复现ICCV 2017经典论文—PyraNet
.
过去几年发表于各大 AI 顶会论文提出的 400 多种算法中,公开算法代码的仅占 6%,其中三分之一的论文作者分享了测试数据,约 54% 的分享包含“伪代码”。这是今年 AAAI 会议上一个严峻的报告。 人工智能这个蓬勃发展的领域正面临着实验重现的危机,就像实验重现问题过去十年来一直困扰着心理学、医学以及其他领域一样。最根本的问题是研究人员通常不共享他们的源代码。
可验证的知识是科学的基础,它事关理解。随着人工智能领域的发展,打破不可复现性将是必要的。
Learning Feature Pyramids for Human Pose Estimation 是发表在 ICCV 2017 的工作,论文提出了一个新的特征金字塔模块,在卷积网络中学习特征金字塔,并修正了现有的网络参数初始化方法,在人体姿态估计和图像分类中都取得了很好的效果。

论文复现代码:
http://aistudio.baidu.com/?_=1540892031956#/projectdetail/29380
LSP数据集简介
LSP && LSP_extended
这个数据集是由 Flickr 上‘Volleyball’, ‘Badminton’, ‘Athletics’, ‘Baseball’, ‘Gymnastics’, ‘Parkour’, ‘Soccer’, ‘Tennis’(原数据集), ‘parkour’, ‘gymnastics’, and ‘athletics’ (扩展集)等标签所构成。
每个图片都由 Amazon Mechanical Turk 和类似的途径标注而来,并不高度准确。这些图片被缩放至每个人大约 150 px 长度进行标注,包含了 14 个节点。
LSP 地址:
http://sam.johnson.io/research/lsp_dataset.zip
LSP 样本数:2000 个(全身,单人)
LSP_extended 地址:
http://sam.johnson.io/research/lspet_dataset.zip
LSP_extended 样本数:10000 个(全身,单人)
LSP && LSP_extended 共 12000 个标注,节点是以下 14 个:
{1. Right ankle 2. Right knee 3. Right hip 4. Left hip 5. Left knee 6.Left ankle 7.Right wrist 8. Right elbow 9. Right shoulder 10. Left shoulder 11. Left elbow 12. Left wrist 13. Neck 14. Head top}
由于是单人数据集,该数据集的训练难度比多人数据集更简单。
MPII数据集简介
MPII 人体姿势数据集是人体姿势预估的一个 benchmark,数据集包括了超过 40k 人的 25000 张带标注图片,这些图片是从 YouTube video 中抽取出来的。在测试集中还收录了身体部位遮挡、3D 躯干、头部方向的标注。
MPII 地址:
http://human-pose.mpi-inf.mpg.de/#overview
MPII 样本数:25000 个(单人、多人)
包括以下 16 类标注:
{Head – 0, Neck – 1, Right Shoulder – 2, Right Elbow – 3, Right Wrist – 4, Left Shoulder – 5, Left Elbow – 6, Left Wrist – 7, Right Hip – 8, Right Knee – 9, Right Ankle – 10, Left Hip – 11, Left Knee – 12, Left Ankle – 13, Chest – 14, Background – 15}
数据集处理
MATLAB格式读入
文件 joints.mat 是 MATLAB 数据格式,包含了一个以 x 坐标、y 坐标和一个表示关节可见性的二进制数字所构成的 3 x 14 x 10000 的矩阵。使用模块 scipy.io 的函数 loadmat 和 savemat 可以实现对 mat 数据的读写。读入后对原始标注进行转置,转置目的是分离每个图片的标注。
import scipy.io as sio
import numpy as np
data = sio.loadmat(self.lsp_anno_path[count])
