oracle中merge into用法解析
merge into的形式:
- MERGE INTO [target-table] A USING [source-table sql] B ON([conditional expression] and [...]...)
- WHEN MATCHED THEN
- [UPDATE sql]
- WHEN NOT MATCHED THEN
- [INSERT sql]
作用:判断B表和A表是否满足ON中条件,如果满足则用B表去更新A表,如果不满足,则将B表数据插入A表但是有很多可选项,如下:
1.正常模式
2.只update或者只insert
3.带条件的update或带条件的insert
4.全插入insert实现
5.带delete的update(觉得可以用3来实现)
下面一一测试。
测试建以下表:
create table A_MERGE
(
id NUMBER not null,
name VARCHAR2(12) not null,
year NUMBER
);
create table B_MERGE
(
id NUMBER not null,
aid NUMBER not null,
name VARCHAR2(12) not null,
year NUMBER,
city VARCHAR2(12)
);
create table C_MERGE
(
id NUMBER not null,
name VARCHAR2(12) not null,
city VARCHAR2(12) not null
);
commit;
其表结构截图如下图所示:
A_MERGE表结构:
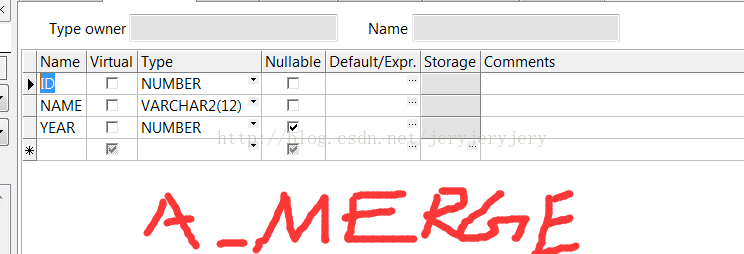
B_MERGE表结构
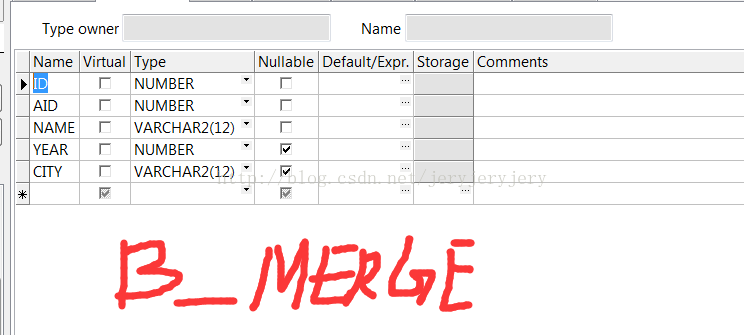
