大数据开发实战:Stream SQL实时开发一
1、流计算SQL原理和架构
流计算SQL通常是一个类SQL的声明式语言,主要用于对流式数据(Streams)的持续性查询,目的是在常见流计算平台和框架(如Storm、Spark Streaming、Flink、Beam等)的底层API上,
通过使用简易通用的的SQL语言构建SQL抽象层,降低实时开发的门槛。
流计算SQL的原理其实很简单,就是在SQL和底层的流计算引擎之间架起一座桥梁---流计算SQL被用户提交,被SQL引擎层翻译为底层的API并在底层的流计算引擎上执行。比如对Storm
来说,会自动翻译成Storm的任务拓扑并在Storm集群上运行。
流计算SQL引擎是流计算SQL的核心,主要负责对用户SQL输入进行语法分析、语义分析、逻辑计划生成、逻辑计划执行、物理执行计划生成等操作。而真正执行计算的是底层的流计算平台。
不同于离线任务,实时的数据是不断流入的,所以为了使用SQL来对流处理进行抽象,流计算SQL也引入了“表”的概念,不过这里的表是动态表。
流计算SQL的架构如下:
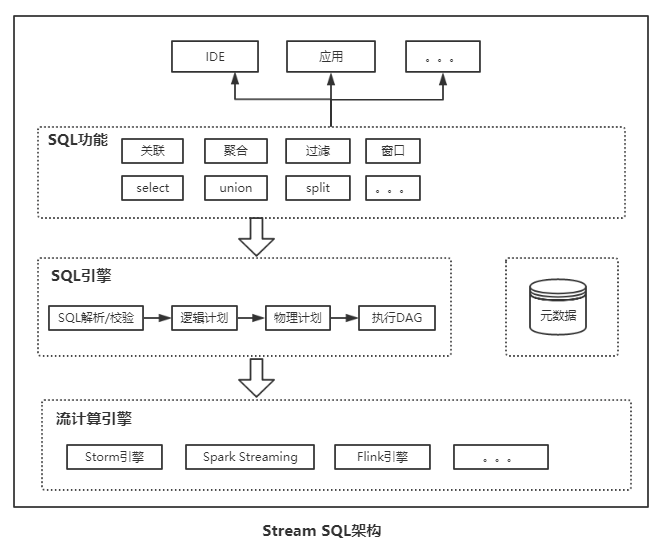
SQL层:流计算SQL给用户的接口,它提供过滤、转换、关联、聚合、窗口、select、union、split等各种功能。
SQL引擎层:负责SQL解析/校验、逻辑计划生成优化和物理计划执行等。
流计算引擎层:具体执行SQL引擎层生成的执行计划。
2、流计算SQL:未来主要的实时开发技术
目前流计算SQL在各个计算框架的进度和支持力度不一。
Storm SQL还只是一个实验性的功能。Flink SQL是Flink大力推广的核心API。Flink是一个原生的开源流计算引擎,而且目前还没有其它开源流计算引擎能提供比Flink 更优秀的流
计算SQL框架和语法等,所以Flink SQL实际上在定义流计算SQL的标注。
阿里云Stream SQL 的底层就是Flink引擎(实际是Blink,也就是Alibaba Flink),可以认为Blink是Flink的企业版本,
3、Stream SQL
阿里云提供了Stream SQL 开发的完整环境,包括Stream SQL语法、IDE开发工具、调试及运维等。下面具体介绍概念和语法
3.1、Stream SQL 源表
Stream SQL 通常将源头数据抽象为源表,就像一个Storm任务必须至少定义一个spout,一个Stream SQL 任务必须至少定义一个源表。
定义Stream SQL 源表的语法如下:
CREATE TABLE tablename
(columnName dataType [,columnName dataType]*)
[WITH (propertyName=propertyValue [,propertyName=propertyValue ] * )];
如下面的例子创建了一个datahub类型的源表
create table datahub_stream(
name varchar,
age BIGINT,
birthday BIGINT)
with (
type ='datahub',
endPoint =‘http://dh-et2.aliyun-inc.com’,
project='blink-datahub_test',
topic ='test_topic_1',
accessId =0i70RRFJD1OBAWAs',
accessKey ='yF60EwURseo1UAn4NinvQPJ2zhCfHU',
startTime='2018-08-20 00:00:00'
);
其中的type表示流式数据的源头类型,可以为datahub,也可以为日志或消息中间件等,type下面的各个参数类型的不同而不同,它们共同确定了此type的某个源头类型。
此外,阿里云Stream SQL底层流计算引擎是Flink/Blink,因此其支持水位线机制。
定义水位线的语法如下:
WATERMARK [watermarkName] FOR <rowtime_field>
AS withOffset(<rowtime_field>,offset)
比如WATERMARK FOR rowtime AS withOffset(rowtime,4000)就对源头数据列rowtime定义了固定延迟4s的水位线。
3.2 、Stream SQL 结果表
有源表,就是结果表,Stream SQL定义结果表的语法如下:
CREATE TABLE tablename
(columnName dataType [,columnName dataType]*)
