初步了解pandas(学习笔记)
1 pandas简介
pandas 是一种列存数据分析 API。它是用于处理和分析输入数据的强大工具,很多机器学习框架都支持将 pandas 数据结构作为输入。 虽然全方位介绍 pandas API 会占据很长篇幅,但它的核心概念非常简单,我们会在下文中进行说明。有关更完整的参考,请访问 pandas 文档网站,其中包含丰富的文档和教程资源。
Pandas 是用于进行数据分析和建模的重要库,广泛应用于 TensorFlow 编码。该教程提供了学习本课程所需的全部 Pandas 信息。
2 学习目标
1)大致了解 pandas 库的 DataFrame 和 Series 数据结构
2)存取和处理 DataFrame 和 Series 中的数据
3)将 CSV 数据导入 pandas 库的 DataFrame
4)对 DataFrame 重建索引来随机打乱数据
3 基本概念
以下行导入了 pandas API 并输出了相应的 API 版本:
from __future__ import print_function import pandas as pd pd.__version__
在jupyter中运行结果 '0.23.4'
pandas 中的主要数据结构被实现为以下两类:
- DataFrame,您可以将它想象成一个关系型数据表格,其中包含多个行和已命名的列。
- Series,它是单一列。DataFrame 中包含一个或多个 Series,每个 Series 均有一个名称。
数据框架是用于数据操控的一种常用抽象实现形式。Spark 和 R 中也有类似的实现。
创建 Series 的一种方法是构建 Series 对象。例如:
pd.Series(['San Francisco', 'San Jose', 'Sacramento'])
运行结果
0 San Francisco 1 San Jose 2 Sacramento dtype: object
pd.Series函数可以将其中的参数(string)作为dict的列名称传递到各自的Series中,从而创建DataFrame对象;如果series的长度不一致,系统会用特殊的NA/NaN值填充至缺失值处。
city_names = pd.Series(['San Francisco', 'San Jose', 'Sacramento'])
population = pd.Series([852469, 1015785, 485199])
pd.DataFrame({ 'City name': city_names, 'Population': population })
运行结果
| City name | Population | |
|---|---|---|
| 0 | San Francisco | 852469 |
| 1 | San Jose | 1015785 |
| 2 | Sacramento | 485199 |
当长度不一致时,则有下列结果
city_names = pd.Series(['San Francisco', 'San Jose', 'Sacramento','hao'])
population = pd.Series([852469, 1015785, 485199])
pd.DataFrame({ 'City name': city_names, 'Population': population })
运行结果
|
City name |
Population |
|
|
0 |
San Francisco |
852469.0 |
|
1 |
San Jose |
1015785.0 |
|
2 |
Sacramento |
485199.0 |
|
3 |
hao |
NaN |
其实在多数时候,我们需要将整个文件加载到DataFrame中。下面示例为加载了一个包含加利福尼亚州住房数据的文件。请运行以下单元格以加载数据,并创建特征定义:
california_housing_dataframe = pd.read_csv("https://download.mlcc.google.cn/mledu-datasets/california_housing_train.csv", sep=",")
california_housing_dataframe.describe()
运行结果
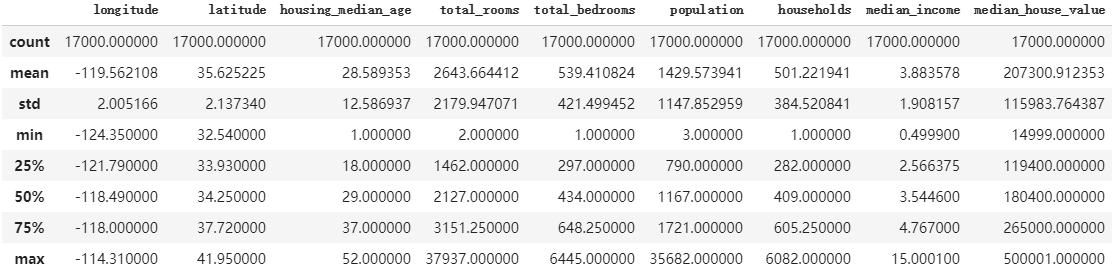
上面的示例使用 DataFrame.describe 来显示关于 DataFrame 的有趣统计信息。另一个实用函数是 DataFrame.head,它显示 DataFrame 的前几个记录:

