sklearn_Logistic Regression
一、什么是逻辑回归?
一种名为“回归”的线性分类器,其本质是由线性回归变化而来的,一种广泛使用于分类问题中的广义回归算法
- 面试高危问题:Sigmoid函数的公式和性质
Sigmoid函数是一个S型的函数,当自变量z趋近正无穷时,因变量g(z)趋近于1,而当z趋近负无穷时,g(z)趋近 于0,它能够将任何实数映射到(0,1)区间,使其可用于将任意值函数转换为更适合二分类的函数。 因为这个性质,Sigmoid函数也被当作是归一化的一种方法,与我们之前学过的MinMaxSclaer同理,是属于 数据预处理中的“缩放”功能,可以将数据压缩到[0,1]之内。区别在于,MinMaxScaler归一化之后,是可以取 到0和1的(大值归一化后就是1,小值归一化后就是0),但Sigmoid函数只是无限趋近于0和1。
二、为什么需要逻辑回归?
线性回归对数据的要求很严格,比如标签必须满足正态分布,特征之间的多重共线性需要消除等等,而现实中很多真实情景的数据无法满足这些要求,因此线性回归在很多现实情境的应用效果有限。逻辑回归是由线性回归变化而来,因此它对数据也有一些要求,而我们之前已经学过了强大的分类模型决策树和随机森林,它们的分类效力很 强,并且不需要对数据做任何预处理。
逻辑回归的优点:
- 1. 逻辑回归对线性关系的拟合效果好到丧心病狂,特征与标签之间的线性关系极强的数据,比如金融领域中的 信用卡欺诈,评分卡制作,电商中的营销预测等等相关的数据,都是逻辑回归的强项。虽然现在有了梯度提 升树GDBT,比逻辑回归效果更好,也被许多数据咨询公司启用,但逻辑回归在金融领域,尤其是银行业中的 统治地位依然不可动摇(相对的,逻辑回归在非线性数据的效果很多时候比瞎猜还不如,所以如果你已经知 道数据之间的联系是非线性的,千万不要迷信逻辑回归)
- 2. 逻辑回归计算快:对于线性数据,逻辑回归的拟合和计算都非常快,计算效率优于SVM和随机森林,亲测表 示在大型数据上尤其能够看得出区别
- 3. 逻辑回归返回的分类结果不是固定的0,1,而是以小数形式呈现的类概率数字:我们因此可以把逻辑回归返 回的结果当成连续型数据来利用。比如在评分卡制作时,我们不仅需要判断客户是否会违约,还需要给出确 定的”信用分“,而这个信用分的计算就需要使用类概率计算出的对数几率,而决策树和随机森林这样的分类 器,可以产出分类结果,却无法帮助我们计算分数(当然,在sklearn中,决策树也可以产生概率,使用接口 predict_proba调用就好,但一般来说,正常的决策树没有这个功能)