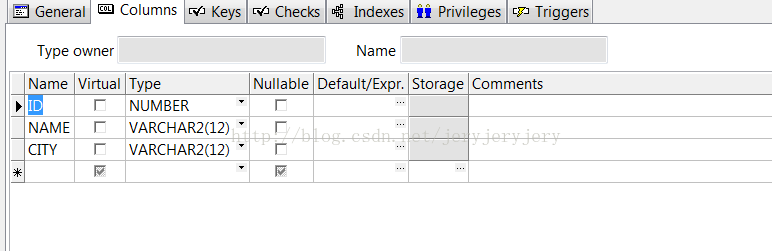
C_MERGE表结构
1.正常模式
先向A_MERGE和B_MERGE插入测试数据:
insert into A_MERGE values(1,'liuwei',20);
insert into A_MERGE values(2,'zhangbin',21);
insert into A_MERGE values(3,'fuguo',20);
commit;
insert into B_MERGE values(1,2,'zhangbin',30,'吉林');
insert into B_MERGE values(2,4,'yihe',33,'黑龙江');
insert into B_MERGE values(3,3,'fuguo','','山东');
commit;
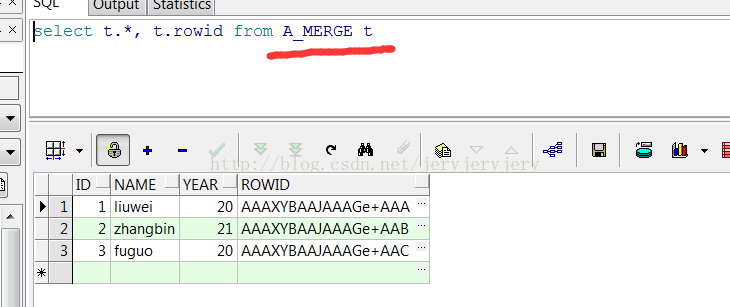
此时A_MERGE和B_MERGE表中数据截图如下:
A_MERGE表数据:
B_MERGE表数据:
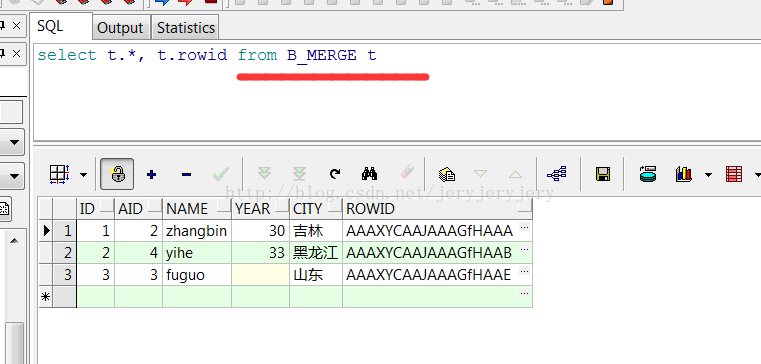
然后再使用merge into用B_MERGE来更新A_MERGE中的数据:
select A.ID, A.NAME,A.YEAR,B.ID,B.AID,B.NAME,B.CITY,B.YEAR from A_MERGE A,B_MERGE B WHERE A.ID= B.AID
MERGE INTO A_MERGE A USING (select B.AID,B.NAME,B.YEAR from B_MERGE B) C ON (A.id=C.AID)
WHEN MATCHED THEN
UPDATE SET A.YEAR=C.YEAR
WHEN NOT MATCHED THEN
