ELK学习笔记之ElasticSearch简介
0x00 什么是Elasticsearch
Elasticsearch (ES)是一个基于 Lucene 的开源搜索引擎,它不但稳定、可靠、快速,而且也具有良好的水平扩展能力,是专门为分布式环境设计的,Elasticsearch是面向文档型数据库,这意味着它存储的
整个对象或者文档,它不但会存储它们,还会为他们建立索引,这样你就可以搜索他们了。你可以在 Elasticsearch 中索引、搜索、排序和过滤这些文档,不需要成行成列的数据,ElasticSearch 提供了一套基
于restful风格的全文检索服务组件。前身是compass,直到2010被一家公司接管进行维护,开始商业化,并提供了ElasticSearch 一些相关的产品,包括大家比较熟悉的 kibana、logstash 以及 ElasticSearch的
一些组件,比如安全组件shield 。当前最新的ElasticSearch 版本为 5.5.1 ,比较应用广泛的为2.X,直到 2016-12 推出了5.x 版本 ,将版本号调为 5.X 。这是为了和 kibana 和 logstash 等产品版本号进行统一ElasticSearch 。
0x01 Elasticsearch特性
1.安装方便:没有其他依赖,下载后安装非常方便;只用修改几个参数就可以搭建起来一个集群
2.JSON:输入/输出格式为 JSON,不需要定义 Schema,快捷方便
3.RESTful:基本所有操作(索引、查询、甚至是配置)都可以通过 HTTP 接口进行(REST风格架构设计)
4.分布式:节点对外表现对等(每个节点都可以用来做入口),加入节点自动均衡
5.多租户:可根据不同的用途分索引;可以同时操作多个索引
6.准实时:从文档索引到可以被检索只有轻微延时,约1s
7.支持插件机制,分词插件、同步插件、Hadoop插件、可视化插件等。

Elasticsearch使用Lucene作为内部引擎,但是在使用它做全文搜索时,只需要使用统一开发好的API即可,而不需要了解其背后复杂的Lucene的运行原理。当然Elasticsearch并不仅仅是Lucene这么简单,它不但包括了全文搜索功能,还可以进行以下工作:
1.分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
2.实时分析的分布式搜索引擎。
3.可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
4.这么多的功能被集成到一台服务器上,你可以轻松地通过客户端或者任何你喜欢的程序语言与ES的RESTful API进行交流。
0x02 ElasticSearch相关概念
下图是 Elasticsearch 插件 head 的一个截图