pandas 的另一个强大功能是绘制图表。例如,借助 DataFrame.hist,您可以快速了解一个列中值的分布:
california_housing_dataframe.hist('housing_median_age')
运行结果
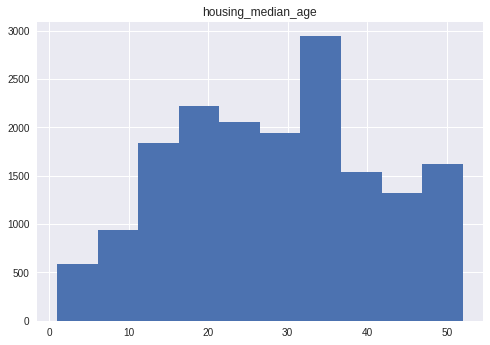
可以采用python的 dict/list 指令访问 DataFrame 数据。
cities = pd.DataFrame({ 'City name': city_names, 'Population': population })
print(type(cities['City name']))
cities['City name']
运行
<class 'pandas.core.series.Series'> 0 San Francisco 1 San Jose 2 Sacramento Name: City name, dtype: object
查看数据元素
print(type(cities['City name'][1])) cities['City name'][1]
运行
<type 'str'> 'San Jose'
进行切片操作
print(type(cities[0:2])) cities[0:2]
运行
<class 'pandas.core.frame.DataFrame'>
|
City name |
Population |
|
|
0 |
San Francisco |
852469 |
|
1 |
San Jose |
1015785 |
此外,pandas 针对高级索引和选择提供了极其丰富的 API(数量过多,此处无法逐一列出)。
4 操控数据
可以向 Series 应用 Python 的基本运算指令。例如:
population / 1000.
运行结果
0 852.469 1 1015.785 2 485.199 dtype: float64
NumPy 是一种用于进行科学计算的常用工具包。pandas Series 可用作大多数 NumPy 函数的参数:
import numpy as np np.log(population)
运行
0 13.655892 1 13.831172 2 13.092314 dtype: float64
对于更复杂的单列转换,您可以使用 Series.apply。
像 Python 映射函数一样,Series.apply 将以参数形式接受 lambda 函数,而该函数会应用于每个值。
下面的示例创建了一个指明 population 是否超过 100 万的新 Series:
population.apply(lambda val: val > 1000000)
运行
0 False 1 True 2 False dtype: bool
DataFrames 的修改方式也非常简单。例如,以下代码可以实现向现有 DataFrame 添加了两个 Series:
cities['Area square miles'] = pd.Series([46.87, 176.53, 97.92]) cities['Population density'] = cities['Population'] / cities['Area square miles'] cities
运行

5 练习
5.1 练习1
通过添加一个新的布尔值列(当且仅当以下两项均为 True 时为 True)修改 cities 表格:
- 城市以圣人命名。
- 城市面积大于 50 平方英里。
注意:布尔值 Series 是使用“按位”而非传统布尔值“运算符”组合的。例如,执行逻辑与时,应使用 &,而不是 and。
提示:"San" 在西班牙语中意为 "saint"。
代码结构
cities['Is wide and has saint name'] = (cities['Area square miles'] > 50) & cities['City name'].apply(lambda name: name.startswith('San'))
cities
运行结果

5.2 索引
Series 和 DataFrame 对象也定义了 index 属性,该属性会向每个 Series 项或 DataFrame 行赋一个标识符值。
默认情况下,在构造时,pandas 会赋可反映源数据顺序的索引值。索引值在创建后是稳定的;也就是说,它们不会因为数据重新排序而发生改变。
city_names.index
运行
RangeIndex(start=0, stop=3, step=1)
求出city的索引值index
cities.index
运行
RangeIndex(start=0, stop=3, step=1)
调用 DataFrame.reindex 以手动重新排列各行的顺序。例如,以下方式与按城市名称排序具有相同的效果:
cities.reindex([2, 0, 1])
运行

重建索引是一种随机排列 DataFrame 的绝佳方式。在下面的示例中,我们会取用类似数组的索引,然后将其传递至 NumPy 的 random.permutation 函数,该函数会随机排列其值的位置。如果使用此重新随机排列的数组调用 reindex,会导致 DataFrame 行以同样的方式随机排列。
尝试多次运行以下单元格!
cities.reindex(np.random.permutation(cities.index))
运行(第一次)