INSERT(A.ID,A.NAME,A.YEAR) VALUES(C.AID,C.NAME,C.YEAR);
commit;
此时A_MERGE中的表数据截图如下:
2.只update模式
首先向B_MERGE中插入两个数据,来为了体现出只update没有insert,必须有一个数据是A中已经存在的
另一个数据时A中不存在的,插入数据语句如下:
- insert into B_MERGE values(4,1,'liuwei',80,'江西');
- insert into B_MERGE values(5,5,'tiantian',23,'河南');
- commit;
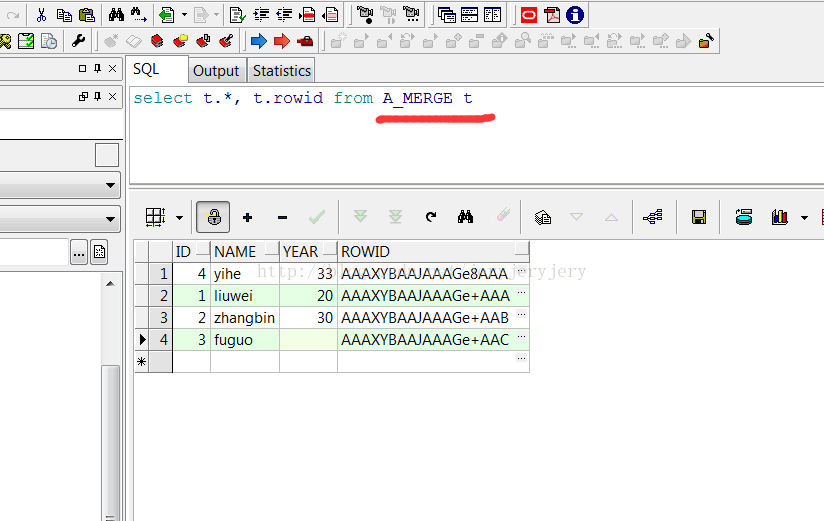
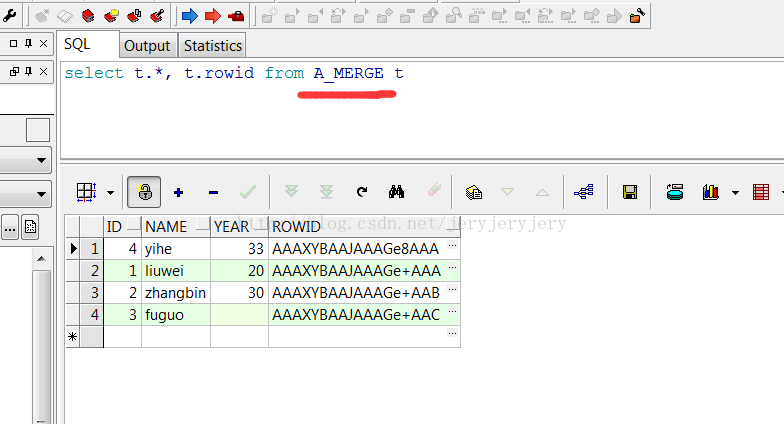
此时A_MERGE和B_MERGE表数据截图如下:
A_MERGE表数据截图:
B_MERGE表数据截图:
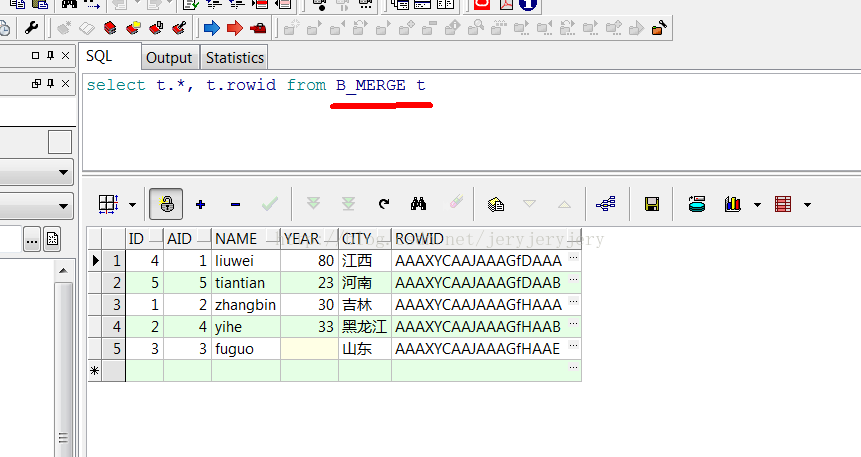
然后再次用B_MERGE来更新A_MERGE,但是仅仅update,没有写insert部分。
- merge into A_MERGE A USING (select B.AID,B.NAME,B.YEAR from B_MERGE B) C ON(A.ID=C.AID)
- WHEN MATCHED THEN
- UPDATE SET A.YEAR=C.YEAR;
- commit;
merge完之后A_MERGE表数据截图如下:可以发现仅仅更新了AID=1的年龄,没有插入AID=4的数据
3.只insert模式
首先改变B_MERGE中的一个数据,因为上次测试update时新增的数据没有插入到A_MERGE,这次可以用。
- update B_MERGE set year=70 where AID=2;