joints = data['joints']
joints = np.transpose(joints, (2, 1, 0))
JSON格式读入
MPII 数据集是以 JSON 格式进行的标注,可以通过 JSON 库进行读入。
import json
anno = json.load(self.mpii_anno_pah)将每个图片打包成(图片,标注,bounding box)的形式,bounding box 即图片大小,其目的是将大小不一的图片处理成 256 x 256 的大小。
from PIL import Image
for idd, joint_idd in enumerate(joints):
image_name = "im%s.jpg" % str(idd + 1).zfill(5) if count else "im%s.jpg" % str(idd + 1).zfill(4)
joint_id = idd + len(joints) if count else idd
im_path = os.path.join(self.lsp_data_path[count], image_name)
im = Image.open(im_path)
im = np.asarray(im)
shape = im.shape
bbox = [0, 0, shape[1], shape[0]]
joint_dict[joint_id] = {'imgpath': im_path, 'joints': joint_idd, 'bbox': bbox}数据增强
作者用到了几种数据增强的手段:
缩放 scale
旋转 rotate
翻转 flip
添加颜色噪声 add color noise
缩放
读入数据后,需要先把大小不一的标注图片统一转换成 256 x 256。
对于 LSP 测试集,作者使用的是图像的中心作为身体的位置,并直接以图像大小来衡量身体大小。数据集里的原图片是大小不一的(原图尺寸存在 bbox 里),一般采取 crop 的方法有好几种,比如直接进行 crop,然后放大,这样做很明显会有丢失关节点的可能性。也可以先把图片放在中间,然后将图片缩放到目标尺寸范围内原尺寸的可缩放的大小,然后四条边还需要填充的距离,最后 resize 到应有大小。
这里采用的是先扩展边缘,然后放大图片,再进行 crop,这样做能够保证图片中心处理后依然在中心位置,且没有关节因为 crop 而丢失。注意在处理图片的同时需要对标注也进行处理。
要注意 OpenCV 和 PIL 读入的 RGB 顺序是不一样的,在使用不同库进行处理时要转换通道。
import cv2
big_img = cv2.copyMakeBorder(img, add, add, add, add, borderType = cv2.BORDER_CONSTANT, value=self.pixel_means.reshape(-1))
#self.show(bimg)
bbox = np.array(dic['bbox']).reshape(4, ).astype(np.float32)
bbox[:2] += add
if 'joints' in dic:
process(joints_anno)
objcenter = np.array([bbox[0] + bbox[2] / 2., bbox[1] + bbox[3] / 2.])
minx, miny, maxx, maxy = compute(extend_border, objcenter, in_size, out_size)
img = cv2.resize(big_img[min_y: max_y, min_x: max_x,:], (width, height))
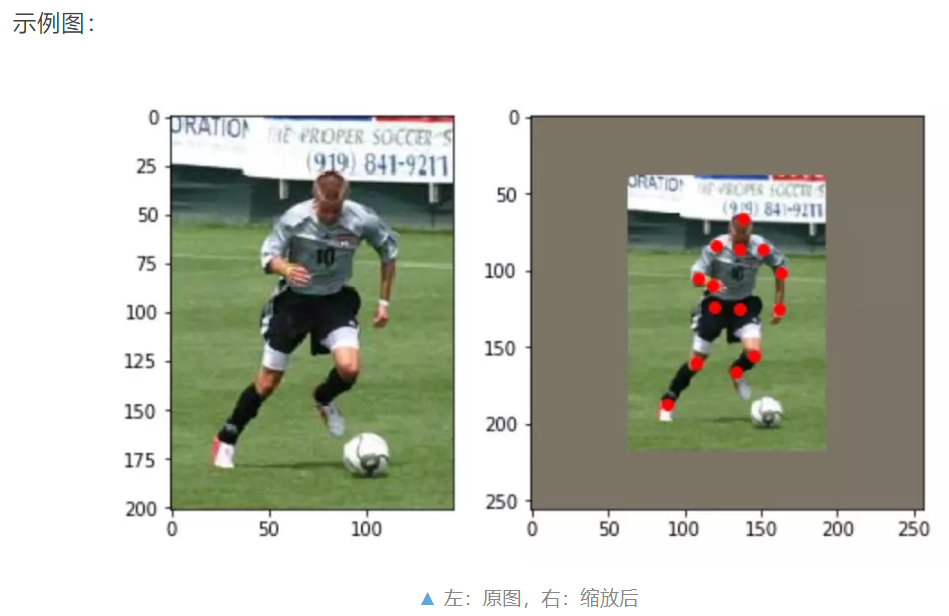
示例图的十四个标注点:
(88.995834, 187.24898);(107.715065, 160.57408);(119.648575, 124.30561) (135.3259, 124.53958);(145.38748, 155.4263);(133.68799, 165.95587) (118.47862, 109.330215);(108.41703, 104.65042);(120.81852, 84.05927) (151.70525, 86.63316);(162.93677, 101.14057);(161.29883, 124.773575) (136.0279, 85.93119);(138.13379, 66.509995)