运行(第二次)

5.3 练习2
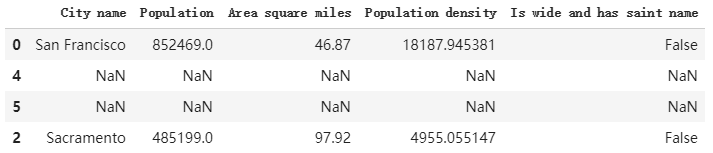
reindex 方法允许使用未在DataFrame索引值中的数字,比如5,6……100,等,如果将这些值假如索引重拍时,所有的内容都会用NaN填充。
cities.reindex([0, 4, 5, 2])
https://colab.research.google.com/notebooks/mlcc/intro_to_pandas.ipynb?utm_source=mlcc&utm_campaign=colab-external&utm_medium=referral&utm_content=pandas-colab&hl=zh-cn#scrollTo=pCvT7R2Lb37Z
https://colab.research.google.com/notebooks/welcome.ipynb 谷歌的练习平台
初步了解pandas(学习笔记)的更多相关文章
- Pandas 学习笔记
Pandas 学习笔记 pandas 由两部份组成,分别是 Series 和 DataFrame. Series 可以理解为"一维数组.列表.字典" DataFrame 可以理解为 ...
- 【转】Pandas学习笔记(七)plot画图
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- 【转】Pandas学习笔记(六)合并 merge
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- 【转】Pandas学习笔记(五)合并 concat
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- 【转】Pandas学习笔记(四)处理丢失值
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- 【转】Pandas学习笔记(三)修改&添加值
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- 【转】Pandas学习笔记(二)选择数据
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- 【转】Pandas学习笔记(一)基本介绍
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- Pandas学习笔记
本学习笔记来自于莫烦Python,原视频链接 一.Pandas基本介绍和使用 Series数据结构:索引在左,值在右 import pandas as pd import numpy as np s ...
- pandas学习笔记(一)
Pandas是一款开放源码的BSD许可的Python库,为Python编程语言提供了高性能,易于使用的数据结构和数据分析工具.Pandas用于广泛的领域,包括金融,经济,统计,分析等学术和商业领域.在 ...
随机推荐
- JavaScript 判断一个对象{}是否为空对象的简单方法
第一种: function isEmptyObject(obj) { for (var key in obj) { //返回false,不为空对象 return false; } return tru ...
- pycharm+python+Django之web开发环境的搭建(windows)
转载:https://blog.csdn.net/yjx2323999451/article/details/53200243/ pycharm+python+Django之web开发环境的搭建(wi ...
- Centos7中修改Hostname的方法
一.Centos7中修改的方法: hostnamectl set-hostname <new hostname> 说明:centOS 7 里面修改hostname的方式有所改变,修改/et ...
- AngularJS实现三级Table列表
angular.module('yo03App') .controller('MyrouteCtrl', function ($scope) { $scope.professors = [{ 'nam ...
- angularjs中的坑
ng-show 等ng的指令中不需要使用{{parameter}}来取值,回无效
- JDK5.0 特性-线程 Condition
来自:http://www.cnblogs.com/taven/archive/2011/12/17/2291471.html import java.util.concurrent.Executor ...
- Array相关的属性和方法
这里只是做了相关的列举,具体的使用方法,请参考网址. Array 对象属性 constructor 返回对创建此对象的数组函数的引用. var test=new Array(); if (test.c ...
- .NET 工具生成引擎概述
Mark Michaelis 微软中国MSDN 过去几年大家一直都在使用 .NET Core(有这么久吗?)并且都知道“生成系统”经历了重大改变,不论是终止对 Gulp 的内置支持,还是放弃 Proj ...
- 分布式锁和Redisson实现
http://thoreauz.com/2017/08/20/language/java/%E5%9F%BA%E7%A1%80/%E5%88%86%E5%B8%83%E5%BC%8F%E9%94%81 ...
- 〖Linux〗Kubuntu, the application 'Google Chrome' has requested to open the wallet 'kdewallet'解决方法
每次打开Google都提示: the application 'Google Chrome' has requested to open the wallet 'kdewallet'... 原来是Go ...