- commit;
此时A_MERGE和B_MERGE的表数据截图如下:
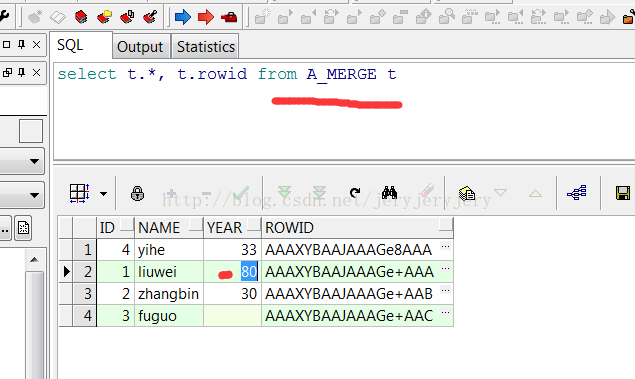
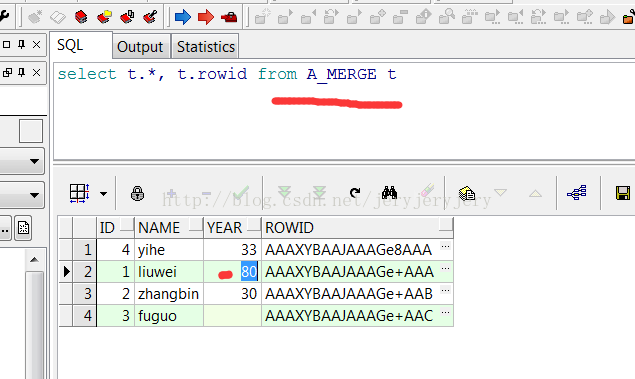
A_MERGE表数据:
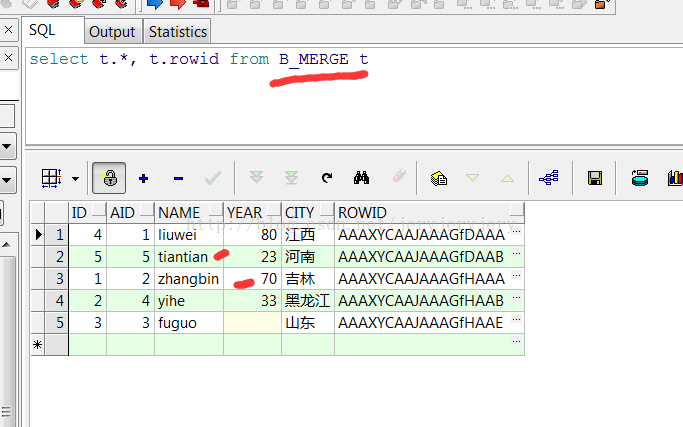
B_MERGE表数据:
然后用B_MERGE来更新A_MERGE中的数据,此时只写了insert,没有写update:
- merge into A_MERGE A USING (select B.AID,B.NAME,B.YEAR from B_MERGE B) C ON(A.ID=C.AID)
- WHEN NOT MATCHED THEN
- insert(A.ID,A.NAME,A.YEAR) VALUES(C.AID,C.NAME,C.YEAR);
- commit;
此时A_MERGE的表数据截图如下:
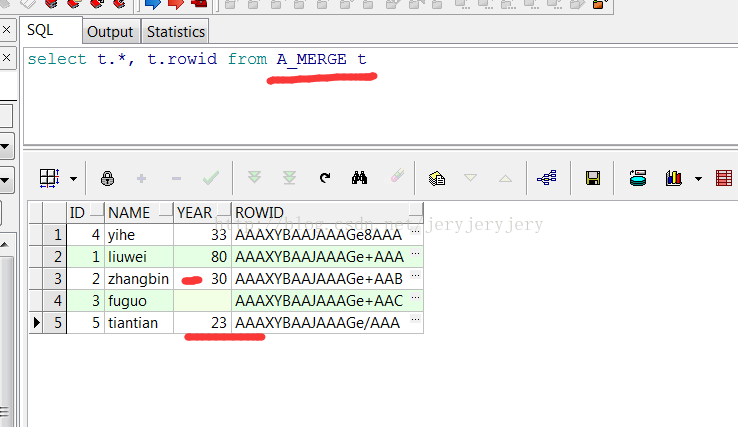
4.带where条件的insert和update。
我们在on中进行完条件匹配之后,还可以在后面的insert和update中对on筛选出来的记录再做一次条件判断,用来控制哪些要更新,哪些要插入。
测试数据的sql代码如下,我们在B_MERGE修改了两个人名,并且增加了两个人员信息,但是他们来自的省份不同,
所以我们可以通过添加省份条件来控制哪些能修改,哪些能插入:
- update B_MERGE set name='yihe++' where id=2;
- update B_MERGE set name='liuwei++' where id=4;
- insert into B_MERGE values(6,6,'ningqin',23,'江西');