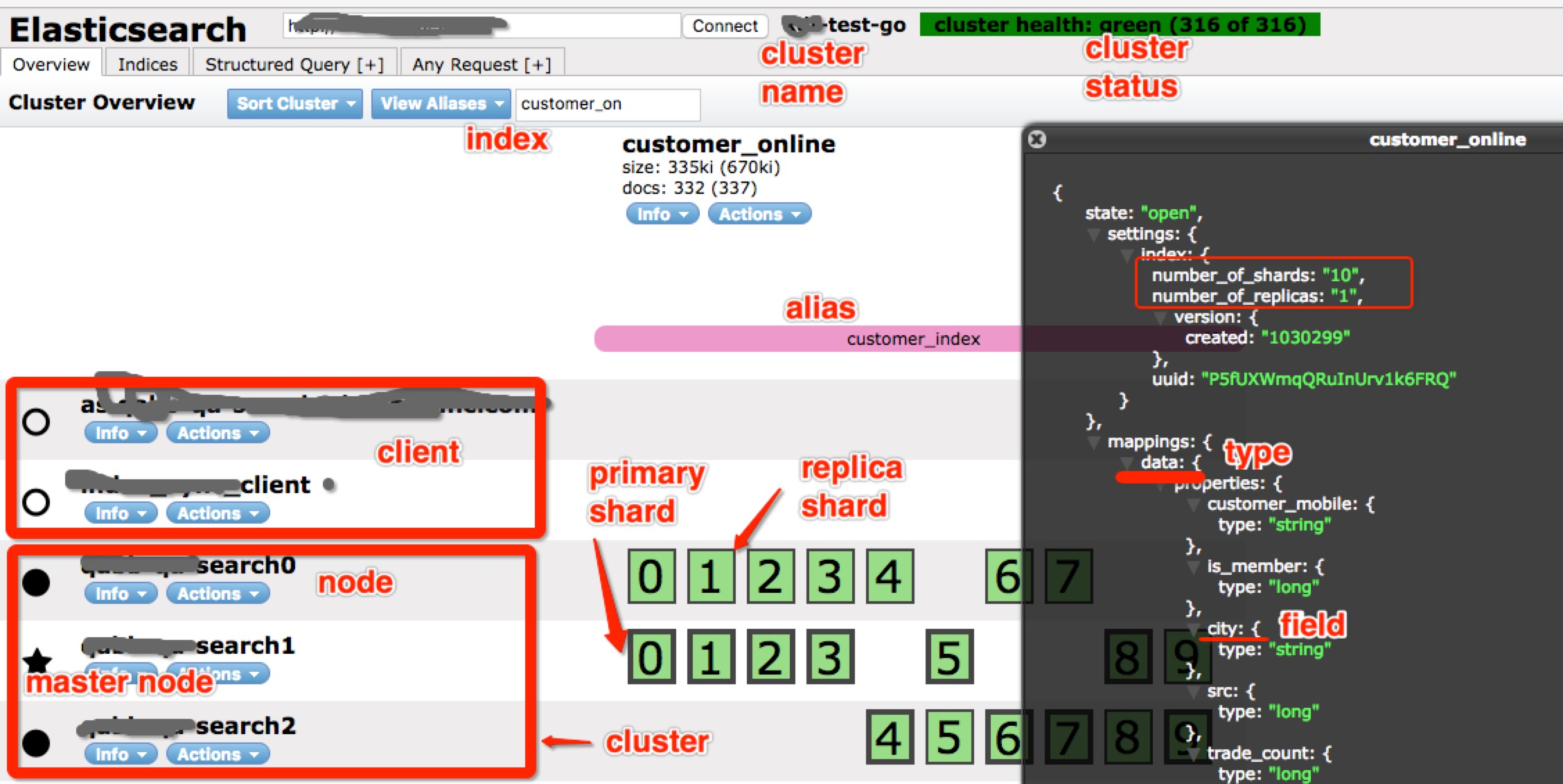
● node:即一个 Elasticsearch 的运行实例,使用多播或单播方式发现 cluster 并加入。
● cluster:包含一个或多个拥有相同集群名称的 node,其中包含一个master node。
● index:类比关系型数据库里的DB,是一个逻辑命名空间。
● alias:可以给 index 添加零个或多个alias,通过 alias 使用index 和根据index name 访问index一样,但是,alias给我们提供了一种切换index的能力,比如重建了index,取名● customer_online_v2,这时,有了alias,我要访问新 index,只需要把 alias 添加到新 index 即可,并把alias从旧的 index 删除。不用修改代码。
● type:类比关系数据库里的Table。其中,一个index可以定义多个type,但一般使用习惯仅配一个type。
● mapping:类比关系型数据库中的 schema 概念,mapping 定义了 index 中的 type。mapping 可以显示的定义,也可以在 document 被索引时自动生成,如果有新的 field,Elasticsearch 会自动推测出 field 的type并加到mapping中。
● document:类比关系数据库里的一行记录(record),document 是 Elasticsearch 里的一个 JSON 对象,包括零个或多个field。
● field:类比关系数据库里的field,每个field 都有自己的字段类型。
● shard:是一个Lucene 实例。Elasticsearch 基于 Lucene,shard 是一个 Lucene 实例,被 Elasticsearch 自动管理。之前提到,index 是一个逻辑命名空间,shard 是具体的物理概念,建索引、查询等都是
体的shard在工作。shard 包括primary shard 和 replica shard,写数据时,先写到primary shard,然后,同步到replica shard,查询时,primary 和 replica 充当相同的作用。replica shard 可以有多份,也可
没有,replica shard的存在有两个作用,一是容灾,如果primary shard 挂了,数据也不会丢失,集群仍然能正常工作;二是提高性能,因为replica 和 primary shard 都能处理查询。另外,如上图右侧红框
示,shard数和replica数都可以设置,但是,shard 数只能在建立index 时设置,后期不能更改,但是,replica 数可以随时更改。但是,由于 Elasticsearch 很友好的封装了这部分,在使用Elasticsearch 的过