- 4.逻辑回归还有抗噪能力强的优点。福布斯杂志在讨论逻辑回归的优点时,甚至有着“技术上来说,佳模型 的AUC面积低于0.8时,逻辑回归非常明显优于树模型”的说法。并且,逻辑回归在小数据集上表现更好,在大型的 数据集上,树模型有着更好的表现。
由此,我们已经了解了逻辑回归的本质,它是一个返回对数几率的,在线性数据上表现优异的分类器,它主要被应用在金融领域。其数学目的是求解能够让模型最优化的参数 的值,并基于参数 和特征矩阵计算出逻辑回归的结果 y(x)。
注意:虽然我们熟悉的逻辑回归通常被用于处理二分类问题,但逻辑回归也可以做多分类
三、sklearn实现逻辑回归
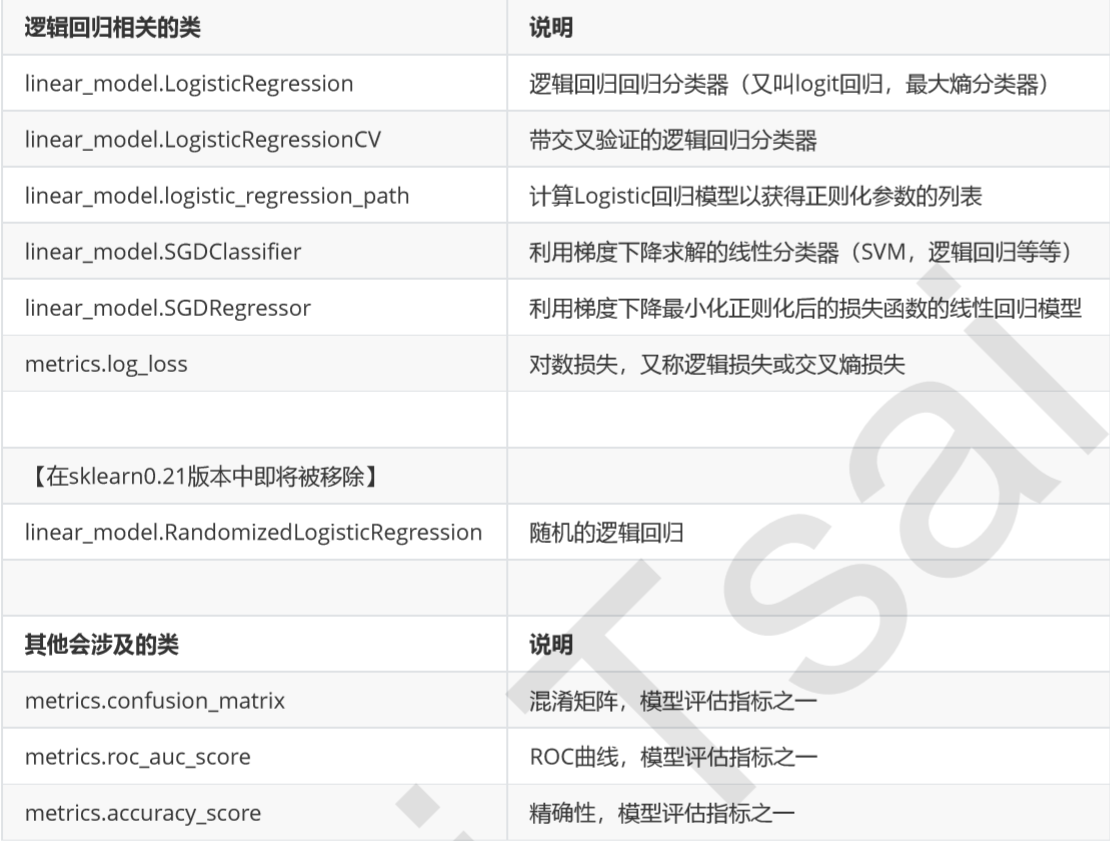
class sklearn.linear_model.LogisticRegression (penalty=’l2’, dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver=’warn’, max_iter=100, multi_class=’warn’, verbose=0, warm_start=False, n_jobs=None)
1.损失函数
我们使用”损失函数“这个评估指标,来衡量参数 的优劣,即这一组参数能否使模型在训练集上表现优异。 如果用一组参数建模后,模型在训练集上表现良好,那我们就说模型表现的规律与训练集数据的规律一致,拟合过 程中的损失很小,损失函数的值很小,这一组参数就优秀;相反,如果模型在训练集上表现糟糕,损失函数就会很 大,模型就训练不足,效果较差,这一组参数也就比较差。即是说,我们在求解参数 时,追求损失函数小,让模型在训练数据上的拟合效果优,即预测准确率尽量靠近100%。

逻辑回归的损失函数是由大似然法来推导出来的,具体结果可以写作
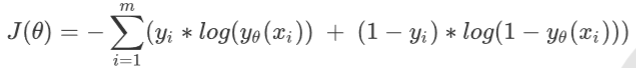

2.正则化 重要参数penalty & C