- insert into B_MERGE values(7,7,'bing',24,'吉安');
- commit;
A_MGERGE表数据截图如下:
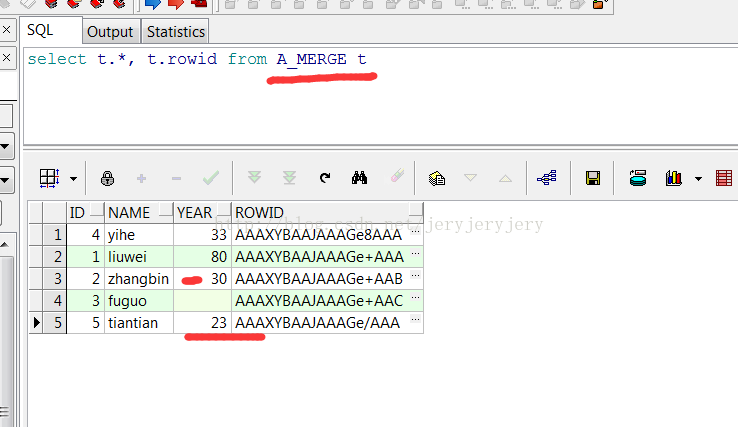
B_MERGE表数据:
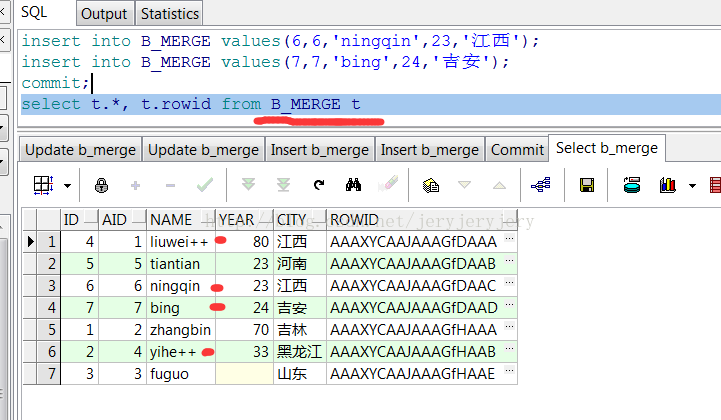
然后再用B_MERGE去更新A_MERGE,但是分别在insert和update后面添加了条件限制,控制数据的更新和插入:
- merge into A_MERGE A USING (select B.AID,B.name,B.year,B.city from B_MERGE B) C
- ON(A.id=C.AID)
- when matched then
- update SET A.name=C.name where C.city != '江西'
- when not matched then
- insert(A.ID,A.name,A.year) values(c.AID,C.name,C.year) where C.city='江西';
- commit;
此时A_MERGE截图如下:
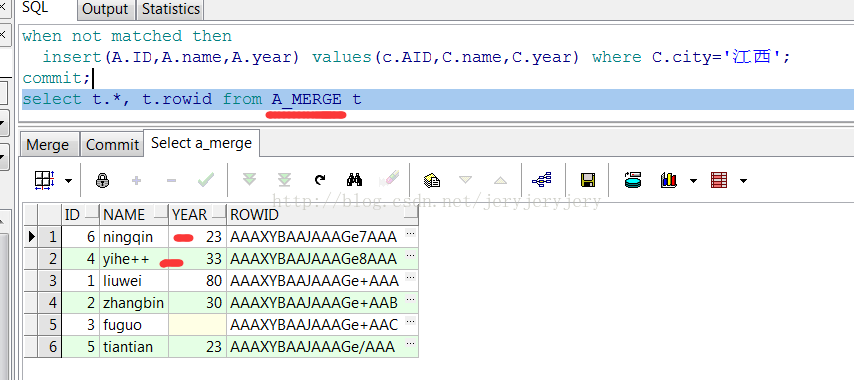
5.无条件的insert。
有时我们需要将一张表中所有的数据插入到另外一张表,此时就可以添加常量过滤谓词来实现,让其只满足
匹配和不匹配,这样就只有update或者只有insert。这里我们要无条件全插入,则只需将on中条件设置为永假
即可。用B_MERGE来更新C_MERGE代码如下:
- merge into C_MERGE C USING (select B.AID,B.NAME,B.City from B_MERGE B) C ON (1=0)
- when not matched then