[WITH (propertyName=propertyValue [,propertyName=propertyValue ] * )];
Stream SQL的结果表支持各种类型,包括类似MySQL的RDS、类似HBase的TableStore、类似消息队列的MessageQueue的,下面以RDS来介绍Stream SQL 结果表的具体语法:
create table rds_output(
id int,
len int,
content varchar,
primary key(id,len)
) with (
type ='rds',
url='jdbc:mysql:XXXXXX',
tableName='test4',
userName='test',
password='xxxx'
);
在上述代码中,结果表的type不同,相应后面的其它参数也不一样,具体可用参考阿里云帮助文档。
3.3、Stream SQL维度表
流计算SQL的维度表数据一类特殊的外部数据,相对流数据来说,他比较稳定且变化缓慢,是静态或准静态数据,作为join / left outer join的右表使用。需要特别注意的是,
维度表在流计算中不允许作为from 后面的数据存储。流计算中对于from子句后对接的数据存储一定是流式数据存储,即 select * from dim_table是不被允许的。
阿里云Stream SQL中没有专门为维度表设计的DDL语法,使用标准的create table语法即可,但是需要额外增加一行PERIOD FOR SYSTEM_TIME的声明,这行声明定义了
维度表的变化周期,即表明该表是一张会变化的表。
一个简单的维度表定义实例如下,type后面的语法类似源表定义,
CREATE TABLE white_list (
id varchar,
name varchar,
age int,
PRIMARY key(id), --用作维度表,必须有声明的主键
PERIOD FOR SYSTEM_TIME ---定义了维度表的变化周期
) with (
type = 'xxx',
。。。
);
3.4、Stream SQL 临时表
在实际的实时开发中,经常发现业务逻辑的复杂性使得只用一个Stream SQL来完成所有的业务逻辑基本是不可能的,而必须拆分为多个SQL共同完成,此时就需要定义中间临时表(
在阿里云Stream SQL 中也叫view,即视图)。在Stream SQL中定义临时表的语法如下:
CREATE VIEW viewName
[ (columnName[,columnName]*])]
AS queryStatement;
但需要注意的是,Stream SQL临时表仅用于辅助计算逻辑表达的内存逻辑中间状态,其物理是并不存在,也不会产生数据的物理存储。当然,临时表也不占用系统空间。一个临时表的例子
如下:
CREATE VIEW largeOrders(r, t, c, u) AS
SELECT rowtime, productId, c, units
FROM Orders;
3.5、Stream SQL DML
Stream SQL语法和SQL标准语法绝大部分都是相同的,下面仅着重介绍insert操作
insert操作的语法:
INSERT INTO tableName
[ ( columnName[,columnName]* )]
queryStatement;
流计算不支持单独SELECT操作,当前在执行SELECT查询之前必须执行INSERT操作将结果保存起来。同时,需要注意的是,一个SQL文件支持多个源表输入和多个结果表输出。
只有result表和tmp表可以执行INSERT操作,且每张表只能执行一次INSERT操作,dim 表和stream表不能执行insert操作。
普通的select操作是从几张表中读数据,但查询的对象也可以是另一个select操作,也就是子查询,但要注意子查询必须加别名,实例如下:
insert into result_table
select * from (
select t.a, sum(t.b) AS sum_b, from t1 t
group by t.a
) t1
where t1.sum_b>100;
参考资料:《离线和实时大数据开发实战》
大数据开发实战:Stream SQL实时开发一的更多相关文章
- 大数据开发实战:Stream SQL实时开发三
4.聚合操作 4.1.group by 操作 group by操作是实际业务场景(如实时报表.实时大屏等)中使用最为频繁的操作.通常实时聚合的主要源头数据流不会包含丰富的上下文信息,而是经常需要实时关 ...