正则化是用来防止模型过拟合的过程,常用的有L1正则化和L2正则化两种选项,分别通过在损失函数后加上参数向量theta的L1范式和L2范式的倍数来实现。这个增加的范式,被称为“正则项”,也被称为"惩罚项"。损失函数改变,基 于损失函数的优化来求解的参数取值必然改变,我们以此来调节模型拟合的程度。其中L1范数表现为参数向量中 的每个参数的绝对值之和,L2范数表现为参数向量中的每个参数的平方和的开方值。
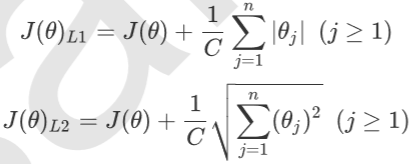
其中J(theta)是我们之前提过的损失函数,C是用来控制正则化程度的超参数,n是方程中特征的总数,也是方程中参 数的总数,j代表每个参数。在这里,J要大于等于1,是因为我们的参数向量theta 中,第一个参数是theta0 ,是我们的截 距,它通常是不参与正则化的。
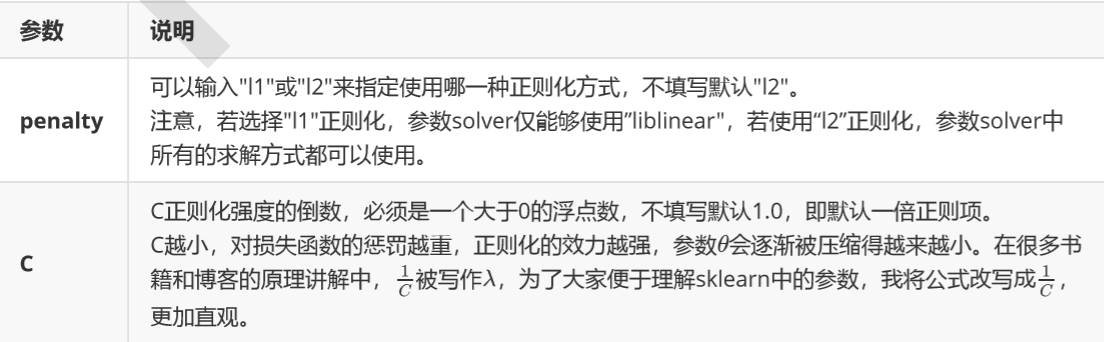
L1正则化和L2正则化虽然都可以控制过拟合,但它们的效果并不相同。当正则化强度逐渐增大(即C逐渐变小), 参数 的取值会逐渐变小,但L1正则化会将参数压缩为0,L2正则化只会让参数尽量小,不会取到0。 在L1正则化在逐渐加强的过程中,携带信息量小的、对模型贡献不大的特征的参数,会比携带大量信息的、对模型 有巨大贡献的特征的参数更快地变成0,所以L1正则化本质是一个特征选择的过程,掌管了参数的“稀疏性”。L1正 则化越强,参数向量中就越多的参数为0,参数就越稀疏,选出来的特征就越少,以此来防止过拟合。因此,如果 特征量很大,数据维度很高,我们会倾向于使用L1正则化。由于L1正则化的这个性质,逻辑回归的特征选择可以由 Embedded嵌入法来完成。
相对的,L2正则化在加强的过程中,会尽量让每个特征对模型都有一些小的贡献,但携带信息少,对模型贡献不大 的特征的参数会非常接近于0。通常来说,如果我们的主要目的只是为了防止过拟合,选择L2正则化就足够了。但 是如果选择L2正则化后还是过拟合,模型在未知数据集上的效果表现很差,就可以考虑L1正则化。 而两种正则化下C的取值,都可以通过学习曲线来进行调整。
建立两个逻辑回归,L1正则化和L2正则化的差别就一目了然了
举例:在乳腺癌数据集上用LR实现二分类,查看L1、L2正则化的效果
from sklearn.linear_model import LogisticRegression as LR |

|
#实例化LR模型 |
|
#逻辑回归的重要属性coef_ theta,查看每个特征所对应的参数 |