- insert(C.ID,C.NAME,C.City) values(B.AID,B.NAME,B.City);
- commit;
C_MERGE表在merge之前的数据截图如下:
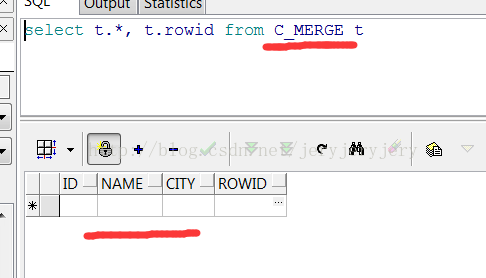
B_MERGE数据截图如下:
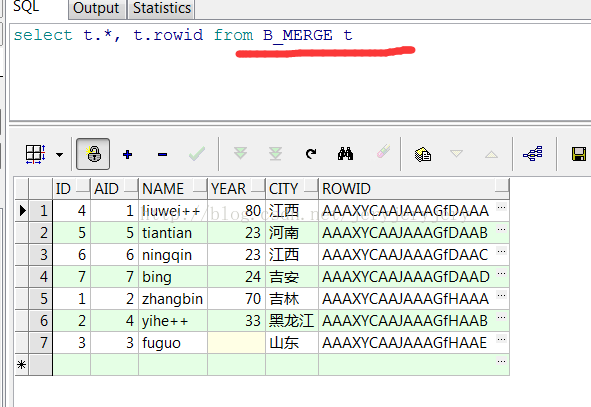
C_MERGE表在merge之后数据截图如下:
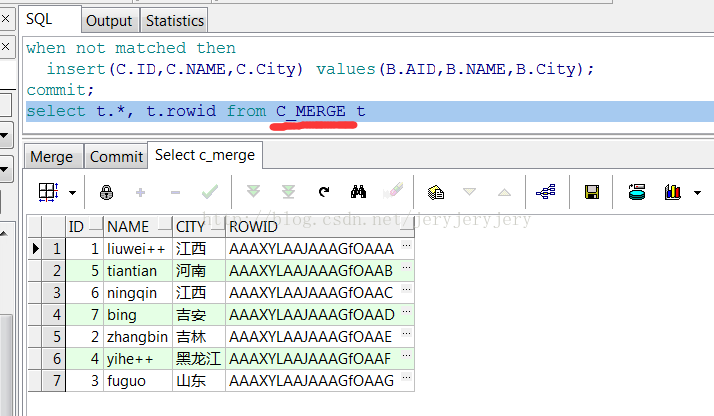
6.带delete的update
MERGE提供了在执行数据操作时清除行的选项. 你能够在WHEN MATCHED THEN UPDATE子句中包含DELETE子句.
DELETE子句必须有一个WHERE条件来删除匹配某些条件的行.匹配DELETE WHERE条件但不匹配ON条件的行不会被从表中删除.
但我觉得这个带where条件的update差不多,都是控制update,完全可以用带where条件的update来实现。
来源:https://blog.csdn.net/jeryjeryjery/article/details/70047022
oracle中merge into用法解析的更多相关文章
- oracle中merge的用法,以及各版本的区别 Create
Merge是一个非常有用的功能,类似于Mysql里的insert into on duplicate key. Oracle在9i引入了merge命令,通过这个merge你能够在一个SQL语句中对一个 ...
- Oracle中Merge into用法总结
MERGE语句是Oracle9i新增的语法,用来合并UPDATE和INSERT语句.通过MERGE语句,根据一张表或子查询的连接条件对另外一张表进行查询,连接条件匹配上的进行UPDATE,无法匹配的执 ...