旋转
旋转后点的坐标需要通过一个旋转矩阵来确定,在网上的开源代码中,作者使用了以下矩阵的变换矩阵围绕着 (x,y) 进行任意角度的变换。
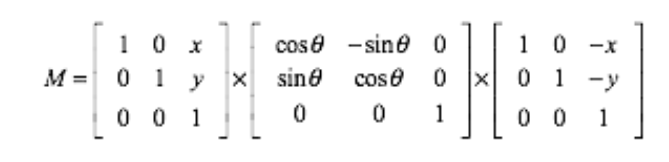
在 OpenCV 中可以使用:
cv2.getRotationMatrix2D((center_x, center_y) , angle, 1.0)
newimg = cv2.warpAffine(img, rotMat, (width, height))
得到转换矩阵,并通过仿射变换得到旋转后的图像。而标注点可以直接通过旋转矩阵获得对应点。
rot = rotMat[:, : 2]
add = np.array([rotMat[0][2], rotMat[1][2]])
coor = np.dot(rot, coor) + w该部分代码:
def rotate(self, img, cord, anno, center):
angle = random.uniform(45, 135)
rotMat = cv2.getRotationMatrix2D((center[0], center[1]) , angle, 1.0)
newimg = cv2.warpAffine(img, rotMat, (width, height))
for i in range(n):
x, y = anno[i][0], anno[i][1]
coor = np.array([x, y])
rot = rotMat[:, : 2]
add = np.array([rotMat[0][2], rotMat[1][2]])
coor = np.dot(rot, coor) + add
label.append((coor[0], coor[1]))
newimg = newimg.transpose(2, 0, 1)
train_data[cnt++] = newimg
train_label[cnt++] = np.array(label)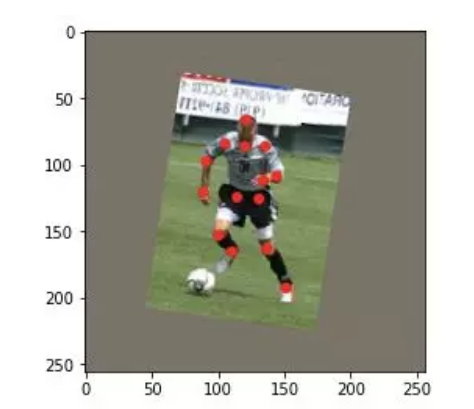
翻转
使用 OpenCV 中的 flip 进行翻转,并对标注点进行处理。在 OpenCV 中 flip 函数的参数有 1 水平翻转、0 垂直翻转、-1 水平垂直翻转三种。
def flip(self, img, cod, anno_valid, symmetry):
'''对图片进行翻转'''
newimg = cv2.flip(img, 1)
train_data[counter] = newimg.transpose(2, 0, 1)
'''处理标注点,symmetry是flip后所对应的标注,具体需要自己根据实际情况确定'''
for (l, r) in symmetry:
cod[l], cod[r] = cod[l], cod[r]
for i in range(n):
label.append((cod[i][0],cod[i][1]))
train_label[cnt++] = np.array(label)

添加颜色噪声
我所采用的方法是直接添加 10% 高斯分布的颜色点作为噪声。人为地损失部分通道信息也可以达到添加彩色噪声的效果。
def add_color_noise(self, image, percentage=0.1):
noise_img = image
'''产生图像大小10%的随机点'''
num = int(percentage*image.shape[0]*image.shape[1])
'''添加噪声'''
for i in range(num):
x = np.random.randint(0,image.shape[0])
y = np.random.randint(0,image.shape[1])
for j in range(3):
noise_img[x, y, i] = noise_img[x, y, i] + random.gauss(2,4)
noise_img[x, y, i] = 255 if noise_img[x, y, ch] > 255 else 0
return noise_img
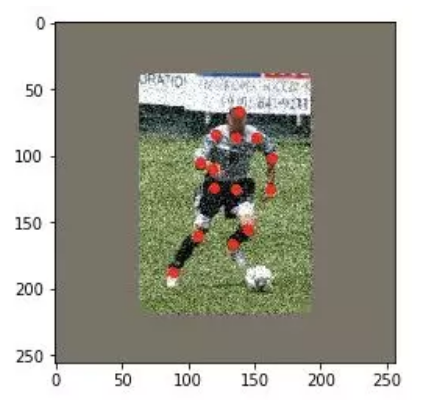
