Oracle索引梳理系列(二)- Oracle索引种类及B树索引
版权声明:本文发布于http://www.cnblogs.com/yumiko/,版权由Yumiko_sunny所有,欢迎转载。转载时,请在文章明显位置注明原文链接。若在未经作者同意的情况下,将本文内容用于商业用途,将保留追究其法律责任的权利。如果有问题,请以邮箱方式联系作者(793113046@qq.com)。
Oracle索引种类
一 Oracle索引类型概述
oracle索引的种类主要有以下几种:
- B树索引:oracle默认的索引类型,内部采用二叉树结构,根据rowid实现访问行的快速定位。
- 反向索引:反转B树索引的索引列的键值字节,尤其是索引列值递增且批量插入数据时,使索引分布均匀。
- 位图索引:通过使用位图,标识被索引的列值,进而管理与数据行的对应关系。主要用于OLAP的系统。
- 表簇索引:使用表簇索引必须要使用表簇(cluster)。
- 函数索引:通过函数将数据列计算的返回值作为索引键值建立的索引结构。
二 B树索引
2.1 B树索引结构图说明
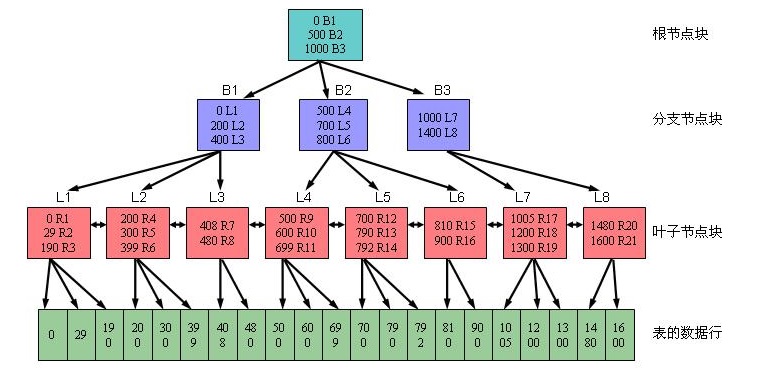
- 该结构图源自于网络,从图中不难看出,B树索引结构主要由三部分组成:根节点、分支节点、叶子节点。
- 对于oracle而言,索引的层级号采用倒序的方式,既对于层级数为N的索引,根节点的层级号为N,其下一层的分支节点为N-1,类推。
- 需要注意的是,oracle会自动为表的主键列创建索引。
- 需要注意的是,oracle不会对包含NULL值的索引列进行索引;但对于组合索引,其中包含NULL值的,这一行会索引。
- 需要注意的是,索引发生的I/O次数与索引树的层数成正比,因此有些情况下,采用“反向索引”(后面介绍),可以有效降低层数,今儿优化索引性能。
2.2 B树索引说明 - 分支节点(包含根节点)
- 对于分支节点块而言,其内部的索引条目采用顺序排列,默认为升序,创建时也可制定为降序。
- 对于分支节点块的索引条目而言,主要两个字段:
- 该分支节点块下面索引块的最小键值。
- 链接的索引块地址,该地址指向下面一个索引块。
- 对于分支节点块的索引条目数量,其大小由数据块大小以及键值长度决定。
2.3 B树索引说明 - 叶子节点
- 对于叶子节点块而言,其内部的索引条目同样采用顺序排列,默认为升序,创建时可制定为降序
- 索引的键值。对于单一列索引,其键值为一个列值;对于组合列索引,其键值为多个列值的组合。
- 键值的rowid信息。该rowid信息记录表中的相应数据的物理地址。
- 对于叶子节点块间的关系,采用双向链表,包含了指向上一个叶子节点以及下一个叶子节点的指针,方便一定范围内索引。
对于叶子节点块的索引条目而言,同样主要包含两个字段:
2.4 B树索引的实际运用情况
- 检索的数据列是索引指定列时,只需访问索引块即可完成数据的访问
--查看表中的索引信息
Yumiko@sunny >select index_name,table_name,column_name from user_ind_columns where table_name = 'EMP'; INDEX_NAME TABLE_NAME COLUMN_NAME
-------------------- -------------------- --------------------
PK_EMP EMP EMPNO--查看索引的类型,normal说明为正常B树索引
Yumiko@sunny >select INDEX_NAME,TABLE_NAME,index_TYPE from user_indexes where index_name ='PK_EMP';
INDEX_NAME TABLE_NAME INDEX_TYPE
----------------------------------------------------
PK_EMP EMP NORMAL--打开会话追踪
Yumiko@sunny >set autotrace traceonly --查看执行结果
Yumiko@sunny >select empno from emp where empno=7900; Execution Plan
----------------------------------------------------------
Plan hash value: 56244932 ----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4 | 0 (0)| 00:00:01 |
|* 1 | INDEX UNIQUE SCAN| PK_EMP | 1 | 4 | 0 (0)| 00:00:01 |
---------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- 1 - access("EMPNO"=7900) Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
1 consistent gets
0 physical reads
0 redo size
523 bytes sent via SQL*Net to client
523 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed通过上面的执行计划可以看到,检索数据仅仅扫描索引块便返回数据,并未进一步通过rowid进行表的扫描(
TABLEACCESSBYINDEXROWID)
- 检索的数据列中,含有未涵盖的索引指定列的时候,将会访问索引块以及数据块进行数据的检索
Yumiko@sunny >select index_name,table_name,column_name from user_ind_columns where table_name = 'EMP'; INDEX_NAME TABLE_NAME COLUMN_NAME
-------------------- -------------------- --------------------