- Oracle中的rownum用法解析
注意:rownum从1开始: 1.rownum按照记录插入时的顺序给记录排序,所以有order by的子句时一定要注意啊! 2.使用时rownum,order by字段是否为主键有什么影响? 3 ...
- SQL2008中Merge的用法
在SQL2008中,新增了一个关键字:Merge,这个和Oracle的Merge的用法差不多,只是新增了一个delete方法而已.下面就是具体的使用说明: 首先是对merge的使用说明: merge ...
- SQL2008中Merge的用法(轉載)
在SQL2008中,新增了一个关键字:Merge,这个和Oracle的Merge的用法差不多,只是新增了一个delete方法而已.下面就是具体的使用说明: 首先是对merge的使用说明: merge ...
- SQL2008中Merge的用法(转)
在SQL2008中,新增了一个关键字:Merge,这个和Oracle的Merge的用法差不多,只是新增了一个delete方法而已.下面就是具体的使用说明: 首先是对merge的使用说明: merge ...
- ORACLE中DBMS_SQL的用法
ORACLE中DBMS_SQL的用法 对于一般的select操作,如果使用动态的sql语句则需要进行以下几个步骤: open cursor---> parse---> define ...
- Oracle 中 decode 函数用法
Oracle 中 decode 函数用法 含义解释:decode(条件,值1,返回值1,值2,返回值2,...值n,返回值n,缺省值) 该函数的含义如下:IF 条件=值1 THEN RETURN(翻译 ...
- Oracle中group by用法
Oracle中group by用法 在select 语句中可以使用group by 子句将行划分成较小的组,一旦使用分组后select操作的对象变为各个分组后的数据,使用聚组函数返回的是每一个组的汇总 ...
随机推荐
- MongoDB联合查询 -摘自网络
1.简单手工关联 首先将结果查询出来放到一个变量里面,然后再查询 u = db.user.findOne({author:"wangwenlong"}); for(var p = ...
- Vue(五):Vue模板语法
1.{{...}}(双大括号) 文本插值 <div id="app"> <p>{{ message }}</p> </div> 2. ...
- c# vs2010 excel 上传oracle数据
excel 数据表上传到oracle数据库.过程例如以下: 1.打开本地excel文件 2.用OleDb连接excel文件 3.将来excel的数据读取到dataset中 4.把dataset 中数据 ...
- android studio(AS) Duplicate files copied in APK META-INF/NOTICE.txt
File 1: /home/slava/.gradle/caches/modules-2/files-2.1/org.apache.httpcomponents/httpmime/4.3.1/f789 ...
- zabbix 对服务器的负载做监控
# cat /etc/zabbix/zabbix_agentd.d/average.conf UserParameter=average[*],uptime|awk '{print $NF}' 自定义 ...
- mongodb学习比较(数据操作篇)
1. 批量插入: 以数组的方式一次插入多个文档可以在单次TCP请求中完成,避免了多次请求中的额外开销.就数据传输量而言,批量插入的数据中仅包含一份消息头,而多次单条插入则会在每次插入数据时封 ...
- spark join
https://jaceklaskowski.gitbooks.io/mastering-apache-spark/content/spark-sql-joins.html https://acadg ...
- Ossec添加Agent端流程总结
(1) 服务器上添加客户端 在服务器上添加客户端,执行如下命令,按照提示进行输入,红色部分是我们输入的: [root@ossec-server logs]# /var/ossec/bin/manage ...
- 双系统linux+win之血的教训
绝对不要用win的软件来直接调整linux分区!!!!! 除非你不想要这个linux分区里的数据了...
- Linux下双网卡绑定bond0【转】
一:原理: linux操作系统下双网卡绑定有七种模式.现在一般的企业都会使用双网卡接入,这样既能添加网络带宽,同时又能做相应的冗余,可以说是好处多多.而一般企业都会使用linux操作系统下自带的网卡绑 ...