中,我们一般仅需要关注 index 即可,不需关注shard。
综上所述,shard、node、cluster 在物理上构成了 Elasticsearch 集群,field、type、index 在逻辑上构成一个index的基本概念,在使用 Elasticsearch 过程中,我们一般关注到逻辑概念就好,就像我们在使用
MySQL 时,我们一般就关注DB Name、Table和schema即可,而不会关注DBA维护了几个MySQL实例、master 和 slave 等怎么部署的一样。
要了解ES首先就要弄清楚下面的几个概念,这样也不会对ES产生一些误解:
1. 近实时(NRT)
ES并不是一个标准的数据库,它不像MongoDB,它侧重于对存储的数据进行搜索。因此要注意到它 不是 实时读写 的,这也就意味着,刚刚存储的数据,并不能马上查询到。
当然这里还要区分查询的方式,ES也有数据的查询以及搜索,这里的近实时强调的是搜索....
2. 集群(Cluster)
在ES中,对用户来说集群是很透明的。你只需要指定一个集群的名字(默认是elasticsearch),启动的时候,凡是集群是这个名字的,都会默认加入到一个集群中。
你不需要做任何操作,选举或者管理都是自动完成的。
对用户来说,仅仅是一个名字而已!
3. 节点(Node)
跟集群的概念差不多,ES启动时会设置这个节点的名字,一个节点也就是一个ES得服务器。
默认会自动生成一个名字,这个名字在后续的集群管理中还是很有作用的,因此如果想要手动的管理或者查看一些集群的信息,最好是自定义一下节点的名字。
4. 索引(Index)
索引是一类文档的集合,所有的操作比如索引(索引数据)、搜索、分析都是基于索引完成的。
在一个集群中,可以定义任意数量的索引。
5. 类型(Type)
类型可以理解成一个索引的逻辑分区,用于标识不同的文档字段信息的集合。但是由于ES还是以索引为粗粒度的单位,因此一个索引下的所有的类型,都存放在一个索引下。这也就导致不同类型相同字段名字的字段会存在类型定义冲突的问题。
在2.0之前的版本,是可以插入但是不能搜索;在2.0之后的版本直接做了插入检查,禁止字段类型冲突。
6. 文档(Document)
文档是存储数据信息的基本单元,使用json来表示。
7. 分片与备份(Sherd & Replica)
在ES中,索引会备份成分片,每个分片是独立的lucene索引,可以完成搜索分析存储等工作。
分片的好处:
1. 如果一个索引数据量很大,会造成硬件硬盘和搜索速度的瓶颈。如果分成多个分片,分片可以分摊压力。
2. 分片允许用户进行水平的扩展和拆分
3. 分片允许分布式的操作,可以提高搜索以及其他操作的效率
拷贝一份分片就完成了分片的备份,那么备份有什么好处呢?
