利用HtmlAgilityPack库进行HTML数据抓取
主要介绍基于XPATH的文本分析方式的实现,代码如下:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks; using HtmlAgilityPack;
namespace MyIdea.Spider
{
class Program
{
static void Main(string[] args)
{
GetDataFromFile();
GetDataFromUrl();
Console.ReadKey();
} static void GetDataFromFile()
{
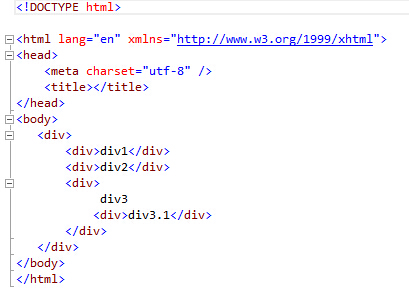
HtmlDocument doc = new HtmlDocument();
doc.Load(AppDomain.CurrentDomain.BaseDirectory.Replace(@"bin\Debug","") + "/test.html");
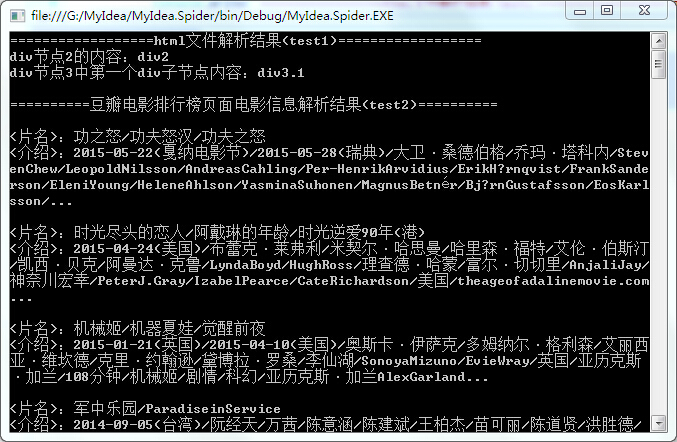
Console.Write("==================html文件解析结果(test1)==================\n");
Console.Write(string.Format("div节点2的内容:{0}\n", doc.DocumentNode.SelectNodes("/html/body/div/div")[].InnerText));
Console.Write(string.Format("div节点3中第一个div子节点内容:{0}\n\n", doc.DocumentNode.SelectNodes("/html/body/div/div/div")[].InnerText));
} static void GetDataFromUrl()
{
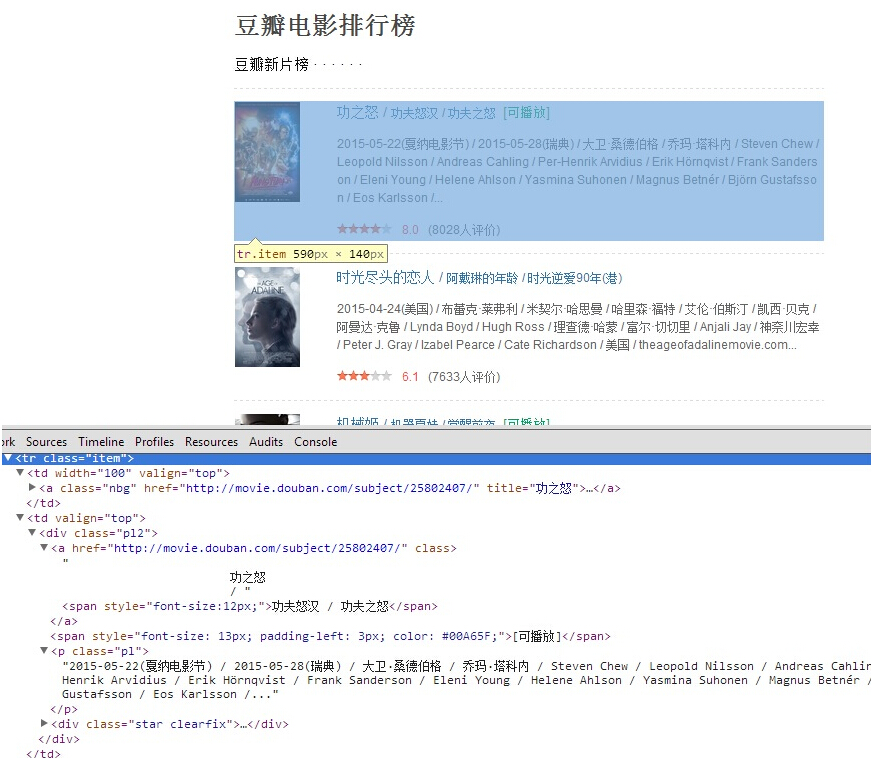
string url = "http://movie.douban.com/chart";
string movieXpath = "/html/body/div[3]/div[1]/div/div[1]/div/div/table/tr/td[2]/div";
HtmlWeb request = new HtmlWeb();
HtmlDocument doc = request.Load(url); HtmlNodeCollection movieItems = doc.DocumentNode.SelectNodes(movieXpath);
Console.Write("==========豆瓣电影排行榜页面电影信息解析结果(test2)==========\n");
foreach (HtmlNode item in movieItems)
{
string title = item.Descendants("a").First().InnerText.Replace(" ","").Replace("\n","");
string introduce = item.Descendants("p").First().InnerText.Replace(" ", "").Replace("\n", "");
Console.WriteLine("\n<片名>:"+title);
Console.WriteLine("<介绍>:" + introduce);
}
}
}
}
解析结果
利用HtmlAgilityPack库进行HTML数据抓取的更多相关文章
- 利用HtmlAgilityPack插件写的一个抓取指定网页的图片 第一次写 很乱 随便看看就行
public partial class Form1 : Form { /// <summary> /// 存放图片地址 /// </summary> List<stri ...