PK_EMP EMP EMPNOYumiko@sunny >select INDEX_NAME,TABLE_NAME,index_TYPE from user_indexes where index_name ='PK_EMP';
INDEX_NAME TABLE_NAME INDEX_TYPE
----------------------------------------------------
PK_EMP EMP NORMALYumiko@sunny >set autotrace traceonly Yumiko@sunny >select * from emp where empno=7900; Execution Plan
----------------------------------------------------------
Plan hash value: 2949544139 --------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 38 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 38 | 1 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | PK_EMP | 1 | | 0 (0)| 00:00:01 |
-------------------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- 2 - access("EMPNO"=7900) Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
2 consistent gets
0 physical reads
0 redo size
889 bytes sent via SQL*Net to client
512 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed通过上面的执行计划可以看到,检索数据在扫描索引块后,进一步通过rowid进行表数据的扫描(
TABLEACCESSBYINDEXROWID)
- 检索数据时,当直接访问表数据的成本(访问数据块)优于使用索引访问表数据的成本(访问索引块+数据块)时,将不使用索引扫描。如全表扫描。
Yumiko@sunny >select index_name,table_name,column_name from user_ind_columns where table_name = 'EMP'; INDEX_NAME TABLE_NAME COLUMN_NAME
-------------------- -------------------- --------------------
PK_EMP EMP EMPNOYumiko@sunny >select INDEX_NAME,TABLE_NAME,index_TYPE from user_indexes where index_name ='PK_EMP';
INDEX_NAME TABLE_NAME INDEX_TYPE
----------------------------------------------------
PK_EMP EMP NORMALYumiko@sunny >set autotrace traceonly Yumiko@sunny >select * from emp;
14 rows selected. Execution Plan
----------------------------------------------------------
Plan hash value: 3956160932 --------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 532 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS FULL| EMP | 14 | 532 | 3 (0)| 00:00:01 |
-------------------------------------------------------------------------- Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
8 consistent gets
0 physical reads
0 redo size
1630 bytes sent via SQL*Net to client
523 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
14 rows processed通过上面的执行计划可以看到,当检索全表时,并未进行索引扫描,而是采用全表扫描的方式(TABLE ACCESS FULL),访问数据块,进而取得结果。
Oracle索引梳理系列(二)- Oracle索引种类及B树索引的更多相关文章
- [独孤九剑]Oracle知识点梳理(二)数据库的连接
本系列链接导航: [独孤九剑]Oracle知识点梳理(一)表空间.用户 [独孤九剑]Oracle知识点梳理(二)数据库的连接 [独孤九剑]Oracle知识点梳理(三)导入.导出 [独孤九剑]Oracl ...
- Oracle索引梳理系列(五)- Oracle索引种类之表簇索引(cluster index)
版权声明:本文发布于http://www.cnblogs.com/yumiko/,版权由Yumiko_sunny所有,欢迎转载.转载时,请在文章明显位置注明原文链接.若在未经作者同意的情况下,将本文内 ...
- Oracle索引梳理系列(四)- Oracle索引种类之位图索引
版权声明:本文发布于http://www.cnblogs.com/yumiko/,版权由Yumiko_sunny所有,欢迎转载.转载时,请在文章明显位置注明原文链接.若在未经作者同意的情况下,将本文内 ...