1. 当一个分片失败或者下线时,备份的分片可以代替工作,提高了高可用性。
2. 备份的分片也可以执行搜索操作,分摊了搜索的压力。
ES默认在创建索引时会创建5个分片,这个数量可以修改。
不过需要注意:
1. 分片的数量只能在创建索引的时候指定,不能在后期修改
2. 备份的数量可以动态的定义
0x03 Elasticsearch主要解决问题
1. 检索相关数据;
2. 返回统计结果;
3. 速度要快:
0x04 Elasticsearch工作原理
当ElasticSearch的节点启动后,它会利用多播(multicast)(或者单播,如果用户更改了配置)寻找集群中的其它节点,并与之建立连接。这个过程如下图所示:

0x05 Elasticsearch对外接口
1. JAVA API接口
2. RESTful API接口
0x06 Elasticsearch JAVA客户端
1.Transport客户端
Transport Client表示传输客户端,ElasticSearch内置客户端的一种,使用传输模块远程连接到Elasticsearch集群
2.Jest客户端
Jest是ElasticSearch的Java HTTP Rest客户端,第三方工具,它为索引和搜索结果提供了一个POJO编组机制
0x07 基于Lucence的全文检索
全文检索就是对一篇文章进行索引,可以根据关键字搜索,类似于mysql里的like语句。
全文索引就是把内容根据词的意义进行分词,然后分别创建索引,例如”你们的激情是因为什么事情来的” 可能会被分词成:“你们“,”激情“,“什么事情“,”来“ 等token,这样当你搜索“你们” 或者 “激情” 都会
这句搜出来。
0x08 ElasticSearch与传统关系型数据库对比
在ElasticSearch中,我们常常会听到Index、Type以及Document等概念,将Elasticsearch和传统关系型数据库MySQL做一下类比:

index => databases
type => table
field => field
document => record
mapping => schema
简单描述:
1) Index
定义:类似于mysql中的database。索引只是一个逻辑上的空间,物理上是分为多个文件来管理的。
命名:必须全小写
描述:因为本身ES是基于Lucene的,所以内部索引的本质上其实Lucene的索引构造方式.
ES中index可能被分为多个分片【对应物理上的lcenne索引】,在实践过程中每个index都会有一个相应的副 本。主要用来在硬件出现问题时,用来回滚数据的。这也某种程序上,加剧了ES对于内存高要求。
2)Type
定义:类似于mysql中的table,根据用户需求每个index中可以新建任意数量的type。
3)Document
定义:对应mysql中的row。有点类似于MongoDB中的文档结构,每个Document是一个json格式的文本。
4)Mapping
更像是一个用来定义每个字段类型的语义规范在mysql中类似sql语句,在ES中经过包装后,都被封装为友好的Restful风格的接口进行操作。这一点也是为什么开发人员更愿意使用ES或者compass这样的框架
而不是直接使用Lucene的一个原因。
5)Shards & Replicas
定义:能够为每个索引提供水平的扩展以及备份操作。
描述:
Shards:在单个节点中,index的存储始终是有限制,并且随着存储的增大会带来性能的问题。为了解决这个问题,ElasticSearch提供一个能够分割单个index到集群各个节点的功能。你可以在新建这个索引时,
手动的定义每个索引分片的数量。
6)Replicas
在每个node出现宕机或者下线的情况,Replicas能够在该节点下线的同时将副本同时自动分配到其他仍然可用的节点。而且在提供搜索的同时,允许进行扩展节点的数量,在这个期间并不会出现服务终止的情况。
默认情况下,每个索引会分配5个分片,并且对应5个分片副本,同时会出现一个完整的副本【包括5个分配的副本数据】。
从 Elasticsearch 中取出一条数据(document)看看:

由index、type和id三者唯一确定一个document,_source 字段中是具体的document 值,是一个JSON 对象,有5个field组成。
注意:mysql的Index和Elasticsearch的Index含义并不一致。
Elasticsearch集群可以包含多个索引(indices)(数据库),每一个索引可以包含多个类型(types)(表), 每一个类型包含多个文档(documents)(行),然后每个文档包含多个字段(Fields)(列)。数据被存储和索引在分片