除此之外,以下数据增强的方法也很常见:
1. 从颜色上考虑,还可以做图像亮度、饱和度、对比度变化、PCA Jittering(按照 RGB 三个颜色通道计算均值和标准差后在整个训练集上计算协方差矩阵,进行特征分解,得到特征向量和特征值);
2. 从图像空间性质上考虑,还可以使用随机裁剪、平移;
3. 从噪声角度,高斯噪声、椒盐噪声、模糊处理;
4. 从类别分布的角度,可以采用 label shuffle、Supervised Data Augmentation(海康威视 ILSVRC 2016 的 report)。
在这个具体例子中,进行数据增强的时候要考虑的是:1)形变会不会影响结果;2)会不会丢掉部分节点。
制作Paddle数据
使用 paddle.batch 批量读入数据,并制作成 Paddle 的数据格式。
reader = paddle.batch(self.read_record(test_list, joint_dict,
mode = 'train'), batch_size=1)
fluid.recordio_writer.convert_reader_to_recordio_file("./work/test_" + str(i) + "_test.recordio",
feeder=feeder, reader_creator=reader) 其他数据相关内容
论文的评价标准
PCK:检测的关键点与其对应的 groundtruth 之间的归一化距离小于设定阈值的比例。在本篇论文中,作者将图片中心作为身体的位置,并以图片大小作为衡量身体尺寸的标准。
PCK@0.2 on LSP && LSP-extended:以驱干直径为归一化标准。
PCKh@0.5 on MPII:以头部为归一化标准。
关于训练的过拟合抢救
对于容易过拟合的数据,数据增强是比较重要的,训练的时候学习率需要不能太大,当一次训练过拟合后,可以从 loss 曲线波动的地方回溯到较为平稳的点,并以平稳点的学习率为起点,以更低的学习率接上上次学习。
关于PaddlePaddle
查了一下资料,PaddlePaddle 最早在 16 年就已经对外开放,然而可能因为本人入门做机器学习时间较晚有关,在复现活动之前,我只是听过有一个开源深度学习平台而不知道其名字。
从官方开源的一些 demo 项目来讲,对推荐和文本处理方面的应用比较友好,搜索相关关键字也能获得很多入门的博客、在不同环境的安装指南,官方甚至还做了教学视频。
据说当前版本的 Fluid 在编写逻辑上和过去的版本已经有了很大的区别,在使用上直观的感受是和 TensorFlow 有一定的相似性。
但由于不熟悉这个框架,也会遇到一些问题:一开始在 AI 开放平台上找了半天没找到文档入口,在搜索引擎上才发现有另一个 paddlepaddle.org 的入口;当一些算子的名字和其他框架不太一样的时候,不太容易从文档里找到;不清楚不同版本之间的区别(能跑就行?);官网介绍对大规模计算友好、对可视化的支持均没有体验;Notebook 非常容易崩等问题等等……
尽管如此,在使用一定时间后,我觉得还是觉得挺方便的。这个框架的使用群体目前并不多,对大公司来讲大家都有内部各自对 TensorFlow 的封装性优化平台,对入门者而言往往又不是那么首选.
从个人学习路径来讲,我觉得就 TensorFlow 和现在流行的 PyTorch 而言,前者是业界工程依赖程度高,后者是研究者使用方便,PaddlePaddle 需要有一个清晰的受众定位和有效的推广机制。
复现ICCV 2017经典论文—PyraNet的更多相关文章
- ICCV 2017论文分析(文本分析)标题词频分析 这算不算大数据 第一步:数据清洗(删除作者和无用的页码)
IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017. IEE ...
- Image Captioning 经典论文合辑
Image Caption: Automatically describing the content of an image domain:CV+NLP Category:(by myself, y ...
- ICCV 2017 Best Paper Awards
[ICCV 2017 Best Paper Awards]今年的ICCV不久前公布了Best Paper得主,來自Facebook AI Research的Mask R-CNN[1],與RetineN ...
