influx+grafana自定义python采集数据和一些坑的总结
先上网卡数据采集脚本,这个基本上是最大的坑,因为一些数据的类型不正确会导致no datapoint的错误,真是令人抓狂,注意其中几个key的值必须是int或者float类型,如果你不慎写成了string,那就麻烦了,其他的tag是string类型。
另外数据采集时间间隔一般就是10秒,这是潜规则,大家都懂。
官方参考地址:
有图有真相
#! /usr/bin/env python
#-*- coding:utf-8 -*-
import os
import arrow
import time
from time import sleep
from influxdb import InfluxDBClient
client = InfluxDBClient('localhost', 8086, 'root', '', 'telegraf')
while True:
if int(time.time())%10 == 0:
cmd = 'cat /proc/net/dev|grep "ens4"'
rawline = os.popen(cmd).read().strip()
rxbytes = int(rawline.split()[1])
txbytes = int(rawline.split()[9])
rxpks = int(rawline.split()[2])
txpks = int(rawline.split()[10])
now = str(arrow.now()).split('.')[0] + 'Z'
print time.time(), rxbytes,txbytes,rxpks,txpks
json_body = [
{
"measurement": "network",
"tags": {
"host": "gc-u16",
"nio": "ens4"
},
#"time": now,
"fields": {
"rxbytes": rxbytes,
"txbytes": txbytes,
"rxpks": rxpks,
"txpks": txpks
}
}
]
client.write_points(json_body)
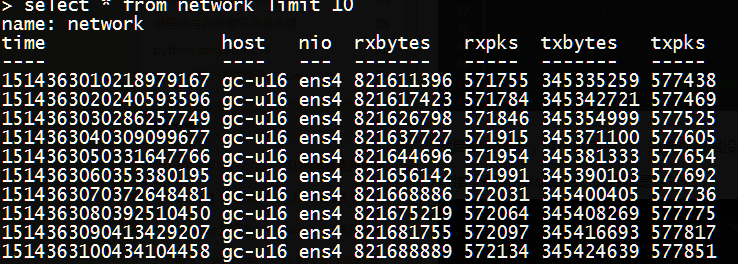
sleep(1)运行脚本,查看influxdb数据,至于后台+独立线程这些东西就见仁见智了
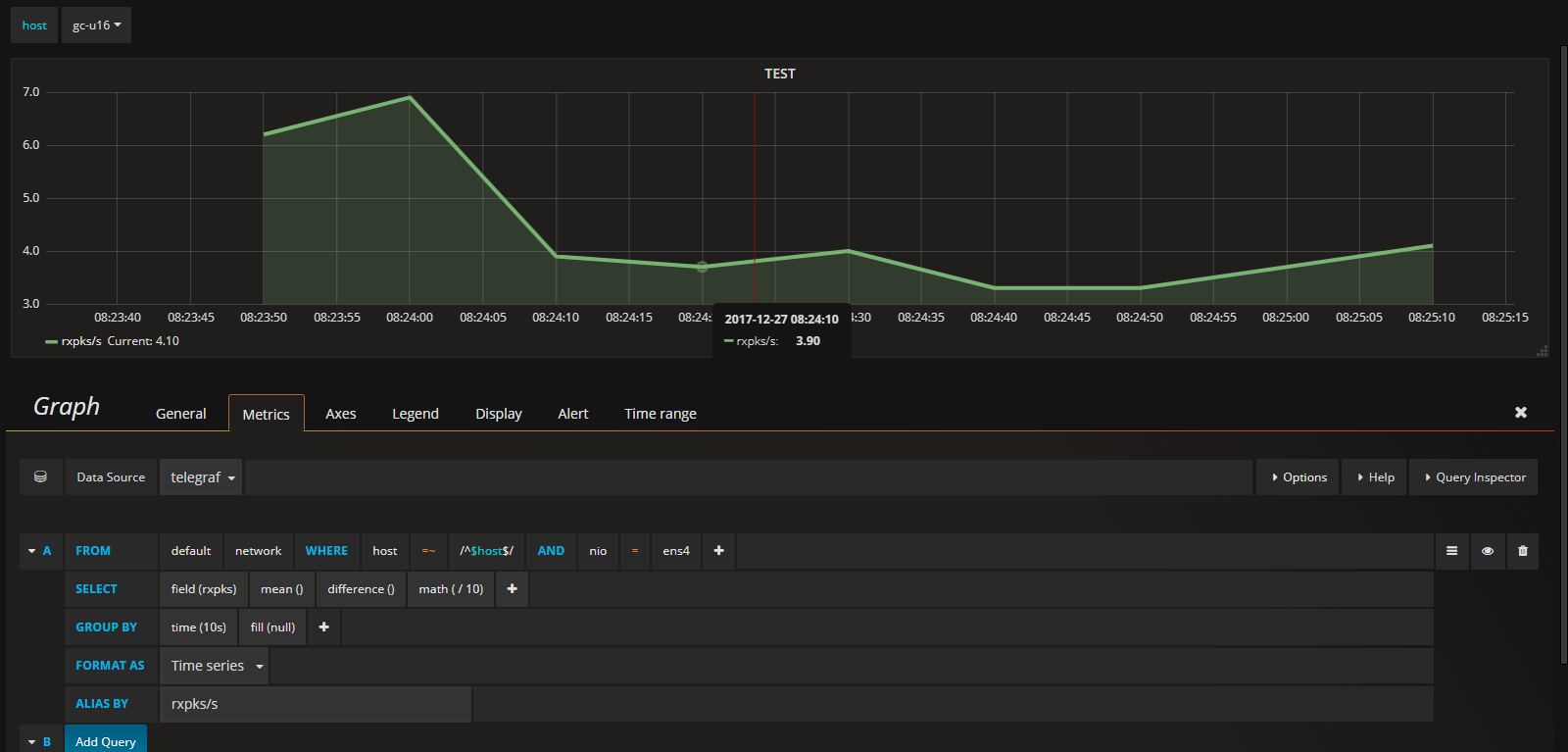
然后配置图形,这个就简单了,只要你数据没写错,基本上grafana都能采集到,这里忽略配置数据源创建dashboard和表格等乱七八糟的,直接上配置的sql图形,大致就是这样吧
influx+grafana自定义python采集数据和一些坑的总结的更多相关文章
- 这么多房子,哪一间是我的小窝?python采集数据并做数据可视化~
前言 嗨喽,大家好呀!这里是小熊猫 环境使用: (https://jq.qq.com/?_wv=1027&k=ONMKhFSZ) Python 3.8 Pycharm 模块使用: (https ...