|
lrl1.coef_ |
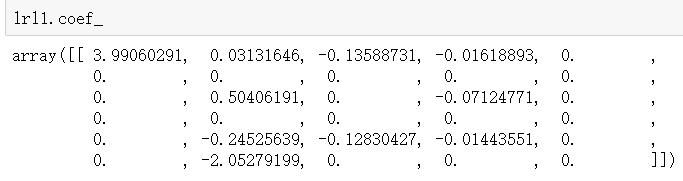
|
(lrl1.coef_!=0).sum(axis=1)#不为0的特征的个数 |

|
lrl2=lrl2.fit(X,y) |
|
lrl2.coef_ |
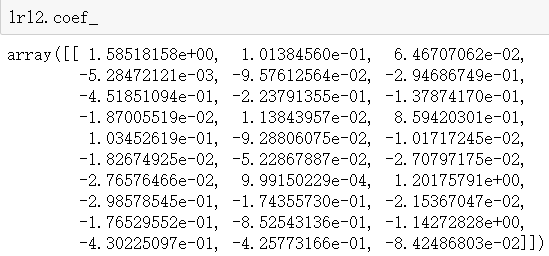
|
l1 = [] |
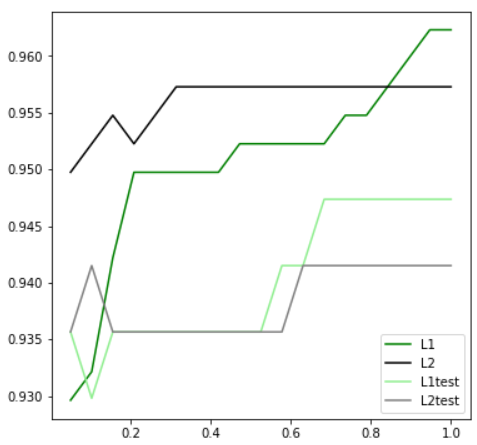
|
可见,至少在我们的乳腺癌数据集下,两种正则化的结果区别不大。但随着C的逐渐变大,正则化的强度越来越小,模型在训练集和测试集上的表现都呈上升趋势,直到C=0.8左右,训练集上的表现依然在走高,但模型在未知 数据集上的表现开始下跌,这时候就是出现了过拟合。我们可以认为,C设定为0.9会比较好。在实际使用时,基本 就默认使用l2正则化,如果感觉到模型的效果不好,那就换L1试试看
sklearn_Logistic Regression的更多相关文章
- 逻辑回归 Logistic Regression
逻辑回归(Logistic Regression)是广义线性回归的一种.逻辑回归是用来做分类任务的常用算法.分类任务的目标是找一个函数,把观测值匹配到相关的类和标签上.比如一个人有没有病,又因为噪声的 ...
- logistic regression与SVM
Logistic模型和SVM都是用于二分类,现在大概说一下两者的区别 ① 寻找最优超平面的方法不同 形象点说,Logistic模型找的那个超平面,是尽量让所有点都远离它,而SVM寻找的那个超平面,是只 ...
- [Machine Learning & Algorithm]CAML机器学习系列1:深入浅出ML之Regression家族
声明:本博客整理自博友@zhouyong计算广告与机器学习-技术共享平台,尊重原创,欢迎感兴趣的博友查看原文. 符号定义 这里定义<深入浅出ML>系列中涉及到的公式符号,如无特殊说明,符号 ...
- 机器学习 1 regression
Linear regerssion 线性回归 回归: stock market forecast f(过去10年股票起伏的资料) = 明天道琼指数点数 self driving car f(获取的道路 ...
