Scrapy-redis改造scrapy实现分布式多进程爬取
一.基本原理:
Scrapy-Redis则是一个基于Redis的Scrapy分布式组件。它利用Redis对用于爬取的请求(Requests)进行存储和调度(Schedule),并对爬取产生的项目(items)存储以供后续处理使用。scrapy-redi重写了scrapy一些比较关键的代码,将scrapy变成一个可以在多个主机上同时运行的分布式爬虫。
参考Scrapy-Redis官方github地址
二.准备工作:
1.安装并启动redis,Windows和lunix可以参考这篇
2.scrapy+Python环境安装
3.scrapy_redis环境安装
$ pip install scrapy-redis
$ pip install redis三.改造scrapy爬虫:
1.首先在settings.py中配置redis(在scrapy-redis 自带的例子中已经配置好)
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'
REDIS_URL = None # 一般情况可以省去
REDIS_HOST = '127.0.0.1' # 也可以根据情况改成 localhost
REDIS_PORT = 63792.item.py的改造
from scrapy.item import Item, Field
from scrapy.loader import ItemLoader
from scrapy.loader.processors import MapCompose, TakeFirst, Join
class ExampleItem(Item):
name = Field()
description = Field()
link = Field()
crawled = Field()
spider = Field()
url = Field()
class ExampleLoader(ItemLoader):
default_item_class = ExampleItem
default_input_processor = MapCompose(lambda s: s.strip())
default_output_processor = TakeFirst()
description_out = Join()3.spider的改造。star_turls变成了redis_key从redis中获得request,继承的scrapy.spider变成RedisSpider。
from scrapy_redis.spiders import RedisSpider
class MySpider(RedisSpider):
"""Spider that reads urls from redis queue (myspider:start_urls)."""
name = 'myspider_redis'
redis_key = 'myspider:start_urls'
def __init__(self, *args, **kwargs):
# Dynamically define the allowed domains list.
domain = kwargs.pop('domain', '')
self.allowed_domains = filter(None, domain.split(','))
super(MySpider, self).__init__(*args, **kwargs)
def parse(self, response):
return {
'name': response.css('title::text').extract_first(),
'url': response.url,
}四.启动爬虫:
$ scrapy crawl myspider可以输入多个来观察多进程的效果。。打开了爬虫之后你会发现爬虫处于等待爬取的状态,是因为list此时为空。所以需要在redis控制台中添加启动地址,这样就可以愉快的看到所有的爬虫都动起来啦。
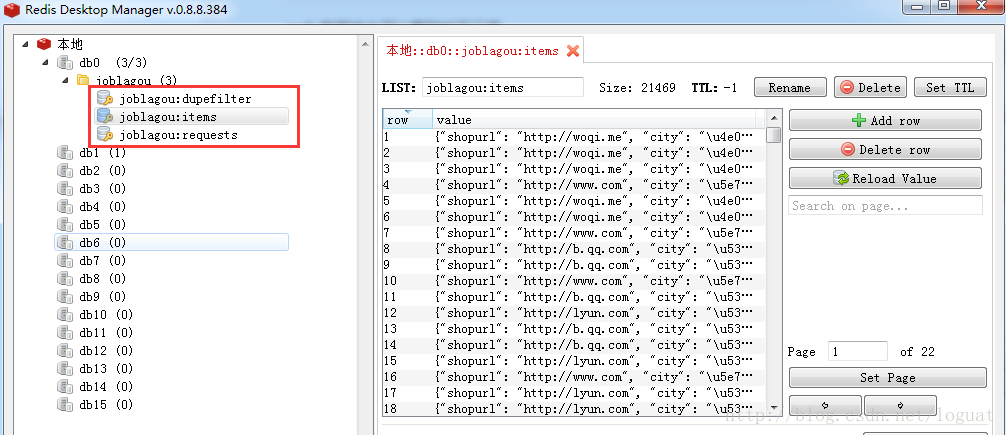
lpush mycrawler:start_urls http://www.***.comredis数据库中可以看到如下三项,第一个为已过滤并下载的request,第二个公用item,第三个为待处理request。
Scrapy-redis改造scrapy实现分布式多进程爬取的更多相关文章
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- scrapy框架基于CrawlSpider的全站数据爬取
引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法 ...