(shards)中,索引只是把一个或多个分片分组在一起的逻辑空间。我们只需要知道文档存储在索引(index)中。其他细节都可以有Elasticsearch搞定。
总结:
(1)关系型数据库中的数据库(DataBase),等价于ES中的索引(Index) (2)一个数据库下面有N张表(Table),等价于1个索引Index下面有N多类型(Type)。 (3)一个数据库表(Table)下的数据由多行(ROW)多列(column,属性)组成,等价于1个Type由多个文档(Document)和多Field组成。 (4)在一个关系型数据库里面,schema定义了表、每个表的字段,还有表和字段之间的关系。 与之对应的,在ES中:Mapping定义索引下的Type的字段处理规则,即索引如何建立、索引类型、是否保存原 始索引JSON文档、是否压缩原始JSON文档、是否需要分词处理、如何进行分词处理等。 (5)在数据库中的增insert、删delete、改update、查search操作等价于ES中的增PUT/POST、删Delete、改_update、查GET。
0x09 Elasticsearch应用场景
1.它提供了强大的搜索功能,可以实现类似百度、谷歌等搜索。
2.可以搜索日志或者交易数据,用来分析商业趋势、搜集日志、分析系统瓶颈或者运行发展等等
3.可以提供预警功能(持续的查询分析某个数据,如果超过一定的值,就进行警告)
4.分析商业信息,在百万级的大数据中轻松的定位关键信息
5.维基百科使用Elasticsearch来进行全文搜做并高亮显示关键词,以及提供search-as-you-type、did-you-mean等搜索建议功能。
6.英国卫报使用Elasticsearch来处理访客日志,以便能将公众对不同文章的反应实时地反馈给各位编辑。
7.StackOverflow将全文搜索与地理位置和相关信息进行结合,以提供more-like-this相关问题的展现。
8.GitHub使用Elasticsearch来检索超过1300亿行代码。
0x10 Elasticsearch与Lucene的区别
Elasticsearch执行搜索的速度更快,可以简单的通过HTTP方式,使用JSON来操作数据,并支持对分布式集群的搜索。
Elasticsearch对分布式支持,其索引功能分拆为多个分片,每个分片可有0个或多个副本,集群中的每个数据节点都可承载一个或多个分片,并且能协调和处理各种操作;负载再平衡(Rebalancing)和路由
(Routing)在大多数情况下都是自动完成的。
Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
0x11 Elasticsearch与Solr的区别
比较总结:
1. 都是基于Lucene,且安装都很简单
2. Solr利用Zookeeper进行分布式管理,而Elasticsearch自身带有分布式协调管理功能
3. Solr支持更多格式的数据,而Elasticsearch仅支持json格式
4. Solr官方提供功能较多,而Elasticsearch更注重核心功能,高级功能多由第三方插件提供
5. Solr在传统的搜索应用中表现好于Elasticsearch,但Elasticsearch在实时搜索应用中效率更高
结论:
1. solr查询快,但更新索引时慢(即插入删除慢),用于电商等查询多的应用;
2.ES建立索引快(即查询慢),即实时性查询快,用于facebook新浪等搜索。
ELK学习笔记之ElasticSearch简介的更多相关文章
- ELK 学习笔记之 elasticsearch环境搭建
ELK概述: ElasticSearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等 Logstash是一 ...
- ELK学习笔记之Elasticsearch和Kibana数据导出实战
0x00 问题引出 以下两个导出问题来自Elastic中文社区. 问题1.kibana怎么导出查询数据?问题2:elasticsearch数据导出就像数据库数据导出一样,elasticsearch可以 ...
- ELK学习笔记之Elasticsearch启动常见错误
问题出现的环境: OS版本:CentOS-7-x86_64-Minimal-1708 ES版本:elasticsearch-6.2.2 1. max file descriptors [4096] f ...
