclassify(x,y,kc)
kc,flag = kcmean(x,y,kc,k)
print(y,kc)
复制代码
聚类K-Means的更多相关文章
- 软件——机器学习与Python,聚类,K——means
K-means是一种聚类算法: 这里运用k-means进行31个城市的分类 城市的数据保存在city.txt文件中,内容如下: BJ,2959.19,730.79,749.41,513.34,467. ...
- KMeans聚类 K值以及初始类簇中心点的选取 转
本文主要基于Anand Rajaraman和Jeffrey David Ullman合著,王斌翻译的<大数据-互联网大规模数据挖掘与分布式处理>一书. KMeans算法是最常用的聚类算法, ...
- 聚类-K均值
数据来源:http://archive.ics.uci.edu/ml/datasets/seeds 15.26 14.84 0.871 5.763 3.312 2.221 5.22 Kama 14.8 ...
- 【机器学习笔记五】聚类 - k均值聚类
参考资料: [1]Spark Mlib 机器学习实践 [2]机器学习 [3]深入浅出K-means算法 http://www.csdn.net/article/2012-07-03/2807073- ...
- 聚类--K均值算法
import numpy as np from sklearn.datasets import load_iris iris = load_iris() x = iris.data[:,1] y = ...
- 第八次作业:聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
import numpy as np x = np.random.randint(1,100,[20,1]) y = np.zeros(20) k = 3 def initcenter(x,k): r ...
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- 机器学习方法(七):Kmeans聚类K值如何选,以及数据重抽样方法Bootstrapping
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入.我的博客写一些自己用得到东西,并分享给 ...
- kmeans 聚类 k 值优化
kmeans 中k值一直是个令人头疼的问题,这里提出几种优化策略. 手肘法 核心思想 1. 肉眼评价聚类好坏是看每类样本是否紧凑,称之为聚合程度: 2. 类别数越大,样本划分越精细,聚合程度越高,当类 ...
随机推荐
- C++builder Tokyo 调用com 不正确的变量类型
C++builder Tokyo 调用com 不正确的变量类型 tt.OleFunction("interface_call","MS01",&erro ...
- Unexpected error: java.security.InvalidAlgorithmParameterException: the trustAnchors parameter must be non-empty 报错
项目中遇到的获取https的数据接口数据时,Unexpected error: java.security.InvalidAlgorithmParameterException: the trustA ...
- 算法之Python实现 - 003 : 换钱的方法数
[题目]给定数组arr,arr中所有的值都为正数且不重复.每个值代表一种面值的货币,每种面值的货币可以使用任意张,再给定一个整数aim代表要找的钱数,求组成aim的方法数. [代码1]递归 impor ...
- vue组件is属性详解
查看官网对is属性的讲解,请移步:vue.js 本文参考资料 在vue.js组件教程的一开始提及到了is特性 下面是官网对is属性使用的说明: 组件功能是vue项目的一大特色.组件可以扩展html元素 ...
- Python 学习笔记02篇
之前很庆幸早点报名课程 可以早点看到视频讲解,不至于后期太赶 不得不说原本21天压缩到14天再压缩到7天,如果可以完整且独立地完成至少三个作业,那水平应该真的很不错吧
- jQuery 效果 - 动画 animate() 方法
我们先看一个demo <!DOCTYPE html> <html> <head> <script src="/jquery/jquery-1.11. ...
- python中logging模块
1. 日志的等级 DEBUG.INFO.NOTICE.WARNING.ERROR.CRITICAL.ALERT.EMERGENCY 级别 何时使用 DEBUG 详细信息,典型地调试问题时会感兴趣. 详 ...
- Game Engine Architecture 2
[Game Engine Architecture 2] 1.endian swap 函数 floating-point endian-swapping:将浮点指针reinterpert_cast 成 ...
- mysql批量update更新,mybatis中批量更新操作
在日常开发中,有时候会遇到批量更新操作,这时候最普通的写法就是循环遍历,然后一条一条地进行update操作.但是不管是在服务端进行遍历,还是在sql代码中进行遍历,都很耗费资源,而且性能比较差,容易造 ...
- 【Spring源码解析】—— 依赖注入结合SpringMVC Demo-xml配置理解
在IOC容器初始化的梳理之后,对依赖注入做一个总结,就是bean实例化的过程,bean的定义有两种方式,一种是xml文件配置,一种是注解,这里是对xml配置文件的依赖注入的介绍,后续对bean与该部分 ...