- python+BeautifulSoup+多进程爬取糗事百科图片
用到的库: import requests import os from bs4 import BeautifulSoup import time from multiprocessing impor ...
- 代理ip的使用以及多进程爬取
一.代理皮的简单使用 简单的看一二例子即可 import requests #代理ip 高频的ip容易被封,所以使用ip代理 #免费代理 ip:www.goubanjia.com 快代理 西祠代理 h ...
- 使用Xpath+多进程爬取诗词名句网的史书典籍类所有文章。update~
上次写了爬取这个网站的程序,有一些地方不完善,而且爬取速度较慢,今天完善一下并开启多进程爬取,速度就像坐火箭.. # 需要的库 from lxml import etree import reques ...
- python+正则+多进程爬取糗事百科图片
话不多说,直接上代码: # 需要的库 import requests import re import os from multiprocessing import Pool # 请求头 header ...
- 使用进程池模拟多进程爬取url获取数据,使用进程绑定的回调函数去处理数据
1 # 使用requests请求网页,爬取网页的内容 2 3 # 模拟使用进程池模拟多进程爬取网页获取数据,使用进程绑定的回调函数去处理数据 4 5 import requests 6 from mu ...
- scrapy爬虫笔记(三)------写入源文件的爬取
开始爬取网页:(2)写入源文件的爬取 为了使代码易于修改,更清晰高效的爬取网页,我们将代码写入源文件进行爬取. 主要分为以下几个步骤: 一.使用scrapy创建爬虫框架: 二.修改并编写源代码,确定我 ...
- Scrapy实战篇(八)之爬取教育部高校名单抓取和分析
本节我们以网址https://daxue.eol.cn/mingdan.shtml为初始链接,爬取教育部公布的正规高校名单. 思路: 1.首先以上面的地址开始链接,抓取到下面省份对应的链接. 2.在解 ...
随机推荐
- bzoj 2118 墨墨的等式 - 图论最短路建模
墨墨突然对等式很感兴趣,他正在研究a1x1+a2y2+…+anxn=B存在非负整数解的条件,他要求你编写一个程序,给定N.{an}.以及B的取值范围,求出有多少B可以使等式存在非负整数解. Input ...
- MAKEFILE 编程基础之一【转】
本文转载自:http://www.himigame.com/gcc-makefile/766.html 概述: 什么是makefile?或许很多Winodws的程序员都不知道这个东西,因为那些Wind ...
- hdu4528 小明系列故事——捉迷藏(记录状态的BFS)题解
思路: 一道BFS题,和以前的BFS有点不同,这里的vis数组需要记录每次走时的状态,所以开了3维,只对该状态下的vis修改. 注意坑点:S的位置是可以走的 代码: #include<queue ...
- jquery 浏览器打印
<!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <m ...
- Python 逗号的几种作用
转自http://blog.csdn.net/liuzx32/article/details/7831247 最近研究Python 遇到个逗号的问题 一直没弄明白 今天总算搞清楚了 1.逗号在参数传 ...
- [SpringBoot] - 上线一份项目记录
首先在服务器上运行war包. (新建项目) 其后,选择数据库,因为之前感觉mysql比较难安装,这次就再试一次,之前的PostgreSQL没有问题. 将原有文件进行复制,排除导包错误. 首先测试邮件发 ...
- 【Android实验】第一个Android程序与Activity生命周期
目录 第一个Android程序和Activity生命周期 实验目的 实验要求 实验过程 1. 程序正常启动与关闭 2. 外来电话接入的情况 3. 外来短信接入的情况 4. 程序运行中切换到其他程序(比 ...
- 使用 PYTHON 为 PIP 搭建 HTTP 代理
在一台没有 Root 权限的机器上,部署使用 Python 编写的服务,似乎只有 virtualenv 一条路可以选了. 当然我见过一些同事会在自己的家目录编译一个,然后设置一下 $PATH ,但是从 ...
- HDU 5963 朋友(找规律博弈)
http://acm.hdu.edu.cn/showproblem.php?pid=5963 题意: 思路: 我们可以先只考虑单链,自己试几种案例就可以发现规律,只有与根相连的边为1时,只需要奇数次操 ...
- 【Python】【环境搭建】
[环境配置] Windows : http://blog.csdn.net/zhunianguo/article/details/53524792 [Pycharm] pyCharm最新2018激活码 ...