- 性能测试 基于Python结合InfluxDB及Grafana图表实时采集Linux多主机性能数据
基于Python结合InfluxDB及Grafana图表实时采集Linux多主机性能数据 by:授客 QQ:1033553122 实现功能 测试环境 环境搭建 使用前提 使用方法 运行程序 效果展 ...
- 性能测试 基于Python结合InfluxDB及Grafana图表实时采集Linux多主机或Docker容器性能数据
基于Python结合InfluxDB及Grafana图表实时采集Linux多主机性能数据 by:授客 QQ:1033553122 实现功能 1 测试环境 1 环境搭建 3 使用前提 3 使用方法 ...
- python Django教程 之 模型(数据库)、自定义Field、数据表更改、QuerySet API
python Django教程 之 模型(数据库).自定义Field.数据表更改.QuerySet API 一.Django 模型(数据库) Django 模型是与数据库相关的,与数据库相关的代码 ...
- 【转】Python之数据序列化(json、pickle、shelve)
[转]Python之数据序列化(json.pickle.shelve) 本节内容 前言 json模块 pickle模块 shelve模块 总结 一.前言 1. 现实需求 每种编程语言都有各自的数据类型 ...
- Python 保存数据的方法(4种方法)
Python 保存数据的方法: open函数保存 使用with open()新建对象 写入数据(这里使用的是爬取豆瓣读书中一本书的豆瓣短评作为例子) import requests from lxml ...
- 在Caffe中使用 DIGITS(Deep Learning GPU Training System)自定义Python层
注意:包含Python层的网络只支持单个GPU训练!!!!! Caffe 使得我们有了使用Python自定义层的能力,而不是通常的C++/CUDA.这是一个非常有用的特性,但它的文档记录不足,难以正确 ...
- (数据科学学习手札06)Python在数据框操作上的总结(初级篇)
数据框(Dataframe)作为一种十分标准的数据结构,是数据分析中最常用的数据结构,在Python和R中各有对数据框的不同定义和操作. Python 本文涉及Python数据框,为了更好的视觉效果, ...
- 服务追踪数据使用 RabbitMQ 进行采集 + 数据存储使用 Elasticsearch + 数据展示使用 Kibana
服务追踪数据使用 RabbitMQ 进行采集 + 数据存储使用 Elasticsearch + 数据展示使用 Kibana https://www.cnblogs.com/xishuai/p/elk- ...
随机推荐
- WPF基础学习笔记整理 (二) XAML
基础知识: XAML:Extensible Application Markup Language, zammel: 用于实例化.NET对象的标记语言: XMAL使用树形逻辑结构描述UI: BAML: ...
- 对 Kotlin 与 Java 编程语言的思考
从长远来看,排名前10的也基本上是Java.C.C++.Python.C#.VB.PHP.JavaScript.至于Kotlin的排名,11月份在编程语言仅排41名,Ratings仅有0.216%. ...
- 《剑指offer》第三十七题(序列化二叉树)
// 面试题37:序列化二叉树 // 题目:请实现两个函数,分别用来序列化和反序列化二叉树. #include "BinaryTree.h" #include <iostre ...
- SQL Timeout超时的处理方法
第一步:修改Web.config配置文件.在数据库连接字符串中加上连接时间Connect Timeout,根据实际情况定时间. <!--连接数据库--> <connectionStr ...
- angular5 生命周期钩子函数
生命周期执行顺序ngOnChanges 在有输入属性的情况下才会调用,该方法接受当前和上一属性值的SimpleChanges对象.如果有输入属性,会在ngOnInit之前调用. ngOnInit 在组 ...
- Python mysql-SQL概要
2017-09-05 20:10:58 一.SQL语句及其种类 SQL使用关键字,表名,列名等组合成一条语句来描述操作的内容.关键字是指那些含义或者使用方法是先已经定义好的英语单词.根据RDBMS赋予 ...
- [可能没有默认的字体]Warning: imagettfbbox() [function.imagettfbbox]: Invalid font filename...
Warning: imagettfbbox() [function.imagettfbbox]: Invalid font filename... [可能没有默认的字体] 例: //putenv('G ...
- 超短reads(primer、barcode、UMI、index等)比对方法
二代reads最短都有50bp,所以大家常用的比对工具都是不支持50bp以下的reads的比对的. 但是,在实际中,我们确实又有比对super short reads的需求. So,我找到了如下方法来 ...
- 44 CSS 浮动 模态框 定位
一.浮动 float : 浮动的盒子不占原来的位置,其下方的盒子会上移 父盒子会发生塌陷现象.同一级盒子right浮动,同级左边的盒子需要左浮动,right浮动的盒子才能上来 由于浮动框不在文档的普通 ...
- ssh: connect to host 192.168.11.180 port 22: Connection refused
错误原因: 1.sshd 未安装:sudo apt-get install openssh-server 2.sshd 未启动:sudo net start sshd 3.防火墙:sudo ufw d ...