- PointCloud及其经典论文介绍
这篇博客会介绍点云的基本知识,重点介绍最近两年发表的部分经典论文,有什么建议欢迎留言! 点云基本介绍 点云是某个坐标系下的点的数据集,包含了丰富的信息,可以是三维坐标X,Y,Z.颜色.强度值.时间等等 ...
- 巨经典论文!推荐系统经典模型Wide & Deep
今天我们剖析的也是推荐领域的经典论文,叫做Wide & Deep Learning for Recommender Systems.它发表于2016年,作者是Google App Store的 ...
- Memory Networks01 记忆网络经典论文
目录 1.Memory Networks 框架 流程 损失函数 QA 问题 一些扩展 小结 2.End-To-End Memory Networks Single Layer 输入模块 算法流程 Mu ...
- 经典论文系列| 实例分割中的新范式-SOLO
前言: 这是实例分割中的一篇经典论文,以往的实例分割模型都比较复杂,这篇论文提出了一个简单且直接的实例分割模型,如何设计这种简单直接的模型且要达到一定的精度往往会存在一些困难,论文中有很多思路或思想值 ...
- 经典论文系列 | 目标检测--CornerNet & 又名 anchor boxes的缺陷
前言: 目标检测的预测框经过了滑动窗口.selective search.RPN.anchor based等一系列生成方法的发展,到18年开始,开始流行anchor free系列,CornerNe ...
- 经典论文系列 | 缩小Anchor-based和Anchor-free检测之间差距的方法:自适应训练样本选择
前言 本文介绍一篇CVPR2020的论文,它在paperswithcode上获得了16887星,谷歌学术上有261的引用次数. 论文主要介绍了目标检测现有的研究进展.anchor-based和 ...
随机推荐
- Eclipse SVN 使用教程
Eclipse SVN 使用教程 做好以上的准备后打开Eclipse编译器,点击编译器右上角的Open Perspective 打开SVN资源库界面,新建一个资源库 选择资源库的位置,这里我们就用刚才 ...
- windows运行打开服务命令
1. gpedit.msc-----组策略 2. sndrec32-------录音机 3. Nslookup-------IP地址侦测器 4. explorer-------打开资源管 ...
- 【计算机视觉】如何使用opencv自带工具训练人脸检测分类器
前言 使用opencv自带的分类器效果并不是很好,由此想要训练自己的分类器,正好opencv有自带的工具进行训练.本文就对此进行展开. 步骤 1.查找工具文件: 2.准备样本数据: 3.训练分类器: ...
- POJ 3069:Saruman's Army
Saruman's Army Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 13242 Accepted: 6636 D ...
- 【java规则引擎】《Drools7.0.0.Final规则引擎教程》第4章 4.4 LHS简介&Pattern
LHS简介 在规则文件组成章节,我们已经了解了LHS的基本使用说明.LHS是规则条件部分的统称,由0个或多个条件元素组成.前面我们已经提到,如果没有条件元素那么默认就是true. 没有条件元素,官方示 ...
- test20180919 选择客栈
题意 分析 不难发现把增加人数看成减少人数,上限是w 看成总数是w,问题就变成了询问有多少个子区间没有0. 考虑这个问题困难在哪里,就是区间加减法让我们不好判断0 的位置. 因为题目保证每个位置的值非 ...
- 使用OASGraph 暴露rest 接口为graphql api
OASGraph 是loopback 团队开发的方便将rest api 暴露为graphql 的工具, 这个也是loopback 4 的一个新特性类似的有些团队提出了binding 以及stitch ...
- cocos2dx学习资料
[9秒原创]cocos2d-x——CCScrollView用法 http://www.9miao.com/thread-45619-1-1.html [9秒原创]cocos2d-x——场景切换效果示例 ...
- FastAdmin 插件的 Git 开发流程(简明)
FastAdmin 插件的 Git 开发流程(简明) cms zip 安装 包安装 删除 addons 里的 cms 使用 mklink 软链接到 cms 插件 Git 仓库 修改 cms 插件 gi ...
- [NN] 对于BackPropagation(BP, 误差反向传播)的一些理解
本文大量参照 David E. Rumelhart, Geoffrey E. Hinton and Ronald J. Williams, Learning representation by bac ...