- 大众点评评论数据抓取 反爬虫措施有css文字映射和字体库反爬虫
大众点评评论数据抓取 反爬虫措施有css文字映射和字体库反爬虫 大众点评的反爬虫手段有那些: 封ip,封账号,字体库反爬虫,css文字映射,图形滑动验证码 这个图片是滑动验证码,访问频率高的话,会出 ...
- 利用python脚本(xpath)抓取数据
有人会问re和xpath是什么关系?如果你了解js与jquery,那么这个就很好理解了. 上一篇:利用python脚本(re)抓取美空mm图片 # -*- coding:utf-8 -*- from ...
- Python数据抓取_BeautifulSoup模块的使用
在数据抓取的过程中,我们往往都需要对数据进行处理 本篇文章我们主要来介绍python的HTML和XML的分析库 BeautifulSoup 的官方文档网站如下 https://www.crummy.c ...
- 大数据抓取采集框架(摘抄至http://blog.jobbole.com/46673/)
摘抄至http://blog.jobbole.com/46673/ 随着BIG DATA大数据概念逐渐升温,如何搭建一个能够采集海量数据的架构体系摆在大家眼前.如何能够做到所见即所得的无阻拦式采集.如 ...
- python爬虫数据抓取方法汇总
概要:利用python进行web数据抓取方法和实现. 1.python进行网页数据抓取有两种方式:一种是直接依据url链接来拼接使用get方法得到内容,一种是构建post请求改变对应参数来获得web返 ...
- python爬虫(一)_爬虫原理和数据抓取
本篇将开始介绍Python原理,更多内容请参考:Python学习指南 为什么要做爬虫 著名的革命家.思想家.政治家.战略家.社会改革的主要领导人物马云曾经在2015年提到由IT转到DT,何谓DT,DT ...
- 网页数据抓取工具,webscraper 最简单的数据抓取教程,人人都用得上
Web Scraper 是一款免费的,适用于普通用户(不需要专业 IT 技术的)的爬虫工具,可以方便的通过鼠标和简单配置获取你所想要数据.例如知乎回答列表.微博热门.微博评论.淘宝.天猫.亚马逊等电商 ...
- 数据抓取的艺术(三):抓取Google数据之心得
本来是想把这部分内容放到前一篇<数据抓取的艺术(二):数据抓取程序优化>之中.但是随着任务的完成,我越来越感觉到其中深深的趣味,现总结如下: (1)时间 时间是一个与抓取规模相形而 ...
随机推荐
- 小程序de 一些经验1
尝试着写微信的小程序,一个简单的表单验证.一开始就花了大把的时间尝试如何开始小程序的准备工作. 鼓捣半天,AppId是没有的,于是用了不用appId的模拟版.其实只要下载一个小程序版的微信开发工具. ...
- 使用JS脚本获取url中的参数
第一种方式:使用分隔符及循环查找function getQueryString(name) { // 如果链接没有参数,或者链接中不存在我们要获取的参数,直接返回空 if(location.href. ...
- flask-admin章节一:使用chartkick画报表
一般中小型WEB整体来看逻辑比较简单些,一般都是基于数据库的增删改查.不过通过数据库查询到的记录直接展示给用户不是很直观,大家其实蛮期待有一个报表 直接展示他们期待的内容. 这块就涉及到数据的提取和展 ...
- Linux多线程服务端编程一些总结
能接触这本书是因为上一个项目是用c++开发基于Linux的消息服务器,公司没有使用第三方的网络库,卷起袖子就开撸了.个人因为从业经验较短,主 要负责的是业务方面的编码.本着兴趣自己找了这本书.拿到书就 ...
- Select语句也会引起死锁
项目上线,准备验收前出现了一个严重的问题:很多select语句作为死锁的牺牲,大部分报表无法打开.这个问题影响范围很大所有的报表都无法访问,而我们的报表是放在电视上面轮播的,电视放在工厂里面,所以出现 ...
- 如何在一个div标签里显示出另一个网页? <iframe src=" http://www.baidu.com " width="800px" height="200px" scrolling="no" frameborder="0"> </iframe>
如何在一个div标签里显示出另一个网页? 用在div里用iframe,就像下面的代码 <iframe src=" http://www.baidu.com " width=& ...
- 微信公众账号开发之N个坑(一)
我这人干活没有前奏,喜欢直接开始.完了,宝宝已经被你们带污了.. 微信公众账号开发文档,官方版(https://mp.weixin.qq.com/wiki),相信我,我已经无力吐槽写这个文档的人了,我 ...
- LogNet4日志框架使用
.百度一下log4dll下载 .webconfig 里的<configSetions>节点中添加 <section name="log4net" type=&qu ...
- 优化后的 google提供的汉字转拼音类(针对某些htc等手机的不兼容情况)
/* * Copyright (C) 2011 The Android Open Source Project * * Licensed under the Apache License, Versi ...
- python ImportError: DLL load failed: %1 不是有效的 Win32 应用程序
导入的时候报出了 ImportError 在windows上安装python 的模块后,导入模块时报 python ImportError: DLL load failed: %1 不是有效的 Win ...