- 线性回归 Linear Regression
成本函数(cost function)也叫损失函数(loss function),用来定义模型与观测值的误差.模型预测的价格与训练集数据的差异称为残差(residuals)或训练误差(test err ...
- Logistic Regression - Formula Deduction
Sigmoid Function \[ \sigma(z)=\frac{1}{1+e^{(-z)}} \] feature: axial symmetry: \[ \sigma(z)+ \sigma( ...
- 线性回归、梯度下降(Linear Regression、Gradient Descent)
转载请注明出自BYRans博客:http://www.cnblogs.com/BYRans/ 实例 首先举个例子,假设我们有一个二手房交易记录的数据集,已知房屋面积.卧室数量和房屋的交易价格,如下表: ...
- 局部加权回归、欠拟合、过拟合(Locally Weighted Linear Regression、Underfitting、Overfitting)
欠拟合.过拟合 如下图中三个拟合模型.第一个是一个线性模型,对训练数据拟合不够好,损失函数取值较大.如图中第二个模型,如果我们在线性模型上加一个新特征项,拟合结果就会好一些.图中第三个是一个包含5阶多 ...
- PRML读书笔记——3 Linear Models for Regression
Linear Basis Function Models 线性模型的一个关键属性是它是参数的一个线性函数,形式如下: w是参数,x可以是原始的数据,也可以是关于原始数据的一个函数值,这个函数就叫bas ...
随机推荐
- remote: fatal: could not read Username for 'http://spapa.wicp.net:3000': No such device ors
解决办法: git remote add origin https://{username}:{password}@github.com/{username}/project.git in my ca ...
- 预编译 ASP.NET 网站以进行部署
预编译 ASP.NET 网站以进行部署和更新 打开一个命令窗口并定位到包含 .NET Framework 的文件夹. .NET Framework 将安装在以下位置. %windir%\Microso ...
- python pytest测试框架介绍二
在介绍一中简单介绍了pytest的安装和简单使用,接下来我们就要实际了解pytest了 一.pytest的用例发现规则 pytest可以在不同的函数.包中发现用例,发现的规则如下 文件名以test_开 ...
- 在eclipse中编辑linux上的项目
以前在linux的上接口自动化项目都是使用notepad++或SVN下载到本地后再上传来完成功做,但在调试时非常麻烦. 查看了下在eclipse中有一个非常好用的插件Remote Systems,可以 ...
- IntelliJ IDEA导出Java 可执行Jar包
extends:http://blog.sina.com.cn/s/blog_3fe961ae0102uy42.html 保证自己的Java代码是没有问题的,在IDEA里面是可以正常运行的,然后,按下 ...
- Windows Server 2008 R2之一活动目录服务部署
测试环境: 服务器:计算机名Win2008R2CNDC,已安装Windows Server 2008 R2.IPV4:192.168.1.13,255.255.255.0,网关地址192.168.1. ...
- 如何使QLineEdit禁止编辑
在写程序的时候喜欢使用QLineEdit,用来显示打开文件的路径.但是很不喜欢被编辑.那么要怎么设置不可编辑呢. (1)调用lineEdit->setEnabled(False) #不可编辑了 ...
- OpenCV学习笔记之CXCORE篇
转自blog.csdn.net/bbzz2/article/details/50764209
- python 将字符串转换为字典
在一般的工程处理中,需要将获取的字符串数据转换为字典,这样处理起来会非常方便. 我获取的是json数据: content = {"corpus_no":"64702772 ...
- redis系列之数据库与缓存数据一致性解决方案
redis系列之数据库与缓存数据一致性解决方案 数据库与缓存读写模式策略 写完数据库后是否需要马上更新缓存还是直接删除缓存? (1).如果写数据库的值与更新到缓存值是一样的,不需要经过任何的计算,可以 ...