- 大数据开发实战:Stream SQL实时开发二
1.介绍 本节主要利用Stream SQL进行实时开发实战,回顾Beam的API和Hadoop MapReduce的API,会发现Google将实际业务对数据的各种操作进行了抽象,多变的数据需求抽象为 ...
- Spark GraphX宝刀出鞘,图文并茂研习图计算秘笈与熟练的掌握Scala语言【大数据Spark实战高手之路】
Spark GraphX宝刀出鞘,图文并茂研习图计算秘笈 大数据的概念与应用,正随着智能手机.平板电脑的快速流行而日渐普及,大数据中图的并行化处理一直是一个非常热门的话题.图计算正在被广泛地应用于社交 ...
- AI应用开发实战 - 从零开始搭建macOS开发环境
AI应用开发实战 - 从零开始搭建macOS开发环境 本视频配套的视频教程请访问:https://www.bilibili.com/video/av24368929/ 建议和反馈,请发送到 https ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
- 云计算分布式大数据Hadoop实战高手之路第八讲Hadoop图文训练课程:Hadoop文件系统的操作实战
本讲通过实验的方式讲解Hadoop文件系统的操作. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发布云 ...
- 大数据开发实战:Hadoop数据仓库开发实战
1.Hadoop数据仓库架构设计 如上图. ODS(Operation Data Store)层:ODS层通常也被称为准备区(Staging area),它们是后续数据仓库层(即基于Kimball维度 ...
- [Hadoop 周边] 浅谈大数据(hadoop)和移动开发(Android、IOS)开发前景【转】
原文链接:http://www.d1net.com/bigdata/news/345893.html 先简单的做个自我介绍,我是云6期的,黑马相比其它培训机构的好偶就不在这里说,想比大家都比我清楚: ...
随机推荐
- IEEEXtreme Practice Community Xtreme9.0 - Digit Fun!
Xtreme9.0 - Digit Fun! 题目连接: https://www.hackerrank.com/contests/ieeextreme-challenges/challenges/di ...
- js识别用户设备是移动端手机时跳转到手机网站
一.识别到用户的设备是手机等移动端设备时跳转到移动端网站 var mobileAgent = new Array("iphone", "ipod", " ...
- 没用过的函数 GetHomePath - 获取用户程序数据目录
uses System.IOUtils; procedure TForm1.FormCreate(Sender: TObject); var S: string; begin { 三种方法结果一致: ...
- Upsync:微博开源基于Nginx容器动态流量管理方案
Upsync:微博开源基于Nginx容器动态流量管理方案 https://mp.weixin.qq.com/s?__biz=MzAwMDU1MTE1OQ==&mid=404151075& ...
- ubuntu单独安装字体包
查看当前字体的命令: fc-list 文泉驿字体下载地址: http://wenq.org/wqy2/index.cgi?ZenHei#v0_8 下载到的是一个deb安装包 在下载完字体以后将字体包拷 ...
- 【Go命令教程】6. go doc 与 godoc
go doc 命令可以打印附于Go语言程序 实体 上的文档.我们可以通过把程序实体的标识符作为该命令的参数来达到查看其文档的目的. 插播:所谓 Go语言的 程序实体,是指变量.常量.函数.结构体以及接 ...
- chrome主页被hao123篡改,怎么改回来?
这两天因为下载个别小程序又把我的chrome的主页给篡改了,由于我现在使用的是任务栏快捷方式,没法右键属性,但我想应该和桌面快捷方式是一个道理,于是我找到任务栏文件夹C:\Users\Administ ...
- 搭建《深入Linux内核架构》的Linux环境
作者 彭东林 pengdonglin137@163.com 软件 Host: Ubuntu14.04 64 Qemu 2.8.0 Linux 2.6.24 busybox 1.24.2 gcc 4.4 ...
- XCODE调试时不显示变量值/指针地址的解决方案
转:http://blog.csdn.net/samuelltk/article/details/41250151
- Java文件管理系统
上一个版本设计参照了 windows 资源管理器的原则,使用了多年.也发现了少许问题,也许是我们应用场景不一样... 目前的设计结合了目前的云概念.目录采用的是虚拟方式和实际的目录无关,只是存在一定的 ...