- Oracle索引梳理系列(九)- 浅谈聚簇因子对索引使用的影响及优化方法
版权声明:本文发布于http://www.cnblogs.com/yumiko/,版权由Yumiko_sunny所有,欢迎转载.转载时,请在文章明显位置注明原文链接.若在未经作者同意的情况下,将本文内 ...
- Oracle索引梳理系列(八)- 索引扫描类型及分析(高效索引必备知识)
版权声明:本文发布于http://www.cnblogs.com/yumiko/,版权由Yumiko_sunny所有,欢迎转载.转载时,请在文章明显位置注明原文链接.若在未经作者同意的情况下,将本文内 ...
- Oracle索引梳理系列(十)- 直方图使用技巧及analyze table操作对直方图统计的影响(谨慎使用)
版权声明:本文发布于http://www.cnblogs.com/yumiko/,版权由Yumiko_sunny所有,欢迎转载.转载时,请在文章明显位置注明原文链接.若在未经作者同意的情况下,将本文内 ...
- Oracle索引梳理系列(七)- Oracle唯一索引、普通索引及约束的关系
版权声明:本文发布于http://www.cnblogs.com/yumiko/,版权由Yumiko_sunny所有,欢迎转载.转载时,请在文章明显位置注明原文链接.若在未经作者同意的情况下,将本文内 ...
- Oracle索引梳理系列(一)- Oracle访问数据的方法
版权声明:本文发布于http://www.cnblogs.com/yumiko/,版权由Yumiko_sunny所有,欢迎转载.转载时,请在文章明显位置注明原文链接.若在未经作者同意的情况下,将本文内 ...
- Oracle索引梳理系列(六)- Oracle索引种类之函数索引
版权声明:本文发布于http://www.cnblogs.com/yumiko/,版权由Yumiko_sunny所有,欢迎转载.转载时,请在文章明显位置注明原文链接.若在未经作者同意的情况下,将本文内 ...
随机推荐
- 在linux中连接wifi
分为以下步骤:-----------(键入以下命令的时候注意大小写与空格.) 1. 进入终端treminal 获取管理员权限---------------------- su 命令(# su) 2. ...
- 51Node 1483----化学变换(暴力枚举)
51Node 1483----化学变换 有n种不同的化学试剂.第i种有ai升.每次实验都要把所有的化学试剂混在一起,但是这些试剂的量一定要相等.所以现在的首要任务是把这些化学试剂的量弄成相等. 有两 ...
- Verilog学习笔记基本语法篇(十三)...............Gate门
Verilog中已有一些建立好的逻辑门和开关的模型.在所涉及的模块中,可通过实例引用这些门与开关模型,从而对模块进行结构化的描述. 逻辑门: and (output,input,...) nand ( ...
- Think_php入口文件配置
think_php的入口模式有两种方式 1,一个入口文件对应一个项目应用 2,一个入口文件对应所有项目应用 默认情况,入口文件只需要require thinkphp文件夹就可以.比如thinkphp文 ...
- javascript脚本设置输入框只读的问题
今天在开发中准备通过javascript设置input框只读属性的时候,用document.getElementById('input').readonly='readonly';结果发现这样设置无效 ...
- Java基础学习小记--多态
题外话:总结了多年的学习心得,不得不说,睡眠是一个学习者的必需品!所谓"早起毁一天"不是没有道理哪,特别对Coders来说,有几天不是加班到夜里.好吧,我承认对于初学Java的我, ...
- 《Continuous Integration》读书笔记
Trigger a Build whenever a change occurs. it can help us reduce assumptions on a projecvt by rebuild ...
- 命令行工具解析Crash文件,dSYM文件进行符号化
备份 文/爱掏蜂窝的熊(简书作者)原文链接:http://www.jianshu.com/p/0b6f5148dab8著作权归作者所有,转载请联系作者获得授权,并标注“简书作者”. 序 在日常开发 ...
- [deviceone开发]-土地销售App开源
一.简介 这个是一个真实项目改造开源,虽然不是很花哨,但是中规中矩,小细节处理的也很好,非常值得参考和借鉴.里面的数据都缓存到本地,可以离线运行,但是调整一下代码,马上就可以和服务端完全对接.后续会有 ...
- 设置css通用字体
font-family: "Helvetica Neue","Arial","PingFang SC","Hiragino San ...