- ELK学习笔记之ElasticSearch的索引详解
0x00 ElasticSearch的索引和MySQL的索引方式对比 Elasticsearch是通过Lucene的倒排索引技术实现比关系型数据库更快的过滤.特别是它对多条件的过滤支持非常好,比如年龄 ...
- ELK 学习笔记之 elasticsearch启动时Warning解决办法
elasticsearch启动时Warning解决办法: 转载:http://www.dajiangtai.com/community/18136.do?origin=csdn-geek&dt ...
- ELK 学习笔记之 elasticsearch Shard和Segment概念
Shard和segment概念: 转载: http://blog.csdn.net/likui1314159/article/details/53217750 Shard(分片) 一个Shard就是一 ...
- ELK 学习笔记之 elasticsearch elasticsearch.yml配置概述
elasticsearch.yml配置概述: 设置集群名字 cluster.name 定义节点名称 node.name 节点作为master,但是不负责存储数据,只是协调. node.master: ...
- ELK 学习笔记之 elasticsearch bool组合查询
elasticsearch bool组合查询: 相当于sql:where _type = 'books' and (price = 500 or title = 'bigdata') Note: mu ...
- ELK 学习笔记之 elasticsearch 基本查询
elasticsearch 基本查询: 基本查询: term查询: terms查询: from和size查询: match查询: match_all查询: match_phrase查询: multi_ ...
随机推荐
- Java 8新增的Lambda表达式
一. 表达式入门 Lambda表达式支持将代码块作为方法参数,lambda表达式允许使用更简洁的代码来创建只有一个抽象方法的接口(这种接口被称为函数式接口)的实例,相当于一个匿名的方法. 1.1 La ...
- Zabbix忘记登录密码重置
Zabbix忘记登录密码了 登录MySQL查看用户 select * from users\G 重置密码 mysql> use zabbix; mysql> update users se ...
- 10W年薪和30W+年薪的产品经理差距在哪?
举办到今年第六届壹佰案例峰会,认识的“程序猿/媛”朋友越来越多,时间长了就发现,程序员的世界一点也不单调,外界传说的不善言辞.最大的乐趣就是买“机械键盘”都是不对的.你见过周末组团去山里骑哈雷的研发经 ...
- java 中的继承
继承的概念 继承就是子类继承父类的特征和行为,使得子类具有父类得属性和方法. 继承得关键字:extends 语法格式:<modifier> class <name> [exte ...
- vue - 组件的创建
组件的创建 vue的核心基础就是组件的使用,玩好了组件才能将前面学的基础更好的运用起来.组件的使用更使我们的项目解耦合.更加符合vue的设计思想MVVM. 那接下来就跟我看一下如何在一个Vue实例中使 ...
- BZOJ5056 OI游戏 最短路+组合数学
链接接接接接! 正解:最短路+小学奥数 乘法原理 解题报告: 首先读懂题意(,,,我觉得我吃枣死于语文太差读不懂题目QAQ 大意就是港,要求从第一个点到其他各点的长度都是最短的方案有多少个(ummm, ...
- GitLab修改时区
https://yq.aliyun.com/articles/275765 一.背景 今天有同事在GitLab上查看时间的时候,发现GitLab上显示的时间和提交的时间不一致. 本地时间现在为:201 ...
- hibernate中cascade和inverse
原文:http://blog.sina.com.cn/s/blog_7b9edd020100racc.html 这两个属性都用于一多对或者多对多的关系中. 而inverse特别是用于双向关系,在单向关 ...
- Selenium之Css Selector使用方法
什么是Css Selector? Css Selector定位实际就是HTML的Css选择器的标签定位 工具 Css Selector的练习建议使用火狐浏览器,下载插件,FireFinder.Fire ...
- Django中的admin组件分析
admin的使用介绍 django-admin的使用 Django 提供了基于 web 的管理工具. Django 自动管理工具是 django.contrib 的一部分.可以在项目的 setting ...